安裝並啟用重複資料刪除
適用於:Windows Server 2022、Windows Server 2019、Windows Server 2016、Azure Stack HCI 21H2 和 20H2 版本
本主題說明如何安裝重複資料刪除、評估重複資料刪除的工作負載,以及在特定磁碟區上啟用重複資料刪除。
注意
如果您打算在容錯移轉叢集中執行重覆資料刪除,叢集中的每個節點都必須安裝重覆資料刪除伺服器角色。
安裝重複資料刪除
重要
KB4025334 包含重複資料刪除的修正彙總(包括重要的可靠性修正),我們強烈建議在使用 Windows Server 2016 搭配重複資料刪除時安裝此修正彙總。
使用伺服器管理員安裝重複資料刪除
- 在 [新增角色及功能精靈] 中,選取 [伺服器角色],然後選取 [重複資料刪除]。
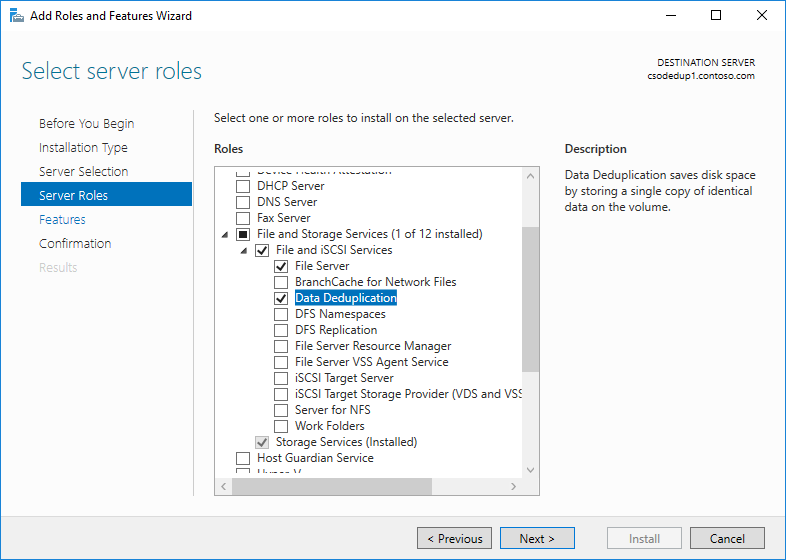
- 按一下 [下一步] 直到 [安裝] 按鈕被啟用,然後按一下 [安裝] 。

使用 PowerShell 安裝重複資料刪除
若要安裝重複資料刪除,請以系統管理員身分執行下列 PowerShell 命令︰Install-WindowsFeature -Name FS-Data-Deduplication
安裝重複資料刪除:
從執行 Windows Server 2016 或更新版本的伺服器,或從已安裝遠端伺服器管理工具 (RSAT) 的 Windows 電腦,安裝重覆資料刪除,並明確參考伺服器名稱 (以伺服器執行個體的實名取代 'MyServer'):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-DeduplicationOr
使用 PowerShell 遠端執行功能遠端連線至伺服器執行個體,然後使用 DISM 安裝重複資料刪除:
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
啟用重複資料刪除
決定可進行重複資料刪除的候選工作負載
重複資料刪除可透過減少重複資料所耗用的磁碟空間量,有效地將伺服器應用程式的資料消耗量成本降至最低。 啟用重複資料刪除之前,請務必了解您工作負載的特性,以確保存放裝置能夠發揮最大效能。 有兩種工作負載類別需要考量:
- 「建議的工作負載」,此類別已證明同時具有能高度受益於重複資料刪除的兩個資料集,且具有與重複資料刪除之後續處理模型相容的資源耗用量模式。 建議您一律在下列的工作負載上啟用重複資料刪除:
- 提供共用的一般用途檔案伺服器 (GPFS),例如小組共用、使用者主資料夾、工作資料夾,以及軟體開發共用。
- 虛擬桌面基礎結構 (VDI) 伺服器。
- 虛擬備份應用程式,例如 Microsoft Data Protection Manager (DPM)。
- 可能受益於重複資料刪除,但並非總是重複資料刪除良好候選的工作負載。 例如,下列工作負載可能適合進行重複資料刪除,但您應該先評估重複資料刪除的優點︰
- 一般用途的 Hyper-V 主機
- SQL 伺服器
- 企業營運 (LOB) 伺服器
評估重複資料刪除的工作負載
重要
如果您是執行建議的工作負載,則可以略過本節,並直接為工作負載啟用重複資料刪除。
若要判斷工作負載是否適合進行重複資料刪除,請回答下列問題。 如果您對工作負載感到不確定,請考慮為工作負載在測試資料集上執行重複資料刪除的試驗部署,以查看它的執行情況。
我的工作負載資料集是否具有足夠的重複資料量,以受益於啟用重複資料刪除? 在為工作負載啟用重複資料刪除之前,請使用重複資料刪除節省評估工具 (或稱為 DDPEval) 調查您工作負載資料集的重複資料量。 安裝重複資料刪除之後,您可以在下列位置找到此工具:
C:\Windows\System32\DDPEval.exe。 DDPEval 可針對直接連線的磁碟區 (包括本機磁碟機或叢集共用磁碟區),以及對應或未對應的網路共用,評估最佳化的可能性。執行 DDPEval.exe 將會傳回類似下列的輸出:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0我的工作負載針對其資料集的 I/O 模式看起來如何? 我的工作負載的效能為何? 重複資料刪除會將檔案最佳化為定期工作,而不是將檔案寫入至磁碟時。 因此,一定要檢查的是工作負載對已經過重複資料刪除處理之磁碟區的預期讀取模式。 由於重複資料刪除會將檔案內容移入區塊存放區中,並嘗試盡可能依檔案來組織區塊存放區,因此針對檔案循序範圍所套用的讀取作業,將會有最佳的效能。
類資料庫的工作負載通常具有較為隨機的讀取模式 (而非循序讀取模式),因為資料庫通常並不會保證資料庫配置會針對所有可能執行的查詢進行最佳化。 由於區塊存放區的區段可能會分散在磁碟區各處,因此針對資料庫查詢存取區塊存放區中的資料範圍,可能會產生額外的延遲。 高效能的工作負載特別容易受到上述額外延遲的影響,但其他類資料庫的工作負載可能不會。
注意
這些考量主要適用於由傳統旋轉式儲存媒體 (也稱為硬碟磁碟機或 HDD) 所組成之磁碟區上的存放裝置工作負載。 全快閃存放裝置基礎結構 (也稱為固態硬碟磁碟機或 SSD) 較不會受到隨機 IO 模式的影響,原因在於快閃媒體的特性之一便是針對媒體上所有位置都具有相同的存取時間。 因此,重複資料刪除針對儲存在全快閃媒體上之工作負載資料集所產生的讀取延遲,與在傳統旋轉式儲存媒體上將會不同。
我在伺服器上的工作負載會有哪些資源需求? 由於重複資料刪除是使用後續處理模型,因此重複資料刪除將定期需要有足夠的系統資源以完成最佳化和其他工作。 這表示具有閒置時間 (例如晚上或週末) 的工作負載最適合進行重複資料刪除,而需要全天候執行的工作負載則較不適合。 沒有任何閒置時間的工作負載如果在伺服器上的資源需求不高,則該工作負載仍然可能適合進行重複資料刪除。
啟用重複資料刪除
啟用重複資料刪除功能之前,您必須選擇與您的工作負載最類似的使用類型。 重複資料刪除包含的使用類型有三種。
- 預設:專為一般用途的檔案伺服器調整
- HYPER-V:專為 VDI 伺服器調整
- 備份:專為虛擬備份應用程式調整,例如 Microsoft DPM
使用伺服器管理員啟用重複資料刪除
- 選取伺服器管理員中的 [檔案和存放服務]。
- 從 [檔案和存放服務] 中,選取 [磁碟區]。
- 在所需的磁碟區上按一下滑鼠右鍵,然後選取 [設定重複資料刪除]。

- 從下拉式清單方塊中選取所需的 [使用類型],然後選取 [確定]。
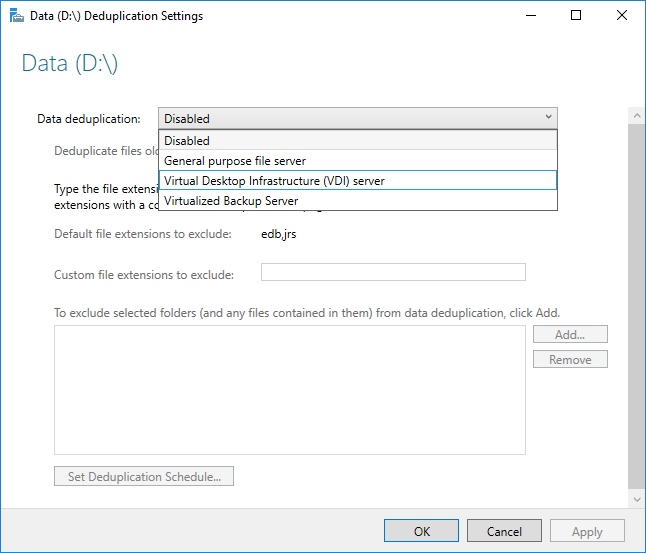
- 如果您是執行建議的工作負載,即大功告成。 針對其他工作負載,請參閱其他考量。
注意
您可以在 [設定重複資料刪除] 頁面上找到排除副檔名或資料夾,以及選取重複資料刪除排程的詳細資訊 (包括這麼做的原因)。
使用 PowerShell 啟用重複資料刪除
使用系統管理員內容,執行下列 PowerShell 命令︰
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>如果您是執行建議的工作負載,即大功告成。 針對其他工作負載,請參閱其他考量。
注意
重複資料刪除 PowerShell Cmdlet (包括 Enable-DedupVolume) 可透過 CIM 工作階段附加 -CimSession 參數從遠端執行。 這特別適用於從遠端針對伺服器執行個體執行重複資料刪除 PowerShell Cmdlet。 若要建立新的 CIM 工作階段,請執行 New-CimSession。
其他考量
重要
如果您是執行建議的工作負載,則可以略過本節。
- 重複資料刪除的使用類型會針對建議的工作負載提供合理的預設值,但也能夠為所有的工作負載提供不錯的起點。 針對建議的工作負載以外的工作負載,您可以修改重複資料刪除的進階設定,來提升重複資料刪除效能。
- 如果您的工作負載在伺服器上具有較高的資源需求,重複資料刪除工作應該安排在該工作負載預期的閒置期間內執行。 這在超交集主機上執行重複資料刪除時特別重要,因為在預期的工作期間內執行重複資料刪除將會佔用 VM。
- 如果您工作負載的資源需求不高,或者完成最佳化工作比起完成工作負載要求更為重要,則您可以調整記憶體、CPU,以及重複資料刪除工作的優先順序。
常見問題集 (FAQ)
我想要在 X 工作負載的資料集上執行重複資料刪除。 這是否受支援? 除了已知無法與重複資料刪除功能相互操作的工作負載之外,我們完全支援搭配任何工作負載之重複資料刪除的資料完整性。 建議的工作負載也受到 Microsoft 針對效能上的支援。 其他工作負載的效能大量取決於它們對您伺服器上執行的作業。 您必須判斷重複資料刪除對您工作負載造成的效能影響,以及該影響對此工作負載是否可以接受。
重複資料刪除磁碟區的磁碟區大小需求為何? 在 Windows Server 2012 與 Windows Server 2012 R2 中,使用者必須仔細調整磁碟區大小,以確保重複資料刪除可以跟上磁碟區上資料量變換的步調。 這通常表示工作負載變換度較高之已經過重複資料刪除處理的磁碟區平均大小上限為 1 至 2 TB,而建議的絕對大小上限為 10 TB。 在 Windows Server 2016 中,這些限制已經被移除。 如需詳細資訊,請參閱重複資料刪除的新功能。
我需要為建議的工作負載修改排程或其他重複資料刪除設定嗎? 否,我們所提供的使用類型能夠為建議的工作負載提供合理的預設值。
重複資料刪除的記憶體需求為何?
重複資料刪除最少應該要有 300 MB 的基本記憶體,並針對每 1 TB 的邏輯資料額外增加 50 MB 的記憶體。 比方說,如果您要最佳化 10 TB 的磁碟區,您最少需要配置 800 MB 的記憶體,以供進行重複資料刪除 (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB)。 雖然重複資料刪除可以利用最低限度的記憶體容量對磁碟區進行最佳化,如此有限的資源將會減緩重複資料刪除工作的速度。
最佳情況是,重複資料刪除針對每 1 TB 的邏輯資料,應該要有 1 GB 的記憶體。 比方說,如果您要最佳化 10 TB 的磁碟區,您最好配置 10 GB 的記憶體,以供進行重複資料刪除 (1 GB * 10)。 這個比率將能確保重複資料刪除工作具有最高效能。
重複資料刪除的儲存體需求為何? 在 Windows Server 2016 中,重複資料刪除可支援最多 64 TB 的磁碟區大小。 如需詳細資訊,請檢視重複資料刪除的新功能。