在 Azure Synapse Analytics 中建立、開發和維護 Synapse Notebook
Synapse 筆記本是一個 Web 介面,可讓您建立包含即時程式代碼、視覺效果和敘述文字的檔案。 筆記本是驗證想法和使用快速實驗從您的資料取得見解的絕佳位置。 筆記本也廣泛用於資料準備、資料視覺效果、機器學習和其他巨量資料案例中。
使用 Synapse 筆記本,您可以:
- 開始使用零設定工作。
- 使用內建企業安全性功能保護數據安全。
- 分析原始格式的數據(CSV、txt、JSON 等)、已處理檔格式(parquet、Delta Lake、ORC 等),以及針對 Spark 和 SQL 的 SQL 表格式數據檔。
- 透過增強的撰寫功能和內建數據視覺效果,提高生產力。
本文說明如何在 Synapse Studio 中使用筆記本。
建立筆記本
有兩種方式可以建立筆記本。 您可以建立新的筆記本,或從 物件總管 將現有的筆記本匯入至 Synapse 工作區。 Synapse Notebook 可辨識標準 Jupyter Notebook IPYNB 檔案。

開發筆記本
筆記本是由儲存格所組成,這些儲存格是個別的程式代碼或文字區塊,可以獨立執行或以群組形式執行。
我們提供豐富的作業來開發筆記本:
- 新增儲存格
- 設定主要語言
- 使用多種語言
- 使用臨時表跨語言參考數據
- IDE 樣式 IntelliSense
- 程式碼片段
- 使用工具列按鈕格式化文字儲存格
- 復原/取消復原單元格作業
- 程式代碼儲存格批註
- 移動儲存格
- 刪除儲存格
- 折疊儲存格輸入
- 折疊單元格輸出
- 筆記本大綱
注意
在筆記本中,會自動為您建立SparkSession,儲存在名為的 spark變數中。 另外還有SparkContext的變數,稱為 sc。 使用者可以直接存取這些變數,而且不應該變更這些變數的值。
新增儲存格
有多種方式可將新單元格新增至筆記本。
將滑鼠停留在兩個儲存格之間的空間上,然後選取 [程序代碼] 或 [Markdown]。
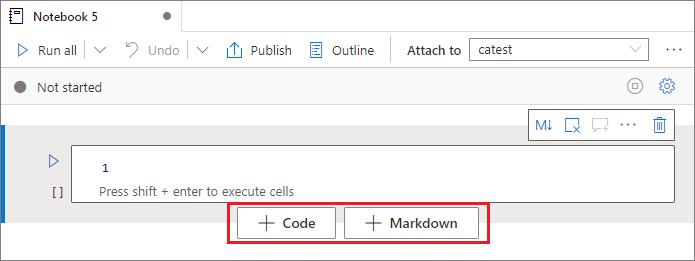
在命令模式下使用 aznb 快速鍵。 按 A 鍵,將儲存格插入目前儲存格上方。 按 B 鍵,將儲存格插入目前儲存格下方。
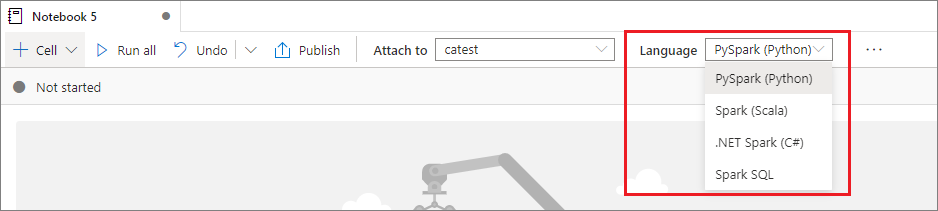
設定主要語言
Synapse Notebook 支援四種 Apache Spark 語言:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
您可以從頂端命令列的下拉式清單中設定新新增儲存格的主要語言。
使用多種語言
您可以在一個筆記本中使用多種語言,方法是在單元格開頭指定正確的語言 magic 命令。 下表列出切換單元格語言的magic命令。
| Magic 命令 | 語言 | 描述 |
|---|---|---|
| %%pyspark | Python | 針對 Spark 內容執行 Python 查詢。 |
| %%spark | Scala | 針對 Spark 內容執行 Scala 查詢。 |
| %%sql | SparkSQL | 針對 Spark 內容執行 SparkSQL 查詢。 |
| %%csharp | 適用於 Spark C 的 .NET# | 針對 Spark 內容執行適用於 Spark C# 查詢的 .NET。 |
| %%sparkr | R | 針對 Spark 內容執行 R 查詢。 |
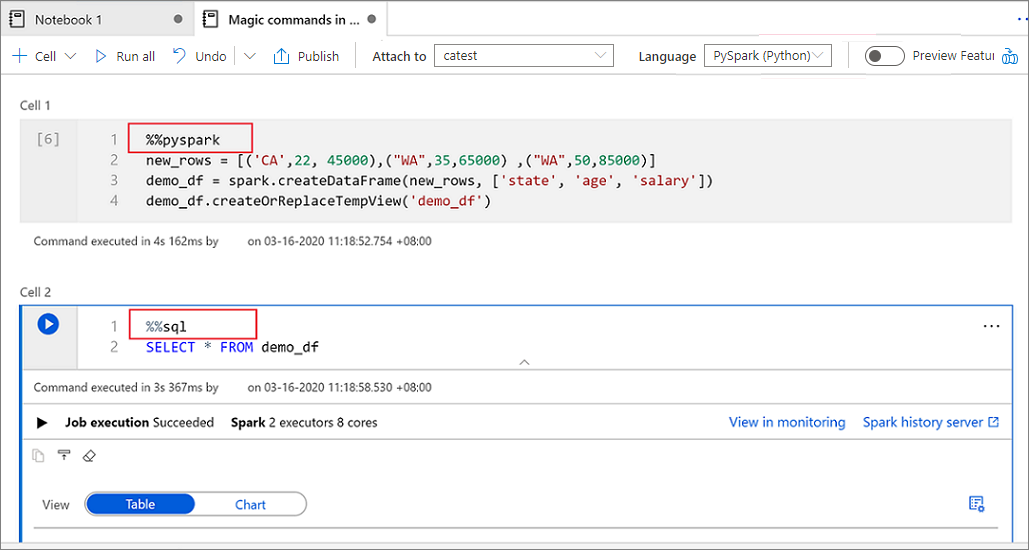
下圖是如何使用 %%pyspark magic 命令或 SparkSQL 查詢搭配 Spark(Scala) 筆記本中的 %%sql magic 命令來撰寫 PySpark 查詢的範例。 請注意,筆記本的主要語言設定為 pySpark。
使用臨時表跨語言參考數據
您無法直接在 Synapse 筆記本中跨不同語言參考數據或變數。 在Spark中,可以跨語言參考臨時表。 以下是如何在 中使用 PySpark Spark 暫存數據表作為因應措施讀取 Scala DataFrame的SparkSQL範例。
在單元格 1 中,使用 Scala 從 SQL 集區連接器讀取 DataFrame,並建立臨時表。
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )在儲存格 2 中,使用 Spark SQL 查詢數據。
%%sql SELECT * FROM mydataframetable在儲存格 3 中,使用 PySpark 中的數據。
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
IDE 樣式 IntelliSense
Synapse 筆記本會與摩納哥編輯器整合,將 IDE 樣式的 IntelliSense 帶入數據格編輯器。 語法醒目提示、錯誤標記和自動程式代碼完成可協助您撰寫程式碼並更快識別問題。
IntelliSense 功能在不同語言的不同成熟度層級。 使用下表來查看支援的專案。
| 語言 | 語法醒目提示 | 語法錯誤標記 | 語法程序代碼完成 | 變數程序代碼完成 | 系統函式程式碼完成 | 使用者函式程式碼完成 | 智慧縮排 | 程式代碼折疊 |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Yes | .是 | .是 | .是 | .是 | .是 | .是 | Yes |
| Spark (Scala) | Yes | .是 | .是 | .是 | .是 | .是 | - | Yes |
| SparkSQL | Yes | .是 | .是 | .是 | Yes | - | - | - |
| 適用於 Spark 的 .NET (C#) | Yes | .是 | .是 | .是 | .是 | .是 | .是 | 是 |
注意
需要作用中的Spark會話,才能讓變數程式代碼完成、系統函式程式碼完成、適用於Spark的 .NET使用者函式程式碼完成 (C#)。
程式碼片段
Synapse 筆記本提供代碼段,可讓您更輕鬆地輸入常用的程式代碼模式,例如設定 Spark 會話、將數據讀取為 Spark 數據框架,或使用 matplotlib 繪製圖表等。
代碼段會出現在 IDE 樣式 IntelliSense 的快速鍵中,與其他建議混合。 代碼段內容會與程式代碼數據格語言一致。 您可以在代碼格編輯器的代碼段標題中輸入 Snippet 或任何關鍵字來查看可用的代碼段。 例如,藉由輸入 read ,您可以看到從各種數據源讀取資料的代碼段清單。

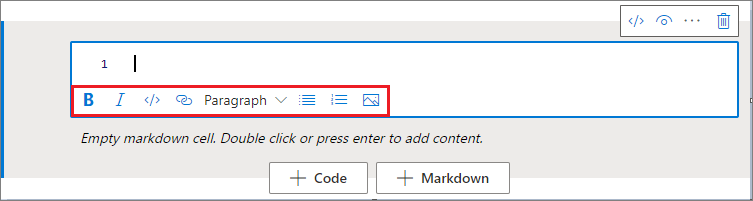
使用工具列按鈕格式化文字儲存格
您可以使用文字儲存格工具列中的格式按鈕來執行常見的 Markdown 動作。 它包含粗體文字、斜體文字、透過下拉式清單、插入程式代碼、插入未排序的清單、插入已排序的清單、插入超連結,以及從URL插入影像。
復原/取消復原單元格作業
選取 [復原重做] / 按鈕,或按 Z / Shift+Z 以撤銷最新的單元格作業。 現在,您最多可以復原/重做最新的 10 個歷程記錄數據格作業。

支援的復原儲存格作業:
- 插入/刪除儲存格:您可以選取 [復原] 來撤銷刪除作業,文字內容會與儲存格一起保留。
- 重新排序儲存格。
- Toggle 參數。
- 在 Code 儲存格與 Markdown 儲存格之間轉換。
注意
儲存格內文字作業和程式碼數據格批注作業無法復原。 現在,您最多可以復原/重做最新的 10 個歷程記錄數據格作業。
程式代碼儲存格批註
選取 筆記本工具列上的 [批注 ] 按鈕,以開啟 [批注 ] 窗格。
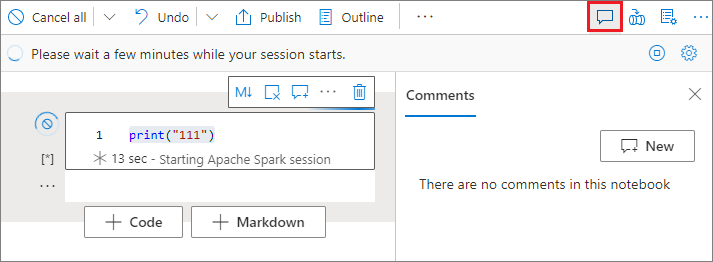
在程式代碼數據格中選取程式代碼,按兩下 [批註] 窗格中的 [新增],新增批注,然後按兩下 [張貼批註] 按鈕以儲存。
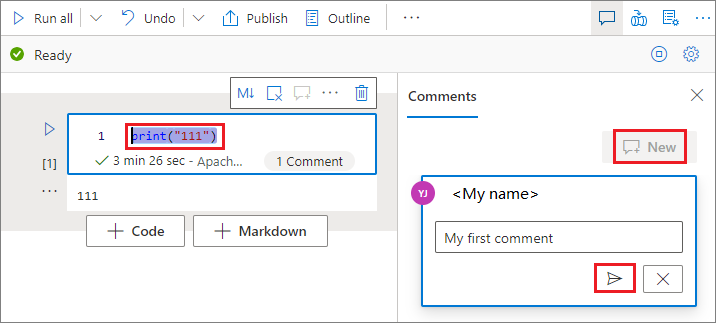
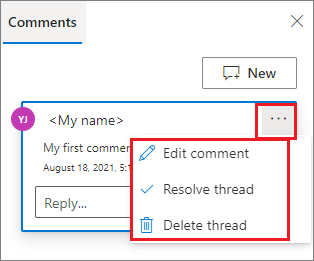
您可以按下批注以外的 [更多] 按鈕,執行 [編輯批注]、[解析線程] 或 [刪除線程]。
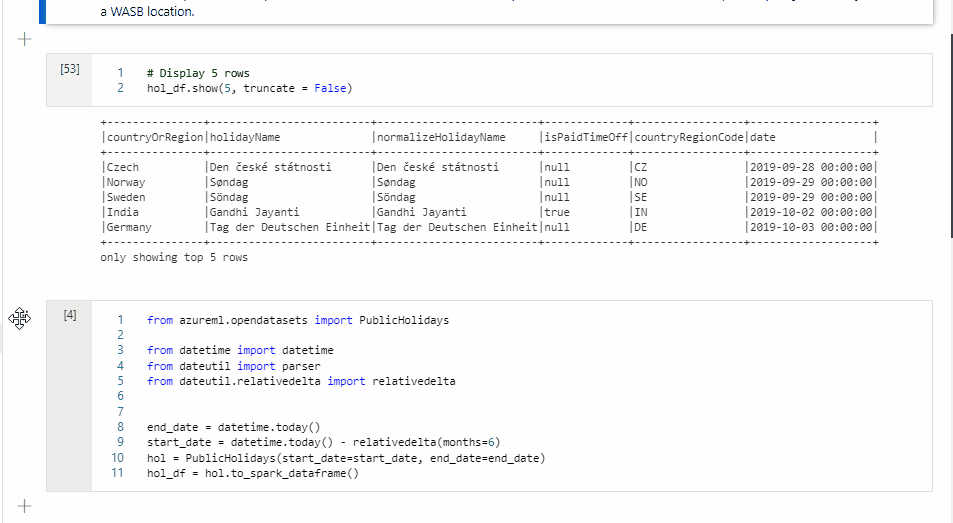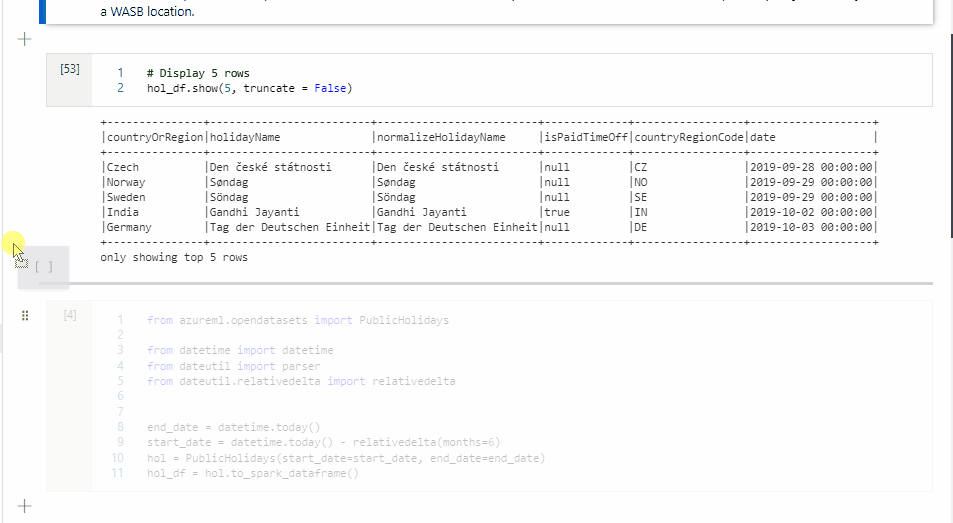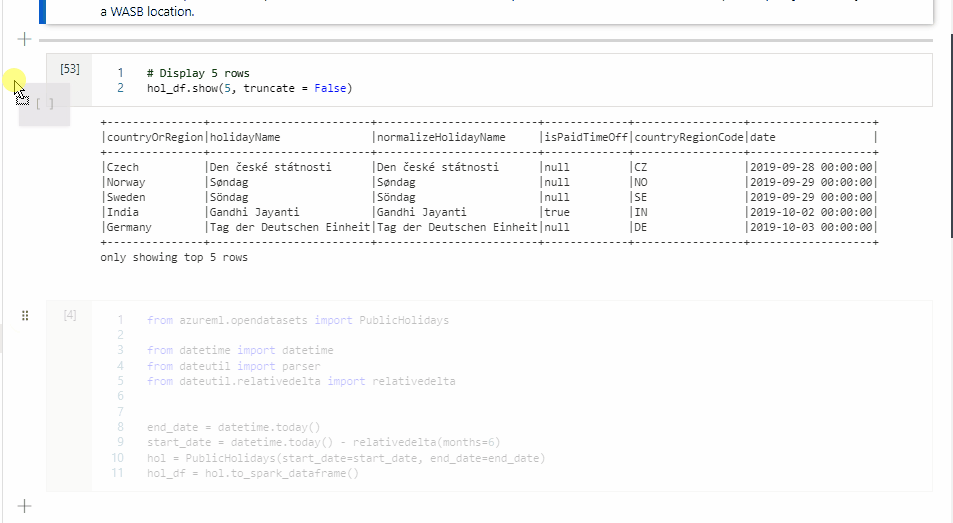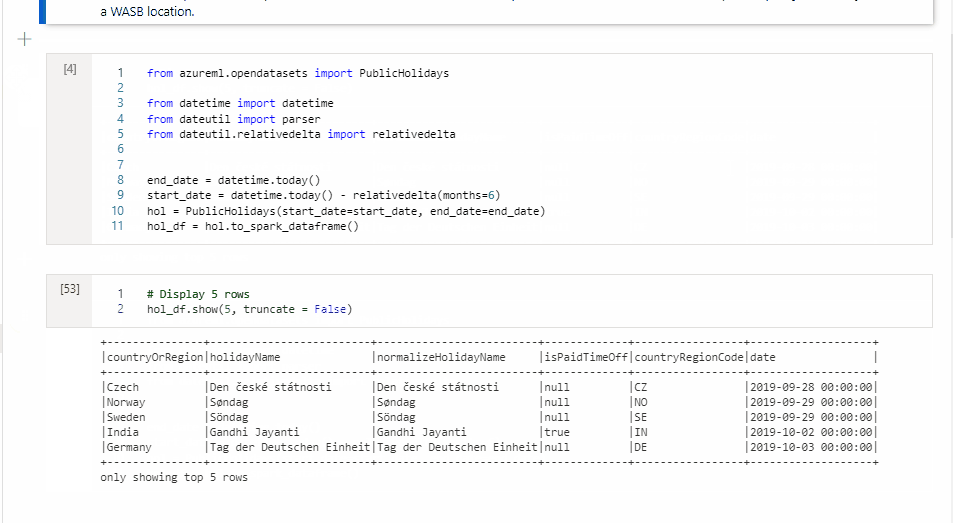
移動儲存格
按兩下格的左側,並將拖曳至所需的位置。
刪除儲存格
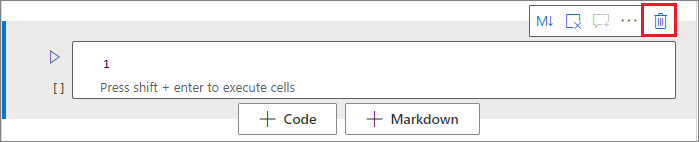
若要刪除儲存格,請選取儲存格右側的 [刪除] 按鈕。
您也可以在命令模式下使用快速鍵。 按 Shift+D 以刪除目前的儲存格。
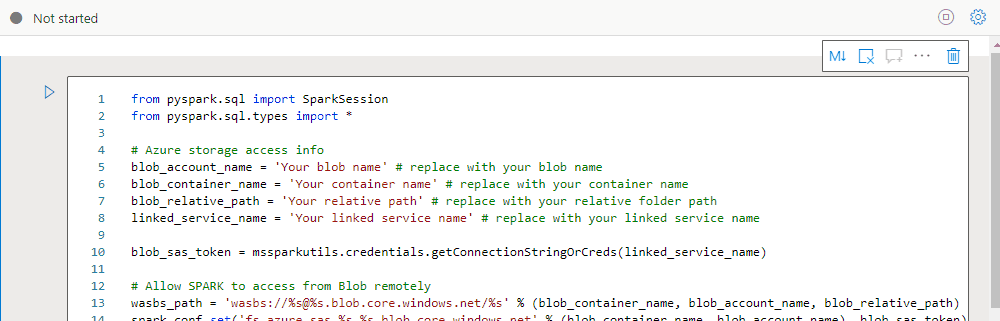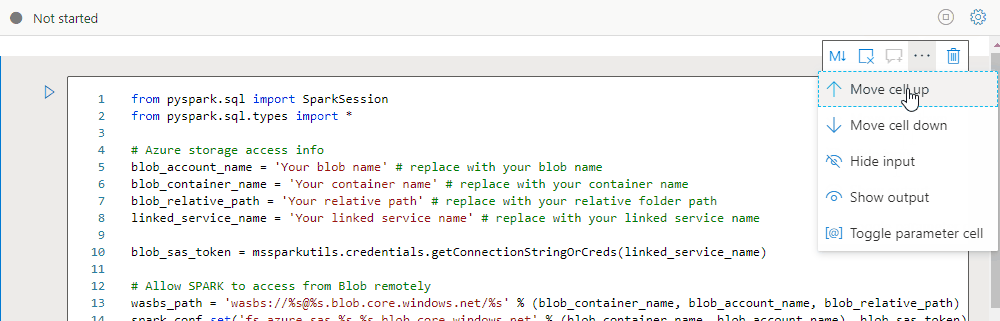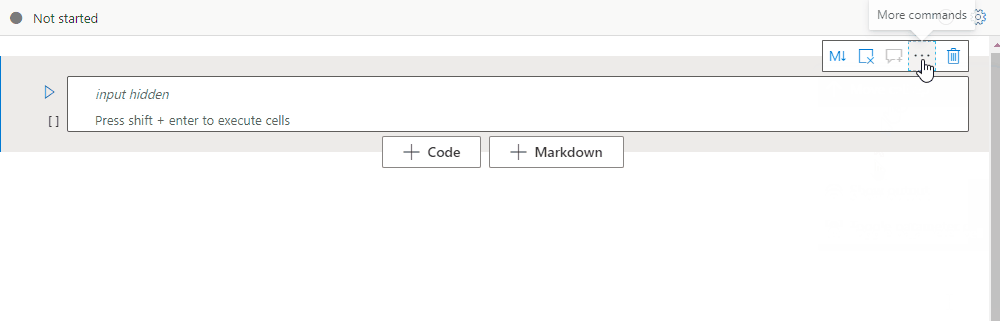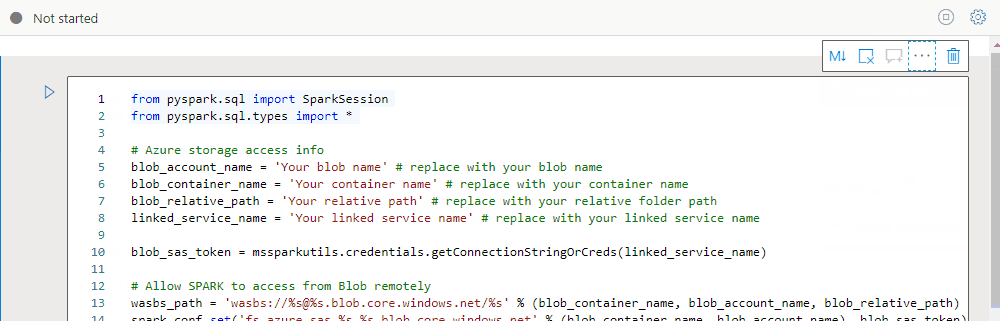
折疊儲存格輸入
選取儲存格工具列上的 [ 更多] 命令 省略號 [...],然後 選取 [隱藏輸入] 以折疊目前儲存格的輸入 。 若要展開它,請在折疊單元格時選取 [顯示輸入 ]。
折疊單元格輸出
選取儲存格工具列上的 [ 更多] 命令 省略號 [...],然後 選取 [隱藏輸出] 以折疊目前單元格的輸出 。 若要展開它,請在隱藏儲存格的輸出時選取 [顯示輸出 ]。
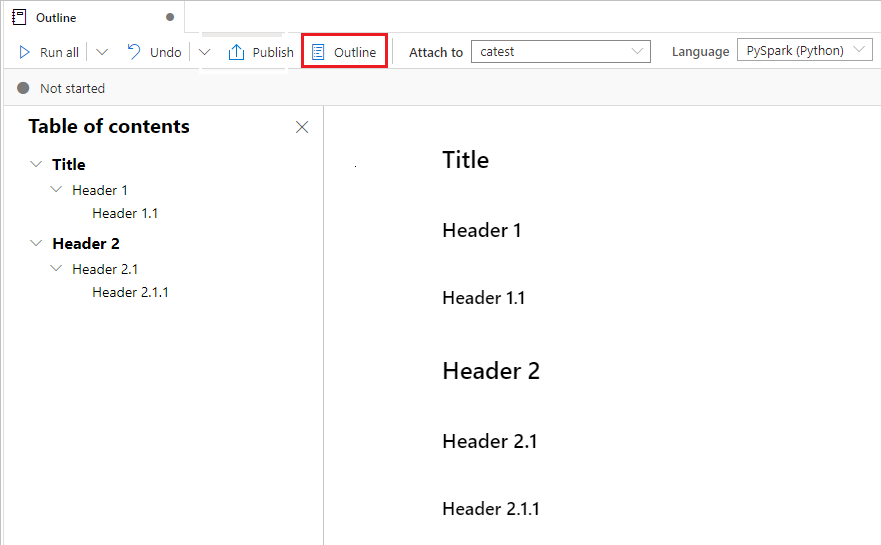
筆記本大綱
Outlines (目錄) 會在提要欄視窗中呈現任何 Markdown 單元格的第一個 Markdown 標頭,以供快速流覽。 [大綱] 提要字段可重設大小且可折疊,以盡可能以最佳方式調整螢幕大小。 您可以選取 筆記本命令行上的 [大綱 ] 按鈕,以開啟或隱藏提要字段
執行筆記本
您可以個別或一次地在筆記本中執行程式碼數據格。 每個儲存格的狀態和進度都會在筆記本中表示。
執行儲存格
有數種方式可以在儲存格中執行程序代碼。
將滑鼠停留在您要執行的儲存格上,然後選取 [ 執行儲存格 ] 按鈕或按 Ctrl+Enter。

在命令模式下使用快速鍵。 按 Shift+Enter 以執行目前的儲存格,然後選取下方的儲存格。 按 Alt+Enter 以執行目前的儲存格,並在下方插入新的儲存格。
執行所有儲存格
選取 [全部執行] 按鈕,依序執行目前筆記本中的所有儲存格。

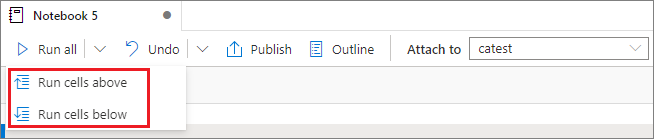
執行上方或下方的所有儲存格
從 [全部執行 ] 按鈕展開下拉式清單,然後選取 [執行上方 的數據格],以依序執行目前上方的所有單元格。 選取下方的 [執行儲存格] 以執行目前順序下的所有儲存格。
取消所有執行中的儲存格
選取 [ 全部 取消] 按鈕,取消佇列中等候的執行單元格或儲存格。

筆記本參考
您可以使用 %run <notebook path> magic命令來參考目前筆記本內容中的另一個筆記本。 參考筆記本中定義的所有變數都可在目前的筆記本中使用。 %run magic 命令支援巢狀呼叫,但不支援遞歸呼叫。 如果語句深度大於 五,您會收到例外狀況。
範例:%run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }。
筆記本參考適用於互動式模式和 Synapse 管線。
注意
%run命令目前僅支持傳遞絕對路徑或筆記本名稱做為參數,不支援相對路徑。%run命令目前僅支援 4 個參數實值類型:int不支援 、float、bool、string、變數取代作業。- 必須發佈參考的筆記本。 除非已啟用參考未發佈的筆記本,否則 您必須發佈筆記本以參考筆記本 。 Synapse Studio 無法從 Git 存放庫辨識未發佈的筆記本。
- 參考的筆記本不支援深度大於 五的語句。
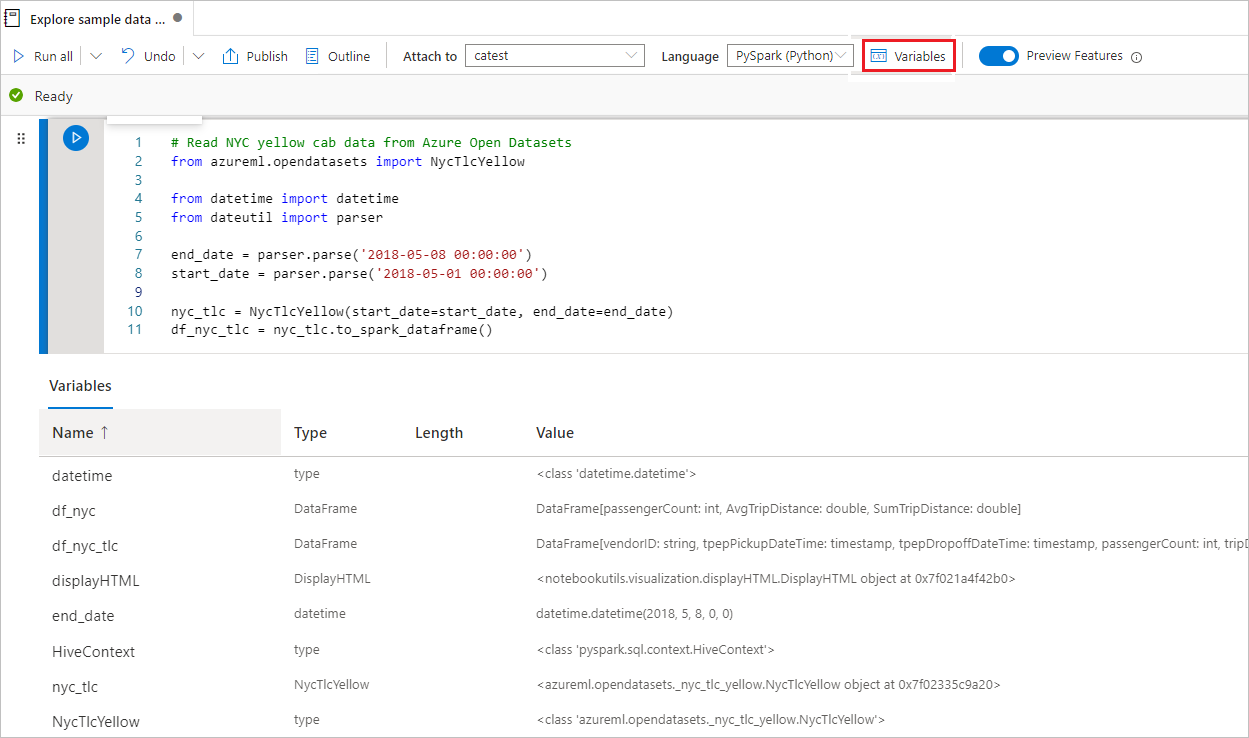
變數總管
Synapse Notebook 提供內建的變數總管,讓您查看 PySpark (Python) 單元格目前 Spark 會話中的變數名稱、類型、長度和值清單。 更多變數會在程式代碼數據格中定義時自動顯示。 按兩下每個資料列標頭會排序資料表中的變數。
您可以選取 筆記本命令行上的 [變數 ] 按鈕,以開啟或隱藏變數總管。
注意
變數總管僅支援 python。
單元格狀態指示器
數據格下會顯示逐步數據格執行狀態,以協助您查看其目前進度。 一旦數據格執行完成,就會顯示總持續時間和結束時間的執行摘要,並保留在那裡以供日後參考。

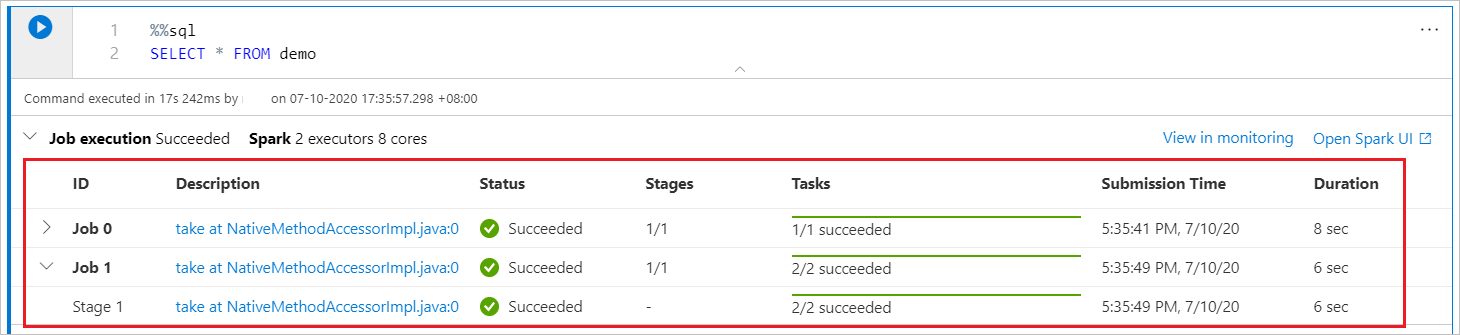
Spark 進度指示器
Synapse Notebook 純粹是以 Spark 為基礎。 程式代碼數據格會從遠端在無伺服器 Apache Spark 集區上執行。 Spark 作業進度指標會提供即時進度列,可協助您了解作業執行狀態。 每個作業或階段的工作數目可協助您找出 Spark 作業的平行層級。 您也可以透過選取作業 (或階段) 名稱上的連結,更深入鑽研特定工作 (或階段) 的 Spark UI。
Spark 會話設定
您可以指定逾時持續時間、數位和執行程式的大小,以在設定工作階段中 提供給目前的 Spark 工作階段。 重新啟動Spark會話是讓設定變更生效。 會清除所有快取的筆記本變數。
您也可以從 Apache Spark 組態建立組態,或選取現有的組態。 如需詳細資訊,請參閱 Apache Spark 組態管理。

Spark 工作階段設定 magic 命令
您也可以透過magic命令 %%configure 來指定Spark工作階段設定。 Spark 工作階段必須重新啟動,才能讓設定生效。 建議您在筆記本開頭執行 %%configure 。 以下是範例,請參閱 https://github.com/cloudera/livy#request-body 完整的有效參數清單。
%%configure
{
//You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of standard spark property, to find more available properties please visit:https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
注意
- 建議在 %%configure 中將 “DriverMemory” 和 “ExecutorMemory” 設定為相同的值,因此“driverCores” 和 “executorCores”。
- 您可以在 Synapse 管線中使用 %%configure,但如果它未在第一個程式代碼數據格中設定,管線執行將會因為無法重新啟動工作階段而失敗。
- mssparkutils.notebook.run 中使用的 %%configure 將會被忽略,但在 %run 筆記本中使用的 %%會繼續執行。
- 標準 Spark 組態屬性必須在 「conf」 主體中使用。 我們不支援Spark組態屬性的第一層參考。
- 一些特殊的 Spark 屬性,包括 “spark.driver.cores”、“spark.executor.cores”、“spark.driver.memory”、“spark.executor.memory”、“spark.executor.instances” 不會在 “conf” 主體中生效。
來自管線的參數化會話組態
參數化會話組態可讓您以管線執行 (Notebook 活動) 參數取代 %%configure magic 中的值。 準備 %%configure 程式代碼數據格時,您可以使用如下的物件覆寫預設值(也可以設定,4 和 “2000”
{
"activityParameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
如果直接在互動式模式中執行筆記本,或未從管線筆記本活動指定符合 「activityParameterName」 的參數,Notebook 就會使用預設值。
在管線執行模式期間,您可以設定管線 Notebook 活動設定,如下所示: 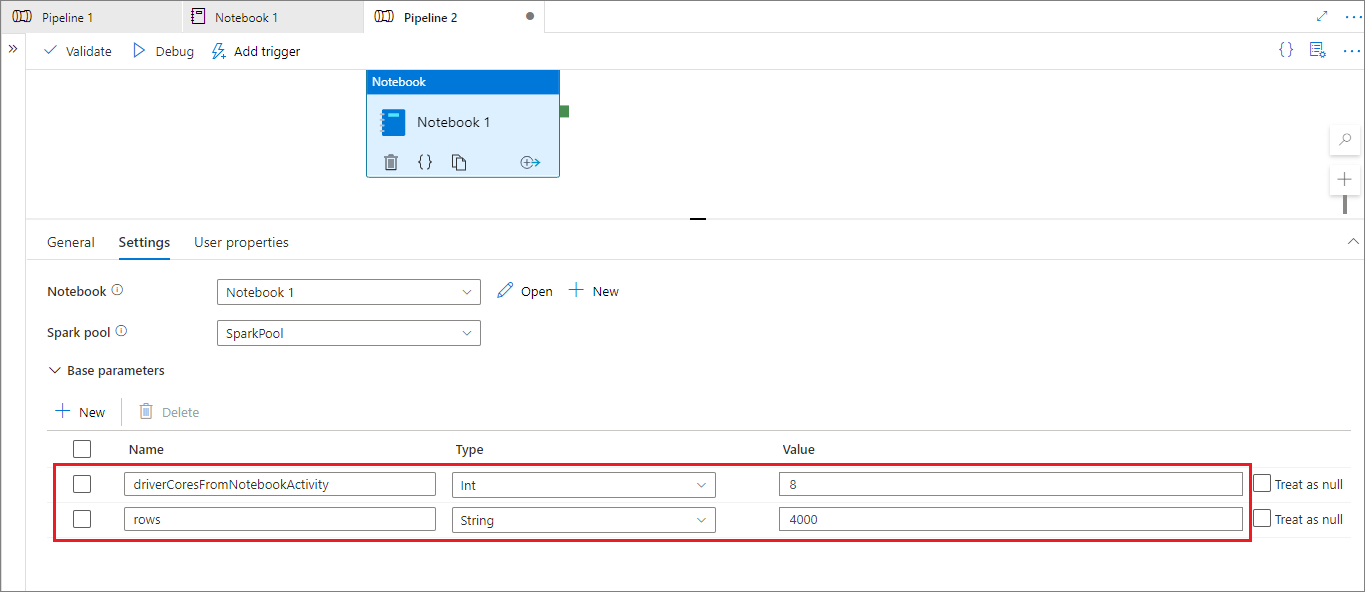
如果您想要變更會話設定,管線 Notebook 活動參數名稱應該與 Notebook 中的 activityParameterName 相同。 執行此管線時,在此範例中,%configure 中的 driverCores 將會由 8 取代,livy.rsc.sql.num-rows 將會取代為 4000。
注意
如果執行管線因為使用此新的 %%configure magic 而失敗,您可以在筆記本的互動式模式中執行 %%configure magic 單元格,以檢查更多錯誤資訊。
將數據帶入筆記本
您可以從 Azure Blob 儲存體、Azure Data Lake Store Gen 2 和 SQL 集區載入數據,如下列程式代碼範例所示。
從 Azure Data Lake Store Gen2 讀取 CSV 作為 Spark DataFrame
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
從 Azure Blob 儲存體 讀取 CSV 作為 Spark 數據框架
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
從主要記憶體帳戶讀取數據
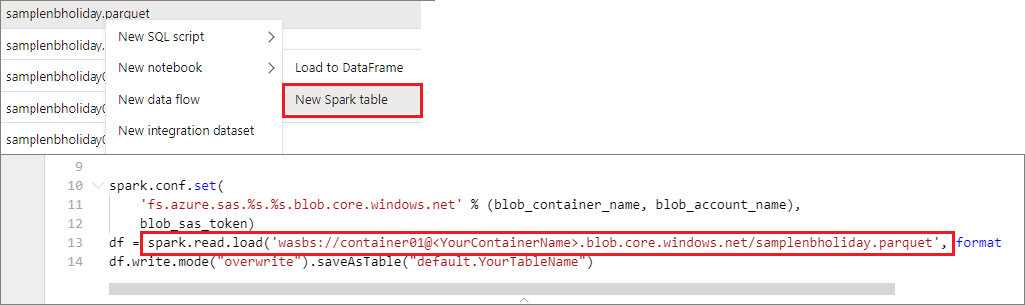
您可以直接存取主要記憶體帳戶中的數據。 不需要提供秘密金鑰。 在 [數據總管] 中,以滑鼠右鍵按兩下檔案,然後選取 [新增筆記本],以查看已自動產生數據擷取器的新筆記本 。
IPython 小工具
小工具是瀏覽器中具有表示法的可事件 Python 物件,通常是像滑桿、文本框等控件一樣。IPython 小工具只能在 Python 環境中運作,其他語言(例如 Scala、SQL、C#)尚不支援。
使用 IPython 小工具
您必須先匯入
ipywidgets模組,才能使用 Jupyter Widget 架構。import ipywidgets as widgets您可以使用最上層
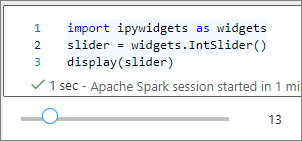
display函式來轉譯小工具,或將小工具類型的運算式保留在程式代碼數據格的最後一行。slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() slider執行數據格,小工具會顯示在輸出區域。
您可以使用多個
display()呼叫來轉譯相同的小工具實例多次,但彼此保持同步。slider = widgets.IntSlider() display(slider) display(slider)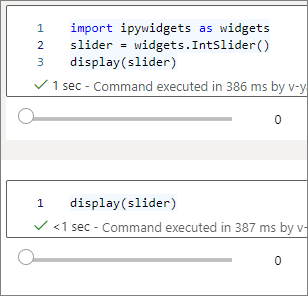
若要讓兩個小工具彼此獨立轉譯,請建立兩個 Widget 實例:
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)
支援的 Widget
| Widget 類型 | Widget |
|---|---|
| 數值小工具 | IntSlider、FloatSlider、FloatLogSlider、IntRangeSlider、FloatRangeSlider、IntProgress、FloatProgress、BoundedIntText、BoundedFloatText、IntText、FloatText |
| 布爾小工具 | ToggleButton、複選框、有效 |
| 選取小工具 | 下拉式清單、RadioButtons、Select、SelectionSlider、SelectionRangeSlider、ToggleButtons、SelectMultiple |
| 字串小工具 | 文字、文字區域、組合框、密碼、標籤、HTML、HTML 數學、影像、按鈕 |
| 播放 (動畫) 小工具 | 日期選擇器、色彩選擇器、控制器 |
| 容器/版面配置小工具 | Box、HBox、VBox、GridBox、Accordion、Tabs、Stacked |
已知的限制
尚不支援下列小工具,您可以遵循對應的因應措施,如下所示:
功能 因應措施 Output部件您可以改用 print()函式將文字寫入 stdout。widgets.jslink()您可以使用 widgets.link()函式來連結兩個類似的小工具。FileUpload部件尚不支援。 Synapse 提供的全域
display函式不支援在一個呼叫中顯示多個小工具,這display(a, b)與 IPythondisplay函式不同。如果您關閉包含 IPython Widget 的筆記本,在再次執行對應的儲存格之前,您將無法看到或與其互動。
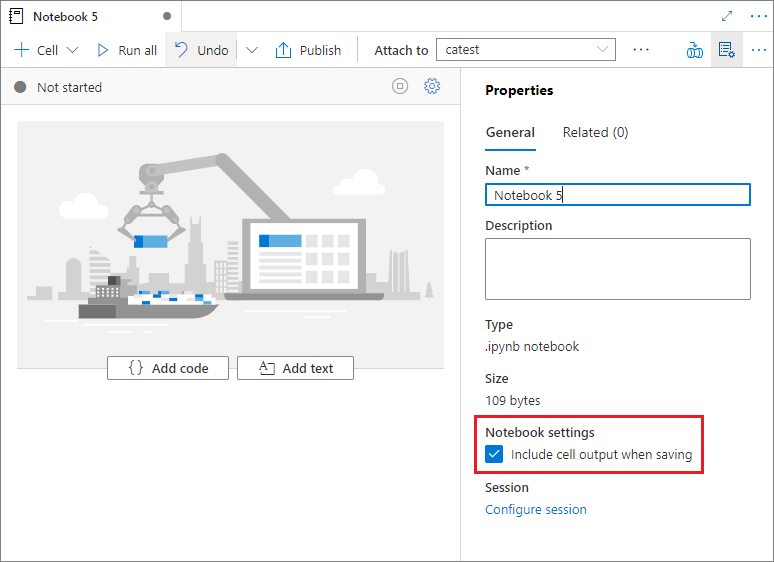
儲存筆記本
您可以在工作區中儲存單一筆記本或所有筆記本。
若要儲存您對單一筆記本所做的變更,請選取 筆記本命令行上的 [發佈 ] 按鈕。

若要在工作區中儲存所有筆記本,請選取工作區命令行上的 [ 發佈所有 ] 按鈕。

在筆記本屬性中,您可以設定是否要在儲存時包含資料格輸出。
Magic 命令
您可以在 Synapse 筆記本中使用熟悉的 Jupyter magic 命令。 請檢閱下列清單作為目前可用的magic命令。 告訴我們 GitHub 上的使用案例,讓我們可以繼續建置更多魔術命令,以符合您的需求。
注意
Synapse 管線只支援下列 magic 命令: %%pyspark、%%spark、%%csharp、%%sql。
可用的線條魔術: %lsmagic, %time, %timeit, %history, %run, %load
可用的單元格魔術:%%time、%%timeit、%%capture、%%writefile、%%sql、%%pyspark、%%spark、%csharp、%%html、%%configure
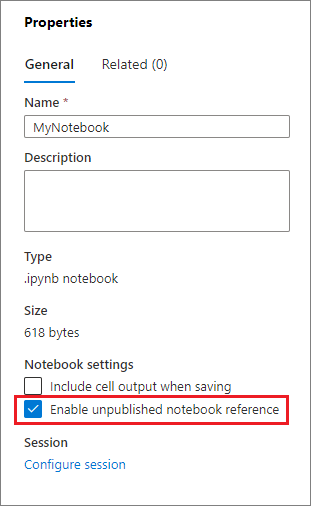
參考未發佈的筆記本
當您想要對「本機」進行偵錯時,參考未發佈的筆記本會很有説明,當您啟用此功能時,筆記本會在 Web 快取中擷取目前的內容,如果您執行包含參考筆記本語句的數據格,您可以在目前的筆記本瀏覽器中參考呈現的筆記本,而不是叢集中儲存的版本,這表示筆記本編輯器中的變更可以立即由其他筆記本參考,而不需要發佈(即時模式)或認可(Git 模式),藉由利用這種方法,您可以輕鬆地避免在開發或偵錯程式期間受到污染的常見連結庫。
您可以從 [屬性] 面板開啟 [參考未發佈筆記本]:
如需不同的案例比較,請查看下表:
請注意, %run 和 mssparkutils.notebook.run 在這裏的行為相同。 我們在這裡使用 %run 作為範例。
| 大小寫 | 停用 | 啟用 |
|---|---|---|
| 即時模式 | ||
- Nb1(已發佈) %run Nb1 |
執行已發行的 Nb1 版本 | 執行已發行的 Nb1 版本 |
- Nb1 (新) %run Nb1 |
錯誤 | 執行新的 Nb1 |
- Nb1 (先前出版,編輯) %run Nb1 |
執行 已發行 的 Nb1 版本 | 執行 已編輯 的 Nb1 版本 |
| Git 模式 | ||
- Nb1(已發佈) %run Nb1 |
執行已發行的 Nb1 版本 | 執行已發行的 Nb1 版本 |
- Nb1 (新) %run Nb1 |
錯誤 | 執行新的 Nb1 |
- Nb1 (未出版,認可) %run Nb1 |
錯誤 | 執行認可的 Nb1 |
- Nb1 (先前出版,已認可) %run Nb1 |
執行 已發行 的 Nb1 版本 | 執行 Nb1 的認可 版本 |
- Nb1(先前出版,最新分支的新功能) %run Nb1 |
執行 已發行 的 Nb1 版本 | 執行 新的 Nb1 |
- Nb1 (未出版,先前認可,編輯) %run Nb1 |
錯誤 | 執行 已編輯 的 Nb1 版本 |
- Nb1 (先前出版並認可,編輯) %run Nb1 |
執行 已發行 的 Nb1 版本 | 執行 已編輯 的 Nb1 版本 |
結論
- 如果停用,請一律執行 已發佈 的版本。
- 如果啟用,優先順序為:已編輯/已發行新的 > 認可 > 。
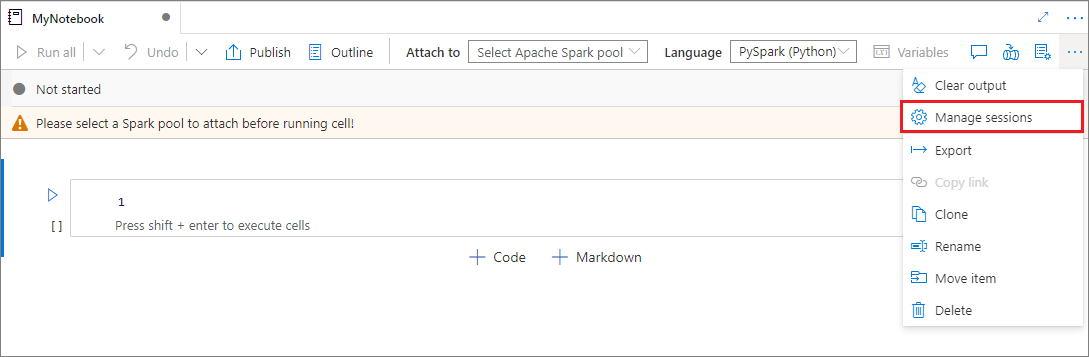
主動會話管理
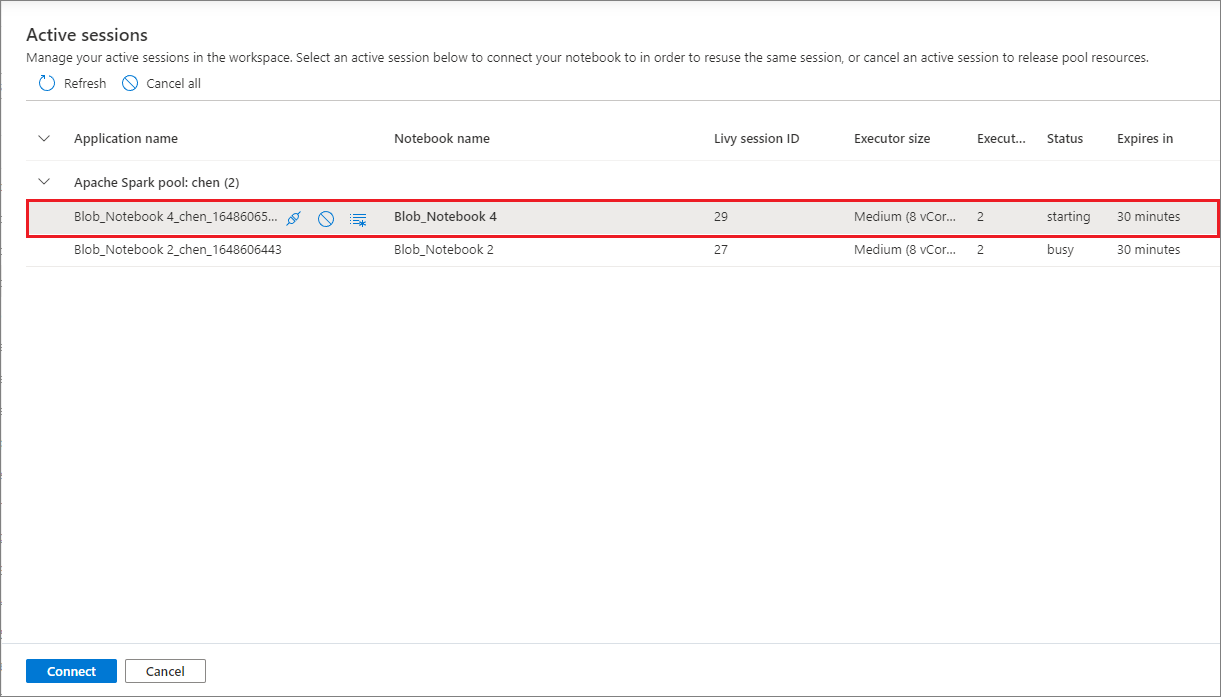
您現在可以輕鬆地重複使用筆記本會話,而不需要啟動新的會話。 Synapse Notebook 現在支援在 [管理會話] 清單中管理使用中的 會話 ,您可以在從筆記本開始的目前工作區中看到所有會話。
在 [作用中 會話] 清單中,您可以看到會話資訊和目前附加至會話的對應筆記本。 您可以使用筆記本操作卸離、停止會話,以及從這裏檢視監視。 此外,您可以輕鬆地將選取的筆記本連線至清單中從另一個筆記本啟動的作用中會話,會話會與先前的筆記本中斷連結(如果它未閑置),然後附加至目前的筆記本。
Notebook 中的 Python 記錄
您可以依照下列範例程式代碼來尋找 Python 記錄,並設定不同的記錄層級和格式:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
檢視輸入命令的歷程記錄
Synapse Notebook 支援 magic 命令 %history 來列印在目前工作階段中執行的輸入命令歷程記錄,相較於標準 Jupyter Ipython 命令,該 %history 命令適用於筆記本中的多種語言內容。
%history [-n] [range [range ...]]
針對選項:
- -n:列印執行編號。
其中範圍可以是:
- N:列印第 N 個執行儲存格的程式代碼。
- M-N:將程式代碼從 Mth 列印到 第 N 個 執行的數據格。
範例:
- 從第 1 個到第 2 個執行的數據格列印輸入歷程記錄:
%history -n 1-2
整合筆記本
將筆記本新增至管線
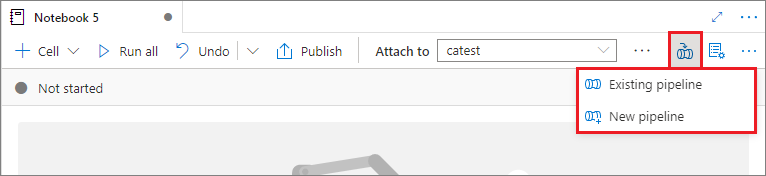
選取右上角的 [ 新增至管線 ] 按鈕,將筆記本新增至現有的管線或建立新的管線。
指定參數儲存格
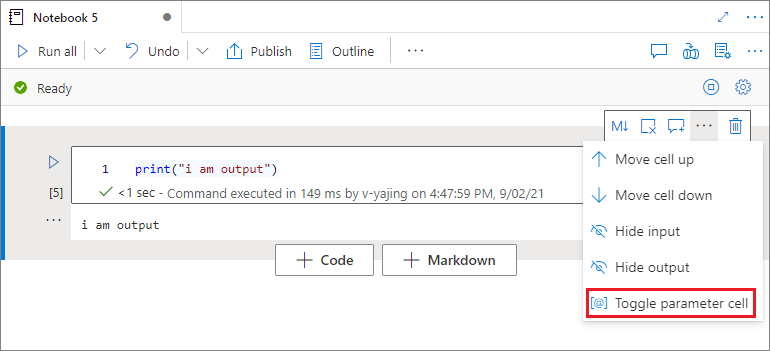
若要將筆記本參數化,請選取省略號 (...) 以存取 儲存格工具列上的更多命令 。 然後選取 [ 切換參數數據格 ],將單元格指定為 parameters 單元格。
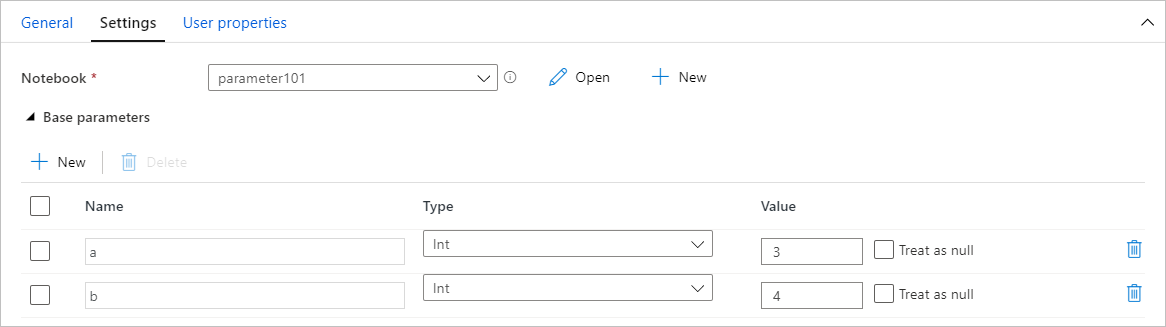
Azure Data Factory 會尋找參數數據格,並將此數據格視為運行時間傳入之參數的預設值。 執行引擎會在具有輸入參數的參數數據格底下加入新的儲存格,以覆寫預設值。
從管線指派參數值
建立具有參數的筆記本之後,您就可以從具有 Synapse Notebook 活動的管線執行筆記本。 將活動新增至管線畫布之後,您將能夠在 [設定] 索引標籤標的 [基底參數] 區段下設定參數值。
快速鍵
與 Jupyter Notebook 類似,Synapse 筆記本具有強制回應使用者介面。 鍵盤會根據筆記本儲存格所在的模式來執行不同的動作。 Synapse Notebook 支援指定程式代碼數據格的下列兩種模式:命令模式和編輯模式。
當沒有文字游標提示您輸入時,單元格會處於命令模式。 儲存格處於命令模式時,您可以將筆記本當做整體編輯,但無法輸入個別的儲存格。 按下
ESC或使用滑鼠在儲存格的編輯器區域外選取,以進入命令模式。
編輯模式會以文字游標指示,提示您在編輯器區域中輸入。 當儲存格處於編輯模式時,您可以在儲存格中輸入文字。 按下
Enter或使用滑鼠在儲存格的編輯器區域上選取 ,以進入編輯模式。
命令模式下的快速鍵
| 動作 | Synapse 筆記本快捷方式 |
|---|---|
| 執行目前的儲存格,然後選取下方 | Shift+Enter |
| 執行目前的儲存格,並在下方插入 | Alt+Enter |
| 執行目前的儲存格 | Ctrl+Enter |
| 選取上方儲存格 | 向上 |
| 選取下方儲存格 | 向下 |
| 選取上一個單元格 | K |
| 選取下一個單元格 | J |
| 在上方插入儲存格 | A |
| 在下方插入儲存格 | B |
| 刪除選取的儲存格 | Shift + D |
| 切換到編輯器模式 | Enter |
編輯模式下的快速鍵
使用下列按鍵快捷方式,您可以在編輯模式時,更輕鬆地在 Synapse 筆記本中巡覽和執行程式碼。
| 動作 | Synapse 筆記本快捷方式 |
|---|---|
| 向上移動游標 | 向上 |
| 向下移動游標 | 向下 |
| 復原 | Ctrl + Z |
| 取消復原 | Ctrl + Y |
| 批註/取消批注 | Ctrl + / |
| 刪除此前的文字 | Ctrl + Backspace |
| 刪除此後的文字 | Ctrl + 刪除 |
| 移至儲存格開端 | Ctrl + 首頁 |
| 移至儲存格末端 | Ctrl + 結束 |
| 往左移一個單字 | Ctrl + 向左 |
| 往右移一個單字 | Ctrl + 向右 |
| 全選 | Ctrl + A |
| Indent | Ctrl +] |
| Dedent | Ctrl + [ |
| 切換至命令模式 | Esc |