Azure AI 搜尋服務中的可靠性
在 Azure 中,可靠性表示在服務中斷或降級時的復原和可用性。 在 Azure AI 搜尋服務中,您可以在單一服務內或透過不同區域中的多個搜尋服務來實現可靠性。
部署單一搜尋服務並相應增加,以實現高可用性。 您可以新增多個複本來處理較高的編製索引和查詢工作負載。 如果您的搜尋服務支援可用性區域,則複本會自動佈建在不同的實體資料中心,以達到額外的復原能力。
跨不同的地理區域部署多個搜尋服務。 所有搜尋工作負載都完全包含在單一地理區域中執行的單一服務內,但在多服務案例中,您可以選擇同步處理內容,讓所有服務中的內容都相同。 您也可以設定負載平衡解決方案,以重新發佈要求,或在服務中斷時進行容錯移轉。
為了實現區域層級的業務連續性和災難復原,請規劃跨區域拓撲,其中包含具有相同設定和內容的多個搜尋服務。 如果某個搜尋服務突然無法使用,您的自訂指令碼或程式碼將向備用搜尋服務提供「容錯移轉」機制。
高可用性
在 Azure AI 搜尋服務中,複本是索引的複本。 一項搜尋服務會委託至少一個復本,且最多可以有 12 個複本。 新增複本可讓 Azure AI 搜尋服務對一個複本執行機器重新開機和維護,同時在其他複本上繼續執行查詢。
對於每個個別的搜尋服務,Microsoft 保證符合下列準則的設定至少有 99.9% 的可用性:
針對唯讀工作負載 (查詢),需有 2 個複本才能達到高可用性
針對讀取/寫入工作負載 (查詢和索引) 的高可用性為 3 或更多個複本
系統具有監視複本健康情況和分割區完整性的內部機制。 如果您佈建複本和分割區的特定組合,系統可確保服務的容量層級。
免費層不提供 SLA。 如需詳細資訊,請參閱 Azure AI 搜尋服務的 SLA。
可用性區域支援
可用性區域是 Azure 平台功能,可將區域資料中心分成不同的實體位置群組,以提供相同區域內的高可用性。 在 Azure AI 搜尋服務中,個別複本是區域指派的單位。 搜尋服務會在一個區域內執行;其複本會在該區域內的不同實體資料中心 (或區域) 中執行。
當您將兩個或多個複本新增至搜尋服務時,會使用可用性區域。 每個複本都會放在區域內不同的可用性區域中。 如果您的複本數量多於搜尋服務區域中的可用性區域,則複本將盡可能平均分散至各個區域。 除了在提供可用性區域的區域建立搜尋服務,然後設定服務以使用多個複本以外,您不需要執行任何特定的動作。
必要條件
- 服務層級必須是「標準」或更高層級。
- 服務區域必須位於具有可用性區域的區域中 (在下一節中列出)。
- 組態必須包含多個複本:兩個用於唯讀查詢工作負載,三個用於包含編製索引的讀寫工作負載。
支援的區域
可用性區域的支援取決於基礎結構和儲存體。 目前,在 2023 年 10 月宣佈的兩個區域儲存體不足,不會針對 Azure AI 搜尋服務提供可用性區域:
- 以色列中部
- 義大利北部
相反地,以下區域支援 Azure AI 搜尋服務的可用性區域:
| 區域 | 推出 |
|---|---|
| 澳大利亞東部 | 2021 年 1 月 30 日或更新版本 |
| 巴西南部 | 2021 年 5 月 2 日或更新版本 |
| 加拿大中部 | 2021 年 1 月 30 日或更新版本 |
| 印度中部 | 2022 年 1 月 20 日或更新版本 |
| 美國中部 | 2020 年 12 月 4 日或更新版本 |
| 中國北部 3 | 2022 年 9 月 7 日或更新版本 |
| 東亞 | 2022 年 1 月 13 日或更新版本 |
| 美國東部 | 2021 年 1 月 27 日或更新版本 |
| 美國東部 2 | 2021 年 1 月 30 日或更新版本 |
| 法國中部 | 2020 年 10 月 23 日或更新版本 |
| 德國中西部 | 2021 年 5 月 3 日或更新版本 |
| 日本東部 | 2021 年 1 月 30 日或更新版本 |
| 南韓中部 | 2022 年 1 月 20 日或更新版本 |
| 北歐 | 2021 年 1 月 28 日或更新版本 |
| 挪威東部 | 2022 年 1 月 20 日或更新版本 |
| 卡達中部 | 2022 年 8 月 25 日或更新版本 |
| 南非北部 | 2022 年 9 月 7 日或更新版本 |
| 美國中南部 | 2021 年 4 月 30 日或更新版本 |
| 東南亞 | 2021 年 1 月 31 日或更新版本 |
| 瑞典中部 | 2022 年 1 月 21 日或更新版本 |
| 瑞士北部 | 2022 年 9 月 7 日或更新版本 |
| 阿拉伯聯合大公國北部 | 2022 年 9 月 9 日或更新版本 |
| 英國南部 | 2021 年 1 月 30 日或更新版本 |
| US Gov 維吉尼亞州 | 2021 年 4 月 30 日或更新版本 |
| 西歐 | 2021 年 1 月 29 日或更新版本 |
| 美國西部 2 | 2021 年 1 月 30 日或更新版本 |
| 美國西部 3 | 2021 年 1 月 2 日或更新版本 |
注意
可用性區域不會變更 Azure AI 搜尋服務等級協定的條款。 您仍然需要三個以上的複本,才能獲得查詢高可用性。
不同地理區域中的多個服務
如果您的作業需求包括下列項目,則需要服務備援:
商務持續性和災害復原 (BCDR) 需求 (Azure AI 搜尋服務不會在發生中斷時提供立即容錯移轉)。
全域分散式應用程式的快速效能。 如果查詢和編製索引要求來自世界各地,則最接近主機資料中心的使用者將有更快的效能。 在這些使用者附近的區域建立更多服務,即可讓所有使用者的效能相當。
如果您需要兩個以上的搜尋服務,在不同的區域中建立可以滿足持續性和復原的應用程式需求,以及針對全域使用者有更快速的回應時間。
Azure AI 搜尋服務不提供自動化方法來跨地理區域進行搜尋索引的複寫,但是有一些技術可讓這個程序更容易實作與管理。 我們將在後續幾節中加以概述。
一組異地分散的搜尋服務目標是,在兩個以上的區域中,可以使用兩個以上的索引,而使用者將在這些區域中路由傳送到 Azure AI 搜尋服務以提供最低延遲:
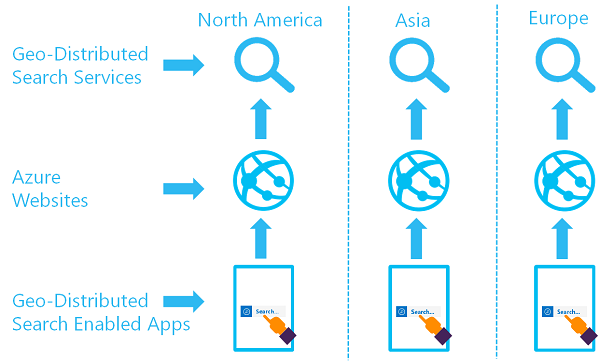
您可以藉由建立多個服務並設計資料同步處理策略來實作此結構。 您可以選擇性地包含 Azure 流量管理員之類的資源,以路由傳送要求。
提示
如需跨多個區域部署多個搜尋服務的說明,請參閱這個 GitHub 上的 Bicep 範例,該範例部署了完整設定的多區域搜尋解決方案。 此範例提供索引同步處理,以及使用流量管理員要求重新導向的兩個選項。
跨多個服務同步資料
有兩個選項可將兩個以上的不同搜尋服務保持同步:
- 使用索引子將內容更新提取至搜尋索引中。
- 使用新增或更新文件 (REST) API 或 Azure SDK 對等 API 將內容推送至索引。
若要設定任一選項,建議您在 azure-search-multiple-region 存放庫中使用範例 Bicep 指令碼,並根據您的區域和編製索引策略進行修改。
選項 1:使用索引子更新多個服務上的內容
如果您已經在一個服務上使用索引子,則可以在第二個服務上設定第二個索引子,以使用相同的資料來源物件,從相同位置提取資料。 每個區域中的每個服務都有自己的索引子與目標索引 (您的搜尋索引不會共用,這表示每個索引都有自己的資料複本),但每個索引子都會參考相同的資料來源。
以下是該架構外觀的高階視覺效果。
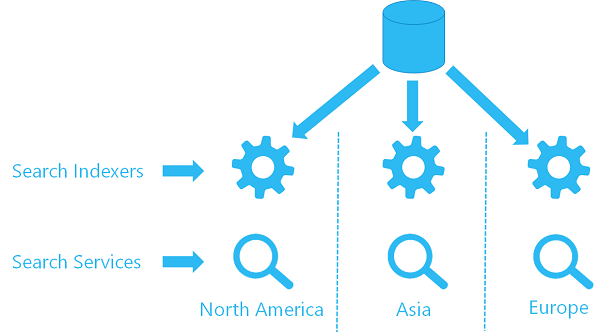
選項 2:使用 REST API 在多個服務上推送內容更新
如果您正在使用 Azure AI 搜尋服務 REST API 來推送搜尋索引的內容,您可以在需要更新時,將變更推送到所有搜尋服務,藉以讓各種搜尋服務維持同步。 在您的程式碼中,請務必處理一個搜尋服務更新失敗但針對其他搜尋服務成功的情況。
容錯移轉或重新導向查詢要求
如果您需要要求層級的備援,Azure 會提供數個負載平衡選項:
- Azure 流量管理員用於將要求路由傳送至位於多個地理位置的網站,然後透過多個搜尋服務進行備份。
- 應用程式閘道用於應用程式層區域內伺服器之間的負載平衡。
- Azure Front Door 用於最佳化 Web 流量的全域路由,以及提供全域容錯移轉。
評估負載平衡選項時,請記住一些重點:
搜尋是一項後端服務,可接受來自用戶端的查詢和編製索引要求。
用戶端向搜尋服務發出的要求必須經過驗證。 若要存取搜尋作業,呼叫端必須具有角色型權限,或在要求上提供 API 金鑰。
預設會透過公共網路連線到服務端點。 如果您為源自虛擬網路內的用戶端連線設定私人端點,請使用應用程式閘道。
Azure AI 搜尋服務會接受尋址至
<your-search-service-name>.search.windows.net端點的要求。 如果您在主機標頭中使用不同的 DNS 名稱 (例如 CNAME) 來連線到相同的端點,則會拒絕要求。
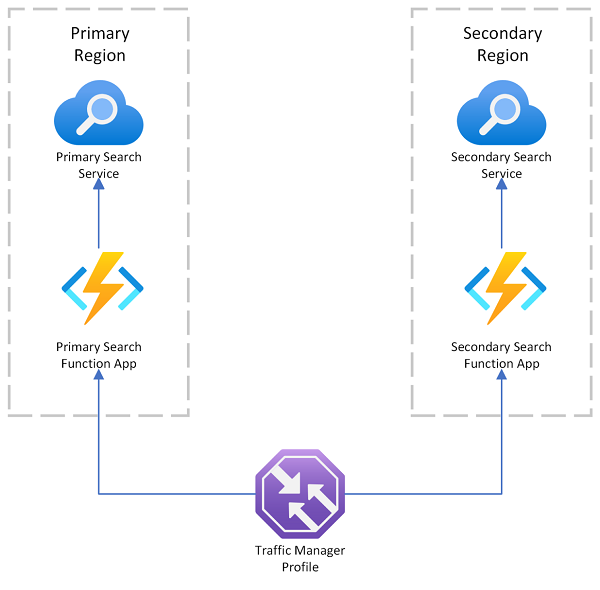
Azure AI 搜尋服務提供多區域部署範例,該範例在主要端點發生故障時使用 Azure 流量管理員進行要求重新導向。 當您路由至已啟用搜尋的用戶端 (只呼叫相同區域中的搜尋服務) 時,此解決方案非常有用。
Azure 流量管理員主要用於根據特定路由方法 (例如優先順序、效能或地理位置) 跨不同端點路由網路流量。 它會在 DNS 層級上運作,以將連入要求導向至適當的端點。 如果流量管理員正在服務的端點開始拒絕要求,流量就會路由傳送至另一個端點。
流量管理員不提供直接連線至 Azure AI 搜尋服務的端點,這表示您無法將搜尋服務直接放在流量管理員後面。 相反地,假設是要求會流向流量管理員,然後流向已啟用搜尋的 Web 用戶端,最後流向後端的搜尋服務。 用戶端和服務位於相同的區域中。 如果一項搜尋服務發生故障,,搜尋用戶端就會開始失敗,流量管理員會重新導向至其餘用戶端。
關於多區域部署中的資料落地
當您在不同地理區域中部署多個搜尋服務時,您的內容會儲存在您為每個搜尋服務選擇的區域中。
在未經您授權的情況下,Azure AI 搜尋服務不會將資料儲存至指定區域之外。 當您使用寫入 Azure 儲存體資源的功能時,授權是隱含的:擴充快取、偵錯工作階段、知識存放區。 在所有情況下,儲存體帳戶都是您在您選擇的區域中提供的帳戶。
注意
如果儲存體帳戶和搜尋服務位於相同的區域中,則搜尋和儲存體之間的網路流量會使用私人 IP 位址,並透過 Microsoft 骨幹網路進行。 由於使用私人 IP 位址,因此您無法針對網路安全性設定 IP 防火牆或私人端點。 當兩個服務都位於相同區域時,請改用受信任的服務例外狀況作為替代方式。
關於服務中斷和災難性事件
如服務等級協定 (SLA) 中所述,Microsoft 會在 Azure AI 搜尋服務執行個體設定使用兩個以上的複本時,保證索引查詢要求的高可用性,以及當 Azure AI 搜尋服務執行個體設定使用三個以上的複本時,保證索引更新要求的高可用性。 不過,沒有任何內建的機制可進行災害復原。 如果在遇到 Microsoft 控制之外的災難性失敗時,需要持續的服務,建議在不同區域佈建第二個服務並實作異地複寫策略,以確保索引在所有服務之間皆具有完整備援。
使用索引子來填入及重新整理索引的客戶,可以透過使用相同資料來源的地理特定索引子來處理災害復原。 在不同區域中的兩個服務 (每個都執行一個索引子),可以從相同相同的資料來源建立索引,以達到異地備援的目的。 如果從同為異地備援的資料來源建立索引,請記住,Azure AI 搜尋服務索引子只能在主要複本執行遞增索引 (從新的、修改的或刪除的文件中合併更新)。 在容錯移轉事件中,請務必將索引子重新指向新的主要複本。
若不使用索引子,您可以使用應用程式程式碼將物件和資料平行推送到不同的搜尋服務。 如需詳細資訊,請參閱讓資料跨多個服務保持同步。
備份和還原替代方案
資料層的商務持續性策略通常包含從備份還原的步驟。 因為 Azure AI 搜尋服務不是主要的資料儲存體解決方案,所以 Microsoft 不提供自助備份及還原的正式機制。 不過,您可以使用此 Azure AI 搜尋服務 .NET 範例存放庫中的 index-backup-restore 範例程式碼,將索引定義和快照集備份至一系列的 JSON 檔案,然後視需要使用這些檔案來還原索引。 此工具也可以移動服務層級之間的索引。
否則,如果不小心刪除索引,您用於建立及填入索引的應用程式程式碼是現行的還原選項。 若要重建索引,請先將索引刪除 (假設它存在),在服務中重新建立索引,然後從您的主要資料存放區擷取資料以重新載入。
下一步
- 若要深入了解定價層及每一層的服務限制,請參閱服務限制。
- 請參閱容量規劃,以便深入了解分割區和複本組合。
- 請參閱案例研究:使用認知搜尋來支援複雜的 AI 案例,以取得更多設定指引。