Netezza 移轉的設計和效能
本文是七個部分系列的第一部分,提供如何從 Netezza 移轉至 Azure Synapse Analytics 的指引。 本文著重於設計和效能的最佳做法。
概觀
由於 IBM 的支援終止,Netezza 資料倉儲系統的許多現有使用者,都想要利用新式雲端環境所提供的創新。 基礎結構即服務 (IaaS) 和平台即服務 (PaaS) 雲端環境可讓您將基礎結構維護和平台開發等工作委派給雲端提供者。
提示
不只是資料庫,Azure 環境還包含一組完整的功能和工具。
儘管 Netezza 和 Azure Synapse Analytics 都是使用大規模平行處理 (MPP) 技術以在超大資料量上實現高查詢效能的 SQL 資料庫,但在方法方面有一些基本差異:
舊版 Netezza 系統通常會安裝在內部部署並使用專屬硬體,而 Azure Synapse Analytics 是以雲端為基礎,並使用 Azure 儲存體和計算資源。
升級 Netezza 設定是一項主要工作,其涉及額外實體硬體,且可能需要很長時間的資料庫重新設定或傾印和重新載入。 由於儲存體和計算資源在 Azure 環境中是分開的,且具有彈性的調整功能,因此這些資源可以獨立擴大或縮小。
您可以根據需要暫停 Azure Synapse Analytics 或調整其大小,以降低資源使用率和成本。
Microsoft Azure 是全球可用、高度安全且可調整的雲端環境,包含 Azure Synapse 以及支援工具和功能的生態系統。 下圖摘要說明 Azure Synapse 生態系統。
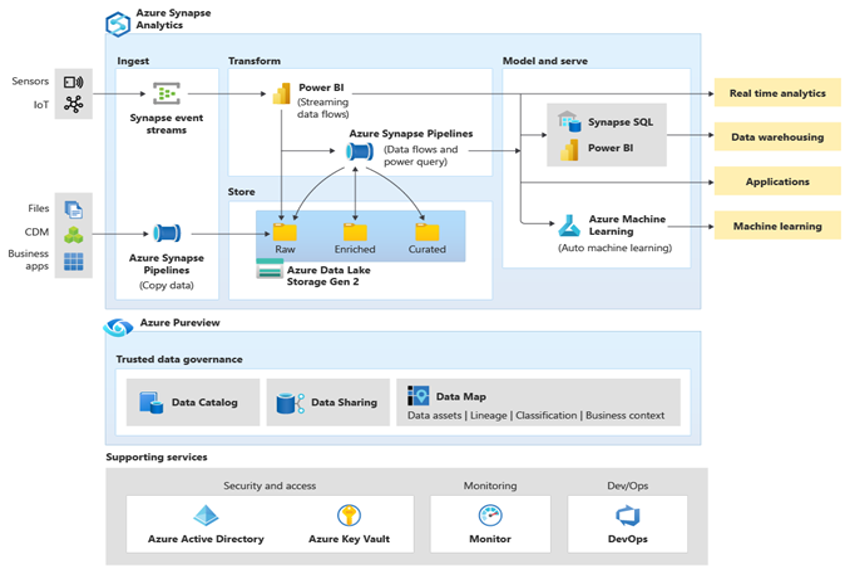
Azure Synapse Analytics 藉由使用 MPP 和針對頻繁使用資料的多個層級自動快取等技術,提供單項最佳的關聯式資料庫效能。 您可以在獨立的效能評定中看到這些技術的結果,例如 GigaOm 最近一次執行的效能評定,其將 Azure Synapse Analytics 與其他熱門的雲端資料倉儲供應項目進行比較。 移轉至 Azure Synapse Analytics 環境的客戶會看到許多優點,包括:
改善的效能與性價比。
增加靈活度和較短的價值時間。
較快的伺服器部署和應用程式開發。
彈性可擴縮性—僅需支付實際使用量的費用。
改善的安全性/合規性。
降低儲存和災害復原的成本。
降低整體 TCO、更好的成本控制,以及簡化的營運支出 (OPEX)。
若要充散發揮這些優點,請將新的和現有的資料與應用程式移轉至 Azure Synapse Analytics 平台中。 在許多組織中,移轉包括將現有的資料倉儲從舊版內部部署平台 (例如 Netezza) 移至 Azure Synapse Analytics。 概括而言,移轉流程包含下列步驟:
準備 🡆
定義範圍:要移轉的內容。
建置要移轉的資料和程序詳細目錄。
定義資料模型變更 (若有的話)。
定義來源資料擷取機制。
識別要使用的適當 Azure 和第三方工具與功能。
盡早在新平台上培訓員工。
設定 Azure 目標平台。
移轉 🡆
從小規模且簡單的內容著手。
盡可能自動化。
使用 Azure 內建工具和功能來減少移轉工作。
遷移資料表和檢視的中繼資料。
移轉要維護的歷史資料。
遷移或重構預存程序和業務流程。
遷移或重構 ETL/ELT 增量負載流程。
移轉後工作
監視並記錄程序的所有階段。
使用獲得的經驗為將來的移轉建置範本。
視需要重新設計資料模型 (使用新的平台效能和可擴縮性)。
測試應用程式和查詢工具。
基準和最佳化查詢效能。
本文提供將資料倉儲從現有 Netezza 環境移轉至 Azure Synapse Analytics 時的效能最佳化一般資訊和指引。 效能最佳化的目標是在結構描述移轉之後,於 Azure Synapse Analytics 中達到相同或更好的資料倉儲效能。
設計考量
移轉範圍
當您準備從 Netezza 環境移轉時,請考慮下列移轉選擇。
選擇初始移轉的工作負載
一般而言,舊版 Netezza 環境會隨著時間的推移而演變,以涵蓋多個主題區域和混合的工作負載。 當您決定要從何處開始移轉專案時,請選擇能夠達到下列條件的區域:
透過快速提供新環境的優勢,證明遷移至 Azure Synapse 的可行性。
可讓內部技術人員透過移轉其他區域時所使用的程序和工具,獲得相關體驗。
建立範本,以進一步執行特定於來源 Netezza 環境,以及目前已就緒工具和程序的移轉。
從 Netezza 環境進行初始移轉的良好候選區域應支援上述項目,以及:
實作 BI/分析工作負載,而不是線上交易處理 (OLTP) 工作負載。
具有資料模型,例如可以透過最少修改進行移轉的星型或雪花式結構描述。
提示
建立需要移轉的物件詳細目錄,並記錄移轉程序。
初始移轉中移轉的資料量應該夠大,才能示範 Azure Synapse Analytics 環境的功能和優點,但也不能太大而無法快速展現價值。 1-10 TB 範圍內的大小是典型大小。
針對初始移轉專案,將風險、投入和移轉時間降至最低,以便快速查看 Azure 雲端環境的優點。 隨即轉移和階段式移轉方法會將初始移轉的範圍限制為只有資料超市,而不處理更廣泛的移轉層面,例如 ETL 移轉和歷史資料移轉。 不過,一旦移轉的資料超市層回填資料和必要的建置程序之後,您就可以在專案的稍後階段中處理那些層面。
隨即轉移移轉與階段式方法
一般而言,不論計劃的移轉目的和範圍為何,移轉都有兩種類型:隨即轉移及包含變更的階段式方法。
隨即轉移
在隨即轉移中,現有的資料模型 (例如星型結構描述) 會依原樣移轉至新的 Azure Synapse Analytics 平台。 此方法只需少量工作就能實現移至 Azure 雲端環境的優點,進而將風險和移轉時間降到最低。 隨即轉移移轉適合下列案例:
- 您的現有 Netezza 環境只有單一資料超市要移轉,或
- 您有現有的 Netezza 環境,其資料已位於設計完善的星形或雪花式結構描述中,或
- 您有移至新式雲端環境的時間和成本壓力。
提示
隨即轉移是不錯的起點,即使後續階段會實作資料模型的變更也一樣。
納入變更的階段式方法
如果舊版資料倉儲已發展很長一段時間,您可能需要重新設計以維持所需的效能等級。 您可能也必須重新設計來支援新的資料,例如物聯網 (IoT) 資料流。 在重新設計的程序中,移轉至 Azure Synapse Analytics 可受益於可調整的雲端環境。 移轉可能也包括基礎資料模型中的變更,例如從 Inmon 模型移至資料保存庫。
Microsoft 建議將現有的資料模型依原樣移至 Azure,並使用 Azure 環境的效能和彈性來套用重新設計的變更。 如此一來,您就可以使用 Azure 的功能進行變更,而不會影響現有的來源系統。
使用 Azure Data Factory 來實作中繼資料驅動的移轉
您可以透過使用 Azure 環境的功能來自動化和協調移轉程序。 此方法會盡可能減少對現有 Netezza 環境的效能影響,該環境可能已接近執行容量的上限。
Azure Data Factory 是一項雲端式資料整合服務,可支援在雲端建立資料驅動工作流程,以便協調及自動進行資料移動和資料轉換。 您可以使用 Data Factory 建立並排定資料驅動的工作流程 (管線),以從不同的資料存放區內嵌資料。 透過使用計算服務 (例如 Azure HDInsight Hadoop、Spark、Azure Data Lake Analytics 和 Azure Machine Learning),Data Factory 可以處理或轉換資料。
當您打算使用 Data Factory 設施來管理移轉程序時,請建立中繼資料,列出要移轉的所有資料表及其位置。
Netezza 和 Azure Synapse 之間的設計差異
如先前所述,Netezza 與 Azure Synapse Analytics 資料庫之間有部分方法上的基本差異,而我們接下來會討論這些差異。
多個資料庫與單一資料庫和結構描述
Netezza 環境通常包含多個不同的資料庫。 例如,可能有不同的資料庫用於:資料擷取和暫存表格、核心倉儲資料表和資料超市 (有時稱為語意層)。 ETL 或 ELT 管線處理可能會實作跨資料庫聯結,並在不同的資料庫之間移動資料。
相反地,Azure Synapse Analytics 環境包含單一資料庫,並使用結構描述將資料表分成邏輯上的個別群組。 我們建議您使用目標 Azure Synapse Analytics 資料庫內的一系列結構描述,以模擬從 Netezza 環境移轉的個別資料庫。 如果 Netezza 環境已使用結構描述,當您將現有 Netezza 資料表和檢視移至新的環境時,您可能需要使用新的命名慣例。 例如,您可以將現有的 Netezza 結構描述和資料表名稱串連到新的 Azure Synapse Analytics 資料表名稱中,然後在新環境中使用結構描述名稱來維護原始的單獨資料庫名稱。 如果結構描述合併命名有小數點,則 Azure Synapse Spark 可能會有問題。 雖然您可以使用基礎資料表上的 SQL 檢視來維護邏輯結構,但該方法有一些潛在的缺點:
Azure Synapse Analytics 中的檢視僅供唯讀,因此必須在基礎基底資料表上更新任何資料。
可能已經存在一或多個檢視層,但因為難以針對巢狀檢視進行疑難排解,所以新增額外的檢視層可能會影響效能和支援性。
秘訣
將多個資料庫結合成 Azure Synapse Analytics 中的單一資料庫,並使用結構描述名稱以邏輯方式分隔資料表。
資料表考量
當您在不同環境之間移轉資料表時,通常只有原始資料和描述其實際移轉的中繼資料。 來源系統的其他資料庫元素 (例如索引) 通常不會移轉,因為它們在新的環境中可能不必要,或會以不同的方式實作。
來源環境中的效能最佳化 (例如索引) 會指出您可以在新環境中新增效能最佳化的位置。 例如,如果來源 Netezza 環境中的查詢經常使用區域對應,則建議在 Azure Synapse Analytics 內建立非叢集索引。 其他原生效能最佳化技術 (如資料表複寫),可能比直接建立「類似」索引更為適用。
秘訣
現有的索引會指出已移轉倉儲中用於編製索引的候選項目。
未經支援的 Netezza 資料庫物件類型
Netezza 特定功能通常可以由 Azure Synapse Analytics 功能取代。 但是,有些 Netezza 資料庫物件未受 Azure Synapse Analytics 直接支援。 下列不支援的 Netezza 資料庫物件清單,說明如何在 Azure Synapse Analytics 中達成對等的功能。
區域對應:在 Netezza 中,系統會自動為下列資料行類型建立與維護區域對應,並在查詢時用來限制要掃描的資料量:
INTEGER的長度為 8 位元或更少。- 時態性資料行,例如
DATE、TIME和TIMESTAMP。 CHAR資料行 (如果其為具體化檢視的一部分,並在ORDER BY子句中提及)。
您可以使用
nz_zonemap公用程式找出哪些資料行具有區域對應,此屬於 NZ 工具組的功能。 Azure Synapse Analytics 不會包含區域對應,但您可以使用其他使用者定義索引類型和/或資料分割達到相似的結果。叢集基底資料表 (CBT):在 Netezza 中,CBT 通常用於事實資料表,事實資料表可以擁有數十億筆記錄。 因為可能需要進行完整的資料表掃描才能取得相關記錄,所以掃描如此龐大的資料表需要可觀的處理時間。 限制性 CBT 上的組織記錄可讓 Netezza 將相同或鄰近範圍的記錄分組。 此程序也會建立區域對應,藉由減少需要掃描的資料量來提升效能。
在 Azure Synapse Analytics 中,您可以藉由資料分割和/或使用其他索引來達到類似的效果。
具體化檢視:Netezza 支援具體化檢視,並建議針對具有許多資料行的大型資料表 (若查詢中只會定期使用幾個資料行),使用一個以上具體化檢視。 當基底資料表的資料已更新時,系統會自動重新整理具體化檢視。
Azure Synapse Analytics 支援具體化檢視,其功能與 Netezza 相同。
Netezza 資料類型對應
大部分的 Netezza 資料類型在 Azure Synapse Analytics 中都有直接的對等用法。 下列資料表顯示將 Netezza 資料類型對應到 Azure Synapse Analytics 的建議方法。
| Netezza 資料類型 | Azure Synapse Analytics 資料類型 |
|---|---|
| bigint | bigint |
| BINARY VARYING(n) | VARBINARY(n) |
| BOOLEAN | BIT |
| BYTEINT | TINYINT |
| CHARACTER VARYING(n) | VARCHAR(n) |
| CHARACTER(n) | CHAR(n) |
| 日期 | DATE(date) |
| DECIMAL(p,s) | DECIMAL(p,s) |
| DOUBLE PRECISION | FLOAT |
| FLOAT(n) | FLOAT(n) |
| INTEGER | INT |
| INTERVAL | Azure Synapse Analytics 目前不支援 INTERVAL 資料類型,但可以使用 DATEDIFF 等時態性函數來計算。 |
| MONEY | MONEY |
| NATIONAL CHARACTER VARYING(n) | NVARCHAR(n) |
| NATIONAL CHARACTER(n) | NCHAR(n) |
| NUMERIC(p,s) | NUMERIC(p,s) |
| REAL | REAL |
| SMALLINT | SMALLINT |
| ST_GEOMETRY(n) | Azure Synapse Analytics 目前不支援如 ST_GEOMETRY 的空間資料類型,但資料可以儲存為 VARCHAR 或 VARBINARY。 |
| TIME | TIME |
| TIME WITH TIME ZONE | DATETIMEOFFSET |
| timestamp | DATETIME |
秘訣
在移轉準備階段評估不支援的資料類型數目和類型。
第三方廠商會提供工具和服務來自動化移轉,包括資料類型的對應。 若您已在 Netezza 環境中使用第三方 ETL 工具,請使用此工具來實作任何必要的資料轉換。
SQL DML 語法差異
Netezza SQL 與 Azure Synapse T-SQL 之間存在 SQL DML 語法差異。 這些差異會在將 Netezza 移轉的 SQL 問題最小化中詳細討論。
STRPOS:在 Netezza 中,該STRPOS語言函式會傳回字串內子字串的位置。 Azure Synapse Analytics 中的對等函式是CHARINDEX,且引數的順序會反轉。 例如,Netezza 中的SELECT STRPOS('abcdef','def')...相當於 Azure Synapse Analytics 中的SELECT CHARINDEX('def','abcdef')...。AGE:Netezza 支援該AGE運算子來提供兩個時態值之間的間隔 (如時間戳記或日期,例如:SELECT AGE('23-03-1956','01-01-2019') FROM...)。 在 Azure Synapse Analytics 中,使用DATEDIFF來取得間隔,例如:SELECT DATEDIFF(day, '1956-03-26','2019-01-01') FROM...。 請注意日期表示序列。NOW(): Netezza 會在 Azure Synapse 中使用NOW()來代表CURRENT_TIMESTAMP。
函數、預存程序及序列
從 Netezza 之類的成熟環境移轉資料倉儲時,您可能需要移轉簡單資料表和檢視以外的元素。 檢查 Azure 環境中的工具是否可以取代函式、預存程序和序列的功能,因為比起為了 Azure Synapse Analytics 重新編碼這些元素,使用內建 Azure 工具通常更有效率。
在準備階段中,請建立需要移轉的物件詳細目錄、定義處理這些物件的方法,並在移轉計劃中配置適當的資源。
資料整合合作夥伴提供的工具和服務可將函式、預存程序及序列移轉自動化。
下列各節會進一步討論函式、預存程序和序列的移轉。
函式
與大多數資料庫產品相同,Netezza 支援 SQL 實作中的系統函式和使用者定義函式。 當您將舊版資料庫平台移轉至 Azure Synapse Analytics 時,通常不需要變更即可移轉一般系統函式。 部分系統函式的語法可能稍有不同,但仍可以將必要的變更自動化。
針對在 Azure Synapse Analytics 中沒有對等項目的 Netezza 系統函式或任意使用者定義函式,請使用目標環境語言重新編碼這些函式。 Netezza 使用者定義函式是以 nzLua 或 C++ 語言來撰寫程式碼。 Azure Synapse Analytics 會使用 Transact-SQL 語言來實作使用者定義函式。
預存程序
大部分的新式資料庫產品,都支援在資料庫中儲存程序。 基於此目的,Netezza 提供以 Postgres PL/pgSQL 為基礎的 NZPLSQL 語言。 預存程序通常包含 SQL 陳述式和程序邏輯,且會傳回資料或狀態。
Azure Synapse Analytics 支援使用 T-SQL 的預存程序,因此您必須以該語言重新編碼任何已移轉的預存程序。
序列
在 Netezza 中,序列是使用 CREATE SEQUENCE 所建立的具名資料庫物件。 序列透過 NEXT VALUE FOR 方法提供唯一的數值。 您可以使用產生的唯一數字,作為主索引鍵值的代理索引鍵值。
Azure Synapse Analytics 不會實作 CREATE SEQUENCE,但您可以使用 IDENTITY 資料行或 SQL 程式碼來實作序列,以產生數列中的下一個序號。
從 Netezza 環境擷取中繼資料和資料
產生資料定義語言 (DDL)
ANSI SQL 標準會定義資料定義語言 (DDL) 命令的基本語法。 Netezza 和 Azure Synapse Analytics 等一些 CREATE TABLECREATE VIEW DDL 命令很常見,但已延伸以提供實作特定的功能。
您可以編輯現有的 Netezza CREATE TABLE 和 CREATE VIEW 指令碼,以在 Azure Synapse Analytics 中達成對等的定義。 若要這樣做,您可能需要使用修改過的資料類型,並移除或修改 Netezza 特定子句,例如 ORGANIZE ON。
在 Netezza 環境中,系統目錄資料表會指定目前的資料表和檢視定義。 與使用者維護的文件不同,系統類別目錄資訊一律是完整的,且與目前的資料表定義同步。 您可以藉由使用 nz_ddl_table 之類的公用程式來存取系統目錄資訊,以產生在 Azure Synapse Analytics 中建立對等資料表的 CREATE TABLE DDL 陳述式。
您也可以使用第三方的移轉和 ETL 工具來處理系統目錄資訊,以達到類似的結果。
從 Netezza 擷取資料
您可以使用標準 Netezza 公用程式,例如 nzsql 和 nzunload,或透過外部資料表,從 Netezza 資料表擷取原始資料表資料到一般分隔的檔案,例如 CSV 檔案。 然後,您可以使用 gzip 壓縮一般分隔檔案,並使用 AzCopy 或 Azure 資料箱之類的 Azure 資料傳輸工具,將壓縮的檔案上傳至 Azure Blob 儲存體。
盡可能有效率地擷取資料表資料。 使用外部資料表方法,因為它是最快的擷取方法。 請以平行方式執行多個擷取,以最大化資料擷取輸送量。 下列 SQL 陳述式會執行外部資料表擷取:
CREATE EXTERNAL TABLE '/tmp/export_tab1.csv' USING (DELIM ',') AS SELECT * from <TABLENAME>;
如果有足夠的網路頻寬可用,您可以將資料從內部部署 Netezza 系統直接擷取到 Azure Synapse Analytics 資料表或 Azure Blob 資料儲存體。 若要這樣做,請使用 Data Factory 處理序或 第三方資料移轉或 ETL 產品。
秘訣
使用 Netezza 外部資料表進行最有效率的資料擷取。
擷取的資料檔案應該包含 CSV、最佳化資料列單欄式 (ORC) 或 Parquet 格式的分隔文字。
如需從 Netezza 環境移轉資料和 ETL 的詳細資訊,請參閱適用於 Netezza 移轉的資料移轉、ETL 和負載。
Netezza 移轉的效能建議
效能最佳化的目標,是在移轉至 Azure Synapse Analytics 之後獲得相同或更好的資料倉儲效能。
效能微調方法概念的相似性
Netezza 資料庫的許多效能微調概念同樣適用於 Azure Synapse Analytics 資料庫。 例如:
使用資料散發將要聯結的資料集中至相同處理節點上。
使用指定資料行的最小資料類型可節省儲存體空間,並加速查詢流程。
請確定要聯結的資料行具有相同的資料類型,以利最佳化聯結處理,並減少資料轉換的需求。
為協助最佳化工具產生最適合的執行計畫,請確保統計資料是最新的。
使用內建資料庫功能監視效能,以確保有效率地使用資源。
秘訣
在移轉開始時,優先熟悉 Azure Synapse Analytics 微調選項。
效能微調方法的差異
本節強調 Netezza 與 Azure Synapse Analytics 之間的低階效能微調實作差異。
資料散發選項
為了提高效能,Azure Synapse Analytics 設計為使用多節點架構,並使用平行處理。 若要最佳化資料表效能,您可以在 Azure Synapse Analytics 中使用 DISTRIBUTION 和 Netezza 的 DISTRIBUTE ON 來定義 CREATE TABLE 陳述式內資料散發選項。
不同於 Netezza,Azure Synapse Analytics 支援透過小型資料表複寫,在小型資料表與大型資料表之間進行本機聯結。 例如,星形結構描述模型中的小型維度資料表和大型事實資料表。 Azure Synapse Analytics 可以跨所有節點複寫較小的維度資料表,以確保大型資料表的任何聯結索引鍵值都有相符的本機可用維度資料列。 小型維度資料表的維度資料表複寫額外負荷相對較低。 對於大型維度資料表來說,雜湊散發方法更合適。 如需資料散發選項的詳細資訊,請參閱使用複寫資料表的設計指引和設計分散式資料表的指引。
資料的索引編製
相較於 Netezza 中的系統管理區域對應,Azure Synapse Analytics 支援數個使用者可定義的索引選項,這些選項具有不同的作業和使用方式。 如需 Azure Synapse Analytics 中不同編製索引選項的詳細資訊,請參閱專用 SQL 集區資料表上的索引。
來源 Oracle 環境內的現存系統管理區域對應,提供資料使用量和候選資料行的實用指示,可用於在 Azure Synapse Analytics 環境中編製索引。
資料分割
在企業資料倉儲中,事實資料表可能包含數十億個資料列。 資料分割可最佳化這些資料表的維護和查詢效能,因為將這些資料表分割成不同的部分可減少所處理資料量。 在 Azure Synapse Analytics 中,CREATE TABLE 陳述式會定義資料表的分割規格。
每個資料表只能使用一個欄位進行資料分割。 該欄位通常是日期欄位,因為許多查詢都會依日期或日期範圍進行篩選。 您可以在初始載入之後變更資料表的分割,只要使用 CREATE TABLE AS (CTAS) 陳述式以新的散發來重新建立資料表即可。 如需 Azure Synapse Analytics 中資料分割的詳細說明,請參閱專用 SQL 集區中的資料分割資料表。
資料表統計資料
您應藉由在 ETL/ELT 作業的統計資料步驟中建置統計資料,以確保資料表上的統計資料為最新。
用於載入資料的 PolyBase 或 COPY INTO
PolyBase 支援使用平行載入資料流,有效率地將大量資料載入至資料倉儲。 如需詳細資訊,請參閱 PolyBase 資料載入策略。
COPY INTO 也支援高輸送量的資料擷取,以及:
從資料夾和子資料夾內的所有檔案中擷取資料。
從相同儲存體帳戶中的多個位置中擷取資料。 您可以使用逗號分隔路徑來指定多個位置。
Azure Data Lake Storage (ADLS) 和 Azure Blob 儲存體。
CSV、PARQUET 和 ORC 檔案格式。
工作負載管理
執行混合工作負載可能會造成忙碌系統上的資源挑戰。 成功的工作負載管理配置可有效地管理資源、確保高效率的資源使用率,以及最大化的投資報酬率 (ROI)。 工作負載分類、工作負載重要性和工作負載隔離可更充分地控制工作負載如何利用系統資源。
工作負載管理指南會說明分析工作負載、管理和監視工作負載重要性的技術,以及將資源類別轉換為工作負載群組的步驟。 使用 Azure 入口網站和 DMV 上的 T-SQL 查詢來監視工作負載,以確保有效率地利用適用資源。
下一步
若要了解 Netezza 移轉的 ETL 和負載,請參閱本系列中的下一篇文章:適用於 Netezza 移轉的資料移轉、ETL 和負載。