Team 資料科學 Process (TDSP) 是一種敏捷、反覆的數據科學方法,可用來有效率地提供預測性分析解決方案和 AI 應用程式。 TDSP 藉由建議小組角色如何搭配運作,協助改善小組共同作業和學習。 TDSP 包含 Microsoft 和其他業界領導者的最佳做法和結構,可協助小組成功實作數據科學計劃,並充分實現分析計劃的優點。
本文提供 TDSP 及其主要元件的概觀。 它提供如何使用 Microsoft 工具和基礎結構實作 TDSP 的指引。 您可以在整個文章中找到更詳細的資源。
TDSP 的主要元件
TDSP 具有下列重要元件:
- 數據科學生命周期定義
- 標準化項目結構
- 數據科學專案建議的基礎結構和資源
- 建議用於專案執行的工具和公用程式
資料科學生命週期
TDSP 提供一個生命週期,可讓您用來建構數據科學項目的開發。 生命週期概述成功專案遵循的完整步驟。
您可以將以工作為基礎的 TDSP 與其他數據科學生命周期結合,例如數據採礦的跨產業標準程式(CRISP-DM)、資料庫 (KDD) 程式中的知識探索,或其他自定義程式。 概括而言,這些不同的方法有很多共同點。
如果您有屬於智慧型手機應用程式一部分的數據科學專案,您應該使用此生命週期。 智慧型手機應用程式會部署機器學習或 AI 模型以進行預測性分析。 您也可以使用此程式來探索資料科學專案和即興分析專案。
TDSP 生命週期是由小組反覆執行的五個主要階段所組成。 這些階段包括:
以下是 TDSP 生命週期的視覺表示法:
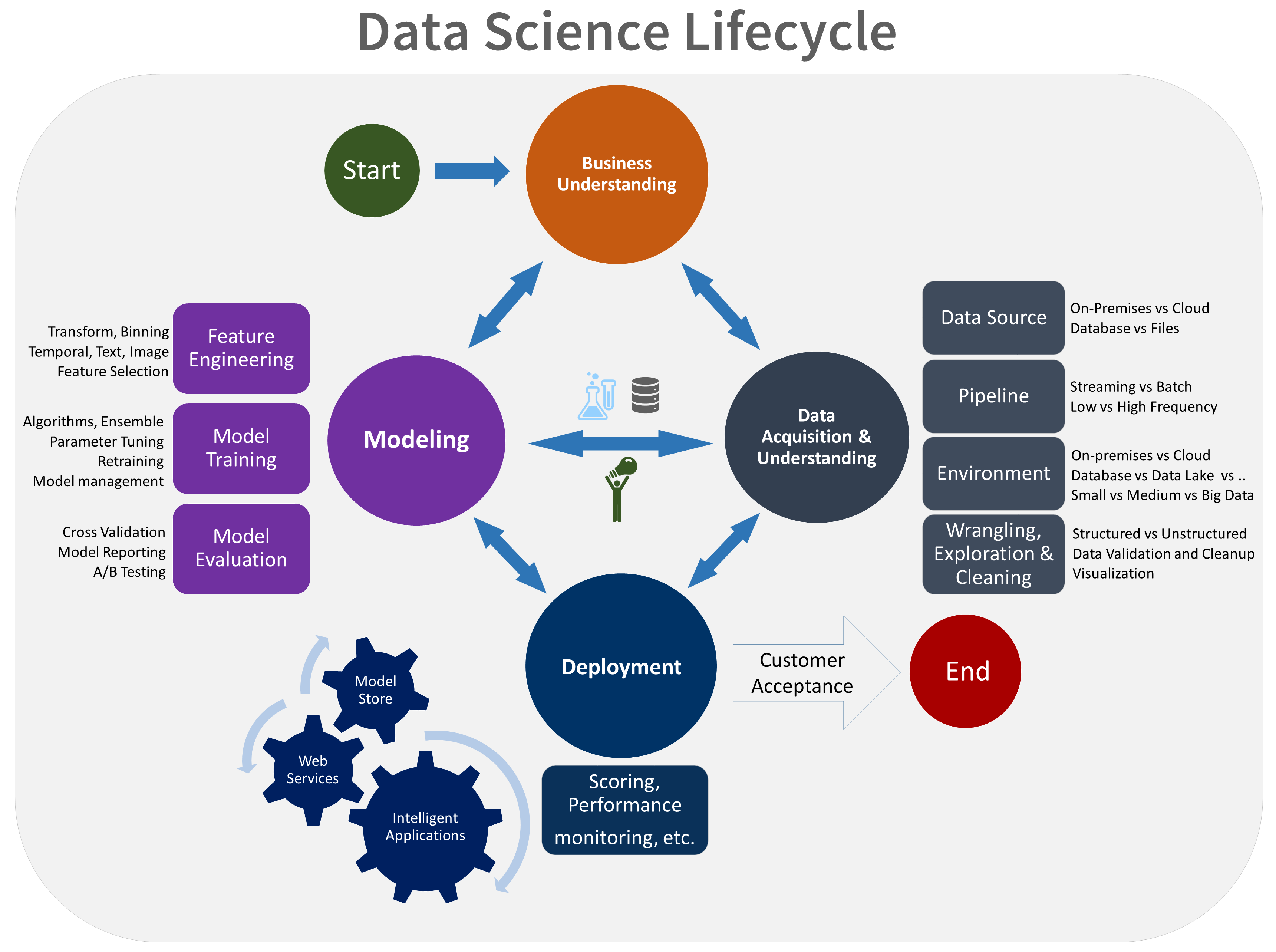
如需每個階段的目標、工作和檔成品的相關信息,請參閱Team資料科學 Process生命週期。
這些工作和成品與專案角色相關聯,例如:
- 解決方案架構師。
- 專案經理。
- 數據工程師。
- 資料科學家。
- 應用程式開發人員。
- 項目負責人。
下圖顯示這些角色(在垂直軸上)與生命週期每個階段相關聯的工作(藍色)和成品(以綠色表示)。

標準化項目結構
您的小組可以使用 Azure 基礎結構來組織數據科學資產。
Azure 機器學習 支持開放原始碼 MLflow。 我們建議使用 MLflow 進行數據科學和 AI 專案管理。 MLflow 的設計目的是要管理完整的機器學習生命週期。 它會在不同的平臺上定型並提供模型,因此無論您的實驗執行位置為何,您都可以使用一組一致的工具。 您可以在本機電腦上、遠端計算目標、虛擬機或 機器學習 計算實例上使用 MLflow。
MLflow 是由數個主要功能所組成:
追蹤實驗:使用 MLflow,您可以追蹤實驗,包括參數、程式代碼版本、計量和輸出檔案。 這項功能可協助您比較不同的執行,並有效率地管理實驗程式。
套件程式代碼:它提供標準化格式來封裝機器學習程序代碼,其中包含相依性和組態。 此封裝可讓您更輕鬆地重現執行,並與其他人共享程序代碼。
管理模型:MLflow 提供管理和版本控制模型的功能。 它支援各種機器學習架構,因此您可以儲存、版本及服務模型。
提供和部署模型:MLflow 整合模型服務與部署功能,讓您可以輕鬆地在各種環境中部署模型。
註冊模型:您可以管理模型的生命週期,包括版本控制、階段轉換和批注。 MLflow 適用於在共同作業環境中維護集中式模型存放區。
使用 API 和 UI:在 Azure 內,MLflow 會組合在 機器學習 API 第 2 版內,讓您可以以程序設計方式與系統互動。 您可以使用 Azure 入口網站 與 UI 互動。
MLflow 旨在簡化和標準化機器學習開發程式,從實驗到部署。
機器學習 與 Git 存放庫整合,因此您可以使用 GitHub、GitLab、Bitbucket、Azure DevOps 或其他與 Git 相容的服務。 除了 機器學習 中已追蹤的資產之外,您的小組還可以在其 Git 相容服務內開發自己的分類法,以儲存其他項目資訊,例如:
- 文件
- Project,例如最終項目報表
- 數據報表,例如數據字典或數據品質報表
- 模型,例如模型報表
- 代碼
- 資料準備
- 模型開發
- 作業化,包括安全性和合規性
基礎結構和資源
TDSP 提供管理共用分析和記憶體基礎結構的建議,例如:
- 用於儲存數據集的雲端檔案系統
- 資料庫
- 巨量數據叢集,例如 SQL 或 Spark
- 機器學習服務
您可以將分析和記憶體基礎結構放在雲端或內部部署中,其中儲存原始和已處理的數據集。 此基礎結構可讓您重現分析。 它也會防止重複,這可能會導致不一致和不必要的基礎結構成本。 基礎結構有工具可布建共用資源、追蹤資源,並允許每個小組成員安全地連線到這些資源。 讓項目成員建立一致的計算環境也是很好的作法。 然後,各種小組成員可以復寫和驗證實驗。
以下是小組處理多個專案並共用各種雲端分析基礎結構元件的範例:

工具和公用程式
在大部分組織中,引進程式是一項挑戰。 基礎結構提供實作 TDSP 和生命週期的工具,有助於降低其採用的障礙,並增加其採用的一致性。
透過 機器學習,數據科學家可以在數據科學管線或工作流程中套用開放原始碼工具。 在 機器學習 內,Microsoft 會推廣負責任的 AI 工具,以協助達成 Microsoft 的負責任 AI 標準。
同行檢閱的引文
TDSP 是 Microsoft 參與中採用的既定方法,因此已在同行審查的文獻中記錄和研究。 這些引文提供調查 TDSP 功能和應用程式的機會。 如需引文清單,請參閱生命週期概觀頁面。