Tento klientský projekt pomohl potravinářské společnosti Fortune 500 zlepšit prognózování poptávky. Společnost dodává produkty přímo do více maloobchodních prodejen. Zlepšení jim pomohlo optimalizovat zásoby svých produktů v různých obchodech v několika oblastech USA. Aby toho bylo dosaženo, tým komerčního softwarového inženýrství (CSE) společnosti Microsoft spolupracoval s datovými vědci klienta na pilotní studii, aby vytvořil přizpůsobené modely strojového učení pro vybrané oblasti. Modely berou v úvahu:
- Demografické údaje o nakupujících
- Historické a předpovídané počasí
- Minulé zásilky
- Vrácení produktu
- Zvláštní události
Cílem optimalizace zásob představuje hlavní součást projektu a klient si v počátečních pokusech o prodej uvědomil významný nárůst prodeje. Tým také viděl 40% snížení prognózování průměrné absolutní procentuální chyby (MAPE) ve srovnání s historickým průměrným základním modelem.
Klíčovou součástí projektu bylo zjištění, jak vertikálně navýšit kapacitu pracovního postupu datových věd z pilotní studie na produkční úroveň. Tento pracovní postup na úrovni produkčního prostředí vyžadoval tým CSE, aby:
- Vyvíjejte modely pro mnoho oblastí.
- Průběžně aktualizujte a monitorujte výkon modelů.
- Usnadnit spolupráci mezi datovými a technickými týmy.
Typický pracovní postup datových věd je dnes blíže k jednorázovému testovacímu prostředí než k provoznímu pracovnímu postupu. Prostředí pro datové vědce musí být vhodné pro ně, aby:
- Připravte data.
- Experimentujte s různými modely.
- Ladění hyperparametrů
- Vytvořte cyklus sestavení-test-evaluate-refine.
Většina nástrojů používaných pro tyto úlohy má specifické účely a není vhodná pro automatizaci. V operaci strojového učení na úrovni produkčního prostředí je potřeba zvážit více informací o správě životního cyklu aplikací a DevOps.
Tým CSE pomohl klientovi vertikálně navýšit kapacitu operace na produkční úrovně. Implementovali různé aspekty možností kontinuální integrace a průběžného doručování (CI/CD) a vyřešili problémy, jako je pozorovatelnost a integrace s možnostmi Azure. Během implementace tým odhalil mezery v existujících doprovodných materiálech MLOps. Tyto mezery je potřeba vyplnit, aby mlOps bylo lépe pochopitelné a použité ve velkém měřítku.
Pochopení postupů MLOps pomáhá organizacím zajistit, aby modely strojového učení, které systém vytváří, byly modely kvality produkce, které zlepšují obchodní výkon. Při implementaci MLOps už organizace nemusí trávit tolik času na podrobnostech nízké úrovně týkajících se infrastruktury a technické práce, která je nutná k vývoji a spouštění modelů strojového učení pro provoz na úrovni produkce. Implementace MLOps také pomáhá komunitám datových věd a softwarových inženýrů naučit se spolupracovat na poskytování systému připraveného pro produkční prostředí.
Tým CSE tento projekt použil k řešení potřeb komunity strojového učení tím, že vyřešil problémy, jako je vývoj modelu vyspělosti MLOps. Cílem tohoto úsilí bylo zlepšit přijetí MLOps pochopením typických výzev klíčových hráčů v procesu MLOps.
Zapojení a technické scénáře
Scénář zapojení popisuje reálné výzvy, které tým CSE musel vyřešit. Technický scénář definuje požadavky na vytvoření životního cyklu MLOps, který je stejně spolehlivý jako zavedený životní cyklus DevOps.
Scénář zapojení
Klient dodává produkty přímo do maloobchodních prodejen podle pravidelného plánu. Každá maloobchodní prodejna se liší ve vzorech využití produktů, takže se inventář produktů musí v jednotlivých týdenních dodávkách lišit. Maximalizace prodeje a minimalizace návratnosti produktů a ztracených prodejních příležitostí jsou cíle metodologií prognózování poptávky, které klient používá. Tento projekt se zaměřil na použití strojového učení ke zlepšení prognóz.
Tým CSE rozdělil projekt do dvou fází. Fáze 1 se zaměřuje na vývoj modelů strojového učení pro podporu pilotní studie založené na terénu na efektivitě prognózování strojového učení pro vybranou prodejní oblast. Úspěch fáze 1 vedl k fázi 2, ve které tým škáloval počáteční pilotní studii z minimální skupiny modelů, které podporovaly jednu geografickou oblast, na sadu udržitelných modelů na úrovni produkce pro všechny prodejní oblasti klienta. Primárním aspektem vertikálního navýšení kapacity řešení byla potřeba přizpůsobit velký počet geografických oblastí a jejich místních maloobchodních prodejen. Tým věnoval modely strojového učení pro velké i malé maloobchodní prodejny v každé oblasti.
Pilotní studie fáze 1 zjistila, že model vyhrazený pro maloobchodní prodejny v jedné oblasti může používat místní historii prodeje, místní demografické údaje, počasí a zvláštní události k optimalizaci prognózy poptávky pro prodejny v dané oblasti. Čtyři modely prognózování strojového učení ve skupině obsluhují trhy v jedné oblasti. Modely zpracovávaly data v týdenních dávkách. Tým také vyvinul dva základní modely s využitím historických dat pro porovnání.
Pro první verzi vertikálně navýšit kapacitu řešení fáze 2 tým CSE vybral 14 geografických oblastí, které se mají zúčastnit, včetně malých a velkých prodejen na trhu. Použili více než 50 modelů prognózování strojového učení. Tým očekával další růst systému a pokračoval v vylepšování modelů strojového učení. Rychle se ukázalo, že toto širší řešení strojového učení je udržitelné pouze v případě, že je založeno na principech osvědčených postupů DevOps pro prostředí strojového učení.
| Prostředí | Market Region | Formát | Modely | Dílčí dělení modelu | Popis modelu |
|---|---|---|---|---|---|
| Vývojové prostředí | Každý geografický trh/oblast (například Severní Texas) | Velké formáty obchodů (supermarkety, velké box obchody atd.) | Dva souborové modely | Pomalé přesouvání produktů | Pomalé i rychlé mají soubor nejméně absolutního zmenšovací a výběrového operátoru (LASSO) lineární regresní model a neurální síť s kategorickými vkládáními. |
| Rychlé přesouvání produktů | Pomalé i rychlé mají soubor modelu lineární regrese LASSO a neurální sítě s kategorickými vkládáními. | ||||
| Jeden souborový model | – | Historický průměr | |||
| Obchody s malými formáty (lékárny, obchody pro pohodlí atd.) | Dva souborové modely | Pomalé přesouvání produktů | Pomalé i rychlé mají soubor modelu lineární regrese LASSO a neurální sítě s kategorickými vkládáními. | ||
| Rychlé přesouvání produktů | Pomalé a oba mají soubor modelu lineární regrese LAS a neurální sítě s kategorickými vkládáními | ||||
| Jeden souborový model | – | Historický průměr | |||
| Stejné jako u dalších 13 geografických oblastí | |||||
| Stejné jako výše pro prod prostředí |
Proces MLOps poskytuje architekturu pro škálovaný systém, který řeší celý životní cyklus modelů strojového učení. Tato architektura zahrnuje vývoj, testování, nasazení, provoz a monitorování. Splňuje potřeby klasického procesu CI/CD. Vzhledem k jeho relativní neměnnosti v porovnání s DevOps se však ukázalo, že stávající pokyny MLOps měly mezery. Projektový tým pracoval na vyplnění některých z těchto mezer. Chtěli poskytnout model funkčního procesu, který zajišťuje životaschopnost škálovaného řešení strojového učení.
Proces MLOps, který byl vyvinut z tohoto projektu, učinil významný skutečný krok k přesunu MLOps na vyšší úroveň vyspělosti a životaschopnosti. Nový proces se přímo vztahuje na jiné projekty strojového učení. Tým CSE použil to, co se naučil, k vytvoření konceptu modelu vyspělosti MLOps, který může kdokoli použít na jiné projekty strojového učení.
Technický scénář
MLOps, označovaný také jako DevOps pro strojové učení, je zastřešující termín, který zahrnuje filozofie, postupy a technologie, které souvisejí s implementací životního cyklu strojového učení v produkčním prostředí. Stále je to relativně nový koncept. Existuje mnoho pokusů o definování toho, co mlOps je, a mnoho lidí se ptali, jestli MLOps může podsout vše od toho, jak datoví vědci připraví data, aby nakonec doručovali, monitorovali a vyhodnocovali výsledky strojového učení. I když DevOps měl roky na vývoj sady základních postupů, MLOps je stále brzy ve svém vývoji. S tím, jak se vyvíjí, zjišťujeme výzvy spojené se dvěma disciplínami, které často pracují s různými sadami dovedností a prioritami: softwarovou/provozní technikou a datovými vědami.
Implementace MLOps v produkčních prostředích v reálném světě má jedinečné výzvy, které je potřeba překonat. Týmy můžou používat Azure k podpoře vzorů MLOps. Azure také může klientům poskytnout služby správy a orchestrace prostředků, které efektivně spravují životní cyklus strojového učení. Služby Azure jsou základem řešení MLOps, které popisujeme v tomto článku.
Požadavky na model strojového učení
Většina práce během pilotní studie fáze 1 vytvářela modely strojového učení, které tým CSE použil na velké a malé maloobchodní prodejny v jedné oblasti. Velmi vhodné požadavky na modely, které jsou součástí:
Použití služby Azure Machine Učení
Počáteční experimentální modely vyvinuté v poznámkových blocích Jupyter a implementované v Pythonu
Poznámka:
Týmy používaly stejný přístup strojového učení pro velké a malé obchody, ale trénovací a bodovací data závisela na velikosti obchodu.
Data, která vyžadují přípravu na spotřebu modelu.
Data, která se zpracovávají dávkově, a ne v reálném čase.
Model se přetrénuje vždy, když se kód nebo data změní, nebo model přestane fungovat.
Zobrazení výkonu modelu na řídicích panelech Power BI
Výkon modelu při vyhodnocování, který je považován za významný, když MAPE <= 45 % ve srovnání s historickým průměrným základním modelem.
Požadavky MLOps
Tým musel splnit několik klíčových požadavků na vertikální navýšení kapacity řešení z pilotní studie fáze 1, ve které bylo vyvinuto pouze několik modelů pro jednu prodejní oblast. Fáze 2 implementovala vlastní modely strojového učení pro více oblastí. Implementace zahrnovala:
Týdenní dávkové zpracování velkých a malých úložišť v každé oblasti za účelem opětovného natrénování modelů s novými datovými sadami.
Průběžné vylepšování modelů strojového učení
Integrace procesu vývoje,testování/balíčku/testu/nasazení, který je společný pro CI/CD, v prostředí pro zpracování podobné DevOps pro MLOps.
Poznámka:
To představuje posun v tom, jak datoví vědci a datoví inženýři běžně pracovali v minulosti.
Jedinečný model, který představoval každou oblast pro velké a malé obchody na základě historie obchodů, demografických údajů a dalších klíčových proměnných. Model musel zpracovat celou datovou sadu, aby minimalizoval riziko chyby zpracování.
Možnost počátečního vertikálního navýšení kapacity na podporu 14 prodejních oblastí s plány dalšího vertikálního navýšení kapacity.
Plány dalších modelů pro dlouhodobější prognózování oblastí a dalších clusterů úložiště
Řešení modelu strojového učení
Životní cyklus strojového učení, označovaný také jako životní cyklus datových věd, odpovídá zhruba následujícímu toku procesu vysoké úrovně:
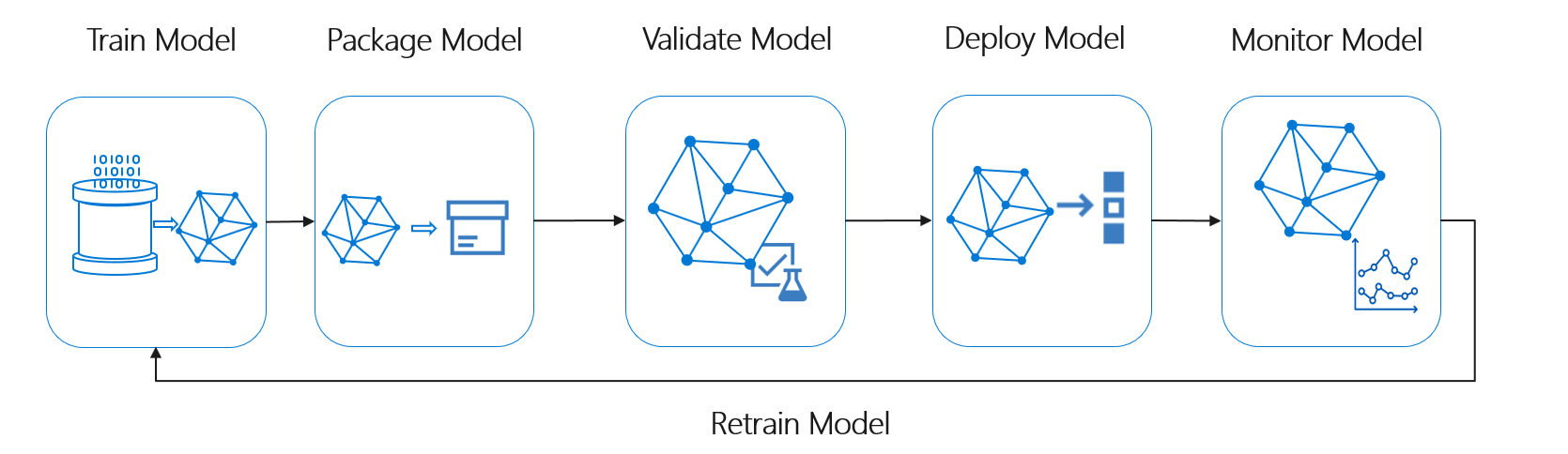
Nasadit model zde může představovat jakékoli provozní použití ověřeného modelu strojového učení. V porovnání s DevOps představuje MLOps další výzvu k integraci životního cyklu strojového učení do typického procesu CI/CD.
Životní cyklus datových věd neodpovídá typickému životnímu cyklu vývoje softwaru. Zahrnuje použití služby Azure Machine Učení k trénování a hodnocení modelů, takže tyto kroky musely být zahrnuty do automatizace CI/CD.
Dávkové zpracování dat je základem architektury. Dva kanály azure machine Učení jsou pro proces centrální, jeden pro trénování a druhý pro bodování. Tento diagram znázorňuje metodologii datových věd, která byla použita pro počáteční fázi projektu klienta:
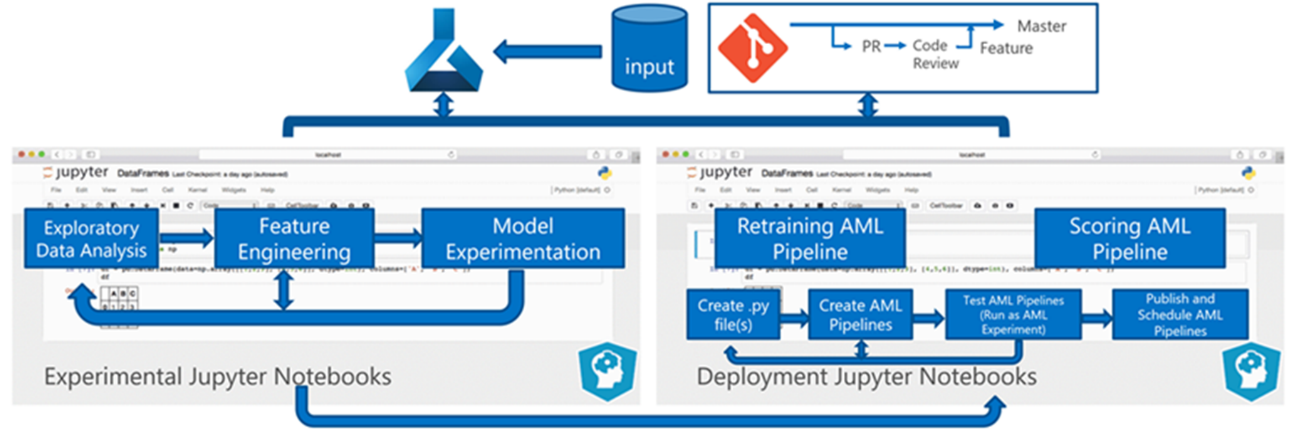
Tým testoval několik algoritmů. Nakonec zvolili souborový návrh modelu lineární regrese LASSO a neurální sítě s kategorickými vkládáními. Tým použil stejný model definovaný úrovní produktu, kterou klient může uložit na webu pro velké i malé obchody. Tým model dále rozdělil na produkty s rychlým a pomalým pohybem.
Datoví vědci vytrénuje modely strojového učení, když tým uvolní nový kód a kdy jsou k dispozici nová data. Trénování se obvykle stává každý týden. V důsledku toho každé spuštění zpracování zahrnuje velké množství dat. Vzhledem k tomu, že tým shromažďuje data z mnoha zdrojů v různých formátech, vyžaduje, aby data byla uložena do spotřebního formátu, aby je mohli datoví vědci zpracovat. Klimatizace dat vyžaduje značné ruční úsilí a tým CSE ho identifikoval jako primární kandidát na automatizaci.
Jak už bylo zmíněno, datoví vědci vyvinuli a použili experimentální modely Azure Machine Učení do jedné prodejní oblasti v pilotní studii fáze 1, aby mohli vyhodnotit užitečnost tohoto přístupu prognózy. Tým CSE posoudil, že prodejní výtah pro obchody v pilotní studii byl významný. Tento úspěch odůvodnil uplatnění řešení na úplné úrovně výroby ve fázi 2, počínaje 14 geografickými oblastmi a tisíci obchodů. Tým pak může použít stejný vzor pro přidání dalších oblastí.
Pilotní model sloužil jako základ pro vertikálně navýšené řešení, ale tým CSE věděl, že model potřeboval další upřesnění na základě dalšího zlepšení výkonu.
Řešení MLOps
Jak koncepty MLOps zraly, týmy často objevují výzvy při propojení datových věd a disciplín DevOps. Důvodem je, že hlavní hráči v disciplínách, softwarových inženýrech a datových vědcích pracují s různými sadami dovedností a prioritami.
Existují ale podobnosti, na kterých je potřeba stavět. MLOps, jako je DevOps, je vývojový proces implementovaný sadou nástrojů. Sada nástrojů MLOps zahrnuje například:
- Správa verzí
- Analýza kódu
- Automatizace sestavení
- Průběžná integrace
- Testování architektur a automatizace
- Zásady dodržování předpisů integrované do kanálů CI/CD
- Automatizace nasazení
- Sledování
- Zotavení po havárii a vysoká dostupnost
- Správa balíčků a kontejnerů
Jak je uvedeno výše, řešení využívá stávající pokyny DevOps, ale rozšiřuje se o vytvoření vyspělejší implementace MLOps, která splňuje potřeby klienta a komunity datových věd. MLOps vychází z pokynů k DevOps s těmito dalšími požadavky:
- Správa verzí dat a modelů není stejná jako správa verzí kódu: Při změně schématu a dat původu musí existovat správa verzí datových sad.
- Požadavky na digitální záznam auditu: Sledujte všechny změny při práci s kódem a klientskými daty.
- Generalizace: Modely se liší od kódu pro opakované použití, protože datoví vědci musí ladit modely na základě vstupních dat a scénáře. Pokud chcete model znovu použít pro nový scénář, možná ho budete muset vyladit, převést nebo naučit. Potřebujete trénovací kanál.
- Zastaralé modely: Modely mají tendenci se v průběhu času rozpadat a potřebujete možnost je znovu vytrénovat na vyžádání, aby se zajistilo, že zůstanou relevantní v produkčním prostředí.
Problémy MLOps
Nezralý standard MLOps
Standardní model MLOps se stále vyvíjí. Řešení je obvykle vytvořeno od začátku a je vytvořeno tak, aby vyhovovalo potřebám konkrétního klienta nebo uživatele. Tým CSE tuto mezeru rozpoznal a snažil se v tomto projektu používat osvědčené postupy DevOps. Rozšířili proces DevOps tak, aby vyhovoval dalším požadavkům MLOps. Proces, který tým vyvinul, je realizovatelným příkladem toho, jak by měl vypadat standardní vzor MLOps.
Rozdíly v sadách dovedností
Softwaroví inženýři a datoví vědci přinášejí týmu jedinečné sady dovedností. Tyto různé sady dovedností můžou ztěžovat nalezení řešení, které bude vyhovovat potřebám všech. Vytvoření dobře pochopitelného pracovního postupu pro doručování modelů z experimentování do produkčního prostředí je důležité. Členové týmu musí sdílet znalosti o tom, jak můžou integrovat změny do systému, aniž by porušili proces MLOps.
Správa více modelů
Často je potřeba, aby několik modelů vyřešilo obtížné scénáře strojového učení. Jednou z výzev MLOps je správa těchto modelů, mezi které patří:
- Máme koherentní schéma správy verzí.
- Průběžně vyhodnocovat a monitorovat všechny modely.
K diagnostice problémů s modelem a vytváření reprodukovatelných modelů je potřeba také trasovatelná rodokmen kódu i dat. Vlastní řídicí panely můžou dávat smysl pro to, jak nasazené modely fungují, a indikují, kdy má dojít k zásahu. Tým pro tento projekt vytvořil tyto řídicí panely.
Potřeba pro klimatizaci dat
Data používaná s těmito modely pocházejí z mnoha soukromých a veřejných zdrojů. Vzhledem k tomu, že původní data jsou neuspořádaná, není možné, aby ho model strojového učení spotřeboval v nezpracovaném stavu. Datoví vědci musí data podmínět do standardního formátu pro spotřebu modelu strojového učení.
Velká část pilotního testu v terénu se zaměřila na přípravu nezpracovaných dat, aby ho model strojového učení mohl zpracovat. V systému MLOps by tým měl tento proces automatizovat a sledovat výstupy.
Model vyspělosti MLOps
Účelem modelu vyspělosti MLOps je objasnit principy a postupy a identifikovat mezery v implementaci MLOps. Je to také způsob, jak ukázat klientovi, jak přírůstkově zvětšit svou schopnost MLOps místo toho, abyste se to snažili provést všechny najednou. Klient by ho měl používat jako vodítko pro:
- Odhad rozsahu práce pro projekt
- Nastavte kritéria úspěchu.
- Identifikujte dodávky.
Model vyspělosti MLOps definuje pět úrovní technické schopnosti:
| Level | Popis |
|---|---|
| 0 | Žádné operace |
| 0 | DevOps, ale žádné MLOps |
| 2 | Automatizované trénování |
| 3 | Automatizované nasazení modelu |
| 4 | Automatizované operace (úplné MLOps) |
Aktuální verzi modelu vyspělosti MLOps najdete v článku o modelu vyspělosti MLOps.
Definice procesu MLOps
MLOps zahrnuje všechny aktivity od získání nezpracovaných dat až po doručení výstupu modelu, označovaného také jako bodování:
- Klimatizace dat
- Trénování modelu
- Testování a vyhodnocení modelů
- Definice sestavení a kanál
- Kanál verze
- Nasazení
- Vyhodnocování
Základní proces strojového učení
Základní proces strojového učení se podobá tradičnímu vývoji softwaru, ale existují významné rozdíly. Tento diagram znázorňuje hlavní kroky v procesu strojového učení:
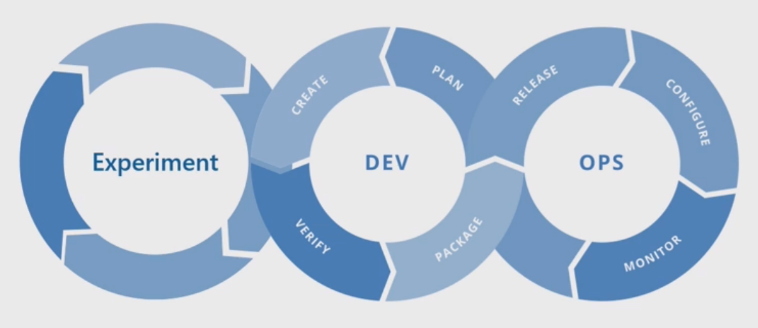
Fáze experimentu je jedinečná pro životní cyklus datových věd, který odráží, jak datoví vědci tradičně dělají svou práci. Liší se od toho, jak vývojáři kódu pracují. Následující diagram znázorňuje tento životní cyklus podrobněji.
Integrace tohoto procesu vývoje dat do MLOps představuje výzvu. Tady vidíte vzor, který tým použil k integraci procesu do formuláře, který MŮŽE MLOps podporovat:
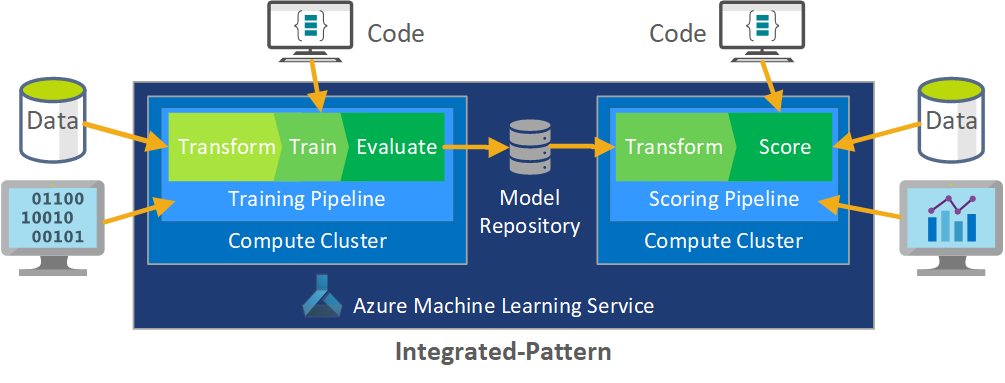
Rolí MLOps je vytvořit koordinovaný proces, který může efektivně podporovat rozsáhlá prostředí CI/CD, která jsou společná v systémech produkční úrovně. Model MLOps musí obsahovat koncepčně všechny požadavky na procesy od experimentování až po bodování.
Tým CSE upřesňuje proces MLOps tak, aby vyhovoval konkrétním potřebám klienta. Nejdůležitější potřebou bylo dávkové zpracování místo zpracování v reálném čase. Když tým vyvinul vertikálně navýšit kapacitu systému, identifikoval a vyřešil některé nedostatky. Nejvýznamnější z těchto nedostatků vedlo k vývoji mostu mezi Azure Data Factory a Učení Azure Machine, který tým implementoval pomocí integrovaného konektoru ve službě Azure Data Factory. Vytvořili tuto sadu komponent, která usnadňuje spouštění a monitorování stavu nezbytné k tomu, aby automatizace procesů fungovala.
Další zásadní změnou bylo, že datoví vědci potřebovali možnost exportovat experimentální kód z poznámkových bloků Jupyter do procesu nasazení MLOps, a ne aktivovat trénování a bodování přímo.
Tady je konečný koncept modelu procesu MLOps:
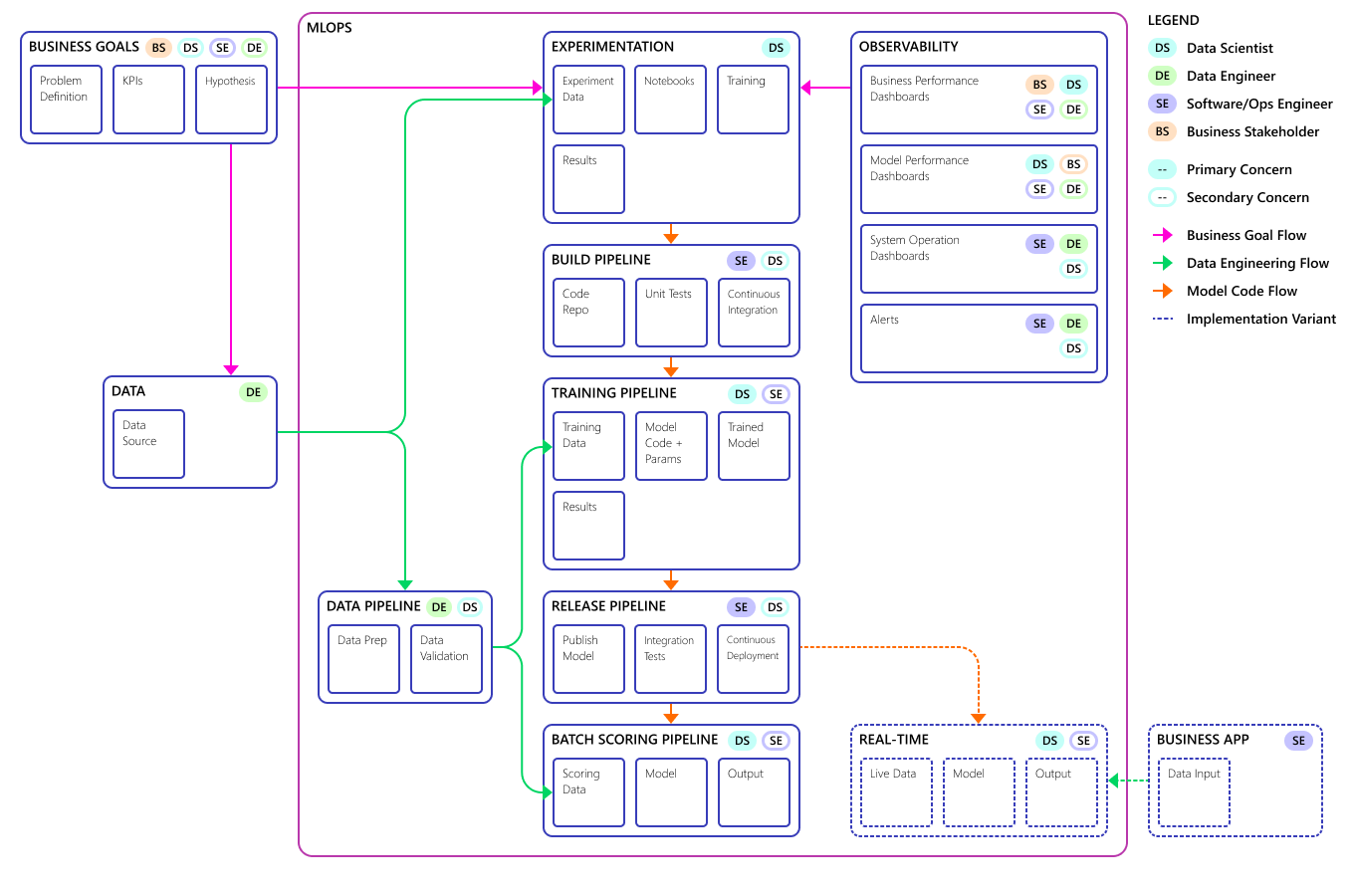
Důležité
Bodování je posledním krokem. Proces spustí model strojového učení, který vytvoří předpovědi. Řeší se tím požadavek základního případu obchodního použití pro prognózování poptávky. Tým hodnotí kvalitu předpovědí pomocí MAPE, což je míra přesnosti předpovědi statistických metod prognózy a funkce ztráty pro regresní problémy ve strojovém učení. V tomto projektu se tým považoval za MAPE <= 45 % významné.
Tok procesu MLOps
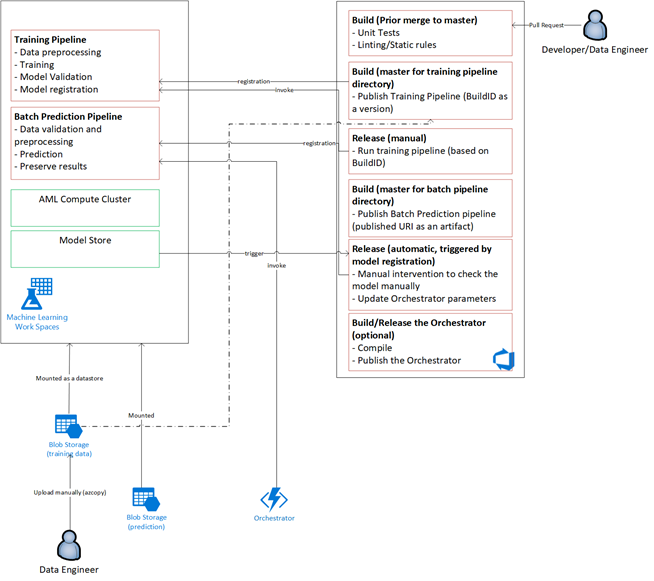
Následující diagram popisuje, jak použít pracovní postupy vývoje a vydávání CI/CD na životní cyklus strojového učení:
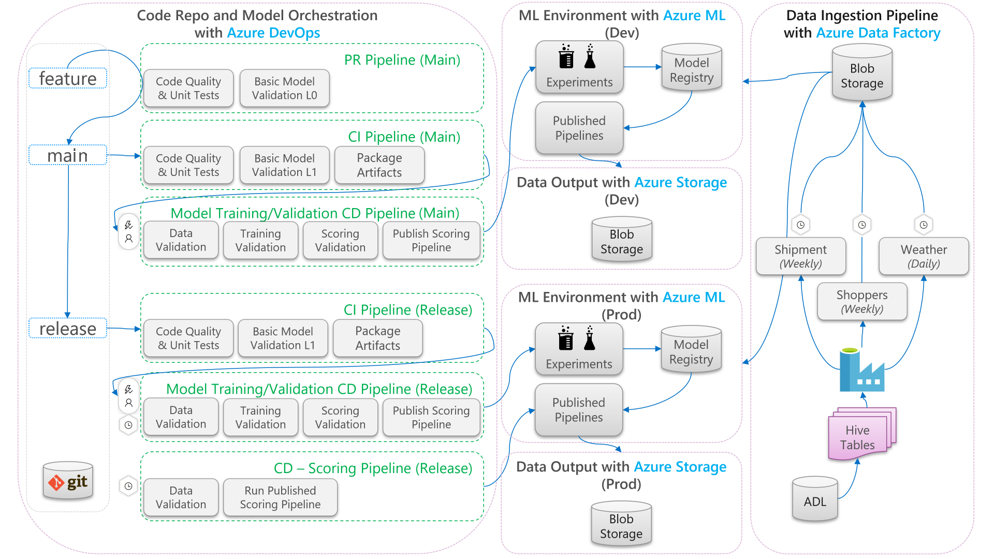
- Když se vytvoří žádost o přijetí změn (PR) z větve funkce, kanál spustí ověřovací testy kódu, aby ověřil kvalitu kódu prostřednictvím testů jednotek a testů kvality kódu. Pro ověření kvality upstreamu kanál také spouští základní ověřovací testy modelu, které ověří kompletní trénování a bodovací kroky s ukázkovou sadou napodobených dat.
- Když se žádost o přijetí změn sloučí do hlavní větve, kanál CI spustí stejné ověřovací testy kódu a základní ověřovací testy modelu se zvýšenou epochou. Kanál pak zabalí artefakty, které zahrnují kód a binární soubory, aby se spustily v prostředí strojového učení.
- Jakmile jsou artefakty k dispozici, aktivuje se kanál CD pro ověření modelu. Spouští kompletní ověřování v vývojovém prostředí strojového učení. Publikuje se bodovací mechanismus. V případě scénáře dávkového bodování se kanál bodování publikuje do prostředí strojového učení a aktivuje se za účelem vytvoření výsledků. Pokud chcete použít scénář bodování v reálném čase, můžete publikovat webovou aplikaci nebo nasadit kontejner.
- Po vytvoření a sloučení milníku do větve verze se aktivuje stejný kanál CI a kanál CD ověření modelu. Tentokrát se spustí proti kódu z větve vydané verze.
Tok dat procesu MLOps uvedený výše můžete považovat za architekturu archetypu pro projekty, které dělají podobné volby architektury.
Ověřovací testy kódu
Ověřovací testy kódu pro strojové učení se zaměřují na ověřování kvality základu kódu. Je to stejný koncept jako jakýkoli technický projekt, který má testy kvality kódu (linting), testy jednotek a měření pokrytí kódu.
Základní ověřovací testy modelu
Ověření modelu obvykle odkazuje na ověření úplných kompletních kroků procesu potřebných k vytvoření platného modelu strojového učení. Zahrnuje následující kroky:
- Ověření dat: Zajišťuje platnost vstupních dat.
- Ověření trénování: Zajišťuje úspěšné trénování modelu.
- Ověření skóre: Zajišťuje, aby tým mohl úspěšně použít natrénovaný model pro bodování se vstupními daty.
Spuštění této úplné sady kroků v prostředí strojového učení je nákladné a časově náročné. V důsledku toho tým provedl základní ověřovací testy modelu místně na vývojovém počítači. Spustil výše uvedené kroky a použil následující:
- Místní testovací datová sada: Malá datová sada, která je často obfuskovaná, která je vrácená se změnami do úložiště a spotřebovaná jako vstupní zdroj dat.
- Místní příznak: Příznak nebo argument v kódu modelu, který indikuje, že kód hodlá datovou sadu spustit místně. Příznak říká kódu, aby obešel jakékoli volání prostředí strojového učení.
Cílem těchto ověřovacích testů není vyhodnotit výkon natrénovaného modelu. Místo toho je potřeba ověřit, že kód pro kompletní proces má dobrou kvalitu. Zajišťuje kvalitu kódu, který je vložený do upstreamu, jako je začlenění testů ověření modelu do sestavení PR a CI. Umožňuje také technikům a datovým vědcům umístit zarážky do kódu pro účely ladění.
Kanál CD pro ověření modelu
Cílem kanálu ověření modelu je ověření kompletního trénování a vyhodnocování kroků v prostředí strojového učení se skutečnými daty. Každý vytrénovaný model, který se vytvoří, se přidá do registru modelu a označí se, aby po dokončení ověření čekal na povýšení. U dávkové předpovědi může být povýšení publikování kanálu bodování, který používá tuto verzi modelu. Pro bodování v reálném čase může být model označen tak, aby označoval, že byl povýšen.
Bodování kanálu CD
Kanál bodování CD je použitelný pro scénář odvozování dávky, kde stejný orchestrátor modelu, který se používá k ověření modelu, aktivuje publikovaný kanál bodování.
Vývoj vs. produkční prostředí
Je vhodné oddělit vývojové prostředí od produkčního (prod) prostředí. Oddělení umožňuje systému aktivovat kanál CD pro ověření modelu a bodování kanálu CD podle různých plánů. V případě popsaného toku MLOps kanály, které cílí na hlavní větev, běží ve vývojovém prostředí a kanál, který cílí na větev verze, běží v prod prostředí.
Změny kódu vs. změny dat
Předchozí části se zabývají většinou tím, jak zpracovávat změny kódu z vývoje na vydání. Změny dat by ale měly dodržovat stejnou úroveň jako změny kódu, aby poskytovaly stejnou kvalitu ověřování a konzistenci v produkčním prostředí. S triggerem změny dat nebo triggerem časovače může systém aktivovat kanál CD pro ověření modelu a kanál CD bodování z orchestrátoru modelů, aby spustil stejný proces, který se spouští pro změny kódu v prod prostředí větve vydané verze.
Osoby a role MLOps
Klíčovým požadavkem pro každý proces MLOps je to, že splňuje potřeby mnoha uživatelů procesu. Pro účely návrhu zvažte tyto uživatele jako jednotlivé osoby. V tomto projektu tým identifikoval tyto osoby:
- Datový vědec: Vytvoří model strojového učení a jeho algoritmy.
- Inženýr
- Datový inženýr: Zpracovává klimatizaci dat.
- Softwarový inženýr: Zpracovává integraci modelu do balíčku prostředků a pracovního postupu CI/CD.
- Provoz nebo IT: Dohlíží na systémové operace.
- Obchodní účastník: Zabývá se predikcemi vytvořenými modelem strojového učení a tím, jak pomáhají firmě.
- Koncový uživatel dat: Využívá výstup modelu nějakým způsobem, který pomáhá při obchodních rozhodnutích.
Tým se musel zabývat třemi klíčovými zjištěními ze studií osob a rolí:
- Datoví vědci a technici mají neshodu přístupu a dovedností v jejich práci. Usnadnění spolupráce datového vědce a inženýra je důležitým aspektem návrhu toku procesu MLOps. Vyžaduje získání nových dovedností všemi členy týmu.
- Je potřeba sjednotit všechny hlavní osoby, aniž by někdo zcizil. Způsob, jak to udělat, je:
- Ujistěte se, že rozumí konceptuálnímu modelu MLOps.
- Spojte se s členy týmu, kteří budou spolupracovat.
- Stanovit pracovní pokyny pro dosažení společných cílů.
- Pokud obchodní účastník a koncový uživatel dat potřebují způsob, jak pracovat s výstupem dat z modelů, je standardním řešením uživatelsky přívětivé uživatelské rozhraní.
Ostatní týmy jistě narazí na podobné problémy v jiných projektech strojového učení, protože vertikálně navyšují kapacitu pro produkční použití.
Architektura řešení MLOps
Logická architektura
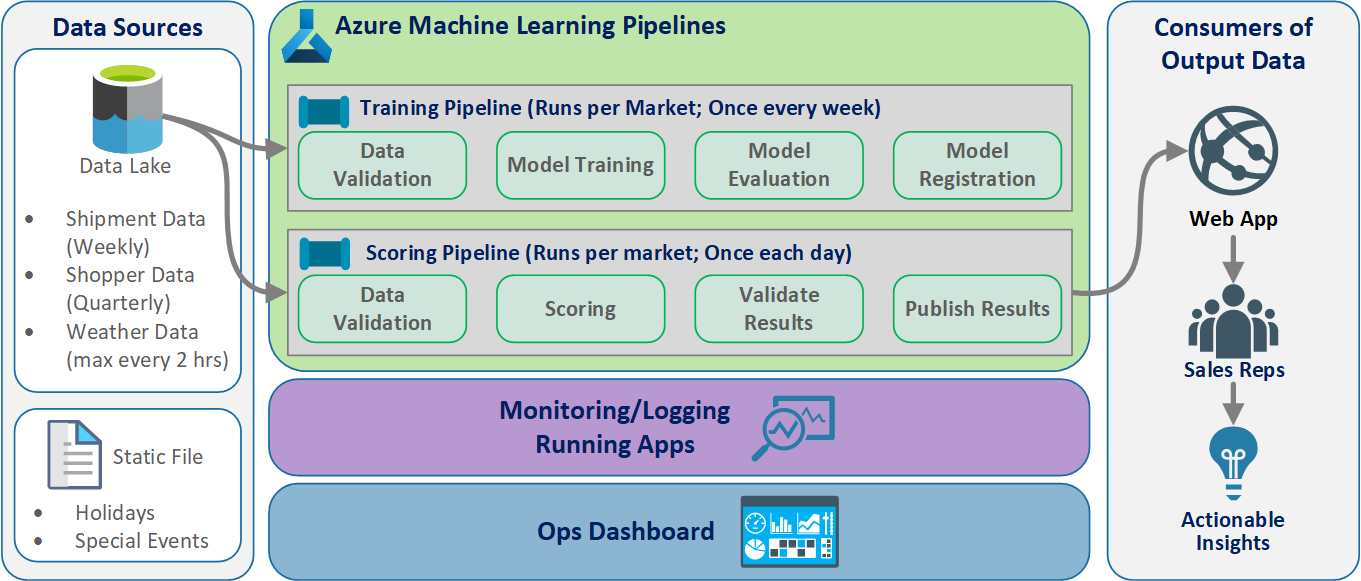
Data pocházejí z mnoha zdrojů v mnoha různých formátech, takže jsou podmíněná před vložením do datového jezera. Klimatizace se provádí pomocí mikroslužeb, které fungují jako Azure Functions. Klienti přizpůsobí mikroslužby tak, aby odpovídaly zdrojům dat, a transformují je do standardizovaného formátu CSV, který kanály trénování a bodování spotřebovávají.
Systémová architektura
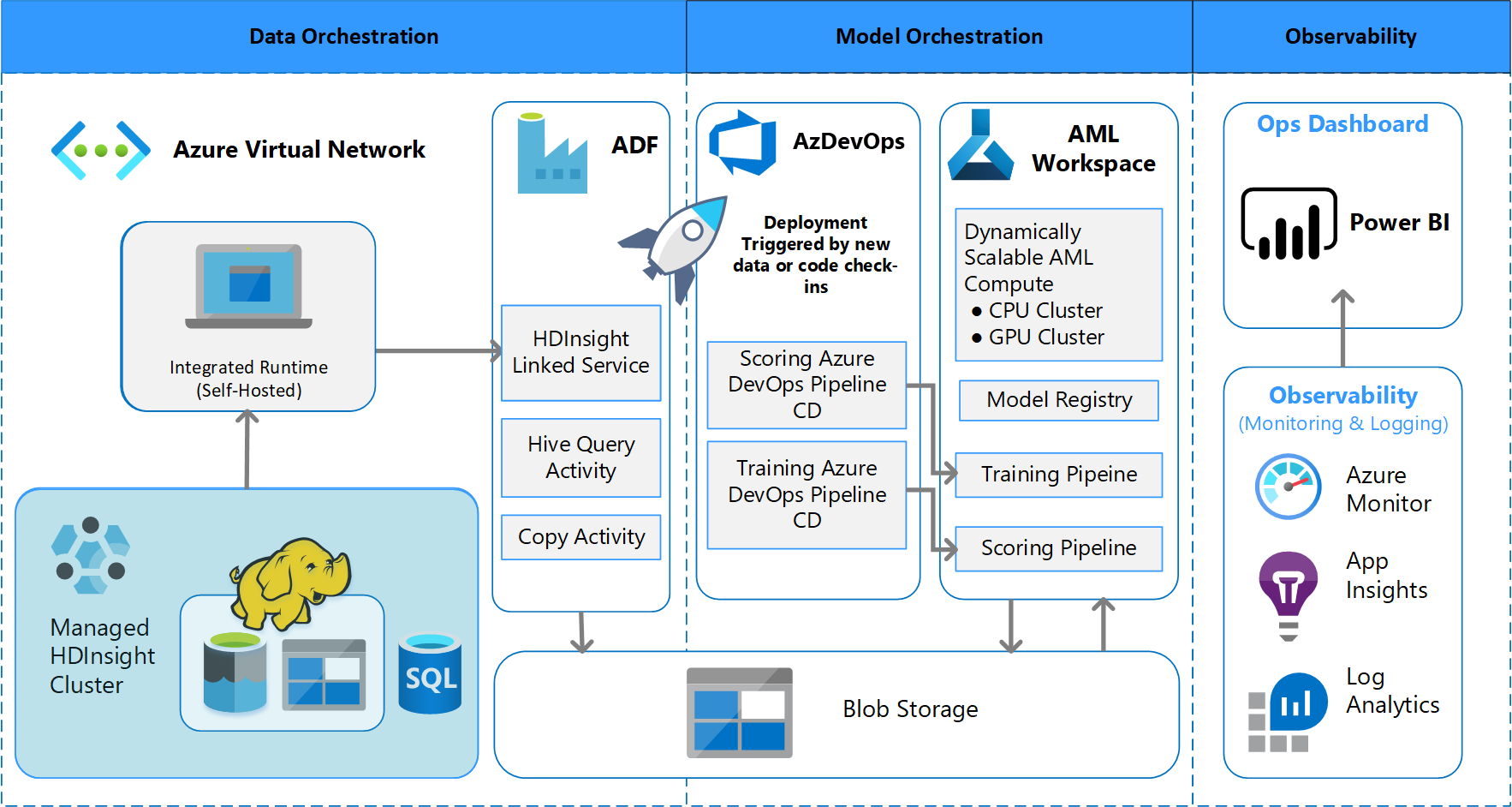
Architektura dávkového zpracování
Tým navrhl návrh architektury, který podporuje schéma dávkového zpracování dat. Existují alternativy, ale to, co se používá, musí podporovat procesy MLOps. Úplné použití dostupných služeb Azure bylo požadavek na návrh. Následující diagram znázorňuje architekturu:
Přehled řešení
Azure Data Factory dělá toto:
- Aktivuje funkci Azure pro spuštění příjmu dat a spuštění kanálu azure machine Učení.
- Spustí odolnou funkci pro dotazování kanálu azure machine Učení na dokončení.
Vlastní řídicí panely v Power BI zobrazují výsledky. Další řídicí panely Azure, které jsou připojené k Azure SQL, Azure Monitoru a Přehledy aplikací prostřednictvím sady OpenCensus Python SDK, sledují prostředky Azure. Tyto řídicí panely poskytují informace o stavu systému strojového učení. Poskytují také data, která klient používá pro prognózování objednávek produktů.
Orchestrace modelů
Orchestrace modelů se řídí těmito kroky:
- Když se odešle žádost o přijetí změn, DevOps aktivuje kanál ověření kódu.
- Kanál spouští testy jednotek, testy kvality kódu a ověřovací testy modelu.
- Při sloučení do hlavní větve se spustí stejné ověřovací testy kódu a DevOps zabalí artefakty.
- Shromažďování artefaktů v DevOps aktivuje azure machine Učení k tomu:
- Ověřování dat.
- Ověření trénování
- Ověření vyhodnocování.
- Po dokončení ověření se spustí konečný kanál bodování.
- Změna dat a odeslání nové žádosti o přijetí změn znovu aktivuje ověřovací kanál následovaný posledním bodovacím kanálem.
Povolení experimentování
Jak už bylo zmíněno, tradiční životní cyklus strojového učení datových věd nepodporuje proces MLOps bez úprav. Používá různé druhy ručních nástrojů a experimentování, ověřování, balení a předání modelu, které nelze snadno škálovat pro efektivní proces CI/CD. MLOps vyžaduje vysokou úroveň automatizace procesů. Bez ohledu na to, jestli se vyvíjí nový model strojového učení, nebo se mění starý model, je nutné automatizovat životní cyklus modelu strojového učení. V projektu Fáze 2 tým použil Azure DevOps k orchestraci a opětovnému publikování kanálů azure Machine Učení pro trénovací úkoly. Dlouhotrvající hlavní větev provádí základní testování modelů a odesílá stabilní verze prostřednictvím dlouhotrvající větve vydané verze.
Správa zdrojového kódu je důležitou součástí tohoto procesu. Git je systém správy verzí, který se používá ke sledování kódu poznámkového bloku a modelu. Podporuje také automatizaci procesů. Základní pracovní postup implementovaný pro správu zdrojového kódu používá následující principy:
- Používejte formální správu verzí pro kód a datové sady.
- K vývoji nového kódu použijte větev, dokud se kód plně nevytvoří a neověří.
- Po ověření nového kódu je možné ho sloučit do hlavní větve.
- Pro vydání se vytvoří trvalá větev se stejnou verzí, která je oddělená od hlavní větve.
- Používejte verze a správu zdrojového kódu pro datové sady, které byly podmíněny pro trénování nebo spotřebu, abyste mohli zachovat integritu každé datové sady.
- Ke sledování experimentů Jupyter Notebook použijte správu zdrojového kódu.
Integrace se zdroji dat
Datoví vědci používají mnoho nezpracovaných zdrojů dat a zpracovávaných datových sad k experimentování s různými modely strojového učení. Objem dat v produkčním prostředí může být ohromující. Aby datoví vědci mohli experimentovat s různými modely, musí používat nástroje pro správu, jako je Azure Data Lake. Požadavek na formální identifikaci a správu verzí se vztahuje na všechna nezpracovaná data, připravené datové sady a modely strojového učení.
V projektu podmínili datoví vědci následující data pro vstup do modelu:
- Historická týdenní data o zásilce od ledna 2017
- Historická a předpovídovaná denní data o počasí pro každý PSČ
- Údaje o nakupujících pro každé ID obchodu
Integrace se správou zdrojového kódu
Pokud chcete datovým vědcům získat osvědčené postupy přípravy, je potřeba pohodlně integrovat nástroje, které používají, se systémy správy zdrojového kódu, jako je GitHub. Tento postup umožňuje správu verzí modelů strojového učení, spolupráci mezi členy týmu a zotavení po havárii, pokud týmy dojde ke ztrátě dat nebo výpadku systému.
Podpora modelových souborů
Návrh modelu v tomto projektu byl souborový model. To znamená, že datoví vědci použili v konečném návrhu modelu mnoho algoritmů. V tomto případě modely používaly stejný základní návrh algoritmu. Jediným rozdílem bylo, že používali různá trénovací data a bodovací data. Modely používaly kombinaci algoritmu lineární regrese LAS a neurální sítě.
Tým prozkoumal, ale neimplementoval, možnost přenést proces do bodu, kde by podporoval mnoho modelů běžících v reálném čase v produkčním prostředí, aby mohl danou žádost obsluhovat. Tato možnost může pojmout použití souborových modelů při testování A/B a prokládání experimentů.
Koncová uživatelská rozhraní
Tým vyvinul uživatelské rozhraní koncového uživatele pro pozorovatelnost, monitorování a instrumentaci. Jak už bylo zmíněno, řídicí panely vizuálně zobrazují data modelu strojového učení. Tyto řídicí panely zobrazují následující data v uživatelsky přívětivé podobě:
- Kroky kanálu, včetně předběžného zpracování vstupních dat
- Monitorování stavu zpracování modelu strojového učení:
- Jaké metriky shromažďujete z nasazeného modelu?
- MAPE: Střední absolutní procentuální chyba, klíčovou metrikou ke sledování celkového výkonu. (Cílí na hodnotu <MAPE = 0,45 pro každý model.)
- RMSE 0: Chyba kořenového středního čtverce (RMSE), pokud skutečná cílová hodnota = 0.
- RMSE All: RMSE na celé datové sadě.
- Jak vyhodnotíte, jestli model funguje podle očekávání v produkčním prostředí?
- Existuje způsob, jak zjistit, jestli se produkční data příliš liší od očekávaných hodnot?
- Funguje váš model v produkčním prostředí špatně?
- Máte stav převzetí služeb při selhání?
- Jaké metriky shromažďujete z nasazeného modelu?
- Sledujte kvalitu zpracovaných dat.
- Zobrazení hodnoticích a předpovědí vytvořených modelem strojového učení
Aplikace naplní řídicí panely podle povahy dat a způsobu, jakým zpracovává a analyzuje data. Proto musí tým navrhnout přesné rozložení řídicích panelů pro každý případ použití. Tady jsou dva ukázkové řídicí panely:


Řídicí panely byly navrženy tak, aby poskytovaly snadno použitelné informace pro spotřebu koncovým uživatelem předpovědí modelu strojového učení.
Poznámka:
Zastaralé modely jsou bodovací běhy, kde datoví vědci vytrénovali model použitý k bodování více než 60 dnů od doby, kdy proběhlo bodování. Na stránce bodování řídicího panelu monitorování ML se zobrazí tato metrika stavu.
Komponenty
- Azure Machine Learning
- Azure Blob Storage
- Azure Data Lake Storage
- Azure Pipelines
- Azure Data Factory
- Azure Functions pro Python
- Azure Monitor
- Azure SQL Database
- Řídicí panely Azure
- Power BI
Důležité informace
Tady najdete seznam aspektů, které je potřeba prozkoumat. Jsou založeny na lekcích, které se tým CSE naučil během projektu.
Aspekty prostředí
- Datoví vědci vyvíjejí většinu svých modelů strojového učení pomocí Pythonu, často začínají poznámkovými bloky Jupyter. Implementace těchto poznámkových bloků jako produkčního kódu může být náročná. Poznámkové bloky Jupyter jsou spíše experimentálním nástrojem, zatímco skripty Pythonu jsou vhodnější pro produkční prostředí. Týmy často potřebují trávit čas refaktoringem kódu pro vytváření modelu do skriptů Pythonu.
- Zajistěte, aby klienti, kteří s DevOps začíná, a strojové učení věděli, že experimentování a produkční prostředí vyžadují jinou rigorii, takže je vhodné je oddělit.
- Nástroje, jako je Azure Machine Učení Visual Designer nebo AutoML, můžou být efektivní při získávání základních modelů od země, zatímco klient se rozběhl na standardní postupy DevOps, které se použijí na zbytek řešení.
- Azure DevOps obsahuje moduly plug-in, které se dají integrovat se službou Azure Machine Učení a pomáhají aktivovat kroky kanálu. Úložiště MLOpsPython obsahuje několik příkladů takových kanálů.
- Strojové učení často vyžaduje pro trénování výkonné grafické procesorové jednotky (GPU). Pokud klient takový hardware ještě nemá, může výpočetní clustery Azure Machine Učení poskytovat efektivní cestu k rychlému zřizování nákladově efektivního výkonného hardwaru, který automaticky škáluje. Pokud má klient pokročilé potřeby zabezpečení nebo monitorování, existují další možnosti, jako jsou standardní virtuální počítače, Databricks nebo místní výpočetní prostředky.
- Aby klient mohl být úspěšný, musí mít týmy pro vytváření modelů (datoví vědci) a týmy nasazení (technici DevOps) silný komunikační kanál. Můžou toho dosáhnout díky denním schůzkám nebo formální online chatovací službě. Oba přístupy pomáhají integrovat své vývojové úsilí do architektury MLOps.
Důležité informace o přípravě dat
Nejjednodušším řešením pro použití služby Azure Machine Učení je ukládání dat do podporovaného řešení úložiště dat. Nástroje, jako je Azure Data Factory, jsou efektivní pro propojení dat do a z těchto umístění podle plánu.
Je důležité, aby klienti často zaznamenávali další přetrénování dat, aby jejich modely zůstaly aktuální. Pokud ještě nemají datový kanál, vytvoření datového kanálu bude důležitou součástí celkového řešení. Použití řešení, jako jsou datové sady ve službě Azure Machine Učení, může být užitečné pro správu verzí dat, která pomáhají sledovatelnost modelů.
Aspekty trénování a vyhodnocení modelů
Je to pro klienta, který právě začíná na cestě strojového učení, aby se pokusil implementovat úplný kanál MLOps. V případě potřeby se k němu můžou snadno připojit pomocí služby Azure Machine Učení ke sledování spuštění experimentů a pomocí služby Azure Machine Učení výpočetních prostředků jako cíle trénování. Tyto možnosti můžou vytvořit nižší bariéru vstupního řešení pro zahájení integrace služeb Azure.
Přechod z experimentu poznámkového bloku na opakovatelné skripty je hrubý přechod pro mnoho datových vědců. Čím dříve je budete moct do skriptů Pythonu napsat, tím jednodušší bude, aby mohli začít psát trénovací kód a povolit opětovné trénování.
To není jediná možná metoda. Databricks podporuje plánování poznámkových bloků jako úloh. Tento přístup je ale na základě aktuálního prostředí klienta obtížně instrumentovat s úplnými postupy DevOps z důvodu omezení testování.
Je také důležité pochopit, jaké metriky se používají k posouzení úspěšného modelu. Přesnost sama o sobě často nestačí k určení celkového výkonu jednoho modelu oproti druhému.
Důležité informace o výpočetních prostředcích
- Zákazníci by měli zvážit použití kontejnerů ke standardizaci výpočetních prostředí. Téměř všechny výpočetní Učení Azure Učení podporují podporu pomocí Dockeru. Zpracování závislostí kontejnerem může výrazně snížit tření, zejména pokud tým používá mnoho výpočetních cílů.
Aspekty poskytování modelu
- Sada Azure Machine Učení SDK poskytuje možnost nasazení přímo do služby Azure Kubernetes Service z registrovaného modelu a vytváří limity pro to, jaké jsou zavedené metriky zabezpečení nebo metriky. Můžete se pokusit najít jednodušší řešení pro klienty k otestování modelu, ale nejlepší je vyvíjet robustnější nasazení do AKS pro produkční úlohy.
Další kroky
- Další informace o MLOps
- MLOps v Azure
- Vizualizace azure Monitoru
- Životní cyklus strojového Učení
- Rozšíření azure DevOps Machine Učení
- Rozhraní CLI služby Azure Machine Learning
- Aktivace aplikací, procesů nebo pracovních postupů CI/CD na základě událostí služby Azure Machine Learning
- Nastavení trénování a nasazení modelu pomocí Azure DevOps
Související prostředky
- Model vyspělosti MLOps
- Orchestrace MLOps v Azure Databricks pomocí poznámkového bloku Databricks
- MLOps pro modely Pythonu s využitím služby Azure Machine Učení
- Datové vědy a strojové učení s využitím Azure Databricks
- Citizen AI s Power Platform
- Nasazení AI a strojového učení v místním prostředí a na hraniční zařízení