Kurz: Detekce a analýza anomálií pomocí funkcí strojového učení KQL ve službě Azure Monitor
Dotazovací jazyk Kusto (KQL) zahrnuje operátory strojového učení, funkce a moduly plug-in pro analýzu časových řad, detekci anomálií, prognózování a analýzu původních příčin. Pomocí těchto funkcí KQL můžete provádět pokročilou analýzu dat ve službě Azure Monitor bez nutnosti exportu dat do externích nástrojů pro strojové učení.
V tomto kurzu se naučíte:
- Vytvoření časové řady
- Identifikace anomálií v časové řadě
- Vylepšení výsledků úpravou nastavení detekce anomálií
- Analýza původní příčiny anomálií
Poznámka
Tento kurz obsahuje odkazy na ukázkové prostředí Log Analytics, ve kterém můžete spustit příklady dotazů KQL. Ve všech nástrojích služby Azure Monitor, které používají KQL, ale můžete implementovat stejné dotazy a objekty zabezpečení KQL.
Požadavky
- Účet Azure s aktivním předplatným. Vytvořte si zdarma účet.
- Pracovní prostor s daty protokolu.
Požadovaná oprávnění
K pracovním prostorům služby Log Analytics, které dotazujete, musíte mít Microsoft.OperationalInsights/workspaces/query/*/read oprávnění, která například poskytuje předdefinovaná role Čtenář Log Analytics.
Vytvoření časové řady
K vytvoření časové řady použijte operátor KQL make-series .
Pojďme vytvořit časovou řadu založenou na protokolech v tabulce Využití, která obsahuje informace o tom, kolik dat každá tabulka v pracovním prostoru ingestuje každou hodinu, včetně fakturovatelných a neúčtovatelných dat.
Tento dotaz pomocí tohoto dotazu zmapuje make-series celkové množství fakturovatelných dat přijatých jednotlivými tabulkami v pracovním prostoru každý den za posledních 21 dnů:
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
Ve výsledném grafu můžete jasně vidět některé anomálie , například v datových AzureDiagnostics typech a SecurityEvent :
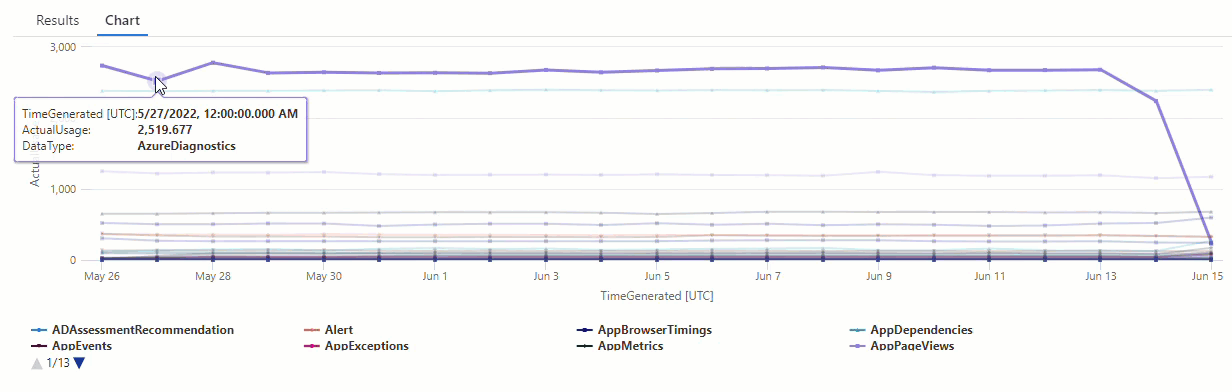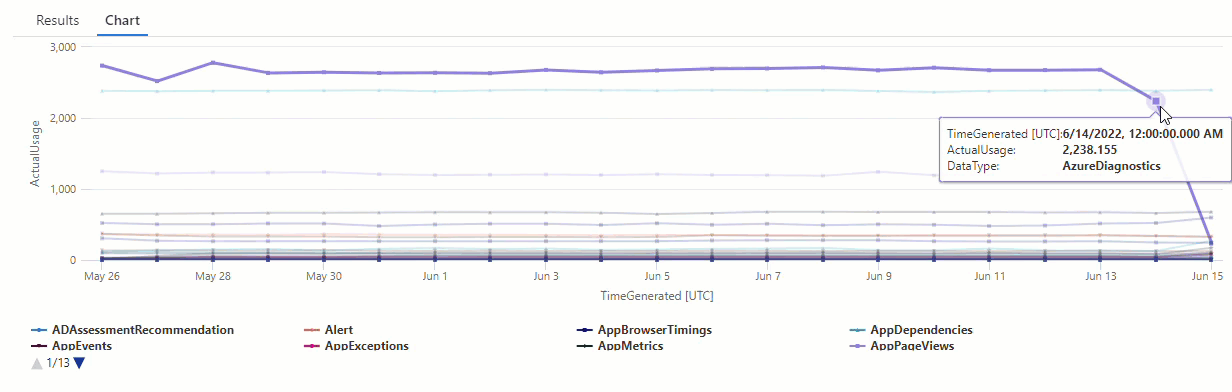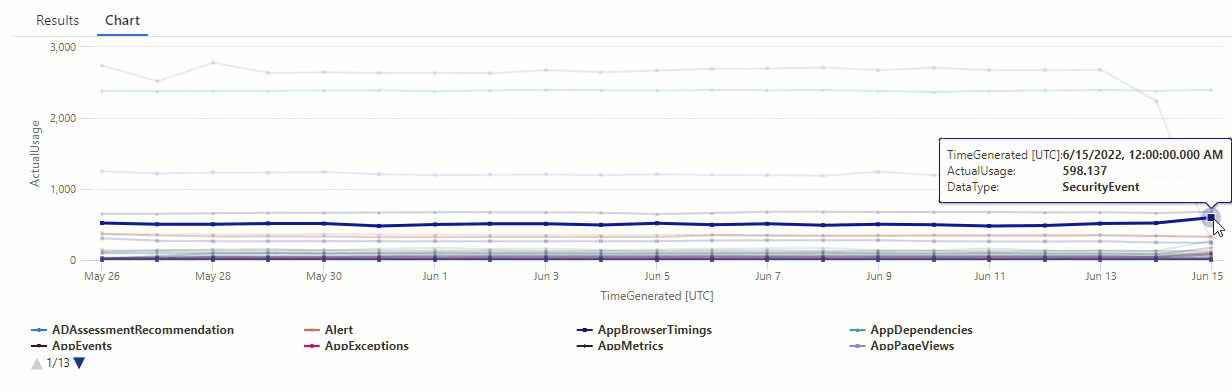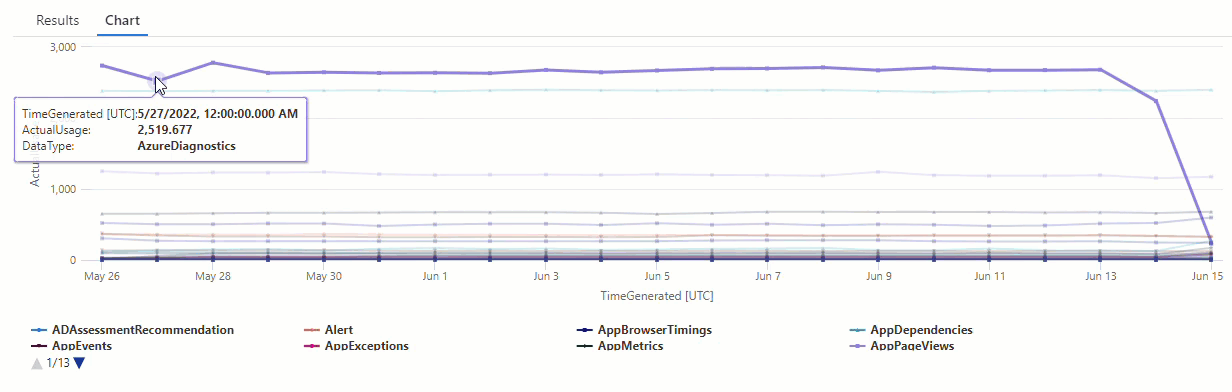
V dalším kroku použijeme funkci KQL k výpisu všech anomálií v časové řadě.
Poznámka
Další informace o make-series syntaxi a použití najdete v tématu Operátor make-series.
Vyhledání anomálií v časové řadě
Funkce series_decompose_anomalies() přebírá řadu hodnot jako vstup a extrahuje anomálie.
Dáme sadu výsledků dotazu časové řady jako vstup do series_decompose_anomalies() funkce:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Tento dotaz vrátí všechny anomálie využití pro všechny tabulky za poslední tři týdny:

Když se podíváte na výsledky dotazu, uvidíte, že funkce:
- Vypočítá očekávané denní využití pro každou tabulku.
- Porovná skutečné denní využití s očekávaným využitím.
- Přiřadí každému datovému bodu skóre anomálií, které označuje rozsah odchylky skutečného využití od očekávaného využití.
- Identifikuje kladné (
1) a záporné (-1) anomálie v každé tabulce.
Poznámka
Další informace o series_decompose_anomalies() syntaxi a použití najdete v tématu series_decompose_anomalies().
Vylepšení výsledků úpravou nastavení detekce anomálií
Doporučuje se zkontrolovat počáteční výsledky dotazu a v případě potřeby dotaz upravit. Odlehlé hodnoty ve vstupních datech můžou ovlivnit učení funkce a možná budete muset upravit nastavení detekce anomálií funkce, abyste získali přesnější výsledky.
Ve výsledcích dotazu vyfiltrujte series_decompose_anomalies() anomálie v datovém AzureDiagnostics typu:

Výsledky ukazují dvě anomálie 14. a 15. června. Porovnejte tyto výsledky s grafem z našeho prvního make-series dotazu, kde můžete vidět další anomálie z 27. a 28. května:

Rozdíl ve výsledcích nastává, protože series_decompose_anomalies() funkce hodnotí anomálie vzhledem k očekávané hodnotě využití, kterou funkce vypočítá na základě celého rozsahu hodnot ve vstupní řadě.
Pokud chcete z funkce získat přesnější výsledky, vylučte z procesu učení funkce použití k 15. červnu, což je odlehlejší hodnota v porovnání s ostatními hodnotami v řadě.
Syntaxe series_decompose_anomalies() funkce je:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points určuje počet bodů na konci řady, které se mají vyloučit z procesu učení (regrese).
Pokud chcete vyloučit poslední datový bod, nastavte Test_points na 1:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Ve výsledcích vyfiltrujte AzureDiagnostics datový typ:

Všechny anomálie v grafu z našeho prvního make-series dotazu se teď zobrazí v sadě výsledků dotazu.
Analýza původní příčiny anomálií
Porovnáním očekávaných hodnot s neobvyklými hodnotami vám pomůže pochopit příčinu rozdílů mezi těmito dvěma sadami.
Modul plug-in KQL diffpatterns() porovná dvě datové sady stejné struktury a najde vzory, které charakterizují rozdíly mezi těmito dvěma datovými sadami.
Tento dotaz porovnává AzureDiagnostics využití k 15. červnu, extrémní odlehlé hodnoty v našem příkladu, s tabulkou využití v jiných dnech:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
Dotaz identifikuje každou položku v tabulce jako výskyt v Den anomálie (15. června) nebo OtherDates. Modul diffpatterns() plug-in pak tyto sady dat rozdělí – s názvem A (v našem příkladu otherDates ) a B (v našem příkladu anomálií ) – a vrátí několik vzorů, které přispívají k rozdílům v těchto dvou sadách:

Když se podíváte na výsledky dotazu, uvidíte následující rozdíly:
- Ve všech ostatních dnech časového rozsahu dotazů existuje 24 892 147 instancí příjmu dat z prostředku CH1-GEARAMAAKS a 15. června žádný příjem dat z tohoto prostředku. Data z prostředku CH1-GEARAMAAKS tvoří 73,36 % celkového příjmu dat v jiných dnech v časovém rozsahu dotazů a 0 % celkového příjmu dat k 15. červnu.
- Ve všech ostatních dnech časového rozsahu dotazu existuje 2 168 448 instancí příjmu dat z prostředku NSG-TESTSQLMI519 a 110 544 instancí příjmu dat z tohoto prostředku k 15. červnu. Data z prostředku NSG-TESTSQLMI519 tvoří 6,39 % celkového příjmu dat v jiných dnech v časovém rozsahu dotazů a 25,61 % příjmu dat k 15. červnu.
Všimněte si, že v průměru existuje 108 422 instancí příjmu dat z prostředku NSG-TESTSQLMI519 během 20 dnů, které tvoří období ostatních dnů (vydělte 2 168 448 20). Proto se příjem dat z prostředku NSG-TESTSQLMI519 15. června výrazně neliší od příjmu dat z tohoto prostředku v jiných dnech. Vzhledem k tomu, že 15. června nedochází z CH1-GEARAMAAKS k žádnému příjmu dat, tvoří příjem dat z NSG-TESTSQLMI519 výrazně větší procento celkového příjmu dat k datu anomálie v porovnání s jinými dny.
Sloupec PercentDiffAB zobrazuje absolutní rozdíl v procentech mezi A a B (|PercentA – PercentB|), což je hlavní míra rozdílu mezi těmito dvěma sadami. Ve výchozím nastavení diffpatterns() modul plug-in vrací rozdíl mezi těmito dvěma sadami dat více než 5 %, ale tuto prahovou hodnotu můžete upravit. Chcete-li například vrátit pouze 20% nebo více rozdílů mezi dvěma datovými sadami, můžete nastavit | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) v dotazu výše. Dotaz teď vrátí jenom jeden výsledek:

Poznámka
Další informace o diffpatterns() syntaxi a použití najdete v modulu plug-in diff patterns.
Další kroky
Přečtěte si další informace: