移轉:Azure Synapse Analytics 專用 SQL 集區至 Fabric
適用於:![]() Microsoft Fabric 中的倉儲
Microsoft Fabric 中的倉儲
本文詳細說明 Azure Synapse Analytics 專用 SQL 集區中將數據倉儲移轉至 Microsoft Fabric 倉儲的策略、考慮和方法。
移轉簡介
隨著 Microsoft 引進 Microsoft Fabric,這是一套全方位服務的企業 SaaS 分析解決方案,可提供完整的服務套件,包括 Data Factory、資料工程師、資料倉儲、資料科學、即時分析和 Power BI。
本文著重於架構 (DDL) 移轉、資料庫程式代碼 (DML) 移轉和資料遷移的選項。 Microsoft 提供數個選項,在這裡我們會詳細討論每個選項,並提供您案例應考慮哪些選項的指引。 本文使用 TPC-DS 產業基準進行圖例和效能測試。 您的實際結果可能會因許多因素而有所不同,包括數據類型、數據類型、數據表寬度、數據源延遲等。
為移轉做準備
在開始之前,請先仔細規劃移轉專案,並確定架構、程式代碼和數據與網狀架構倉儲相容。 您需要考慮一些 限制 。 量化不相容專案的重構工作,以及移轉傳遞之前所需的任何其他資源。
規劃的另一個重要目標是調整您的設計,以確保您的解決方案充分利用網狀架構倉儲設計所提供的高查詢效能。 針對規模設計數據倉儲引進了獨特的設計模式,因此傳統方法不一定是最佳方法。 檢閱網狀架構倉儲效能指導方針,因為雖然移轉之後可以進行一些設計調整,但稍早進行變更會節省您的時間和精力。 從某個技術/環境移轉至另一個技術/環境一直是一項重大工作。
下圖描述移轉生命週期,其中列出由評估與評估、規劃和設計、移轉、監視及控管、優化和現代化各支柱組成的主要要素,以及每個要件中相關工作,以規劃和準備順利移轉。

移轉的 Runbook
請考慮下列活動作為規劃 Runbook,以便從 Synapse 專用 SQL 集區移轉至網狀架構倉儲。
- 評估和評估
- 識別目標和動機。 建立明確的預期結果。
- 探索、評估和基準現有的架構。
- 識別重要的項目關係人和贊助者。
- 定義要移轉的範圍。
- 從小型和簡單開始,準備多個小型移轉。
- 開始監視並記錄程式的所有階段。
- 建置移轉的數據和程式清查。
- 定義數據模型變更(如果有的話)。
- 設定網狀架構工作區。
- 您的技能集/喜好設定為何?
- 盡可能自動化。
- 使用 Azure 內建工具和功能來減少移轉工作。
- 在新的平臺上提前訓練員工。
- 識別提升技能的需求和訓練資產,包括 Microsoft Learn。
- 規劃和設計
- 定義所需的架構。
- 選取移轉的方法/工具以完成下列工作:
- 從來源擷取數據。
- 架構 (DDL) 轉換,包括數據表和檢視的元數據
- 數據擷取,包括歷程記錄數據。
- 如有必要,請使用新的平臺效能和延展性重新設計數據模型。
- 資料庫程式代碼 (DML) 移轉。
- 移轉或重構預存程式和商務程式。
- 清查並擷取來源的安全性功能和物件許可權。
- 設計和規劃取代/修改累加式載入的現有 ETL/ELT 程式。
- 建立新環境的平行 ETL/ELT 進程。
- 準備詳細的移轉計劃。
- 將目前狀態對應至新的所需狀態。
- 移轉
- 執行架構、數據、程式代碼移轉。
- 從來源擷取數據。
- 架構 (DDL) 轉換
- 數據擷取
- 資料庫程式代碼 (DML) 移轉。
- 如有必要,請暫時相應增加專用 SQL 集區資源,以協助加速移轉。
- 套用安全性和許可權。
- 移轉現有的 ETL/ELT 程式以進行累加式載入。
- 移轉或重構 ETL/ELT 累加式載入程式。
- 測試並比較平行遞增加載程式。
- 視需要調整詳細移轉計劃。
- 執行架構、數據、程式代碼移轉。
- 監視與控管
- 以平行方式執行,與來源環境進行比較。
- 測試應用程式、商業智慧平臺和查詢工具。
- 基準檢驗並優化查詢效能。
- 監視和管理成本、安全性和效能。
- 治理基準和評量。
- 以平行方式執行,與來源環境進行比較。
- 優化和現代化
- 當商務舒適時,將應用程式和主要報告平台轉換為 Fabric。
- 隨著工作負載從 Azure Synapse Analytics 轉移至 Microsoft Fabric,相應增加/減少資源。
- 從未來移轉的經驗建置可重複的範本。 反覆運算。
- 找出成本優化、安全性、延展性和卓越營運的機會
- 找出使用最新網狀架構功能將您的數據資產現代化的機會。
- 當商務舒適時,將應用程式和主要報告平台轉換為 Fabric。
「隨即轉移」或現代化?
一般而言,不論規劃的移轉用途和範圍為何,都有兩種類型的移轉案例:依原樣隨即轉移,或包含架構和程式代碼變更的階段式方法。
隨即轉移
在隨即轉移中,現有的數據模型會隨著新網狀架構倉儲的次要變更而移轉。 這種方法可藉由減少實現移轉優點所需的新工作,將風險和移轉時間降到最低。
隨即轉移移轉適合下列案例:
- 您有一個現有的環境,其中包含少量要移轉的數據超市。
- 您有現有的環境,其數據已位於設計完善的星形或雪花式架構中。
- 您正面臨移至網狀架構倉儲的時間和成本壓力。
總而言之,此方法適用於使用您目前 Synapse 專用 SQL 集區環境優化的工作負載,因此不需要在 Fabric 中進行重大變更。
使用架構變更分階段方式現代化
如果舊版數據倉儲在很長一段時間內發展,您可能需要重新設計它,以維持所需的效能等級。
您也可以重新設計架構,以利用網狀架構工作區中可用的新引擎和功能。
設計差異:Synapse 專用 SQL 集區和網狀架構倉儲
請考慮下列 Azure Synapse 和 Microsoft Fabric 數據倉儲差異,將專用 SQL 集區與網狀架構倉儲進行比較。
資料表考量
當您在不同環境之間移轉數據表時,通常只會實際移轉原始數據和元數據。 來源系統的其他資料庫元素,例如索引,通常不會移轉,因為它們在新的環境中可能不必要或以不同的方式實作。
來源環境中的效能優化,例如索引,表示您可以在新環境中新增效能優化的位置,但現在 Fabric 會自動為您處理。
T-SQL 考慮
有幾個數據操作語言 (DML) 語法差異需要注意。 請參閱 Microsoft Fabric 中的 T-SQL 介面區。 在選擇資料庫程式代碼 (DML) 移轉的方法時,也請考慮程式代碼評估。
根據移轉時的同位差異,您可能需要重寫 T-SQL DML 程式代碼的一部分。
數據類型對應差異
網狀架構倉儲中有數個數據類型差異。 如需詳細資訊,請參閱 Microsoft Fabric 中的數據類型。
下表提供從 Synapse 專用 SQL 集區到網狀架構倉儲的支持數據類型對應。
| Synapse 專用 SQL 集區 | 網狀架構倉儲 |
|---|---|
| money | 十進位(19,4) |
| smallmoney | 十進位(10,4) |
| smalldatetime | datetime2 |
| Datetime | datetime2 |
| NCHAR | char |
| nvarchar | varchar |
| TINYINT | SMALLINT |
| binary | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 不會儲存儲存在 的額外時區位移資訊。 由於 Fabric Warehouse 目前不支援 datetimeoffset 數據類型,因此時區位移數據必須擷取到個別的數據行。
架構、程式代碼和數據遷移方法
檢閱並識別這些選項中哪一個選項符合您的案例、員工技能集,以及數據的特性。 選擇的選項取決於您的體驗、喜好設定,以及每個工具的優點。 我們的目標是繼續開發移轉工具,以減輕摩擦和手動介入,讓該移轉體驗順暢。
下表摘要說明數據架構 (DDL)、資料庫程式代碼 (DML) 和數據遷移方法的資訊。 本文稍後會進一步展開每個案例,並連結在 Option 數據行中。
| 選項編號 | 選項 | 作用 | 技能/喜好設定 | 案例 |
|---|---|---|---|---|
| 1 | Data Factory | 架構 (DDL) 轉換 數據擷 資料擷取 |
ADF/管線 | 簡化一個架構 (DDL) 和數據遷移中的所有專案。 建議用於維度數據表。 |
| 2 | 具有數據分割的 Data Factory | 架構 (DDL) 轉換 數據擷 資料擷取 |
ADF/管線 | 使用數據分割選項來增加讀取/寫入平行處理原則,以提供10倍的輸送量與選項1,建議用於事實數據表。 |
| 3 | 具有加速程序代碼的 Data Factory | 架構 (DDL) 轉換 | ADF/管線 | 先轉換並移轉架構 (DDL),然後使用 CETAS 擷取和 COPY/Data Factory 擷取數據,以獲得最佳整體擷取效能。 |
| 4 | 預存程式加速程序代碼 | 架構 (DDL) 轉換 數據擷 程式代碼評估 |
T-SQL | 使用 IDE 的 SQL 使用者,可更細微地控制要處理哪些工作。 使用 COPY/Data Factory 來內嵌數據。 |
| 5 | 適用於 Azure Data Studio 的 SQL 資料庫 Project 延伸模組 | 架構 (DDL) 轉換 數據擷 程式代碼評估 |
SQL 專案 | SQL 資料庫 Project,以整合選項 4 進行部署。 使用 COPY 或 Data Factory 來內嵌數據。 |
| 6 | CREATE EXTERNAL TABLE AS SELECT (CETAS) | 數據擷 | T-SQL | 將符合成本效益且高效能的數據擷取到 Azure Data Lake 儲存體 (ADLS) Gen2。 使用 COPY/Data Factory 來內嵌數據。 |
| 7 | 使用 dbt 移轉 | 架構 (DDL) 轉換 資料庫程式代碼 (DML) 轉換 |
Dbt | 現有的 dbt 使用者可以使用 dbt Fabric 配接器來轉換其 DDL 和 DML。 您接著必須使用此資料表中的其他選項來移轉數據。 |
選擇初始移轉的工作負載
當您決定從 Synapse 專用 SQL 集區到網狀架構倉儲移轉項目的開始位置時,請選擇一個工作負載區域,您可以在其中:
- 藉由快速提供新環境的優點,證明移轉至網狀架構倉儲的可行性。 從小型和簡單開始,準備多個小型移轉。
- 讓您的內部技術人員有時間透過移轉至其他區域時所使用的流程和工具,獲得相關經驗。
- 建立範本以進一步移轉來源 Synapse 環境專屬,以及可協助的工具和程式。
提示
建立需要移轉的物件清查,並記錄從頭到尾的移轉程式,以便針對其他專用 SQL 集區或工作負載重複它。
初始移轉中移轉的數據量應該足以示範網狀架構倉儲環境的功能和優點,但不會太大,無法快速示範價值。 1-10 TB 範圍的大小是典型的。
使用網狀架構 Data Factory 進行移轉
在本節中,我們會討論針對熟悉 Azure Data Factory 和 Synapse Pipeline 的低程式代碼/無程序代碼角色使用 Data Factory 的選項。 此拖放UI選項提供簡單的步驟來轉換 DDL 並移轉資料。
Fabric Data Factory 可以執行下列工作:
- 將架構 (DDL) 轉換為網狀架構倉儲語法。
- 在網狀架構倉儲上建立架構 (DDL)。
- 將數據遷移至網狀架構倉儲。
選項 1。 架構/數據遷移 - 複製精靈和 ForEach 複製活動
此方法會使用Data Factory 複製小幫手聯手到來源專用SQL集區、將專用SQL集區 DDL 語法轉換為 Fabric,並將數據複製到網狀架構倉儲。 您可以選取 1 個以上的目標數據表(針對 TPC-DS 數據集,有 22 個數據表)。 它會產生 ForEach 來迴圈查看 UI 中選取的數據表清單,並繁衍 22 個平行複製活動線程。
- 在專用 SQL 集區中產生並執行 22 個 SELECT 查詢(每個選取的數據表各一個)。
- 請確定您有適當的 DWU 和資源類別,以允許執行產生的查詢。 在此情況下,您至少需要 DWU1000,
staticrc10才能允許最多 32 個查詢處理提交的 22 個查詢。 - Data Factory 會將數據從專用 SQL 集區直接複製到網狀架構倉儲需要預備。 擷取程式包含兩個階段。
- 第一個階段包含將數據從專用 SQL 集區擷取至 ADLS,並稱為預備。
- 第二個階段包含將數據從預備環境擷取到網狀架構倉儲。 大部分的數據擷取時間都處於預備階段。 總而言之,暫存會對擷取效能產生巨大影響。
建議使用
使用複製精靈產生 ForEach 提供簡單的 UI,以一個步驟將 DDL 轉換成網狀架構倉儲,並將選取的數據表從專用 SQL 集區內嵌至網狀架構倉儲。
不過,整體輸送量並不理想。 使用暫存的需求,需要平行處理「來源到階段」步驟的讀取和寫入,是效能延遲的主要因素。 建議只針對維度數據表使用此選項。
選項 2。 DDL/資料遷移 - 使用分割區選項的數據管線
若要使用網狀架構數據管線改善輸送量以載入較大的事實數據表,建議針對具有分割區選項的每個事實數據表使用複製活動。 這可提供 複製活動 的最佳效能。
如果有的話,您可以選擇使用源數據表實體分割。 如果數據表沒有實體數據分割,您必須指定資料分割數據行,並提供最小值/最大值以使用動態數據分割。 在下列螢幕快照中,數據管線 [來源] 選項會根據 ws_sold_date_sk 數據行指定數據分割的動態範圍。
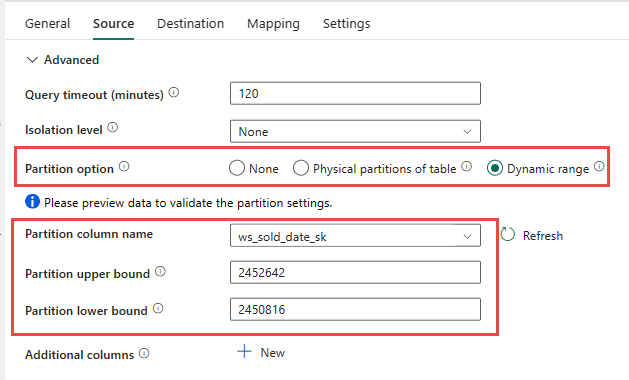
雖然使用分割區可以增加暫存階段的輸送量,但有適當的調整考慮:
- 根據您的分割範圍,它可能會使用所有並行位置,因為它可能會在專用SQL集區上產生超過128個查詢。
- 您必須調整為至少DWU6000,才能執行所有查詢。
- 例如,針對 TPC-DS
web_sales數據表,會將 163 個查詢提交至專用 SQL 集區。 DWU6000時,會執行 128 個查詢,同時排入佇列 35 個查詢。 - 動態數據分割會自動選取範圍分割區。 在此情況下,每個提交至專用 SQL 集區之 SELECT 查詢的 11 天範圍。 例如:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
建議使用
針對事實數據表,我們建議使用 Data Factory 搭配數據分割選項來增加輸送量。
不過,增加的平行讀取需要專用 SQL 集區調整為較高的 DWU,以允許執行擷取查詢。 利用數據分割,速率會比沒有數據分割選項提高 10 倍。 您可以增加 DWU 以透過計算資源取得額外的輸送量,但專用 SQL 集區最多允許 128 個作用中查詢。
選項 3。 DDL 移轉 - 複製精靈 ForEach 複製活動
上述兩個選項是較小型資料庫的絕佳數據遷移選項。 但是,如果您需要較高的輸送量,我們建議使用替代選項:
- 將數據從專用 SQL 集區擷取至 ADLS,因此可降低階段效能負擔。
- 使用 Data Factory 或 COPY 命令,將資料內嵌至網狀架構倉儲。
建議使用
您可以繼續使用 Data Factory 來轉換架構 (DDL)。 使用 [複製精靈],您可以選取特定的數據表或 [所有數據表]。 根據設計,這會在一個步驟中移轉架構和數據,在查詢語句中使用 false 條件 TOP 0 擷取架構,而沒有任何數據列。
下列程式代碼範例涵蓋使用 Data Factory 的架構 (DDL) 移轉。
程式代碼範例:使用 Data Factory 進行架構 (DDL) 移轉
您可以使用網狀架構數據管線,輕鬆地從任何來源 Azure SQL 資料庫 或專用 SQL 集區移轉數據表物件的 DDL (架構)。 此資料管線會透過來源專用 SQL 集區資料表的架構 (DDL) 移轉至網狀架構倉儲。
管線設計:參數
此資料管線接受 參數 SchemaName,可讓您指定要移轉的架構。 架構 dbo 是預設值。
在 [預設值] 欄位中,輸入以逗號分隔的數據表架構清單,指出要移轉的架構:'dbo','tpch'提供兩個架構和 dbotpch。
![Data Factory 的螢幕快照,其中顯示數據管線的 [參數] 索引卷標。在 [名稱] 欄位中,[SchemaName]。在 [預設值] 字段中,'dbo','tpch',表示應該移轉這兩個架構。](media/migration-synapse-dedicated-sql-pool-warehouse/fabric-data-factory-parameters-schemaname.png)
管線設計:查閱活動
建立查閱活動,並將 連線 設定為指向源資料庫。
在 [設定] 索引標籤中:
將 [資料存放區類型] 設定為 [外部]。
連線 是 Azure Synapse 專用 SQL 集區。 連線 ion 類型為 Azure Synapse Analytics。
使用查詢 會設定為 [查詢]。
[查詢] 欄位必須使用動態表達式來建置,才能在傳回目標源數據表清單的查詢中使用 SchemaName 參數。 選取 [ 查詢 ],然後選取 [ 新增動態內容]。
LookUp 活動內的這個運算式會產生 SQL 語句,以查詢系統檢視以擷取架構和數據表的清單。 參考 SchemaName 參數,以允許篩選 SQL 架構。 此輸出是 SQL 架構和資料表的數位,將做為 ForEach 活動的輸入。
使用下列程式代碼傳回具有其架構名稱的所有用戶數據表清單。
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
![Data Factory 的螢幕快照,其中顯示數據管線 設定 索引標籤。已選取 [查詢] 按鈕,並將程式代碼貼到 [查詢] 字段中。](media/migration-synapse-dedicated-sql-pool-warehouse/fabric-data-factory-query-dynamic-content.png)
管線設計:ForEach 迴圈
針對 ForEach 循環,請在 [設定] 索引標籤中設定下列選項:
- 停用 循序 以允許多個反覆項目同時執行。
- 將 [批次計數] 設定為
50,限制並行反覆項目的數目上限。 - [專案] 欄位需要使用動態內容來參考 LookUp 活動的輸出。 使用下列代碼段:
@activity('Get List of Source Objects').output.value
![顯示 [ForEach 循環活動設定] 索引標籤的螢幕快照。](media/migration-synapse-dedicated-sql-pool-warehouse/fabric-data-factory-settings-foreach-loop-items.png)
管線設計:ForEach 迴圈內的複製活動
在 ForEach 活動內,新增複製活動。 此方法會使用數據管線內的動態表達式語言來建置 SELECT TOP 0 * FROM <TABLE> ,只移轉架構而不將數據遷移至網狀架構倉儲。
在 [ 來源] 索引標籤 中:
- 將 [資料存放區類型] 設定為 [外部]。
- 連線 是 Azure Synapse 專用 SQL 集區。 連線 ion 類型為 Azure Synapse Analytics。
- 將 [使用查詢] 設定為 [查詢]。
- 在 [ 查詢 ] 欄位中,貼上動態內容查詢,並使用這個表達式會傳回零個數據列,而只會傳回數據表架構:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)
![Data Factory 的螢幕快照,其中顯示 ForEach 循環內複製活動的 [來源] 索引標籤。](media/migration-synapse-dedicated-sql-pool-warehouse/fabric-data-factory-foreach-copy-activity-source.png#lightbox)
在 [ 目的地] 索引標籤 中:
- 將 [數據存放區類型] 設定為 [工作區]。
- 工作區 數據存放區類型 為 數據倉儲 , 而數據倉儲 會設定為網狀架構倉儲。
- 目的地 數據表的架構和數據表名稱是使用動態內容來定義。
- 架構是指目前反覆專案的欄位 SchemaName,其中包含代碼段:
@item().SchemaName - Table 會參考 TableName 與代碼段:
@item().TableName
- 架構是指目前反覆專案的欄位 SchemaName,其中包含代碼段:
![Data Factory 的螢幕快照,其中顯示每個 ForEach 循環內複製活動的 [目的地] 索引標籤。](media/migration-synapse-dedicated-sql-pool-warehouse/fabric-data-factory-foreach-copy-activity-destination.png#lightbox)
管線設計:接收
針對 [接收],指向您的倉儲,並參考來源架構和數據表名稱。
執行此管線之後,您會看到數據倉儲已填入來源中的每個數據表,並具有適當的架構。
在 Synapse 專用 SQL 集區中使用預存程式進行移轉
此選項會使用預存程式來執行網狀架構移轉。
您可以在 microsoft/fabric-migration on GitHub.com 取得程式代碼範例。 此程式代碼會以 開放原始碼 的形式共用,因此您可以自由地參與共同作業並協助社群。
移轉預存程式可以執行的動作:
- 將架構 (DDL) 轉換為網狀架構倉儲語法。
- 在網狀架構倉儲上建立架構 (DDL)。
- 將數據從 Synapse 專用 SQL 集區擷取至 ADLS。
- 標記 T-SQL 程式代碼的非支援網狀架構語法(預存程式、函式、檢視表)。
建議使用
對於那些:
- 熟悉 T-SQL。
- 想要使用集成開發環境,例如 SQL Server Management Studio (SSMS)。
- 想要更細微地控制他們想要處理的工作。
您可以執行架構 (DDL) 轉換、資料擷取或 T-SQL 程式代碼評估的特定預存程式。
若要進行數據遷移,您必須使用 COPY INTO 或 Data Factory 將資料內嵌至網狀架構倉儲。
使用 SQL 資料庫 項目進行移轉
Azure Data Studio 和 Visual Studio Code 中提供的 SQL 資料庫 Projects 延伸模組支援 Microsoft Fabric 數據倉儲。
此延伸模組可在 Azure Data Studio 和 Visual Studio Code 內取得。 此功能可啟用原始檔控制、資料庫測試和架構驗證的功能。
建議使用
對於想要使用 SQL 資料庫 Project 進行部署的人來說,這是一個很好的選項。 此選項基本上已將網狀架構移轉預存程式整合到 SQL 資料庫 專案中,以提供順暢的移轉體驗。
SQL 資料庫 項目可以:
- 將架構 (DDL) 轉換為網狀架構倉儲語法。
- 在網狀架構倉儲上建立架構 (DDL)。
- 將數據從 Synapse 專用 SQL 集區擷取至 ADLS。
- 標記 T-SQL 程式代碼的非支援語法(預存程式、函式、檢視表)。
針對數據遷移,您接著會使用 COPY INTO 或 Data Factory 將資料內嵌至網狀架構倉儲。
新增至 Azure Data Studio 對 Fabric 的支援性,Microsoft Fabric CAT 小組提供了一組 PowerShell 腳本,可透過 SQL 資料庫 Project 來處理架構 (DDL) 和資料庫程式代碼 (DML) 的擷取、建立和部署。 如需使用 SQL 資料庫 專案搭配實用PowerShell腳本的逐步解說,請參閱 microsoft/fabric-migration on GitHub.com。
如需 SQL 資料庫 項目的詳細資訊,請參閱開始使用 SQL 資料庫 專案延伸模組和建置和發佈專案。
使用 CETAS 移轉數據
T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) 命令提供最符合成本效益且最佳的方法,可將 Synapse 專用 SQL 集區中的數據擷取至 Azure Data Lake 儲存體 (ADLS) Gen2。
CETAS 可以執行的動作:
- 將數據擷取到ADLS。
- 此選項需要使用者在網狀架構倉儲上建立架構 (DDL),才能內嵌數據。 請考慮本文中的選項以移轉架構 (DDL)。
此選項的優點如下:
- 每個數據表只會針對來源 Synapse 專用 SQL 集區提交單一查詢。 這不會用盡所有並行位置,因此不會封鎖並行客戶生產 ETL/查詢。
- 不需要調整為DWU6000,因為每個數據表只會使用單一併行位置,因此客戶可以使用較低的 DWU。
- 擷取會跨所有計算節點平行執行,而這是改善效能的關鍵。
建議使用
使用 CETAS 將數據擷取至 ADLS 作為 Parquet 檔案。 Parquet 檔案利用單欄式壓縮提供有效率的數據記憶體優勢,以較少的頻寬在網路上移動。 此外,由於 Fabric 會將資料儲存為 Delta parquet 格式,因此相較於文本檔格式,數據擷取速度會快 2.5 倍,因為擷取期間不會轉換成 Delta 格式的額外負荷。
若要增加 CETAS 輸送量:
- 新增平行 CETAS 作業,增加並行位置的使用,但允許更多輸送量。
- 在 Synapse 專用 SQL 集區上調整 DWU。
透過 dbt 移轉
在本節中,我們會針對已在目前 Synapse 專用 SQL 集區環境中使用 dbt 的客戶討論 dbt 選項。
dbt 可以執行的動作:
- 將架構 (DDL) 轉換為網狀架構倉儲語法。
- 在網狀架構倉儲上建立架構 (DDL)。
- 將資料庫程式代碼 (DML) 轉換為 Fabric 語法。
dbt 架構會在每次執行時,實時產生 DDL 和 DML (SQL 腳本)。 使用以 SELECT 語句表示的模型檔案,DDL/DML 可以藉由變更配置檔 (連接字串) 和配接器類型,立即轉譯為任何目標平臺。
建議使用
dbt 架構是程式代碼優先的方法。 您必須使用本檔中所列的選項來移轉數據,例如 CETAS 或 COPY/Data Factory。
Microsoft Fabric Synapse 數據倉儲的 dbt 配接器可讓以不同平臺為目標的現有 dbt 專案,例如 Synapse 專用 SQL 集區、Snowflake、Databricks、Google Big Query 或 Amazon Redshift,以簡單設定變更移轉至網狀架構倉儲。
若要開始使用以網狀架構倉儲為目標的 dbt 專案,請參閱 教學課程:設定適用於網狀架構數據倉儲的 dbt。 本檔也會列出在不同倉儲/平台之間移動的選項。
數據擷取至網狀架構倉儲
若要擷取至網狀架構倉儲,請使用 COPY INTO 或 Fabric Data Factory,視您的喜好設定而定。 這兩種方法都是建議且效能最佳的選項,因為它們具有對等的效能輸送量,因為前提是檔案已擷取至 Azure Data Lake 儲存體 (ADLS) Gen2。
要注意的幾個因素,讓您可以設計程式以達到最大效能:
- 使用 Fabric 時,沒有任何資源爭用會將多個數據表從 ADLS 同時載入至網狀架構倉儲。 因此,載入平行線程不會降低效能。 最大擷取輸送量只會受限於網狀架構容量的計算能力。
- 網狀架構工作負載管理提供配置給負載和查詢的資源區隔。 查詢和數據載入同時執行時,沒有任何資源爭用。
相關內容
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應