處理 Azure Logic Apps 中的錯誤和例外狀況
適用於:Azure Logic Apps (使用量 + 標準)
適當地處理相依系統所造成的停機情況或問題,對任何整合架構來說都是種挑戰。 為協助您建立強固且具復原性的整合方案以便順利處理問題與失敗,Azure Logic Apps 提供一流的錯誤和例外狀況處理體驗。
重試原則
對於最基本的例外狀況和錯誤處理,您可以在觸發程序或動作支援時使用「重試原則」,例如 HTTP 動作。 如果觸發程序或動作的原始要求逾時或失敗,導致 408、429 或 5xx 回應,重試原則會指定觸發程序或動作依照原則設定來重新傳送要求。
重試原則限制
如需重試原則、設定、限制和其他選項的詳細資訊,請參閱重試原則限制。
重試原則型別
支援重試原則的連接器作業會使用預設原則,除非您選取不同的重試原則。
| 重試原則 | 描述 |
|---|---|
| Default | 對於大多數作業,預設重試原則是一個指數間隔原則,其以指數增加的間隔傳送最多 4 次重試。 這些間隔依 7.5 秒縮放,但上限在 5 到 45 秒之間。 數個作業使用不同的預設重試原則,如固定間隔原則。 如需詳細資訊,請檢閱預設重試原則型別。 |
| None | 不重新傳送要求。 如需詳細資訊,請檢閱無 - 無重試原則。 |
| 指數間隔 | 此原則會先等待選自指數成長範圍內的隨機間隔時間,再傳送下一個要求。 如需詳細資訊,請檢閱指數間隔原則型別。 |
| 固定間隔 | 此原則會先等待指定的間隔時間,再傳送下一個要求。 如需詳細資訊,請檢閱固定間隔原則型別。 |
變更設計工具中的重試原則型別
在 Azure 入口網站中,在設計工具中開啟您的邏輯應用程式工作流程。
根據您使用的是使用量或標準工作流程,開啟觸發程序或動作的 [設定]。
使用量:在動作圖形中,開啟省略符號功能表 (...),並選取 [設定]。
標準:在設計工具上,選取動作。 在詳細資料窗格中,選取 [設定]。
如果觸發程序或動作支援重試原則,請於 [重試原則] 下,選取您想要的原則型別。
在程式碼檢視編輯器中變更重試原則型別
如有必要,請完成設計工具中的先前步驟,確認觸發程序或動作是否支援重試原則。
在程式碼檢視編輯器中,開啟您的邏輯應用程式工作流程。
在觸發程序或動作定義中,將
retryPolicyJSON 物件新增至該觸發程序或動作的inputs物件。 否則,如果沒有retryPolicy物件存在,觸發程序或動作會使用default重試原則。"inputs": { <...>, "retryPolicy": { "type": "<retry-policy-type>", // The following properties apply to specific retry policies. "count": <retry-attempts>, "interval": "<retry-interval>", "maximumInterval": "<maximum-interval>", "minimumInterval": "<minimum-interval>" }, <...> }, "runAfter": {}必要
屬性 值 類型 描述 type<retry-policy-type> String 使用的重試原則型別: default、none、fixed或exponentialcount<retry-attempts> 整數 對於 fixed和exponential原則型別,嘗試重試次數的值介於 1 到 90 之間。 如需詳細資訊,請檢閱固定間隔和指數間隔。interval<retry-interval> String 對於 fixed和exponential原則型別,重試間隔值為 ISO 8601 格式。 對於exponential原則,您也可以指定選用的最大和最小間隔。 如需詳細資訊,請檢閱固定間隔和指數間隔。
使用量:5 秒 (PT5S) 到 1 天 (P1D)。
標準:對於具狀態工作流程,5 秒 (PT5S) 到 1 天 (P1D)。 對於無狀態工作流程,1 秒 (PT1S) 到 1 分鐘 (PT1M)。選擇性
屬性 值 類型 描述 maximumInterval<maximum-interval> String 對於 exponential原則,此為隨機選取間隔的最大間隔,且採用 ISO 8601 格式。 預設值是 1 天 (P1D)。 如需詳細資訊,請檢閱指數間隔。minimumInterval<minimum-interval> String 對於 exponential原則,此為隨機選取間隔的最小間隔,且採用 ISO 8601 格式。 預設值為 5 秒 (PT5S)。 如需詳細資訊,請檢閱指數間隔。
預設重試原則
支援重試原則的連接器作業會使用預設原則,除非您選取不同的重試原則。 對於大多數作業,預設重試原則是一個指數間隔原則,其以指數增加的間隔傳送最多 4 次重試。 這些間隔依 7.5 秒縮放,但上限在 5 到 45 秒之間。 數個作業使用不同的預設重試原則,如固定間隔原則。
在您的工作流程定義中,觸發程序或動作定義不會明確定義預設原則,但下列範例顯示預設重試原則對 HTTP 動作的行為方式:
"HTTP": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "http://myAPIendpoint/api/action",
"retryPolicy" : {
"type": "exponential",
"interval": "PT7S",
"count": 4,
"minimumInterval": "PT5S",
"maximumInterval": "PT1H"
}
},
"runAfter": {}
}
無 - 無重試原則
若要將動作或觸發程序指定為不會重試失敗的要求,請將 retry-policy-type<> 設定為 none。
固定間隔重試原則
若要將動作或觸發程序指定為先等候指定間隔再傳送下一個要求,請將 retry-policy-type<> 設定為 fixed。
範例
此重試原則會嘗試在第一次失敗要求後再取得最新消息兩次,每次嘗試之間有 30 秒的延遲:
"Get_latest_news": {
"type": "Http",
"inputs": {
"method": "GET",
"uri": "https://mynews.example.com/latest",
"retryPolicy": {
"type": "fixed",
"interval": "PT30S",
"count": 2
}
}
}
指數間隔重試原則
指數間隔重試原則會指定觸發程序或動作先等候隨機間隔,再傳送下一個要求。 隨機間隔會從指數成長範圍選取。 或者,您可以根據是否具備使用量或標準邏輯應用程式工作流程,指定自己的最小和最大間隔,藉此覆寫預設的最小和最大間隔。
| 名稱 | 使用量限制 | 標準限制 | 備註 |
|---|---|---|---|
| 最大延遲 | 預設值:1 天 | 預設值︰1 小時 | 若要變更使用量邏輯應用程式工作流程中的預設限制,請使用重試原則參數。 若要變更標準邏輯應用程式工作流程中的預設限制,請檢閱在單一租用戶 Azure Logic Apps 中編輯邏輯應用程式的主機和應用程式設定。 |
| 最小延遲 | 預設值:5 秒 | 預設值:5 秒 | 若要變更使用量邏輯應用程式工作流程中的預設限制,請使用重試原則參數。 若要變更標準邏輯應用程式工作流程中的預設限制,請檢閱在單一租用戶 Azure Logic Apps 中編輯邏輯應用程式的主機和應用程式設定。 |
隨機變數範圍
對於指數間隔重試原則,下表顯示 Azure Logic Apps 用來在每個重試的指定範圍內,產生統一隨機變數的一般演算法。 指定範圍最高可達並包括重試次數。
| 重試數目 | 最小間隔 | 最大間隔 |
|---|---|---|
| 1 | max(0, <minimum-interval>) | min(interval, <maximum-interval>) |
| 2 | max(interval, <minimum-interval>) | min(2 * interval, <maximum-interval>) |
| 3 | max(2 * interval, <minimum-interval>) | min(4 * interval, <maximum-interval>) |
| 4 | max(4 * interval, <minimum-interval>) | min(8 * interval, <maximum-interval>) |
| .... | .... | .... |
管理「執行時間點」行為
當您在工作流程設計工具中新增動作時,會隱含宣告用於執行這些動作的順序。 動作執行完畢之後,該動作會標示為下列狀態,例如 Succeeded (成功)、Failed (失敗)、Skipped (略過) 或 TimedOut (逾時)。 根據預設,您在設計工具中新增的動作只會在前置任務完成且狀態為 Succeeded (成功) 之後執行。 在動作的基礎定義中,runAfter 屬性會指定後置任務動作可以執行之前,必須先完成的前置任務動作,以及該前置任務允許的狀態。
當動作擲出未處理的錯誤或例外狀況時,動作會標示為 Failed (失敗),且任何後續動作都會標示為 Skipped (略過)。 如果此行為發生在具有平行分支的動作,Azure Logic Apps 引擎會遵循其他分支來判斷其完成狀態。 例如,如果分支以 Skipped (略過) 動作結束,該分支的完成狀態會以該略過動作的前置任務狀態為基礎。 工作流程執行完畢之後,引擎會評估所有分支的狀態,藉此判斷整個執行的狀態。 如果有任何分支以失敗結束,整個工作流程執行會標示為 Failed (失敗)。
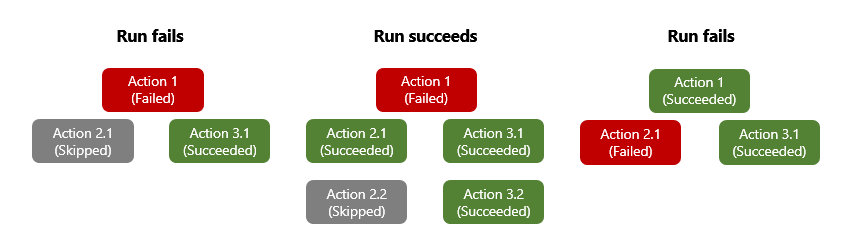
若要確保無論動作的前置任務狀態為何,該動作仍可執行,您可以變更動作的「執行時間點」行為,處理前置任務失敗的狀態。 如此一來,當前置任務的狀態為 Succeeded (成功)、Failed (失敗)、Skipped (略過)、TimedOut (逾時) 或所有這些狀態時,動作仍會執行。
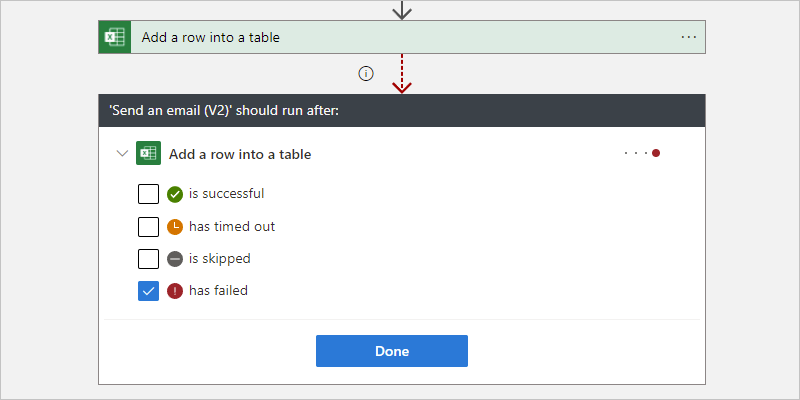
例如,若要在 Excel Online 將資料列新增至資料表前置任務動作標示為 Failed (失敗),而非 Succeeded (成功) 之後,執行 Office 365 Outlook 傳送電子郵件動作,請使用設計工具或程式碼檢視編輯器來變更「執行時間點」行為。
注意
在設計工具中,「執行時間點」設定不適用於緊接在觸發程序後的動作,因為觸發程序必須先順利執行,才能執行第一個動作。
變更設計工具中的「執行時間點」行為
在 Azure 入口網站中,在設計工具中開啟邏輯應用程式工作流程。
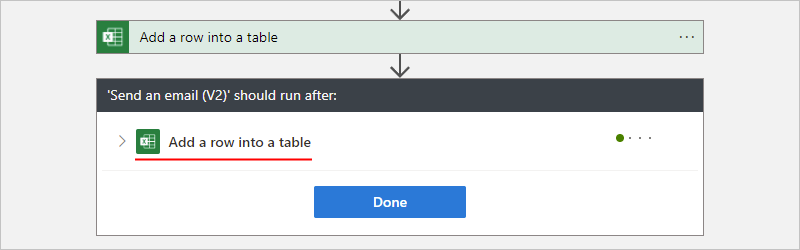
在設計工具上,選取動作圖形。 在詳細資料窗格中,選取 [執行時間點]。
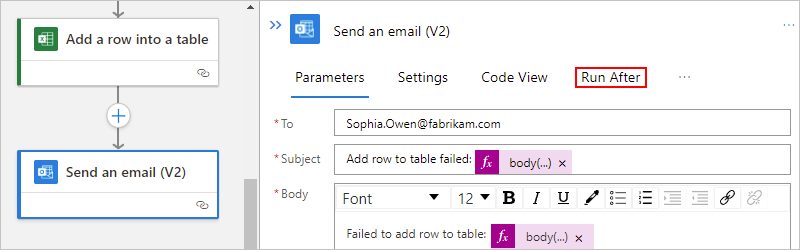
[執行時間點] 窗格顯示目前選取動作的前置任務動作。

展開前置任務動作節點,檢視所有「執行時間點」狀態。
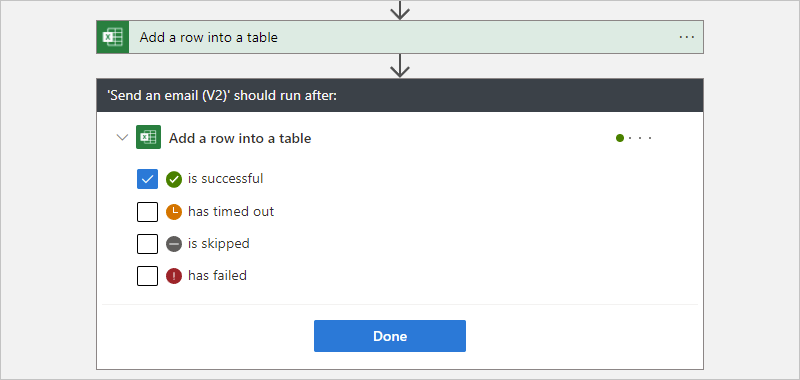
根據預設,「執行時間點」狀態會設定為成功。 因此,必須先順利執行前置任務動作,才能執行目前選取的動作。

將「執行時間點」行為變更為您想要的狀態。 請務必先選取選項,再清除預設選項。 您必須一律選取至少一個選項。
下列範例選取失敗。

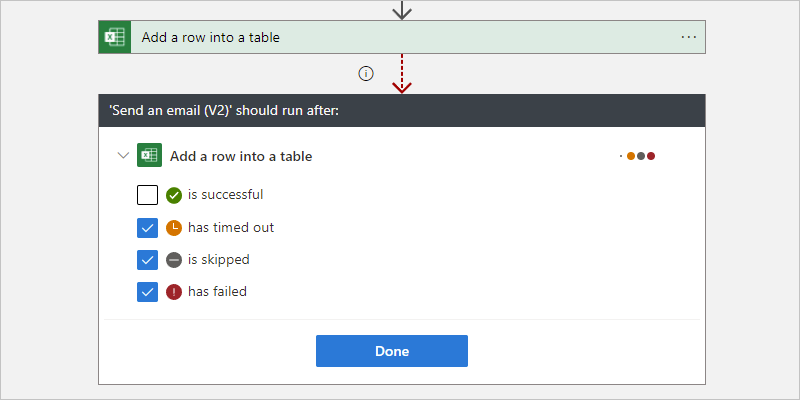
若要在無論前置任務動作標示為 Failed (失敗)、Skipped (略過) 或 TimedOut (逾時) 的情況下指定目前動作執行,請選取其他狀態。
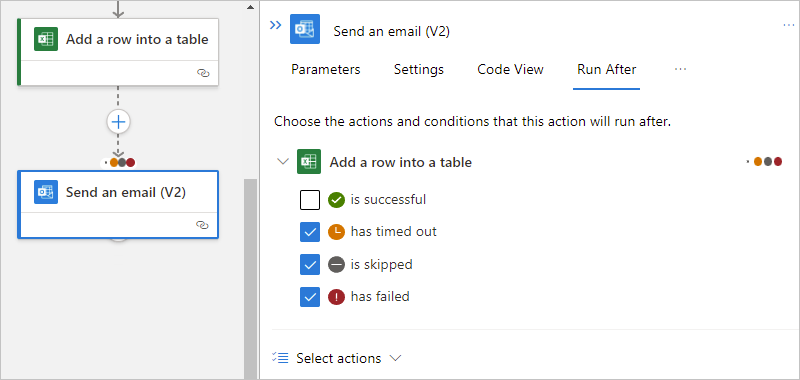
若要求執行多個前置任務動作,每個動作都有自己的「執行時間點」狀態,請展開 [選取動作] 清單。 選取您想要的前置任務動作,並指定其需要的「執行時間點」狀態。

準備就緒後,選取 [完成]。
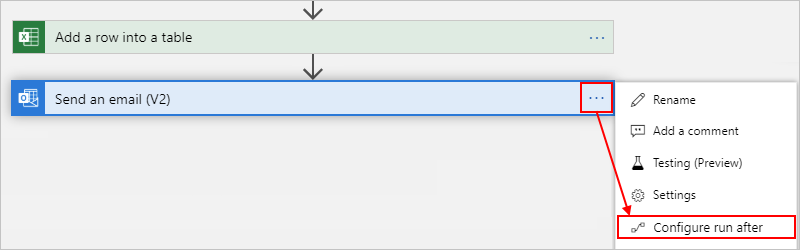
在程式碼檢視編輯器中變更「執行時間點」行為
在 Azure 入口網站中,在程式碼檢視編輯器中開啟您的邏輯應用程式工作流程。
在動作的 JSON 定義中,編輯具有下列語法的
runAfter屬性:"<action-name>": { "inputs": { "<action-specific-inputs>" }, "runAfter": { "<preceding-action>": [ "Succeeded" ] }, "type": "<action-type>" }在此範例中,將
runAfter屬性從Succeeded變更為Failed:"Send_an_email_(V2)": { "inputs": { "body": { "Body": "<p>Failed to add row to table: @{body('Add_a_row_into_a_table')?['Terms']}</p>", "Subject": "Add row to table failed: @{body('Add_a_row_into_a_table')?['Terms']}", "To": "Sophia.Owen@fabrikam.com" }, "host": { "connection": { "name": "@parameters('$connections')['office365']['connectionId']" } }, "method": "post", "path": "/v2/Mail" }, "runAfter": { "Add_a_row_into_a_table": [ "Failed" ] }, "type": "ApiConnection" }若要在無論前置任務動作標示為
Failed、Skipped或TimedOut的情況下指定動作執行,請新增其他狀態:"runAfter": { "Add_a_row_into_a_table": [ "Failed", "Skipped", "TimedOut" ] },
以範圍和其結果評估動作
類似於使用「執行時間點」設定,在個別動作之後執行步驟,您可以在範圍內將動作分組在一起。 當您想要以邏輯方式將動作群組在一起、評估範圍的彙總狀態,並根據這些狀態執行動作時,即可使用範圍。 當範圍中的所有動作都執行完成之後,範圍本身會取得自己的狀態。
若要檢查範圍的狀態,您可以使用檢查工作流程執行狀態時所用的相同準則,例如 Succeeded (成功)、Failed (失敗) 等。
根據預設,當範圍的所有動作都成功時,範圍的狀態會標示為 Succeeded (成功)。 如果範圍內的最後動作標示為 Failed (失敗) 或 Aborted (中止),範圍的狀態會標示 Failed (失敗)。
若要攔截 Failed (失敗) 範圍的例外狀況,並執行處理這些錯誤的動作,您可以使用 Failed (失敗) 範圍的「執行時間點」設定。 如此一來,如果範圍內的「任何」動作失敗,而您對該範圍使用「執行時間點」設定,則可建立單一動作來擷取失敗。
如需範圍的限制,請參閱限制和設定。
取得失敗的內容和結果
雖然從範圍擷取失敗很實用,但還是建議您取得更多內容以了解實際失敗的動作,以及任何錯誤或狀態碼。 result() 函式會傳回範圍動作中最上層動作的結果。 此函式接受範圍名稱做為單一參數,並傳回包含最上層動作結果的陣列。 這些動作物件包含的屬性與 actions() 函式傳回的屬性相同,例如動作的開始時間、結束時間、狀態、輸入、相互關聯識別碼和輸出。
注意
result() 函式「只會」傳回最上層動作的結果,而不是切換或條件式動作等更深入巢狀動作的結果。
若要取得失敗範圍中的動作內容,您可以使用 @result() 運算式搭配範圍名稱和「執行時間點」設定。 若要將傳回的陣列篩選為狀態是 Failed (失敗) 的動作,您可以新增篩選陣列動作。 若要執行傳回為失敗的動作,請採用傳回的篩選陣列,並使用針對每個迴圈。
下列 JSON 範例會針對名稱為 My_Scope 範圍動作內失敗的任何動作,傳送具有回應本文的 HTTP POST 要求。 範例後面接著詳細說明。
"Filter_array": {
"type": "Query",
"inputs": {
"from": "@result('My_Scope')",
"where": "@equals(item()['status'], 'Failed')"
},
"runAfter": {
"My_Scope": [
"Failed"
]
}
},
"For_each": {
"type": "foreach",
"actions": {
"Log_exception": {
"type": "Http",
"inputs": {
"method": "POST",
"body": "@item()['outputs']['body']",
"headers": {
"x-failed-action-name": "@item()['name']",
"x-failed-tracking-id": "@item()['clientTrackingId']"
},
"uri": "http://requestb.in/"
},
"runAfter": {}
}
},
"foreach": "@body('Filter_array')",
"runAfter": {
"Filter_array": [
"Succeeded"
]
}
}
下列步驟描述此範例中發生的情況:
若要從 My_Scope 內的所有動作取得結果,篩選陣列動作會使用此篩選條件運算式:
@result('My_Scope')篩選陣列的條件是狀態等於
Failed的任何@result()項目。 此條件會將具有 My_Scope 所有動作結果的陣列篩選成只有失敗動作結果的陣列。對「篩選陣列」輸出執行
For_each迴圈動作。 此步驟會對之前篩選的每個失敗動作結果執行動作。如果範圍中的單一動作失敗,
For_each迴圈中的動作只會執行一次。 如果有多個失敗動作,則會導致對每個失敗執行一個動作。在
For_each項目回應本文上傳送 HTTP POST,即@item()['outputs']['body']運算式。@result()項目圖形和@actions()圖形相同,並可透過相同方式剖析。包含兩個具有失敗動作名稱 (
@item()['name']) 和失敗執行用戶端追蹤識別碼 (@item()['clientTrackingId']) 的自訂標頭。
供您參考,以下範例是單一 @result() 項目,會顯示前一個範例中剖析的 name、body 和 clientTrackingId 屬性。 在 For_each 動作以外,@result() 會傳回這些物件的陣列。
{
"name": "Example_Action_That_Failed",
"inputs": {
"uri": "https://myfailedaction.azurewebsites.net",
"method": "POST"
},
"outputs": {
"statusCode": 404,
"headers": {
"Date": "Thu, 11 Aug 2016 03:18:18 GMT",
"Server": "Microsoft-IIS/8.0",
"X-Powered-By": "ASP.NET",
"Content-Length": "68",
"Content-Type": "application/json"
},
"body": {
"code": "ResourceNotFound",
"message": "/docs/folder-name/resource-name does not exist"
}
},
"startTime": "2016-08-11T03:18:19.7755341Z",
"endTime": "2016-08-11T03:18:20.2598835Z",
"trackingId": "bdd82e28-ba2c-4160-a700-e3a8f1a38e22",
"clientTrackingId": "08587307213861835591296330354",
"code": "NotFound",
"status": "Failed"
}
若要執行不同的例外狀況處理模式,您可以使用本文前面描述的運算式。 您可以選擇在範圍外執行單一例外狀況處理動作,以接受整個篩選後的失敗陣列,並移除 For_each 動作。 您也可以包含 \@result() 回應中其他有用的屬性,如先前所述。
設定 Azure 監視器記錄
先前的模式是處理執行中發生的錯誤和例外狀況的實用方式。 不過,您也可以識別並回應與執行無關的錯誤。 若要評估執行狀態,您可以監視執行的記錄和計量,或將其發佈至您偏好使用的任何監視工具。
例如,Azure 監視器提供簡化的方式,將所有工作流程事件,包括所有執行和動作狀態傳送至目的地。 您可以在 Azure 監視器中設定特定計量和閾值的警示。 您也可以將工作流程事件傳送至 Log Analytics 工作區或 Azure 儲存體帳戶。 或者,您可以透過 Azure 事件中樞,將所有事件串流至 Azure 串流分析。 在「串流分析」中,您可以根據診斷記錄中的任何異常、平均或失敗,撰寫即時查詢。 您可以使用「串流分析」將資訊傳送到其他資料來源,例如傳送到佇列、主題、SQL、Azure Cosmos DB 或 Power BI。
如需詳細資訊,請檢閱設定 Azure 監視器記錄並收集 Azure Logic Apps 的診斷資料。