快速入門:適用於 Python 的 Azure Cosmos DB for MongoDB 與 MongoDB 驅動程式
適用於:![]() MongoDB
MongoDB
開始使用 PyMongo 套件,以在您的 Azure Cosmos DB 資源內建立資料庫、集合和文件。 請遵循下列步驟來安裝套件,並試用基本工作的程式碼範例。
注意
範例程式碼片段 可在 GitHub 上作為 Python 專案取得。
在本快速入門中,您將使用適用於 Python 的其中一個開放原始碼 MongoDB 用戶端驅動程式 PyMongo,與適用於 MongoDB 的 Azure Cosmos DB API 通訊。 此外,您將使用 MongoDB 延伸模組命令,其設計目的是協助您建立及取得 Azure Cosmos DB 容量模型的特定資料庫資源。
必要條件
- 具有有效訂用帳戶的 Azure 帳戶。 免費建立帳戶。
- Python 3.8+
- Azure 命令列介面 (CLI) 或 Azure PowerShell
先決條件檢查
- 在終端機或命令視窗中,執行
python --version以檢查您具有最新版本的 Python。 - 執行
az --version(Azure CLI) 或Get-Module -ListAvailable Az*(Azure PowerShell),以確認您已安裝適當的 Azure 命令列工具。
設定
本節將逐步引導您建立 Azure Cosmos DB 帳戶,並設定使用 MongoDB NPM 套件的專案。
建立 Azure Cosmos DB 帳戶
本快速入門會使用 API for MongoDB 建立單一 Azure Cosmos DB 帳戶。
建立 accountName、resourceGroupName 和 location 的殼層變數。
# Variable for resource group name resourceGroupName="msdocs-cosmos-quickstart-rg" location="westus" # Variable for account name with a randomnly generated suffix let suffix=$RANDOM*$RANDOM accountName="msdocs-$suffix"如果您尚未登入,請使用
az login命令登入 Azure CLI。使用
az group create命令在您的訂用帳戶中建立新的資源群組。az group create \ --name $resourceGroupName \ --location $location使用
az cosmosdb create命令建立具有預設設定的新 Azure Cosmos DB for MongoDB 帳戶。az cosmosdb create \ --resource-group $resourceGroupName \ --name $accountName \ --locations regionName=$location --kind MongoDB



取得 MongoDB 連接字串
使用
az cosmosdb keys list命令,從帳戶的連接字串清單中尋找 API for MongoDB 連接字串。az cosmosdb keys list --type connection-strings \ --resource-group $resourceGroupName \ --name $accountName記錄 PRIMARY KEY 值。 稍後您將使用這些認證。

建立新的 Python 應用程式
使用您慣用的終端機建立新的空白資料夾,並將目錄變更為資料夾。
注意
如果您只想要完成的程式碼,請下載或派生,並複製具有完整範例的範例程式碼片段存放庫。 您也可以在 Azure Cloud Shell 中
git clone存放庫,以逐步解說本快速入門中所示的步驟。建立列出 PyMongo 和 python-dotenv 套件的 requirements.txt 檔案。
# requirements.txt pymongo python-dotenv建立虛擬環境並安裝套件。
# py -3 uses the global python interpreter. You can also use python3 -m venv .venv. py -3 -m venv .venv source .venv/Scripts/activate pip install -r requirements.txt
設定環境變數
若要在程式碼內使用 CONNECTION STRING 值,請在執行應用程式的本機環境中設定此值。 若要設定環境變數,請使用您慣用的終端機來執行下列命令:
$env:COSMOS_CONNECTION_STRING = "<cosmos-connection-string>"
物件模型
讓我們先看看 API for MongoDB 中的資源階層,以及用於建立及存取這些資源的物件模型。 Azure Cosmos DB 會在由帳戶、資料戶、集合和文件所組成的階層中建立資源。
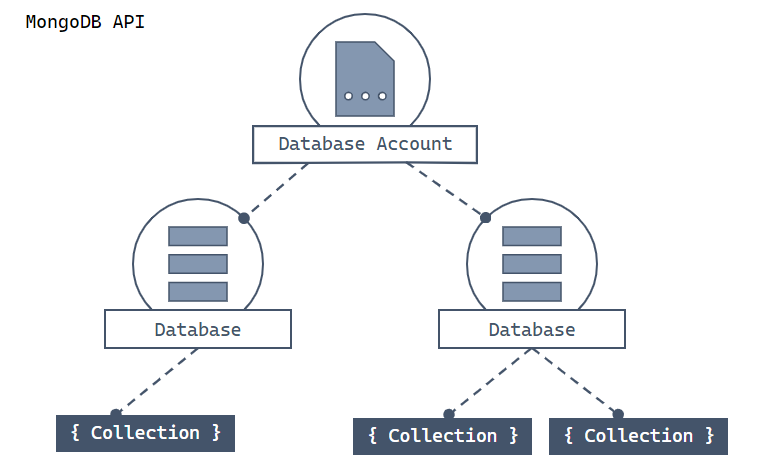
在頂端顯示 Azure Cosmos DB 帳戶的階層式圖表。 帳戶有兩個子資料庫分區。 其中一個資料庫分區包含兩個子集合分區。 另一個資料庫分區包含單一子集合分區。 該單一集合分區有三個子文件分區。
每種資源類型都會以 Python 類別表示。 以下是最常見的類別:
MongoClient - 使用 PyMongo 時的第一個步驟是建立 MongoClient,以連線至 Azure Cosmos DB 的 API for MongoDB。 用戶端物件會用於設定及執行針對服務的要求。
資料庫 - 適用於 MongoDB 的 Azure Cosmos DB API 可以支援一或多個獨立資料庫。
集合 - 資料庫可以包含一或多個集合。 集合是儲存在 MongoDB 中的文件群組,可視為關係資料庫中資料表的大致對等項目。
文件 - 文件是一組機碼值組。 文件具有動態結構描述。 動態結構描述表示相同集合中的文件不需要有一組相同欄位或結構。 而且集合文件中的常見欄位可能會保存不同類型的資料。
若要深入了解實體階層,請參閱 Azure Cosmos DB 資源模型一文。
程式碼範例
本文所述的範例程式碼會建立名為 adventureworks 的資料庫,其中包含名為 products 的集合。 products 集合的設計目的是要包含產品詳細資料,例如名稱、類別、數量和銷售指標。 每個產品也都包含唯一識別碼。 完整的程式碼範例位於 https://github.com/Azure-Samples/azure-cosmos-db-mongodb-python-getting-started/tree/main/001-quickstart/。
針對以下步驟,資料庫不會使用分區化,並使用 PyMongo 驅動程式顯示同步應用程式。 針對非同步應用程式,請使用 Motor 驅動程式。
驗證用戶端
在專案目錄中,建立 run.py 檔案。 在您的編輯器中,新增 require 陳述式來參考您將使用的套件,包括 PyMongo 和 python-dotenv 套件。
import os import sys from random import randint import pymongo from dotenv import load_dotenv從 .env 檔案中定義的環境變數取得連線資訊。
load_dotenv() CONNECTION_STRING = os.environ.get("COSMOS_CONNECTION_STRING")定義您將在程式碼中使用的常數。
DB_NAME = "adventureworks" COLLECTION_NAME = "products"
連線至適用於 MongoDB 的 Azure Cosmos DB API
使用 MongoClient 物件,連線至適用於 MongoDB 的 Azure Cosmos DB 資源。 此連接方法會傳回資料庫的參考。
client = pymongo.MongoClient(CONNECTION_STRING)
取得資料庫
使用 list_database_names 方法檢查資料庫是否存在。 如果資料庫不存在,請使用 create database extension 命令,以指定的佈建輸送量加以建立。
# Create database if it doesn't exist
db = client[DB_NAME]
if DB_NAME not in client.list_database_names():
# Create a database with 400 RU throughput that can be shared across
# the DB's collections
db.command({"customAction": "CreateDatabase", "offerThroughput": 400})
print("Created db '{}' with shared throughput.\n".format(DB_NAME))
else:
print("Using database: '{}'.\n".format(DB_NAME))
取得集合
使用 list_collection_names 方法檢查集合是否存在。 如果集合不存在,請使用 create collection extension 命令 來建立它。
# Create collection if it doesn't exist
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.command(
{"customAction": "CreateCollection", "collection": COLLECTION_NAME}
)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
建立索引
使用更新集合延伸模組命令建立索引。 您也可以在建立集合延伸模組命令中設定索引。 將此範例中的索引設定為 name 屬性,以便您稍後可以使用產品名稱上的資料指標類別排序方法進行排序。
indexes = [
{"key": {"_id": 1}, "name": "_id_1"},
{"key": {"name": 2}, "name": "_id_2"},
]
db.command(
{
"customAction": "UpdateCollection",
"collection": COLLECTION_NAME,
"indexes": indexes,
}
)
print("Indexes are: {}\n".format(sorted(collection.index_information())))
建立文件
使用 adventureworks 資料庫的 product 屬性來建立文件:
- category 屬性。 此屬性可作為邏輯分割區索引鍵。
- name 屬性。
- 庫存 quantity 屬性。
- sale 屬性,指出產品是否正在銷售。
"""Create new document and upsert (create or replace) to collection"""
product = {
"category": "gear-surf-surfboards",
"name": "Yamba Surfboard-{}".format(randint(50, 5000)),
"quantity": 1,
"sale": False,
}
result = collection.update_one(
{"name": product["name"]}, {"$set": product}, upsert=True
)
print("Upserted document with _id {}\n".format(result.upserted_id))
藉由呼叫集合等級作業 update_one,在集合中建立文件。 在此範例中,您將「更新插入」upsert,而不是「建立」新文件。 此範例中不需要更新插入,因為產品「名稱」是隨機的。 不過,在多次執行程式碼且產品名稱相同時,最好進行更新插入。
update_one 作業的結果包含您可以在後續作業中使用的 _id 欄位值。 已自動建立 _id 屬性。
取得文件
使用 find_one 方法來取得文件。
doc = collection.find_one({"_id": result.upserted_id})
print("Found a document with _id {}: {}\n".format(result.upserted_id, doc))
在 Azure Cosmos DB 中,您可以使用唯一識別碼 (_id) 和分割區索引鍵來執行成本較低的點讀取作業。
查詢文件
插入文件之後,您可以執行查詢來取得符合特定篩選的所有文件。 此範例會尋找符合特定類別的所有文件:gear-surf-surfboards。 定義查詢之後,請呼叫 Collection.find 以取得 Cursor 結果,然後使用排序。
"""Query for documents in the collection"""
print("Products with category 'gear-surf-surfboards':\n")
allProductsQuery = {"category": "gear-surf-surfboards"}
for doc in collection.find(allProductsQuery).sort(
"name", pymongo.ASCENDING
):
print("Found a product with _id {}: {}\n".format(doc["_id"], doc))
疑難排解:
- 如果您收到
The index path corresponding to the specified order-by item is excluded.這類錯誤,則請確定您已建立索引。
執行程式碼
此應用程式會建立 API for MongoDB 資料庫和集合,並建立文件,然後讀回完全相同的文件。 最後,此範例會發出查詢,以傳回符合指定產品「類別」的文件。 在每個步驟中,範例會將資訊輸出至主控台,包含其執行的步驟。
若要執行應用程式,請使用終端機瀏覽至應用程式目錄並執行應用程式。
python run.py
此命令的輸出應類似此範例:
Created db 'adventureworks' with shared throughput.
Created collection 'products'.
Indexes are: ['_id_', 'name_1']
Upserted document with _id <ID>
Found a document with _id <ID>:
{'_id': <ID>,
'category': 'gear-surf-surfboards',
'name': 'Yamba Surfboard-50',
'quantity': 1,
'sale': False}
Products with category 'gear-surf-surfboards':
Found a product with _id <ID>:
{'_id': ObjectId('<ID>'),
'name': 'Yamba Surfboard-386',
'category': 'gear-surf-surfboards',
'quantity': 1,
'sale': False}
清除資源
當您不再需要 Azure Cosmos DB for NoSQL 帳戶時,可以刪除對應的資源群組。
使用 az group delete 命令以刪除資源群組。
az group delete --name $resourceGroupName