البرنامج التعليمي: تحميل بياناتك والوصول إليها واستكشافها في Azure التعلم الآلي
ينطبق على: Python SDK azure-ai-ml v2 (الحالي)
Python SDK azure-ai-ml v2 (الحالي)
في هذا البرنامج التعليمي، ستتعرف على كيفية القيام بما يلي:
- تحميل بياناتك إلى التخزين السحابي
- إنشاء أصل بيانات Azure التعلم الآلي
- الوصول إلى بياناتك في دفتر ملاحظات للتطوير التفاعلي
- إنشاء إصدارات جديدة من أصول البيانات
يتضمن بدء مشروع التعلم الآلي عادة تحليل البيانات الاستكشافية (EDA)، والمعالجة المسبقة للبيانات (التنظيف، وهندسة الميزات)، وبناء نماذج أولية التعلم الآلي للتحقق من صحة الفرضيات. مرحلة مشروع النماذج الأولية هذه تفاعلية للغاية. وهو يفسح المجال للتطوير في IDE أو دفتر ملاحظات Jupyter، مع وحدة تحكم Python تفاعلية. يصف هذا البرنامج التعليمي هذه الأفكار.
يوضح هذا الفيديو كيفية البدء في Azure التعلم الآلي studio بحيث يمكنك اتباع الخطوات الواردة في البرنامج التعليمي. يوضح الفيديو كيفية إنشاء دفتر ملاحظات، واستنساخ دفتر الملاحظات، وإنشاء مثيل حساب، وتنزيل البيانات اللازمة للبرنامج التعليمي. كما يتم وصف الخطوات في الأقسام التالية.
المتطلبات الأساسية
-
لاستخدام Azure التعلم الآلي، ستحتاج أولا إلى مساحة عمل. إذا لم يكن لديك واحد، فأكمل إنشاء الموارد التي تحتاجها للبدء في إنشاء مساحة عمل ومعرفة المزيد حول استخدامها.
-
سجل الدخول إلى الاستوديو وحدد مساحة العمل إذا لم تكن مفتوحة بالفعل.
-
افتح دفتر ملاحظات أو أنشئه في مساحة العمل:
- إنشاء دفتر ملاحظات جديد، إذا كنت تريد نسخ/لصق التعليمات البرمجية في الخلايا.
- أو افتح البرامج التعليمية/get-started-notebooks/explore-data.ipynb من قسم Samples في studio. ثم حدد استنساخ لإضافة دفتر الملاحظات إلى ملفاتك. (راجع مكان العثور على العينات.)
تعيين نواة
في الشريط العلوي أعلى دفتر الملاحظات المفتوح، أنشئ مثيل حساب إذا لم يكن لديك مثيل بالفعل.

إذا تم إيقاف مثيل الحساب، فحدد Start compute وانتظر حتى يتم تشغيله.

تأكد من أن النواة، الموجودة في أعلى اليمين، هي
Python 3.10 - SDK v2. إذا لم يكن الأمر كما هو، فاستخدم القائمة المنسدلة لتحديد هذا النواة.
إذا رأيت شعارا يشير إلى أنك بحاجة إلى المصادقة، فحدد المصادقة.



هام
يحتوي باقي هذا البرنامج التعليمي على خلايا دفتر ملاحظات البرنامج التعليمي. انسخها/الصقها في دفتر الملاحظات الجديد، أو قم بالتبديل إلى دفتر الملاحظات الآن إذا قمت باستنساخه.
تنزيل البيانات المستخدمة في هذا البرنامج التعليمي
لاستيعاب البيانات، يعالج Azure Data Explorer البيانات الأولية بهذه التنسيقات. يستخدم هذا البرنامج التعليمي نموذج بيانات عميل بطاقة الائتمان بتنسيق CSV. نرى الخطوات تتم في مورد Azure التعلم الآلي. في هذا المورد، سنقوم بإنشاء مجلد محلي بالاسم المقترح للبيانات مباشرة ضمن المجلد حيث يوجد دفتر الملاحظات هذا.
إشعار
يعتمد هذا البرنامج التعليمي على البيانات الموضوعة في موقع مجلد مورد Azure التعلم الآلي. بالنسبة لهذا البرنامج التعليمي، يعني "محلي" موقع مجلد في مورد Azure التعلم الآلي هذا.
حدد Open terminal أسفل النقاط الثلاث، كما هو موضح في هذه الصورة:
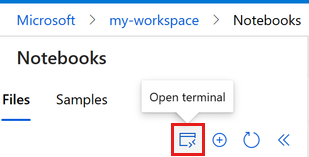
تفتح نافذة المحطة الطرفية في علامة تبويب جديدة.
تأكد من أنك
cdفي المجلد نفسه حيث يوجد دفتر الملاحظات هذا. على سبيل المثال، إذا كان دفتر الملاحظات في مجلد يسمى get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedأدخل هذه الأوامر في نافذة المحطة الطرفية لنسخ البيانات إلى مثيل الحساب الخاص بك:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvيمكنك الآن إغلاق نافذة المحطة الطرفية.
تعرف على المزيد حول هذه البيانات على مستودع التعلم الآلي UCI.
إنشاء مقبض لمساحة العمل
قبل أن نتعمق في التعليمات البرمجية، تحتاج إلى طريقة للإشارة إلى مساحة العمل الخاصة بك. ستقوم بإنشاء ml_client مقبض لمساحة العمل. ثم ستستخدم ml_client لإدارة الموارد والوظائف.
في الخلية التالية، أدخل معرف الاشتراك واسم مجموعة الموارد واسم مساحة العمل. للعثور على هذه القيم:
- في شريط أدوات أستوديو Azure Machine Learning العلوي الأيمن، حدد اسم مساحة العمل الخاصة بك.
- انسخ قيمة مساحة العمل ومجموعة الموارد ومعرف الاشتراك في التعليمات البرمجية.
- ستحتاج إلى نسخ قيمة واحدة، وإغلاق المنطقة ولصقها، ثم العودة إلى القيمة التالية.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
إشعار
لن يؤدي إنشاء MLClient إلى الاتصال بمساحة العمل. تهيئة العميل كسولة، ستنتظر للمرة الأولى التي يحتاج فيها إلى إجراء مكالمة (سيحدث هذا في خلية التعليمات البرمجية التالية).
تحميل البيانات إلى التخزين السحابي
يستخدم Azure التعلم الآلي معرفات الموارد الموحدة (URIs)، التي تشير إلى مواقع التخزين في السحابة. يسهل URI الوصول إلى البيانات في دفاتر الملاحظات والمهام. تبدو تنسيقات URI للبيانات مشابهة لعناوين URL على الويب التي تستخدمها في مستعرض الويب للوصول إلى صفحات الويب. على سبيل المثال:
- الوصول إلى البيانات من خادم https العام:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - الوصول إلى البيانات من Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
يشبه أصل بيانات Azure التعلم الآلي الإشارات المرجعية لمستعرض الويب (المفضلة). بدلا من تذكر مسارات التخزين الطويلة (URIs) التي تشير إلى البيانات الأكثر استخداما، يمكنك إنشاء أصل بيانات، ثم الوصول إلى هذا الأصل باسم مألوف.
ينشئ إنشاء أصول البيانات أيضا مرجعا إلى موقع مصدر البيانات، جنبا إلى جنب مع نسخة من بيانات التعريف الخاصة به. نظرا لأن البيانات تظل في موقعها الحالي، فإنك لا تتحمل أي تكلفة تخزين إضافية، ولا تخاطر بسلامة مصدر البيانات. يمكنك إنشاء أصول البيانات من مخازن بيانات Azure التعلم الآلي وتخزين Azure وعناوين URL العامة والملفات المحلية.
تلميح
بالنسبة لتحميلات البيانات الأصغر حجما، يعمل Azure التعلم الآلي إنشاء أصول البيانات بشكل جيد لتحميل البيانات من موارد الجهاز المحلي إلى التخزين السحابي. يتجنب هذا النهج الحاجة إلى أدوات أو أدوات مساعدة إضافية. ومع ذلك، قد يتطلب تحميل البيانات بحجم أكبر أداة أو أداة مساعدة مخصصة - على سبيل المثال، azcopy. تنقل أداة سطر الأوامر azcopy البيانات من وإلى Azure Storage. تعرف على المزيد حول azcopy هنا.
تنشئ خلية دفتر الملاحظات التالية أصل البيانات. يقوم نموذج التعليمات البرمجية بتحميل ملف البيانات الأولية إلى مورد التخزين السحابي المعين.
في كل مرة تقوم فيها بإنشاء أصل بيانات، تحتاج إلى إصدار فريد له. إذا كان الإصدار موجودا بالفعل، فستتلقى خطأ. في هذه التعليمة البرمجية، نستخدم "الأولي" للقراءة الأولى للبيانات. إذا كان هذا الإصدار موجودا بالفعل، فسنتخطى إنشائه مرة أخرى.
يمكنك أيضا حذف معلمة الإصدار ، ويتم إنشاء رقم إصدار لك، بدءا من 1 ثم زيادة من هناك.
في هذا البرنامج التعليمي، نستخدم الاسم "الأولي" كإصدار أول. سيستخدم البرنامج التعليمي إنشاء مسارات التعلم الآلي للإنتاج أيضا هذا الإصدار من البيانات، لذلك هنا نستخدم قيمة سترى مرة أخرى في هذا البرنامج التعليمي.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
يمكنك رؤية البيانات التي تم تحميلها عن طريق تحديد Data على اليسار. سترى تحميل البيانات وإنشاء أصل بيانات:
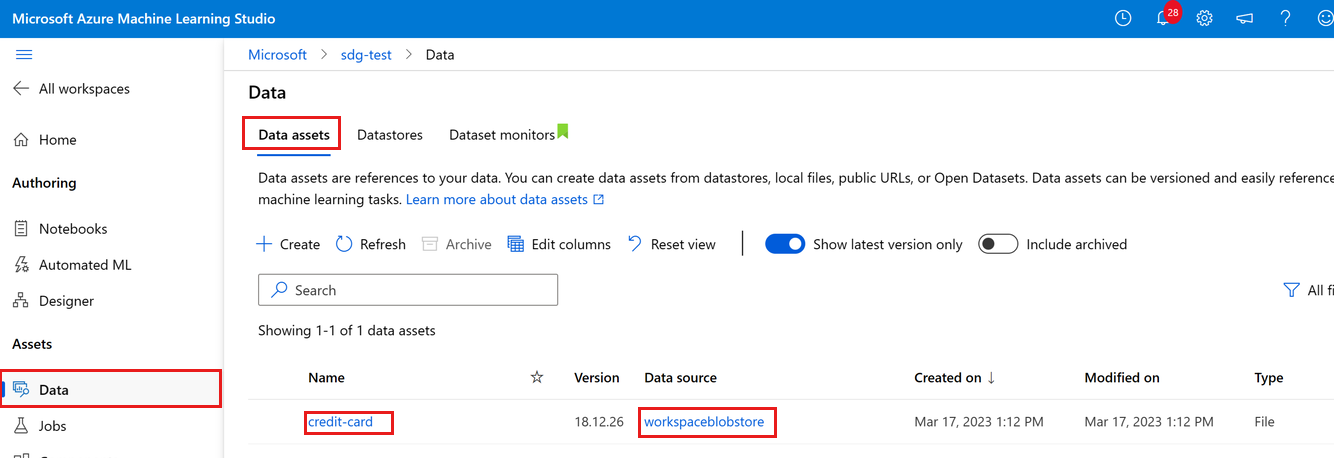
تسمى هذه البيانات ببطاقة الائتمان، وفي علامة التبويب Data assets، يمكننا رؤيتها في عمود Name. تم تحميل هذه البيانات إلى مخزن البيانات الافتراضي لمساحة العمل المسمى workspaceblobstore، الذي يظهر في عمود مصدر البيانات.
مخزن بيانات Azure التعلم الآلي هو مرجع إلى حساب تخزين موجود على Azure. يوفر مخزن البيانات هذه المزايا:
- واجهة برمجة تطبيقات شائعة وسهلة الاستخدام، للتفاعل مع أنواع تخزين مختلفة (Blob/Files/Azure Data Lake Storage) وأساليب المصادقة.
- طريقة أسهل لاكتشاف مخازن البيانات المفيدة، عند العمل كفريق.
- في البرامج النصية، طريقة لإخفاء معلومات الاتصال للوصول إلى البيانات المستندة إلى بيانات الاعتماد (كيان الخدمة/SAS/المفتاح).
الوصول إلى بياناتك في دفتر ملاحظات
تدعم Pandas عناوين URI مباشرة - يوضح هذا المثال كيفية قراءة ملف CSV من Azure التعلم الآلي Datastore:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
ومع ذلك، كما ذكرنا سابقا، قد يصبح من الصعب تذكر معرفات URI هذه. بالإضافة إلى ذلك، يجب استبدال كافة <قيم السلسلة> الفرعية يدويا في الأمر pd.read_csv بالقيم الحقيقية لمواردك.
ستحتاج إلى إنشاء أصول بيانات للبيانات التي يتم الوصول إليها بشكل متكرر. فيما يلي طريقة أسهل للوصول إلى ملف CSV في Pandas:
هام
في خلية دفتر ملاحظات، نفذ هذه التعليمة البرمجية لتثبيت azureml-fsspec مكتبة Python في نواة Jupyter:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
اقرأ الوصول إلى البيانات من تخزين سحابة Azure أثناء التطوير التفاعلي لمعرفة المزيد حول الوصول إلى البيانات في دفتر ملاحظات.
إنشاء إصدار جديد من أصل البيانات
ربما لاحظت أن البيانات تحتاج إلى القليل من التنظيف الخفيف، لجعلها مناسبة لتدريب نموذج التعلم الآلي. يحتوي على:
- رأسان
- عمود معرف العميل؛ لن نستخدم هذه الميزة في التعلم الآلي
- المسافات في اسم متغير الاستجابة
أيضا، مقارنة بتنسيق CSV، يصبح تنسيق ملف Parquet طريقة أفضل لتخزين هذه البيانات. يوفر Parquet الضغط، ويحافظ على المخطط. لذلك، لتنظيف البيانات وتخزينها في Parquet، استخدم:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
يعرض هذا الجدول بنية البيانات في ملف default_of_credit_card_clients.csv الأصلي . تم تنزيل ملف CSV في خطوة سابقة. تحتوي البيانات التي تم تحميلها على 23 متغيرا توضيحيا ومتغير استجابة 1، كما هو موضح هنا:
| اسم (أسماء) العمود | نوع المتغير | الوصف |
|---|---|---|
| X1 | التفسيريه | مبلغ الائتمان المحدد (الدولار الأمريكي): يشمل كلا من الائتمان الاستهلاكي الفردي والائتمان العائلي (التكميلي). |
| X2 | التفسيريه | الجنس (1 = ذكر؛ 2 = أنثى). |
| X3 | التفسيريه | التعليم (1 = كلية الدراسات العليا؛ 2 = جامعة؛ 3 = مدرسة ثانوية؛ 4 = أخرى). |
| X4 | التفسيريه | الحالة الزوجية (1 = متزوج؛ 2 = عزباء؛ 3 = آخرين). |
| X5 | التفسيريه | العمر (سنوات). |
| X6-X11 | التفسيريه | تاريخ الدفع الماضي. وتعقبنا سجلات الدفع الشهرية السابقة (من نيسان/أبريل إلى أيلول/سبتمبر 2005). -1 = الدفع حسب الأصول؛ 1 = تأخير الدفع لمدة شهر واحد؛ 2 = تأخير الدفع لمدة شهرين؛ . . .; 8 = تأخير الدفع لمدة ثمانية أشهر؛ 9 = تأخير الدفع لمدة تسعة أشهر وما فوق. |
| X12-17 | التفسيريه | مبلغ بيان الفاتورة (بالدولار الأمريكي) من نيسان/أبريل إلى أيلول/سبتمبر 2005. |
| X18-23 | التفسيريه | مبلغ الدفعة السابقة (NT dollar) من نيسان/أبريل إلى أيلول/سبتمبر 2005. |
| Y | استجابة | الدفع الافتراضي (نعم = 1، لا = 0) |
بعد ذلك، قم بإنشاء إصدار جديد من أصل البيانات (يتم تحميل البيانات تلقائيا إلى التخزين السحابي). بالنسبة لهذا الإصدار، سنضيف قيمة وقت، بحيث يتم إنشاء رقم إصدار مختلف في كل مرة يتم فيها تشغيل هذه التعليمة البرمجية.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
ملف parquet الذي تم تنظيفه هو أحدث مصدر بيانات الإصدار. تعرض هذه التعليمة البرمجية مجموعة نتائج إصدار CSV أولا، ثم إصدار Parquet:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
تنظيف الموارد
إذا كنت تخطط للمتابعة الآن إلى البرامج التعليمية الأخرى، فانتقل إلى الخطوات التالية.
إيقاف حساب مثيل
إذا كنت لن تستخدمه الآن، فأوقف مثيل الحساب:
- في الاستوديو، في منطقة التنقل اليسرى، حدد Compute.
- في علامات التبويب العليا، حدد "Compute instances"
- حدد "compute instance" في القائمة.
- في شريط الأدوات العلوي، حدد "Stop".
حذف كافة الموارد
هام
يمكن استخدام الموارد التي قمت بإنشائها كمتطلبات أساسية لبرامج تعليمية أخرى في Azure ومقالات إرشادية.
إذا كنت لا تخطط لاستخدام الموارد التي أنشأتها، فاحذفها، حتى لا تتحمل أي رسوم:
من مدخل Microsoft Azure، حدد Resource groups من أقصى الجانب الأيمن.
من القائمة، حدد مجموعة الموارد التي أنشأتها.
حدد Delete resource group.
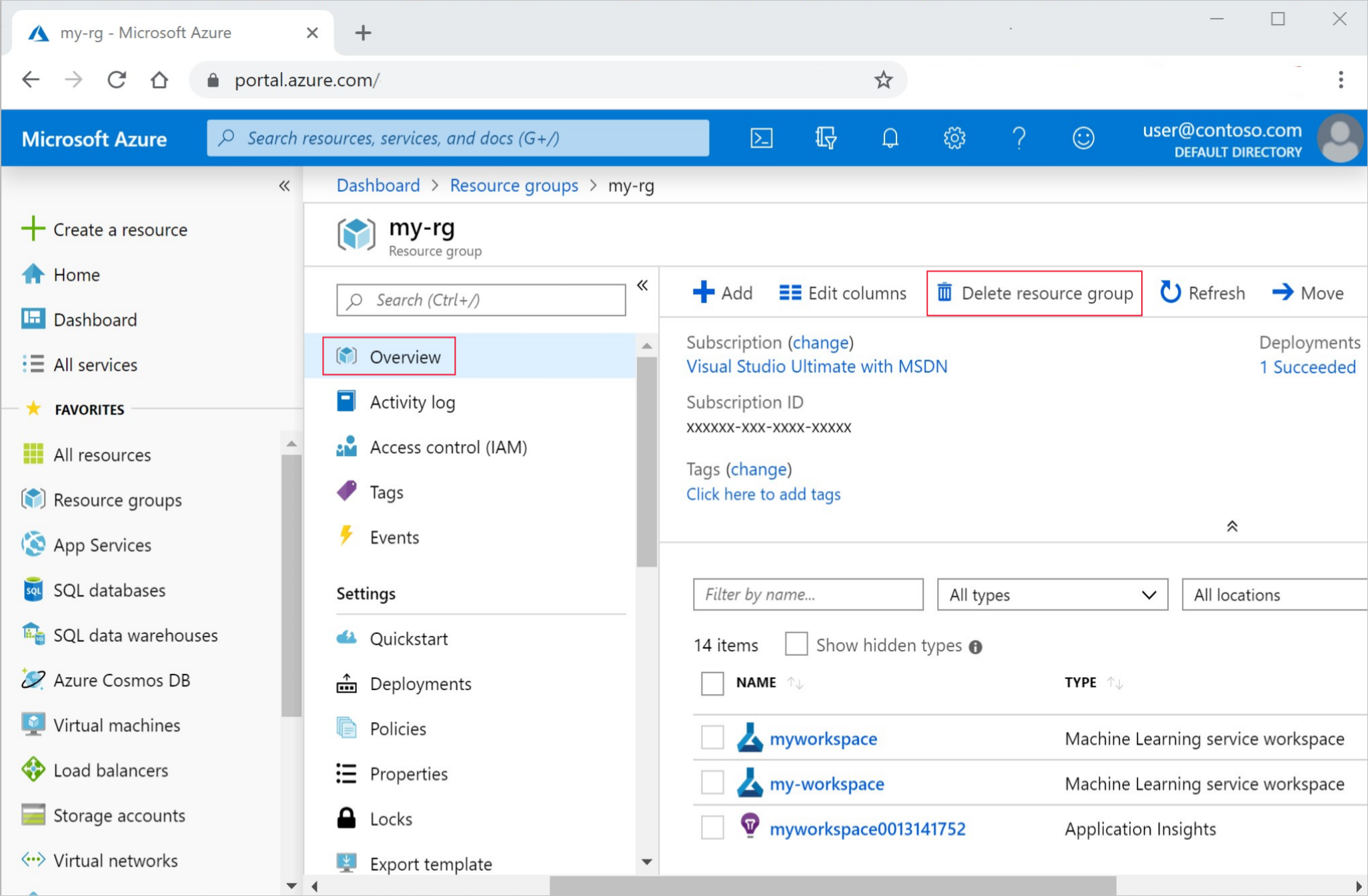
أدخل اسم مجموعة الموارد. ثم حدد حذف.
الخطوات التالية
اقرأ إنشاء أصول بيانات لمزيد من المعلومات حول أصول البيانات.
اقرأ إنشاء مخازن البيانات لمعرفة المزيد حول مخازن البيانات.
تابع البرامج التعليمية لمعرفة كيفية تطوير برنامج نصي للتدريب.