Azure SQL Database 的高可用性
適用於:![]() Azure SQL 資料庫
Azure SQL 資料庫
本文描述 Azure SQL Database 中的高可用性架構。
概觀
Azure SQL Database 中高可用性架構的目標是將服務維護作業和中斷對客戶工作負載的影響降到最低。 如需不同服務層級之特定 SLA 的相關資訊,請參閱 Azure SQL Database 的 SLA。
SQL Database 是已安裝所有適用修補程式的 Windows 作業系統上,最新穩定版本的 SQL Server 資料庫引擎上執行。 SQL Database 會自動處理重要的維護工作,例如修補、備份、Windows 和 SQL 引擎升級,以及基礎硬體、軟體或網路失敗等非計劃性事件。 在修補或容錯移轉 SQL Database 中的資料庫或彈性集區時,如果您在應用程式中採用重試邏輯,則停機不會產生影響。 即使在最嚴重的情況下,SQL Database 都可以快速復原,從而確保您的資料隨時可供使用。 大多數的使用者不會注意到升級是持續進行的。
高可用性解決方案旨在確保認可的資料絕不會因為失敗而遺失、維護作業不會影響到您的工作負載,以及資料庫不會是您軟體架構中的單一失敗點。
高可用性架構模型有三種:
- 遠端儲存模型,以計算和儲存體分隔為基礎。 這有賴於遠端儲存層的高可用性和可靠性。 此架構的適用標的是預算導向、可容許效能在維護活動期間些許下降的商務應用程式。
- 本機儲存模型,以資料庫引擎程序叢集為基礎。 這有賴於可用的資料庫引擎節點一律都有仲裁的事實。 此架構的適用標的是具有高 IO 效能、高交易率的任務關鍵性應用程式,可保證在維護活動期間對工作負載的效能影響最小。
- 超大規模資料庫模型,其使用高可用性元件的分散式系統,例如計算節點、頁面伺服器、記錄服務和永續性儲存體。 支援超大規模資料庫的每個元件都會提供自己的備援和失敗復原能力。 計算節點、頁面伺服器和記錄服務都會在 Azure Service Fabric 上執行,以控制每個元件的健康情況,並視需要執行容錯移轉至可使用且狀況良好的節點。 永續性儲存體會使用 Azure 儲存體及其原生的高可用性和備援功能。 若要深入了解,請參閱超大規模資料庫架構。
在這三種可用性模型中,SQL Database 都支援本機備援和區域備援選項。 本機備援可在資料中心內提供復原功能,而區域備援則可透過防範區域內可用性區域的中斷,進一步提升復原能力。
下表顯示以服務層級為基礎的可用性選項:
| 服務層級 | 高可用性模型 | 本機備援可用性 | 區域備援可用性 |
|---|---|---|---|
| 一般用途 (vCore) | 遠端儲存體 | Yes | Yes |
| 業務關鍵 (vCore) | 本機儲存體 | Yes | Yes |
| 超大規模資料庫 (vCore) | 超大規模資料庫 | Yes | Yes |
| 基本 (DTU) | 遠端儲存體 | 是 | No |
| 標準 (DTU) | 遠端儲存體 | 是 | No |
| 進階 (DTU) | 本機儲存體 | Yes | Yes |
本機備援可用性
本機備援可用性是以將資料庫儲存至本機備援儲存體 (LRS) 為基礎,這會在主要區域中的單一資料中心內複製資料三次,並在發生本機故障 (例如小規模的網路或電源故障) 時保護您的資料。 相較於其他選項,LRS 是成本最低的備援選項,且提供的持久性最弱。 如果在某個區域內發生火災或洪水之類的大規模災害,則可能會失去使用 LRS 的所有儲存體帳戶複本或無法復原。 因此,若要在使用本機備援可用性選項時進一步保護您的資料,請考慮針對資料庫備份使用更具彈性的儲存體選項。 這不適用於其中相同儲存體會同時用於資料檔案和備份的超大規模資料庫。
所有服務層級以及表示資料遺失量為零的復原點目標 (RPO) 中的所有資料庫都可以使用本機備援可用性。
[基本]、[標準] 和 [一般用途] 服務層級
[基本]、[標準] 和 [一般用途] 服務層級會針對無伺服器和已佈建的計算,使用遠端儲存可用性模型。 下圖顯示四個不同的節點,分別具有個別的計算和儲存層。
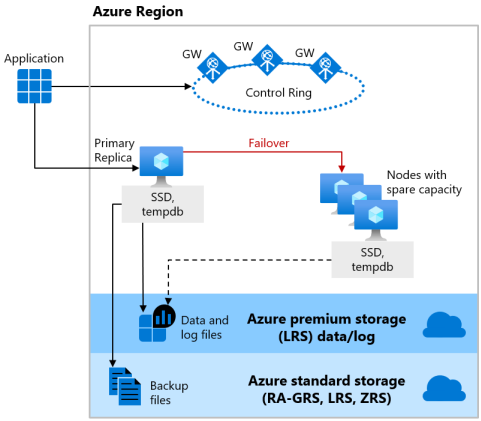
遠端存放可用性模型包含兩層:
- 無狀態計算層,會執行資料庫引擎程序,而且只包含暫時性和快取資料,例如已連結 SSD 上的
tempdb和model資料庫,以及記憶體中的計畫快取、緩衝集區與資料行存放區集區。 此無狀態節點是由 Azure Service Fabric 操作,可初始化資料庫引擎、控制節點的健康情況,並在必要時執行容錯移轉至其他節點。 - 具狀態資料層,包含 Azure Blob 儲存體中所儲存的資料庫檔案 (
.mdf和.ldf)。 Azure Blob 儲存體具有內建的資料可用性和備援功能。 其保證即使資料庫引擎程序損毀,也將保留記錄檔中每個記錄檔或頁面中的每筆記錄。
每當升級資料庫引擎或作業系統,或者偵測到失敗時,Azure Service Fabric 都會將無狀態資料庫引擎程序移至另一個包含足夠可用容量的無狀態計算節點。 Azure Blob 儲存體中的資料不受移動的影響,而資料/記錄檔會連結至新初始化的資料庫引擎程序。 此程序可保證高可用性,但因為新的資料庫引擎程序從冷快取開始,所以大量工作負載在轉換期間可能會經歷一些效能降低。
[進階] 與 [業務關鍵] 服務層級
[進階] 與 [業務關鍵] 服務層級會使用本機儲存可用性模型,此模型會將計算資源 (資料庫引擎程序) 和儲存體 (本機連結的 SSD) 整合在單一節點上。 藉由將計算和儲存體複寫至其他節點,即可達到高可用性。

基礎資料庫檔案 (.mdf/.ldf) 會放在連接的 SSD 儲存體上,以提供非常低的延遲 IO 給工作負載。 使用類似 SQL Server Always On 可用性群組的技術,實作高可用性。 叢集包含單一主要複本,可供讀寫客戶工作負載存取,以及最多三個包含資料複本的次要複本 (計算和儲存體) 存取。 主要複本會依序將變更持續推送至次要複本,並確保在提交每筆交易之前,將資料持久保存在足夠數量的次要複本上。 此程序可保證如果主要複本或可讀取的次要複本因任何原因而損毀,則一律會有完全同步的目標複本可供容錯移轉。 容錯移轉是由 Azure Service Fabric 所起始。 一旦次要復本變成新的主要復本,就會建立另一個次要復本,以確保叢集有足夠數量的復本來維護仲裁。 容錯移轉完成後,Azure SQL 連線會自動重新導向至新的主要複本或可讀取的次要複本。
本機儲存可用性模型還有額外的優點,包括將唯讀 Azure SQL 連線重新導向至其中一個次要複本的功能。 這項功能稱為讀取縮放。其會從主要複本提供 100% 額外的計算容量,而無需額外費用來卸載唯讀作業,例如分析工作負載。
超大規模資料庫服務層級
[超大規模資料庫] 服務層級架構會在分散式功能架構中描述。

超大規模資料庫的可用性模型包含四個層級:
- 無狀態計算層級,可執行資料庫引擎程序,而且只包含暫時性資料和快取資料,例如:已連結 SSD 上的非涵蓋 RBPEX 快取、
tempdb和model資料庫等,以及記憶體中的計畫快取、緩衝集區和資料行存放區集區。 此無狀態層包括主要計算複本,並選擇性包括一些可作為容錯移轉目標的次要計算複本。 - 由頁面伺服器構成的無狀態儲存層。 此層級是在計算複本上執行的資料庫引擎程序的分散式儲存引擎。 每部頁面伺服器只包含暫時性和快取資料,例如附加 SSD 上的涵蓋 RBPEX 快取,以及記憶體中快取的資料頁面。 每部頁面伺服器在主動-主動設定中都有配對的頁面伺服器,以提供負載平衡、備援和高可用性。
- 由執行記錄服務程序、交易記錄登陸區域和交易記錄長期儲存體的計算節點所構成的具狀態交易記錄儲存層。 登陸區域和長期儲存體會使用 Azure 儲存體,可提供交易記錄的可用性和備援,以確保認可交易的資料持久性。
- 具狀態資料儲存層具有資料庫檔案 (.mdf/.ndf),這些資料庫檔案是儲存在 Azure 儲存體中,並由頁面伺服器進行更新。 此層級使用 Azure 儲存體的資料可用性和備援功能。 其保證即使其他超大規模資料庫結構層中的程序損毀,或即使計算節點失敗,也會保留資料檔案中的每個頁面。
所有超大規模資料庫層中的計算節點都會在 Azure Service Fabric 上執行,以控制每個節點的健康情況,並視需要執行容錯移轉至可使用且狀況良好的節點。
如需關於超大規模資料庫高可用性的詳細資訊,請參閱超大規模資料庫中的資料庫高可用性。
區域備援可用性
區域備援可用性可確保您的資料分散在主要區域的三個 Azure 可用性區域。 每個可用性區域都是具有獨立電源、冷卻和網路的個別實體位置。
區域備援可用性適用於 [進階]、[業務關鍵]、[一般用途] 和 [超大規模資料庫] 服務層級,而不適用於以 DTU 為基礎的購買模型的 [基本] 和 [標準] 服務層級。 每個服務層級會以不同的方式實作區域備援可用性。 請參閱下列各章節中每個服務層級的詳細資料。 所有實作都會確保復原點目標 (RPO) 在容錯移轉時不會遺失認可的資料。
一般用途服務層級
[一般用途] 服務層級的區域備援設定適用於vCore 購買模型中資料庫的無伺服器和已佈建的計算。 此設定會利用 Azure 可用性區域,在 Azure 區域內的多個實體位置之間複寫資料庫。 藉由選取區域備援,您無須進行任何應用程式邏輯變更,即可讓新的和現有無伺服器及已佈建的一般用途單一資料庫和彈性集區在面對更大規模的故障 (包括災難性的資料中心服務中斷) 時,也能夠復原。
一般用途層的區域備援設定有兩層:
- 具狀態資料層,包含儲存在 ZRS (區域備援儲存體) 中的資料庫檔案 (.mdf/.ldf)。 使用 ZRS 時,資料和記錄檔會同步複製到三個實體隔離的 Azure 可用性區域。
- 無狀態計算層,會執行 sqlservr.exe 程序,而且只包含暫時性和快取資料,例如,已連結 SSD 上的
tempdb和model資料庫,以及記憶體中的計畫快取、緩衝集區和資料行存放區集區。 此無狀態節點是由 Azure Service Fabric 操作,可初始化 sqlservr.exe、控制節點的健康情況,並在必要時執行故障轉移至其他節點。 針對區域備援無伺服器與已佈建的一般用途資料庫,可在其他可用性區域中立即取得具有備援容量的節點以進行容錯移轉。
下圖說明一般用途服務層級之高可用性架構的區域備援版本:
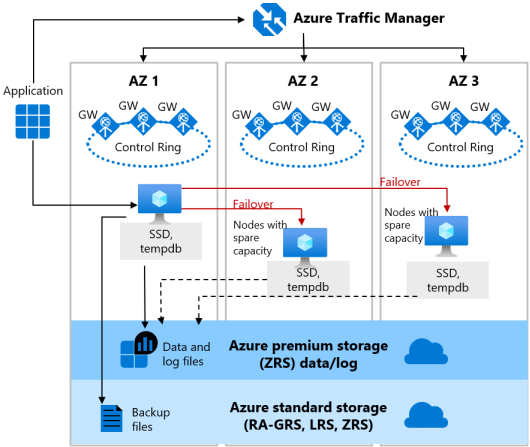
使用區域備援設定 [一般用途] 資料庫時,請考慮下列事項:
- 針對 [一般用途] 層級,區域備援設定在下列區域中正式推出:
- (非洲) 南非北部
- (亞太地區) 澳大利亞東部
- (亞太地區) 東亞
- (亞太地區) 日本東部
- (亞太地區) 南韓中部
- (亞太地區) 東南亞
- (亞太地區) 印度中部
- (亞太地區) 中國北部 3
- (亞太地區) 阿拉伯聯合大公國北部
- (歐洲) 法國中部
- (歐洲) 德國中西部
- (歐洲) 義大利北部
- (歐洲) 歐洲北部
- (歐洲) 挪威東部
- (歐洲) 波蘭中部
- (歐洲) 西歐
- (歐洲) 英國南部
- (歐洲) 瑞士北部
- (歐洲) 瑞典中部
- (中東) 以色列中部
- (中東) 卡達中部
- (北美洲) 加拿大中部
- (北美洲) 美國東部
- (北美洲) 美國東部 2
- (北美洲) 美國中南部
- (北美洲) 美國西部 2
- (北美洲) 美國西部 3
- (南美洲) 巴西南部
- 針對區域備援可用性,選擇預設值以外的維護時段目前可在選取區域中使用。
- 只有選取標準系列 (Gen5) 硬體時,才能在 SQL Database 中使用區域備援設定。
- 區域備援不適用於 DTU 購買模型中的 [基本] 和 [標準] 服務層級。
[進階] 與 [業務關鍵] 服務層級
針對 [進階] 或 [業務關鍵] 服務層級啟用區域備援時,複本會放在相同區域中的不同可用性區域。 為了避免發生單點失敗,系統也會跨多個區域將控制環複寫成三個閘道環 (GW)。 特定閘道通道的路由是由 Azure 流量管理員所控制。 由於 [進階] 或 [業務關鍵] 服務層級中的區域備援組態會使用其現有的複本來放置於不同的可用性區域中,因此您無需額外費用即可加以啟用。 藉由選取區域備援設定,您無須對應用程式邏輯進行任何變更,即可讓您的進階或業務關鍵資料庫和彈性集區在面對一組更大規模的失敗情況 (包括災難性的資料中心服務中斷) 時,也能夠復原。 您也可以將任何現有的進階或業務關鍵資料庫或彈性集區轉換成區域備援設定。
下圖說明區域備援版的高可用性架構:

使用區域備援設定進階或業務關鍵資料庫時,請考慮下列事項:
- 如需支援區域備援資料庫區域的最新資訊,請參閱依區域分類的服務支援。
- 針對區域備援可用性,選擇預設值以外的維護時段目前可在選取區域中使用。
超大規模資料庫服務層級
您可以為 [超大規模資料庫] 服務層級中的資料庫設定區域備援。 若要深入了解,請檢閱建立區域備援超大規模資料庫。
啟用此設定可透過跨所有超大規模資料庫層級的可用性區域複寫,來確保區域層級復原能力。 藉由選取區域備援,您無須進行任何應用程式邏輯變更,即可讓超大規模資料庫在面對更大規模的故障 (包括災難性的資料中心服務中斷) 時,也能夠復原。 所有具有可用性區域的 Azure 區域都支援區域備援超大規模資料庫。
超大規模資料庫獨立資料庫和超大規模資料庫彈性集區都支援區域備援可用性。 如需詳細資訊,請參閱超大規模資料庫彈性集區。
下圖展示區域備援超大規模資料庫的基礎架構:

請考慮下列限制:
您只能在資料庫建立期間指定區域備援設定。 佈建資源之後,就無法修改此設定。 使用資料庫複本、時間點還原,或建立異地複本來更新現有超大規模資料庫的區域備援設定。 當您使用下列其中一個更新選項時,若目標資料庫位於與來源不同的區域,或資料庫備份儲存體備援與來源資料庫不同時,複製作業會是資料大小的作業。
使用 Azure 入口網站將資料庫移轉至超大規模資料庫時,目前沒有任何可指定區域備援的選項。 不過,將現有的資料庫從另一個 Azure SQL Database 服務層級移轉至超大規模資料庫時,可以使用 Azure PowerShell、Azure CLI 或 REST API 指定區域備援。 以下是 Azure CLI 的範例:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true至少需要 1 個高可用性計算複本,以及需要使用區域備援或異地區域備援備份儲存體,才能啟用超大規模資料庫的區域備援設定。
資料庫區域備援可用性
在 Azure SQL Database 中,伺服器是一種邏輯建構,可作為資料庫集合的中央管理點。 在伺服器層級,您可以管理登入、驗證方法、防火牆規則、稽核規則、威脅偵測原則,以及容錯移轉群組。 與其中一些功能相關的資料 (例如登入和防火牆規則) 會儲存在 master 資料庫中。 同樣地,某些 DMV 的資料 (例如 sys.resource_stats) 也會儲存在 master 資料庫中。
在邏輯伺服器上建立具有區域備援設定的資料庫時,與伺服器相關聯的 master 資料庫也會自動建立區域備援。 這可確保在區域性中斷中,使用資料庫的應用程式仍然不會受到影響,因為依存於 master 資料庫的功能 (例如登入和防火牆規則) 仍然可以使用。 將 master 資料庫設為區域備援是非同步程序,需要一些時間才能在背景完成。
伺服器上沒有任何資料庫具有區域備援時,或當您建立空的伺服器時,與伺服器相關聯的 master 資料庫「未具有區域備援」。
您可以使用 Azure PowerShell 或 Azure CLI 或 REST API 來檢查 master 資料庫的 ZoneRedundant 屬性:
使用下列範例命令,來檢查 master 資料庫的 "ZoneRedundant" 屬性值。
Get-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "myServerName" -DatabaseName "master"
測試應用程式錯誤復原
高可用性是 SQL Database 平台的基礎部分,可為您的資料庫應用程式提供透明的運作。 不過,我們認為您可能想要測試在計劃性或非計劃性事件期間起始的自動容錯移轉作業對應用程式的影響,然後再將其部署到生產環境。 您可藉由呼叫特殊 API 重新啟動資料庫或彈性集區,手動觸發容錯移轉。 在區域備援無伺服器或佈建一般用途資料庫或彈性集區的情況下,API 呼叫會導致將用戶端連線重新導向至可用性區域中的新主要複本 (與舊主要複本的可用性區域不同)。 因此,除了測試容錯移轉如何影響現有的資料庫工作階段之外,您也可以確認其是否因為網路延遲的變更而變更端對端效能。 因為重新啟動作業會產生干擾,而且大量的作業可能會對平台造成壓力,所以每個資料庫或彈性集區每 15 分鐘只允許一次容錯移轉呼叫。
如需有關 Azure SQL Database 高可用性和災害復原的詳細資訊,請檢閱高可用性/災害復原檢查清單。
您可以使用 PowerShell、REST API 或 Azure CLI 來起始容錯移轉:
| 部署類型 | PowerShell | REST API | Azure CLI |
|---|---|---|---|
| 資料庫 | Invoke-AzSqlDatabaseFailover | 資料庫容錯移轉 | az rest 可用來從 Azure CLI 叫用 REST API 呼叫 |
| 彈性集區 | Invoke-AzSqlElasticPoolFailover | 彈性集區容錯移轉 | az rest 可用來從 Azure CLI 叫用 REST API 呼叫 |
重要
容錯移轉命令不適用於超大規模資料庫的可讀取次要複本。
結論
Azure SQL Database 具有與 Azure 平台高度整合的內建高可用性解決方案。 其仰賴 Service Fabric 進行失敗偵測和復原、仰賴 Azure Blob 儲存體進行資料保護,以及仰賴可用性區域進行容錯。 此外,SQL Database 使用 SQL Server 的 Always On 可用性群組技術進行資料同步和容錯移轉。 這些技術的組合可讓應用程式完全了解混合式儲存模型的優點,並支援最嚴苛的 SLA。
相關內容
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應