Tento článek popisuje osvědčené postupy pro monitorování aplikace mikroslužeb, která běží ve službě Azure Kubernetes Service (AKS). Mezi konkrétní témata patří shromažďování telemetrie, monitorování stavu clusteru, metriky, protokolování, strukturované protokolování a distribuované trasování. Druhá možnost je znázorněna v tomto diagramu:

Stáhněte si soubor aplikace Visio s touto architekturou.
Shromažďování telemetrie
V jakékoli složité aplikaci se v určitém okamžiku něco pokazí. V aplikaci mikroslužeb je potřeba sledovat, co se děje napříč desítkami nebo dokonce stovkami služeb. Abyste měli představu o tom, co se děje, musíte shromažďovat telemetrická data z aplikace. Telemetrii je možné rozdělit do těchto kategorií: protokoly, trasování a metriky.
Protokoly jsou textové záznamy událostí, ke kterým dochází, když je aplikace spuštěná. Zahrnují například protokoly aplikací (příkazy trasování) a protokoly webového serveru. Protokoly jsou primárně užitečné pro forenzní a analýzu původní příčiny.
Trasování, označovaná také jako operace, propojují kroky jednoho požadavku napříč několika voláními v rámci mikroslužeb a napříč mikroslužbami. Mohou poskytovat strukturovanou pozorovatelnost v interakcích systémových komponent. Trasování může začít v rané fázi procesu žádosti, například v uživatelském rozhraní aplikace, a může se rozšířit prostřednictvím síťových služeb v síti mikroslužeb, které zpracovávají požadavek.
- Rozsahy jsou jednotky práce v rámci trasování. Každé rozpětí je propojené s jedním trasováním a lze je vnořit s jinými rozsahy. Často odpovídají jednotlivým požadavkům v operaci mezi službami, ale mohou také definovat práci v jednotlivých komponentách v rámci služby. Zahrnuje také sledování odchozích volání z jedné služby do druhé. (Někdy se říká záznamy závislostí.)
Metriky jsou číselné hodnoty, které je možné analyzovat. Můžete je použít k pozorování systému v reálném čase (nebo téměř v reálném čase) nebo k analýze trendů výkonu v průběhu času. Abyste porozuměli systému holisticky, musíte shromažďovat metriky na různých úrovních architektury, od fyzické infrastruktury až po aplikaci, včetně:
Metriky na úrovni uzlů, včetně využití procesoru, paměti, sítě, disku a systému souborů. Systémové metriky pomáhají porozumět přidělování prostředků pro každý uzel v clusteru a řešit potíže s odlehlými hodnotami.
Metriky kontejnerů U kontejnerizovaných aplikací potřebujete shromažďovat metriky na úrovni kontejneru, nejen na úrovni virtuálního počítače.
Metriky aplikací . Tyto metriky jsou relevantní pro pochopení chování služby. Mezi příklady patří počet příchozích požadavků HTTP ve frontě, latence požadavků a délka fronty zpráv. Aplikace můžou také používat vlastní metriky specifické pro doménu, například počet zpracovaných obchodních transakcí za minutu.
Metriky závislé služby Služby někdy volají externí služby nebo koncové body, jako jsou spravované služby PaaS nebo služby SaaS. Služby třetích stran nemusí poskytovat metriky. Pokud ne, musíte se spolehnout na vlastní metriky aplikace, abyste mohli sledovat statistiky latence a míry chyb.
Monitorování stavu clusteru
Pomocí služby Azure Monitor můžete monitorovat stav clusterů. Následující snímek obrazovky ukazuje cluster s kritickými chybami v podech nasazených uživatelem:

Odsud můžete přejít k podrobnostem a najít problém. Pokud je ImagePullBackoffnapříklad stav podu , Kubernetes nemohl vyžádat image kontejneru z registru. Příčinou tohoto problému může být neplatná značka kontejneru nebo chyba ověřování při přijetí změn z registru.
Pokud dojde k chybovému ukončení kontejneru, kontejner State se stane Waitings CrashLoopBackOffReason V případě typického scénáře, kdy je pod součástí sady replik a zásada opakování je Always, tento problém se ve stavu clusteru nezobrazuje jako chyba. Můžete ale spouštět dotazy nebo nastavit upozornění pro tuto podmínku. Další informace najdete v tématu Vysvětlení výkonu clusteru AKS pomocí přehledů kontejnerů služby Azure Monitor.
V podokně sešitů prostředku AKS je k dispozici více sešitů specifických pro kontejnery. Tyto sešity můžete použít k rychlému přehledu, řešení potíží, správě a přehledům. Následující snímek obrazovky ukazuje seznam sešitů, které jsou ve výchozím nastavení dostupné pro úlohy AKS.

Metriky
Ke shromažďování a zobrazení metrik pro clustery AKS a všech dalších závislých služeb Azure doporučujeme použít monitorování .
Pro metriky clusteru a kontejneru povolte přehledy kontejnerů služby Azure Monitor. Pokud je tato funkce povolená, monitor shromažďuje metriky paměti a procesoru z kontrolerů, uzlů a kontejnerů prostřednictvím rozhraní API metrik Kubernetes. Další informace o metrikách dostupných v Přehledech kontejnerů najdete v tématu Vysvětlení výkonu clusteru AKS pomocí přehledů kontejnerů služby Azure Monitor.
Pomocí Přehledy aplikace můžete shromažďovat metriky aplikací. Aplikační Přehledy je rozšiřitelná služba správy výkonu aplikací (APM). Pokud ho chcete použít, nainstalujte do své aplikace balíček instrumentace. Tento balíček monitoruje aplikaci a odesílá telemetrická data do aplikace Přehledy. Může také načíst telemetrická data z hostitelského prostředí. Data se pak odesílají do monitorování. Aplikační Přehledy také poskytuje integrované korelace a sledování závislostí. (Viz Distribuované trasování, dále v tomto článku.)
Aplikační Přehledy má maximální propustnost měřenou v událostech za sekundu a omezuje telemetrii, pokud rychlost dat překročí limit. Podrobnosti najdete v tématu Omezení Přehledy aplikací. Vytvořte pro každé prostředí různé instance aplikačních Přehledy, aby vývojová/testovací prostředí nekonkurují produkční telemetrii pro kvótu.
Jedna operace může vygenerovat mnoho událostí telemetrie, takže pokud aplikace zaznamená velký objem provozu, bude jeho zachytávání telemetrie pravděpodobně omezené. Pokud chcete tento problém zmírnit, můžete provést vzorkování, abyste snížili provoz telemetrie. Kompromisem je, že vaše metriky budou méně přesné, pokud instrumentace nepodporuje předběžnou agregaci. V takovém případě bude pro řešení potíží méně vzorků trasování, ale metriky udržují přesnost. Další informace najdete v tématu Vzorkování v Přehledy aplikace. Objem dat můžete také snížit agregací metrik. To znamená, že můžete vypočítat statistické hodnoty, jako je průměr a směrodatná odchylka, a odeslat tyto hodnoty místo nezpracované telemetrie. Tento blogový příspěvek popisuje přístup k používání aplikačních Přehledy ve velkém měřítku: Monitorování a analýzy Azure ve velkém měřítku.
Pokud je rychlost dat dostatečně vysoká pro aktivaci omezování a vzorkování nebo agregace nejsou přijatelné, zvažte export metrik do databáze časových řad, jako je Azure Data Explorer, Prometheus nebo InfluxDB, spuštěná v clusteru.
Azure Data Explorer je služba pro zkoumání dat nativní pro Azure a vysoce škálovatelná služba pro zkoumání dat protokolů a telemetrie. Nabízí podporu více formátů dat, bohatého dotazovacího jazyka a připojení pro využívání dat v oblíbených nástrojích, jako jsou Jupyter Notebooks a Grafana. Azure Data Explorer má integrované konektory pro příjem dat protokolů a metrik prostřednictvím služby Azure Event Hubs. Další informace najdete v tématu Ingestování a dotazování dat monitorování v Azure Data Exploreru.
InfluxDB je systém založený na nabízených oznámeních. Agent musí nasdílit metriky. K nastavení monitorování Kubernetes můžete použít stack TICK. Dále můžete odesílat metriky do influxDB pomocí Telegrafu, což je agent pro shromažďování a generování sestav metrik. InfluxDB můžete použít pro nepravidelné události a datové typy řetězců.
Prometheus je systém založený na vyžádání. Pravidelně se střižuje metriky z nakonfigurovaných umístění. Prometheus může ztěžovat metriky generované službou Azure Monitor nebo metrikami kube-state-metrics. kube-state-metrics je služba, která shromažďuje metriky ze serveru rozhraní Kubernetes API a zpřístupňuje je pro Prometheus (nebo škrabku, která je kompatibilní s koncovým bodem klienta Prometheus). Pro systémové metriky použijte exportér uzlů, což je exportér pro systémové metriky. Prometheus podporuje data s plovoucí desetinnou čárkou, ale ne řetězcová data, takže je vhodná pro systémové metriky, ale ne protokoly. Server metrik Kubernetes je agregátorem využití prostředků v celém clusteru.
Protokolování
Tady jsou některé obecné problémy s protokolováním v aplikaci mikroslužeb:
- Vysvětlení kompletního zpracování požadavku klienta, kde může být vyvoláno více služeb pro zpracování jednoho požadavku.
- Sloučení protokolů z více služeb do jednoho agregovaného zobrazení
- Analýza protokolů, které pocházejí z více zdrojů, které používají vlastní schémata protokolování nebo nemají žádné konkrétní schéma. Protokoly můžou generovat komponenty třetích stran, které neřídíte.
- Architektury mikroslužeb často generují větší objem protokolů než tradiční monolity, protože transakce obsahuje více služeb, síťových volání a kroků. To znamená, že samotné protokolování může být kritickým bodem výkonu nebo prostředků pro aplikaci.
Architektury založené na Kubernetes mají několik dalších problémů:
- Kontejnery se můžou pohybovat a přeplánovat.
- Kubernetes má abstrakci sítí, která používá virtuální IP adresy a mapování portů.
V Kubernetes je standardním přístupem k protokolování kontejner zapisovat protokoly do stdout a stderr. Modul kontejneru tyto streamy přesměruje na ovladač protokolování. Pokud chcete usnadnit dotazování a zabránit možné ztrátě dat protokolu, pokud uzel přestane reagovat, je obvyklým přístupem shromáždit protokoly z každého uzlu a odeslat je do centrálního umístění úložiště.
Azure Monitor se integruje s AKS, aby tento přístup podporoval. Monitor shromažďuje protokoly kontejnerů a odesílá je do pracovního prostoru služby Log Analytics. Odtud můžete použít dotazovací jazyk Kusto k zápisu dotazů napříč agregovanými protokoly. Tady je například dotaz Kusto pro zobrazení protokolů kontejneru pro zadaný pod:
ContainerLogV2
| where PodName == "podName" //update with target pod
| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource
Azure Monitor je spravovaná služba a konfigurace clusteru AKS pro použití služby Monitor je jednoduchá změna konfigurace v rozhraní příkazového řádku nebo šabloně Azure Resource Manageru. (Další informace najdete v tématu Jak povolit přehledy kontejnerů služby Azure Monitor.) Další výhodou použití služby Azure Monitor je, že konsoliduje vaše protokoly AKS s dalšími protokoly platformy Azure, aby poskytoval jednotné prostředí monitorování.
Azure Monitor se účtuje za gigabajt (GB) přijatých dat do služby. (Viz Ceny služby Azure Monitor.) Při vysokých objemech můžou být náklady důležité. Pro ekosystém Kubernetes je k dispozici řada opensourcových alternativ. Mnoho organizací například používá Fluentd s Elasticsearch. Fluentd je opensourcový kolektor dat a Elasticsearch je databáze dokumentů, která se používá k vyhledávání. Výzvou s těmito možnostmi je, že vyžadují další konfiguraci a správu clusteru. V případě produkční úlohy možná budete muset experimentovat s nastavením konfigurace. Budete také muset monitorovat výkon infrastruktury protokolování.
OpenTelemetry
OpenTelemetry je mezi odvětvími úsilí o zlepšení trasování tím, že standardizuje rozhraní mezi aplikacemi, knihovnami, telemetrií a kolektory dat. Pokud používáte knihovnu a architekturu instrumentovanou pomocí OpenTelemetry, většina operací trasování, které jsou tradičně systémové operace, zpracovává podkladové knihovny, které zahrnují následující běžné scénáře:
- Protokolování základních operací požadavků, jako je čas spuštění, čas ukončení a doba trvání
- Vyvolané výjimky
- Šíření kontextu (například odeslání ID korelace přes hranice volání HTTP)
Místo toho základní knihovny a architektury, které zpracovávají tyto operace, vytvářejí bohaté vzájemně propojené struktury a trasují datové struktury a šíří je napříč kontexty. Před OpenTelemetry se tyto zprávy obvykle vkládají jako speciální zprávy protokolu nebo jako proprietární datové struktury, které byly specifické pro dodavatele, který vytvořil monitorovací nástroje. OpenTelemetry také podporuje bohatší datový model instrumentace než tradiční přístup založený na protokolování a protokoly jsou užitečnější, protože zprávy protokolu jsou propojeny s trasováním a rozsahem jejich generování. To často usnadňuje hledání protokolů přidružených ke konkrétní operaci nebo požadavku.
Mnohé sady Azure SDK jsou instrumentované pomocí OpenTelemetry nebo jsou v procesu jeho implementace.
Vývojář aplikace může přidat ruční instrumentaci pomocí sad OpenTelemetry SDK k provedení následujících aktivit:
- Přidejte instrumentaci, ve které ji podkladová knihovna neposkytuje.
- Rozšíření kontextu trasování přidáním rozsahů pro zveřejnění jednotek práce specifických pro aplikaci (například smyčka objednávek, která vytváří rozsah pro zpracování každého řádku objednávky).
- Rozšíření existujících rozsahů pomocí klíčů entit za účelem snadnějšího trasování (Například přidejte klíč/hodnotu OrderID do požadavku, který zpracovává danou objednávku.) Tyto klíče se zobrazují monitorovacími nástroji jako strukturované hodnoty pro dotazování, filtrování a agregaci (bez analýzy řetězců zpráv protokolu nebo hledání kombinací sekvencí zpráv protokolu, jak tomu bylo u přístupu při prvním protokolování).
- Šíření kontextu trasování přístupem k atributům trasování a rozsahu, vložením traceIds do odpovědí a datových částí a/nebo čtením traceId z příchozích zpráv za účelem vytvoření požadavků a rozsahů.
Další informace o instrumentaci a sadách OpenTelemetry SDK najdete v dokumentaci k OpenTelemetry.
Application Insights
Aplikace Přehledy shromažďuje bohatá data z OpenTelemetry a jeho instrumentačních knihoven a zachytává je v efektivním úložišti dat, aby poskytovala bohatou podporu vizualizací a dotazů. Instrumentační knihovny založené na OpenTelemetry aplikace Přehledy pro jazyky, jako jsou .NET, Java, Node.js a Python, usnadňují odesílání telemetrických dat do aplikačního Přehledy.
Pokud používáte .NET Core, doporučujeme zvážit také Přehledy aplikace pro knihovnu Kubernetes. Tato knihovna rozšiřuje trasování aplikací Přehledy dalšími informacemi, jako je kontejner, uzel, pod, popisky a sada replik.
Application Přehledy mapuje kontext OpenTelemetry na jeho interní datový model:
- Trasování –> operace
- ID trasování –> ID operace
- Rozsah –> požadavek nebo závislost
Vezměte v úvahu následující skutečnosti:
- Aplikace Přehledy omezí telemetrii, pokud rychlost dat překročí maximální limit. Podrobnosti najdete v tématu Omezení Přehledy aplikací. Jedna operace může generovat několik událostí telemetrie, takže pokud aplikace zaznamená velký objem provozu, pravděpodobně dojde k omezení.
- Vzhledem k tomu, že aplikace Přehledy dávková data, můžete dávku ztratit, pokud proces selže s neošetřenou výjimkou.
- Fakturace Přehledy aplikací vychází z objemu dat. Další informace najdete v tématu Správa cen a objemu dat v Přehledy aplikace.
Strukturované protokolování
Pokud chcete usnadnit parsování protokolů, použijte strukturované protokolování, pokud je to možné. Při použití strukturovaného protokolování aplikace zapisuje protokoly ve strukturovaném formátu, jako je JSON, a ne výstup nestrukturovaných textových řetězců. K dispozici je mnoho knihoven strukturovaného protokolování. Tady je například příkaz protokolování, který používá knihovnu Serilog pro .NET Core:
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
...
}
V této části volání LogInformation zahrnuje Id parametr a DeliveryInfo parametr. Pokud používáte strukturované protokolování, tyto hodnoty nejsou interpolovány do řetězce zprávy. Místo toho výstup protokolu vypadá přibližně takto:
{"@t":"2019-06-13T00:57:09.9932697Z","@mt":"In Put action with delivery {Id}: {@DeliveryInfo}","Id":"36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef","DeliveryInfo":{...
Jedná se o řetězec JSON, ve kterém @t je pole časové razítko, @mt je řetězec zprávy a zbývající páry klíč/hodnota jsou parametry. Vytváření výstupu formátu JSON usnadňuje dotazování dat strukturovaným způsobem. Například následující dotaz Log Analytics napsaný v dotazovacím jazyce Kusto vyhledá instance této konkrétní zprávy ze všech kontejnerů s názvem fabrikam-delivery:
traces
| where customDimensions.["Kubernetes.Container.Name"] == "fabrikam-delivery"
| where customDimensions.["{OriginalFormat}"] == "In Put action with delivery {Id}: {@DeliveryInfo}"
| project message, customDimensions["Id"], customDimensions["@DeliveryInfo"]
Pokud výsledek zobrazíte na webu Azure Portal, uvidíte, že DeliveryInfo se jedná o strukturovaný záznam, který obsahuje serializovanou reprezentaci DeliveryInfo modelu:

Tady je JSON z tohoto příkladu:
{
"Id": "36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef",
"Owner": {
"UserId": "user id for logging",
"AccountId": "52dadf0c-0067-43e7-af76-86e32b48bc5e"
},
"Pickup": {
"Altitude": 0.29295161612934972,
"Latitude": 0.26815900219052985,
"Longitude": 0.79841844309047727
},
"Dropoff": {
"Altitude": 0.31507750848078986,
"Latitude": 0.753494655598651,
"Longitude": 0.89352830773849423
},
"Deadline": "string",
"Expedited": true,
"ConfirmationRequired": 0,
"DroneId": "AssignedDroneId01ba4d0b-c01a-4369-ba75-51bde0e76cc9"
}
Mnoho zpráv protokolu označuje začátek nebo konec pracovní jednotky nebo propojí obchodní entitu se sadou zpráv a operací pro sledovatelnost. V mnoha případech je rozšiřování openTelemetry span a objektů požadavků lepším přístupem než protokolováním pouze zahájení a konce operace. Tím se tento kontext přidá ke všem připojeným trasováním a podřízeným operacím a umístí tyto informace do rozsahu úplné operace. Sady OpenTelemetry SDK pro různé jazyky podporují vytváření rozsahů nebo přidávání vlastních atributů do rozsahů. Například následující kód používá sadu Java OpenTelemetry SDK, která je podporována aplikací Přehledy. Existující nadřazené rozpětí (například rozsah požadavku přidružený ke volání kontroleru REST a vytvořený používaným webovou architekturou) se dá rozšířit o ID entity, které je k němu přidružené, jak je znázorněno tady:
import io.opentelemetry.api.trace.Span;
// ...
Span.current().setAttribute("A1234", deliveryId);
Tento kód nastaví klíč nebo hodnotu v aktuálním rozsahu, který je připojený k operacím a protokolovacím zprávám, ke kterým dochází v daném rozsahu. Hodnota se zobrazí v objektu požadavku Přehledy aplikace, jak je znázorněno zde:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project timestamp, name, url, success, resultCode, duration, operation_Id, deliveryId
Tato technika se stává výkonnější při použití s protokoly, filtrováním a přidáváním poznámek trasování protokolů s kontextem rozsahu, jak je znázorněno tady:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project deliveryId, operation_Id, requestTimestamp = timestamp, requestDuration = duration // keep some request info
| join kind=inner traces on operation_Id // join logs only for this deliveryId
| project requestTimestamp, requestDuration, logTimestamp = timestamp, deliveryId, message
Pokud používáte knihovnu nebo architekturu, která už je instrumentovaná pomocí OpenTelemetry, zpracovává vytváření rozsahů a požadavků, ale kód aplikace může také vytvářet jednotky práce. Například metoda, která prochází polem entit, které provádějí práci na každém z nich, může vytvořit rozsah pro každou iteraci smyčky zpracování. Informace o přidání instrumentace do kódu aplikace a knihovny naleznete v dokumentaci k instrumentaci OpenTelemery.
Distribuované trasování
Jednou z výzev při používání mikroslužeb je pochopení toku událostí napříč službami. Jedna transakce může zahrnovat volání více služeb.
Příklad distribuovaného trasování
Tento příklad popisuje cestu distribuované transakce prostřednictvím sady mikroslužeb. Příklad je založený na aplikaci pro doručování pomocí dronů.
V tomto scénáři distribuovaná transakce zahrnuje tyto kroky:
- Služba příjmu dat vloží zprávu do fronty služby Azure Service Bus.
- Služba pracovního postupu načítá zprávu z fronty.
- Služba pracovního postupu volá tři back-endové služby pro zpracování požadavku (plánovač dronů, balíček a doručování).
Následující snímek obrazovky ukazuje mapu aplikace pro aplikaci pro doručování pomocí dronů. Tato mapa zobrazuje volání koncového bodu veřejného rozhraní API, které vedou k pracovnímu postupu, který zahrnuje pět mikroslužeb.
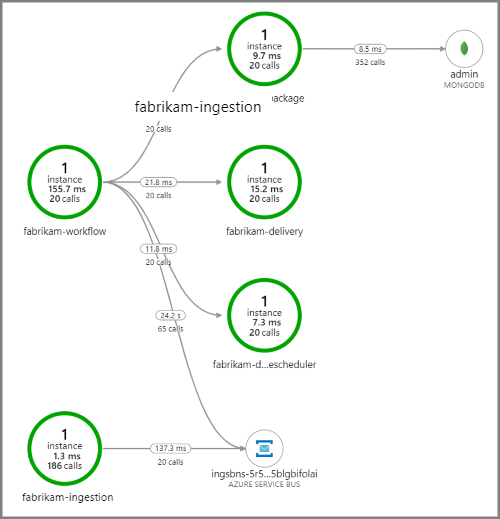
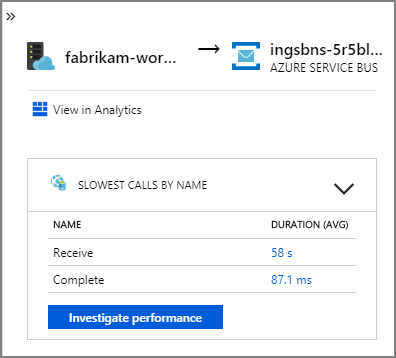
Šipky z fabrikam-workflow fronty a fabrikam-ingestion do fronty služby Service Bus ukazují, kam se zprávy odesílají a přijímají. Z diagramu nemůžete zjistit, která služba odesílá zprávy a která přijímá. Šipky ukazují, že obě služby volají Service Bus. Informace o tom, která služba odesílá a která přijímá, jsou ale k dispozici v podrobnostech:
Vzhledem k tomu, že každé volání obsahuje ID operace, můžete také zobrazit kompletní kroky jedné transakce, včetně informací o časování a volání HTTP v každém kroku. Tady je vizualizace jedné takové transakce:

Tato vizualizace ukazuje kroky ze služby příjmu dat do fronty, z fronty do služby Pracovního postupu a ze služby Pracovního postupu do ostatních back-endových služeb. Posledním krokem je služba pracovního postupu, která označuje zprávu Service Bus jako dokončenou.
Tento příklad ukazuje volání back-endové služby, která selhává:
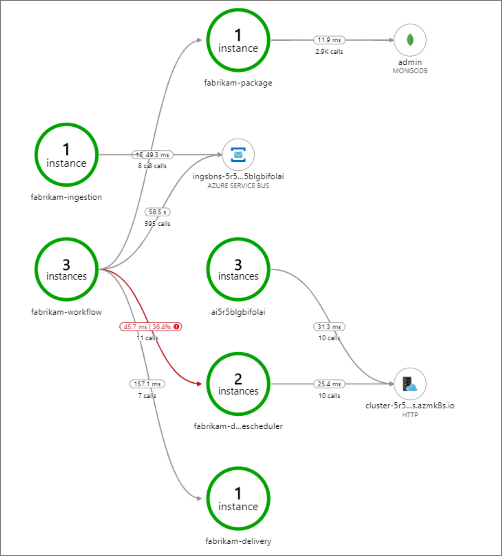
Tato mapa ukazuje, že během období dotazu selhal velký zlomek (36 %) volání do služby Plánovač dronů. Zobrazení komplexní transakce odhalí, že při odeslání požadavku HTTP PUT do služby dojde k výjimce:

Pokud přejdete k podrobnostem dál, uvidíte, že se jedná o výjimku soketu: "Žádné takové zařízení nebo adresa".
Fabrikam.Workflow.Service.Services.BackendServiceCallFailedException:
No such device or address
---u003e System.Net.Http.HttpRequestException: No such device or address
---u003e System.Net.Sockets.SocketException: No such device or address
Tato výjimka naznačuje, že back-endová služba není dostupná. V tuto chvíli můžete k zobrazení konfigurace nasazení použít kubectl. V tomto příkladu se název hostitele služby nepřeloží kvůli chybě v konfiguračních souborech Kubernetes. Článek Ladicí služby v dokumentaci Kubernetes obsahuje tipy pro diagnostiku tohoto typu chyby.
Tady jsou některé běžné příčiny chyb:
- Chyby kódu. Tyto chyby se můžou zobrazit takto:
- Výjimky: Prohlédněte si protokoly aplikace Přehledy a prohlédněte si podrobnosti o výjimce.
- Proces selhává. Prohlédněte si stav kontejneru a podu a prohlédněte si protokoly kontejnerů nebo trasování Přehledy aplikací.
- Chyby HTTP 5xx .
- Vyčerpání prostředků:
- Hledejte omezování (HTTP 429) nebo vypršení časových limitů požadavků.
- Prozkoumejte metriky kontejneru pro procesor, paměť a disk.
- Podívejte se na konfigurace limitů prostředků kontejnerů a podů.
- Zjišťování služeb. Prozkoumejte konfiguraci služby Kubernetes a mapování portů.
- Neshoda rozhraní API Vyhledejte chyby HTTP 400. Pokud jsou rozhraní API verze, podívejte se na verzi, která se volá.
- Při načítání image kontejneru došlo k chybě. Podívejte se na specifikaci podu. Ujistěte se také, že cluster má oprávnění načíst z registru kontejneru.
- Problémy RBAC.
Další kroky
Další informace o funkcích ve službě Azure Monitor, které podporují monitorování aplikací v AKS:
- Přehled přehledů kontejnerů služby Azure Monitor
- Vysvětlení výkonu clusteru AKS pomocí přehledů kontejnerů služby Azure Monitor