使用 Azure Data Factory 或 Synapse Analytics 中的 Hadoop MapReduce 活動轉換資料
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
Azure Data Factory 或 Synapse Analytics 管線中的 HDInsight MapReduce 活動會在您自己或隨選的 HDInsight 叢集上叫用 MapReduce 程式。 本文是根據 資料轉換活動 一文,它呈現資料轉換和支援的轉換活動的一般概觀。
若要深入了解,請仔細閱讀 Azure Data Factory 和 Synapse Analytics 的簡介文章,並在閱讀本文之前進行教學課程:教學課程:轉換資料。
若要了解如何使用 HDInsight 的 Pig 和 Hive 活動,在 HDInsight 叢集上從管線執行 Pig/Hive 指令碼,請參閱 Pig 和 Hive。
使用 UI 將 HDInsight MapReduce 活動新增至管道
若要將 HDInsight MapReduce 活動用於管道,請完成下列步驟:
在管道 [活動] 窗格中搜尋 MapReduce,然後將 MapReduce 活動拖曳至管道畫布。
如果尚未選取,請選取畫布上的新 MapReduce 活動。
選取 [HDI 叢集] 索引標籤,選取或建立 HDInsight 叢集的新連結服務,該叢集會用來執行 MapReduce 活動。
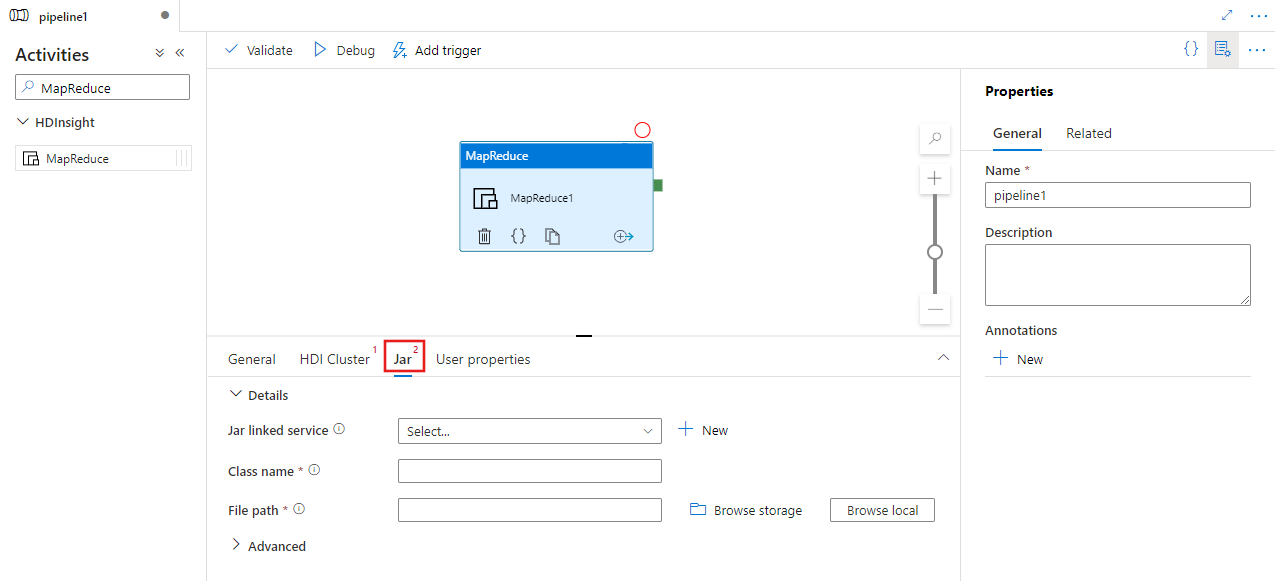
選取 [Jar] 索引標籤,選取或建立 Azure 儲存體帳戶的新 Jar 連結服務,該帳戶會裝載您的指令碼。 指定要在其中執行的類別名稱,以及儲存體位置內部的檔案路徑。 您也可以設定進階的詳細資料,包括 Jar 程式庫位置、偵錯設定,以及要傳遞至指令碼的引數和參數。
語法
{
"name": "Map Reduce Activity",
"description": "Description",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.myorg.SampleClass",
"jarLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "MyAzureStorage/jars/sample.jar",
"getDebugInfo": "Failure",
"arguments": [
"-SampleHadoopJobArgument1"
],
"defines": {
"param1": "param1Value"
}
}
}
語法詳細資料
| 屬性 | 描述 | 必要 |
|---|---|---|
| NAME | 活動的名稱 | Yes |
| description | 說明活動用途的文字 | No |
| type | 對於 MapReduce 活動,活動類型為 HDinsightMapReduce | Yes |
| linkedServiceName | 註冊為連結服務的 HDInsight 叢集參考。 若要深入了解此已連結的服務,請參閱計算已連結的服務一文。 | Yes |
| className | 要執行的類別名稱 | Yes |
| jarLinkedService | Azure 儲存體連結服務用來儲存 Jar 檔案的參考。 這裡僅支援 Azure Blob 儲存體和 ADLS Gen2 的連結服務。 如果您未指定這項連結服務,則會使用 HDInsight 已連結的服務中定義的 Azure 儲存體已連結的服務。 | No |
| jarFilePath | 提供儲存在 jarLinkedService 引用之 Azure 儲存體中 Jar 檔案的路徑。 檔案名稱有區分大小寫。 | Yes |
| jarlibs | 儲存在 jarLinkedService 引用之 Azure 儲存體中作業所參考的 Jar 程式庫檔路徑字串陣列。 檔案名稱有區分大小寫。 | No |
| getDebugInfo | 指定何時將記錄檔複製到 HDInsight 叢集所使用 (或) jarLinkedService 所指定的 Azure 儲存體。 允許的值︰None、Always 或 Failure。 預設值:無。 | No |
| 引數 | 指定 Hadoop 作業的引數陣列。 引數會以命令列引數的方式傳遞給每項工作。 | No |
| 定義 | 指定參數作為機碼/值組,以供在 Hive 指令碼內參考。 | No |
範例
您可以使用「HDInsight MapReduce 活動」,在 HDInsight 叢集上執行任何 MapReduce Jar 檔案。 在下列管線的範例 JSON 定義中,已設定讓「HDInsight 活動」執行 Mahout JAR 檔案。
{
"name": "MapReduce Activity for Mahout",
"description": "Custom MapReduce to generate Mahout result",
"type": "HDInsightMapReduce",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"className": "org.apache.mahout.cf.taste.hadoop.similarity.item.ItemSimilarityJob",
"jarLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
},
"jarFilePath": "adfsamples/Mahout/jars/mahout-examples-0.9.0.2.2.7.1-34.jar",
"arguments": [
"-s",
"SIMILARITY_LOGLIKELIHOOD",
"--input",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/input",
"--output",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/output/",
"--maxSimilaritiesPerItem",
"500",
"--tempDir",
"wasb://adfsamples@spestore.blob.core.windows.net/Mahout/temp/mahout"
]
}
}
您可以在 arguments 區段中,為 MapReduce 程式指定所有引數。 在執行階段,您會看到幾個來自 MapReduce 架構的額外引數 (例如:mapreduce.job.tags)。 若要區分您的引數與 MapReduce 引數,請考慮同時使用選項和值作為引數,如下列範例所示 (-s、--input、--output 等等是後面接著其值的選項)。
相關內容
請參閱下列文章,其說明如何以其他方式轉換資料: