Tipy pro zvýšení výkonu pro asynchronní sadu Java SDK služby Azure Cosmos DB v2
PLATÍ PRO: ![]() NoSQL
NoSQL
Důležité
Nejedná se o nejnovější sadu Java SDK pro službu Azure Cosmos DB! Projekt byste měli upgradovat na sadu Java SDK služby Azure Cosmos DB v4 a pak si přečíst průvodce tipy pro zvýšení výkonu sady Java SDK služby Azure Cosmos DB v4. Postupujte podle pokynů v průvodci migrací na sadu Java SDK služby Azure Cosmos DB verze 4 a průvodce upgradem nástroje Reactor vs RxJava .
Tipy pro zvýšení výkonu v tomto článku jsou určené pouze pro sadu Azure Cosmos DB Java SDK v2. Další informace najdete v průvodci odstraňováním potíží se sadou Azure Cosmos DB Async Java SDK verze 2, úložištěm Maven a asynchronní sadou Java SDK služby Azure Cosmos DB verze 2.
Důležité
31. srpna 2024 bude sada Azure Cosmos DB Async Java SDK v2.x vyřazena; sada SDK a všechny aplikace používající sadu SDK budou i nadále fungovat; Azure Cosmos DB jednoduše přestane poskytovat další údržbu a podporu pro tuto sadu SDK. Pokud chcete migrovat na sadu Java SDK služby Azure Cosmos DB verze 4, doporučujeme postupovat podle výše uvedených pokynů.
Azure Cosmos DB je rychlá a flexibilní distribuovaná databáze, která se bezproblémově škáluje s garantovanou latencí a propustností. Nemusíte provádět významné změny architektury ani psát složitý kód pro škálování databáze pomocí služby Azure Cosmos DB. Vertikální navýšení a snížení kapacity je stejně snadné jako vytvoření jediného volání rozhraní API nebo volání metody sady SDK. Vzhledem k tomu, že se k Azure Cosmos DB přistupuje prostřednictvím síťových volání, existují optimalizace na straně klienta, které můžete dosáhnout maximálního výkonu při použití sady Azure Cosmos DB Async Java SDK v2.
Pokud se tedy ptáte, jak můžu zlepšit výkon databáze? zvažte následující možnosti:
Sítě
režim Připojení: Použití přímého režimu
To, jak se klient připojuje ke službě Azure Cosmos DB, má významný vliv na výkon, zejména pokud jde o latenci na straně klienta. Připojení ionMode je nastavení konfigurace klíče dostupné pro konfiguraci klienta Připojení ionPolicy. Pro sadu Azure Cosmos DB Async Java SDK v2 jsou k dispozici dva dostupné Připojení ionModes:
Režim brány se podporuje na všech platformách sady SDK a ve výchozím nastavení je to nakonfigurovaná možnost. Pokud vaše aplikace běží v podnikové síti s přísnými omezeními brány firewall, je nejlepší volbou režim brány, protože používá standardní port HTTPS a jeden koncový bod. Nevýhodou výkonu je ale to, že režim brány zahrnuje další segment směrování sítě při každém čtení nebo zápisu dat do Azure Cosmos DB. Z tohoto důvodu nabízí přímý režim lepší výkon kvůli menšímu počtu segmentů směrování sítě.
Připojení ionMode se konfiguruje během sestavování instance DocumentClient s parametrem Připojení ionPolicy.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
public ConnectionPolicy getConnectionPolicy() {
ConnectionPolicy policy = new ConnectionPolicy();
policy.setConnectionMode(ConnectionMode.Direct);
policy.setMaxPoolSize(1000);
return policy;
}
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);
Sloučit klienty ve stejné oblasti Azure pro zajištění výkonu
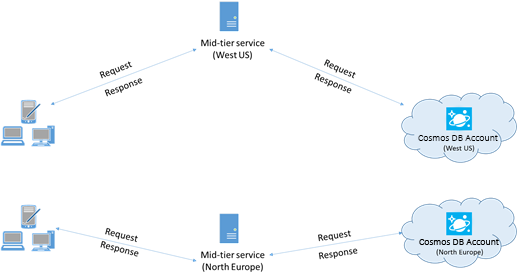
Pokud je to možné, umístěte všechny aplikace, které volají službu Azure Cosmos DB, do stejné oblasti jako databáze Azure Cosmos DB. Pro přibližné porovnání se volání služby Azure Cosmos DB ve stejné oblasti dokončí do 1 až 2 ms, ale latence mezi pobřežím USA – západ a východ je >50 ms. Tato latence se může pravděpodobně lišit od požadavku na požadavek v závislosti na trase, kterou žádost vzala při průchodu z klienta do hranice datacentra Azure. Nejnižší možné latence se dosahuje tím, že se volající aplikace nachází ve stejné oblasti Azure jako zřízený koncový bod služby Azure Cosmos DB. Seznam dostupných oblastí najdete v tématu Oblasti Azure.
Využití sady SDK
Instalace nejnovější sady SDK
Sady SDK služby Azure Cosmos DB se neustále vylepšují, aby poskytovaly nejlepší výkon. Podívejte se na stránky se zprávami k vydání verze sady Azure Cosmos DB Async Java SDK v2 a zjistěte nejnovější vylepšení sady SDK a kontroly.
Použití jednoúčelového klienta Azure Cosmos DB po celou dobu životnosti vaší aplikace
Každá instance AsyncDocumentClient je bezpečná pro přístup z více vláken a provádí efektivní správu připojení a ukládání adres do mezipaměti. Pokud chcete umožnit efektivní správu připojení a lepší výkon pomocí AsyncDocumentClient, doporučujeme použít jednu instanci AsyncDocumentClient per AppDomain po celou dobu života aplikace.
Ladění Připojení ionPolicy
Ve výchozím nastavení se požadavky Azure Cosmos DB v přímém režimu provádějí přes protokol TCP při použití sady Azure Cosmos DB Async Java SDK v2. Sada SDK interně používá speciální architekturu přímého režimu k dynamické správě síťových prostředků a zajištění nejlepšího výkonu.
V asynchronní sadě Java SDK služby Azure Cosmos DB verze 2 je nejlepší volbou přímý režim pro zlepšení výkonu databáze s většinou úloh.
- Přehled přímého režimu

Architektura na straně klienta použitá v režimu Direct umožňuje předvídatelné využití sítě a multiplexovaný přístup k replikám služby Azure Cosmos DB. Výše uvedený diagram ukazuje, jak přímý režim směruje požadavky klientů na repliky v back-endu služby Azure Cosmos DB. Architektura přímého režimu přiděluje na straně klienta až 10 kanálů na repliku databáze. Kanál je připojení TCP, kterému předchází vyrovnávací paměť požadavku, což je 30 požadavků hluboko. Kanály patřící do repliky se dynamicky přidělují podle potřeby koncovým bodem služby repliky. Když uživatel vydá požadavek v režimu Direct, TransportClient směruje požadavek na správný koncový bod služby na základě klíče oddílu. Fronta požadavků zařadí požadavky do vyrovnávací paměti před koncovým bodem služby.
možnosti konfigurace Připojení ionPolicy pro přímý režim
Jako první krok použijte následující doporučená nastavení konfigurace níže. Pokud narazíte na problémy s tímto konkrétním tématem, obraťte se na tým Služby Azure Cosmos DB.
Pokud používáte Azure Cosmos DB jako referenční databázi (to znamená, že se databáze používá pro mnoho operací čtení bodů a několik operací zápisu), může být přijatelné nastavit hodnotu idleEndpointTimeout na hodnotu 0 (to znamená bez časového limitu).
Možnost konfigurace Výchozí bufferPageSize 8192 Connectiontimeout "PT1M" idleChannelTimeout "PT0S" idleEndpointTimeout "PT1M10S" maxBufferCapacity 8388608 maxChannelsPerEndpoint 10 maxRequestsPerChannel 30 receiveHangDetectionTime "PT1M5S" requestExpiryInterval "PT5S" requestTimeout "PT1M" requestTimerResolution "PT0.5S" sendHangDetectionTime "PT10S" shutdownTimeout "PT15S"
Tipy pro programování pro přímý režim
Projděte si článek řešení potíží se sadou Azure Cosmos DB Async Java SDK v2 jako základní informace o řešení problémů se sadou SDK.
Některé důležité tipy pro programování při použití přímého režimu:
Použití multithreading v aplikaci k efektivnímu přenosu dat TCP – Po provedení požadavku by se vaše aplikace měla přihlásit k odběru příjmu dat v jiném vlákně. Když tak neučiníte, vynutí nechtěnou operaci "polo duplexní" a následné požadavky budou blokovány čekáním na odpověď předchozího požadavku.
Provádění úloh náročných na výpočetní výkon na vyhrazeném vlákně – z podobných důvodů jako předchozí tip jsou operace, jako je komplexní zpracování dat, nejlépe umístěné v samostatném vlákně. Požadavek, který načítá data z jiného úložiště dat (například pokud vlákno využívá úložiště dat Azure Cosmos DB a Sparku současně), může mít zvýšenou latenci a doporučuje se vytvořit další vlákno, které čeká na odpověď z jiného úložiště dat.
- Základní vstupně-výstupní operace sítě v sadě Azure Cosmos DB Async Java SDK v2 spravuje Netty. Podívejte se na tyto tipy, jak se vyhnout vzorům kódování, které blokují vlákna Netty V/V.
Modelování dat – Smlouva SLA služby Azure Cosmos DB předpokládá, že velikost dokumentu je menší než 1 kB. Optimalizace datového modelu a programování tak, aby upřednostněla menší velikost dokumentu, obvykle povede ke snížení latence. Pokud budete potřebovat úložiště a načítání dokumentů větších než 1 kB, doporučujeme, aby dokumenty odkazy na data ve službě Azure Blob Storage propojily.
Ladění paralelních dotazů pro dělené kolekce
Sada Azure Cosmos DB Async Java SDK v2 podporuje paralelní dotazy, které umožňují paralelně dotazovat dělenou kolekci. Další informace najdete v ukázkách kódu souvisejících s prací se sadami SDK. Paralelní dotazy jsou navržené tak, aby zlepšily latenci a propustnost dotazů oproti jejich sériovému protějšku.
Tuning setMaxDegreeOfParallelism:
Paralelní dotazy fungují dotazováním více oddílů paralelně. Data z jednotlivé dělené kolekce se ale načítají sériově s ohledem na dotaz. Proto pomocí setMaxDegreeOfParallelism nastavte počet oddílů, které mají maximální šanci dosáhnout nejvýkonnějšího dotazu, za předpokladu, že všechny ostatní systémové podmínky zůstanou stejné. Pokud neznáte počet oddílů, můžete použít setMaxDegreeOfParallelism k nastavení vysokého čísla a systém jako maximální stupeň paralelismu zvolí minimum (počet oddílů, zadaný vstup uživatelem).
Je důležité si uvědomit, že paralelní dotazy přinášejí nejlepší výhody, pokud se data rovnoměrně distribuují napříč všemi oddíly s ohledem na dotaz. Pokud je dělená kolekce tak, aby se všechna nebo většina dat vrácených dotazem soustředila do několika oddílů (v nejhorším případě jeden oddíl), pak by byl výkon dotazu kritickým bodem těchto oddílů.
Tuning setMaxBufferedItemCount:
Paralelní dotaz je navržený tak, aby předem načítá výsledky, zatímco klient zpracovává aktuální dávku výsledků. Předběžné načítání pomáhá při celkovém zlepšení latence dotazu. setMaxBufferedItemCount omezuje počet předem načtených výsledků. Nastavení setMaxBufferedItemCount na očekávaný počet vrácených výsledků (nebo vyšší číslo) umožňuje dotazu získat maximální výhodu z předběžného načtení.
Předběžné načítání funguje stejně bez ohledu na MaxDegreeOfParallelism a pro data ze všech oddílů existuje jedna vyrovnávací paměť.
Implementace backoffu v intervalech getRetryAfterInMilliseconds
Během testování výkonu byste měli zvýšit zatížení, dokud nedojde k omezení malé míry požadavků. Pokud dojde k omezení, měla by se klientská aplikace pro interval opakování zadaný serverem vrátit zpět. Dodržování zpětného běhu zajišťuje, že strávíte minimální dobu čekáním mezi opakovanými pokusy.
Škálování úlohy klienta na více instancí
Pokud testujete vysoké úrovně propustnosti (>50 000 RU/s), může se klientská aplikace stát kritickým bodem kvůli omezování využití procesoru nebo sítě. Pokud se k tomuto bodu dostanete, můžete účet služby Azure Cosmos DB dál nabízet horizontálním navýšením kapacity klientských aplikací na více serverů.
Použití adresování na základě názvů
Použijte adresování založené na názvu, kde odkazy mají formát
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, místo SelfLinks (_self), které mají formátdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>, aby se zabránilo načtení ResourceId všech prostředků použitých k vytvoření propojení. Vzhledem k tomu, že se tyto prostředky znovu vytvoří (pravděpodobně se stejným názvem), nemusí jim pomoct jejich ukládání do mezipaměti.Vyladění velikosti stránky pro dotazy nebo informační kanály pro čtení pro zajištění lepšího výkonu
Při provádění hromadného čtení dokumentů pomocí funkcí informačního kanálu pro čtení (například readDocuments) nebo při vydávání dotazu SQL se výsledky vrátí segmentovaným způsobem, pokud je sada výsledků příliš velká. Ve výchozím nastavení se výsledky vrátí v blocích po 100 položkách nebo 1 MB, podle toho, jaký limit se dosáhne prvního.
Pokud chcete snížit počet síťových cest potřebných k načtení všech použitelných výsledků, můžete velikost stránky zvětšit pomocí hlavičky požadavku x-ms-ms-max-item-count až na 1 000. V případech, kdy potřebujete zobrazit jenom několik výsledků, například pokud vaše uživatelské rozhraní nebo rozhraní API aplikace vrací jenom 10 výsledků, můžete také zmenšit velikost stránky na 10, aby se snížila propustnost spotřebovaná pro čtení a dotazy.
Velikost stránky můžete také nastavit pomocí setMaxItemCount metoda.
Použití vhodného plánovače (vyhněte se krádeži vláken IO Netty smyčky událostí)
Sada Azure Cosmos DB Async Java SDK v2 používá pro odblokování vstupně-výstupních operací netty . Sada SDK používá pro provádění vstupně-výstupních operací pevný počet vláken smyčky Netty vstupně-výstupních operací (počet procesorových jader vašeho počítače). Observable vrácené rozhraním API generuje výsledek na jednom ze sdílených vláken netty smyčky událostí vstupně-výstupních operací. Proto je důležité neblokovat sdílená vlákna Netty smyčky událostí vstupně-výstupních operací. Provádění operací náročných na procesor nebo blokování ve vlákně netty smyčky událostí vstupně-výstupních operací může způsobit zablokování nebo výrazně snížit propustnost sady SDK.
Například následující kód provede práci náročnou na procesor na vlákně io netty smyčky událostí:
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribe( resourceResponse -> { //this is executed on eventloop IO netty thread. //the eventloop thread is shared and is meant to return back quickly. // // DON'T do this on eventloop IO netty thread. veryCpuIntensiveWork(); });Po přijetí výsledku byste se měli vyhnout tomu, abyste se vyhnuli vláknu io netty smyčky událostí. Místo toho můžete zadat vlastní plánovač, který vám poskytne vlastní vlákno pro spuštění práce.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
import rx.schedulers; Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribeOn(Schedulers.computation()) subscribe( resourceResponse -> { // this is executed on threads provided by Scheduler.computation() // Schedulers.computation() should be used only when: // 1. The work is cpu intensive // 2. You are not doing blocking IO, thread sleep, etc. in this thread against other resources. veryCpuIntensiveWork(); });Na základě typu práce byste měli pro práci použít odpovídající existující plánovač RxJava. Přečtěte si zde
Schedulers.Další informace najdete na stránce GitHubu pro sadu Async Java SDK služby Azure Cosmos DB v2.
Zakázání protokolování netty
Protokolování knihovny Netty je chatty a je potřeba ho vypnout (potlačení přihlášení nemusí stačit), aby se zabránilo dalším nákladům na procesor. Pokud nejste v režimu ladění, zakažte protokolování netty úplně. Pokud tedy používáte log4j k odebrání dalších nákladů na procesor, které
org.apache.log4j.Category.callAppenders()vzniknou z netty, přidejte do základu kódu následující řádek:org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);Limit prostředků o otevření souborů operačního systému
Některé systémy Linux (například Red Hat) mají horní limit počtu otevřených souborů, takže celkový počet připojení. Spuštěním následujícího příkazu zobrazte aktuální limity:
ulimit -aPočet otevřených souborů (nofile) musí být dostatečně velký, aby měl dostatek místa pro nakonfigurovanou velikost fondu připojení a další otevřené soubory operačního systému. Dá se upravit tak, aby umožňoval větší velikost fondu připojení.
Otevřete soubor limits.conf:
vim /etc/security/limits.confPřidejte nebo upravte následující řádky:
* - nofile 100000
Zásady indexování
Vyloučení nepoužívaných cest z indexování za účelem zrychlení zápisu
Zásady indexování služby Azure Cosmos DB umožňují určit, které cesty k dokumentu se mají zahrnout nebo vyloučit z indexování pomocí cest indexování (setIncludedPaths a setExcludedPaths). Použití cest indexování může nabídnout lepší výkon zápisu a nižší úložiště indexů pro scénáře, ve kterých jsou vzory dotazů známé předem, protože náklady na indexování přímo korelují s počtem indexovaných jedinečných cest. Následující kód například ukazuje, jak vyloučit celý oddíl dokumentů (označovaný také jako podstrom) z indexování pomocí zástupného znaku "*".
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Další informace najdete v tématu Zásady indexování služby Azure Cosmos DB.
Propustnost
Měření a ladění nižších jednotek žádostí za sekundu
Azure Cosmos DB nabízí bohatou sadu databázových operací, včetně relačních a hierarchických dotazů s funkcemi definované uživatelem, uloženými procedurami a triggery – všechny operace s dokumenty v rámci kolekce databází. Náklady spojené s jednotlivými operacemi se liší v závislosti na procesoru, V/V a paměti, které jsou potřeba k dokončení operace. Místo toho, abyste přemýšleli o hardwarových prostředcích a správě hardwarových prostředků, si můžete představit jednotku žádostí (RU) jako jednu míru pro prostředky potřebné k provádění různých databázových operací a žádosti o aplikaci.
Propustnost se zřizuje na základě počtu jednotek žádostí nastavených pro každý kontejner. Spotřeba jednotek žádosti se vyhodnocuje jako sazba za sekundu. Aplikace, které překročí zřízenou jednotkovou sazbu požadavku pro svůj kontejner, jsou omezené, dokud se rychlost sníží pod zřízenou úroveň kontejneru. Pokud vaše aplikace vyžaduje vyšší úroveň propustnosti, můžete zvýšit propustnost zřízením dalších jednotek žádostí.
Složitost dotazu má vliv na počet jednotek žádostí spotřebovaných pro operaci. Počet predikátů, povaha predikátů, počet definovaných uživatelem a velikost sady zdrojových dat ovlivňují náklady na operace dotazu.
Pokud chcete změřit režii jakékoli operace (vytvoření, aktualizace nebo odstranění), zkontrolujte hlavičku x-ms-request-charge a změřte počet jednotek žádostí spotřebovaných těmito operacemi. Můžete se také podívat na ekvivalentní RequestCharge vlastnost ResourceResponse<T> nebo FeedResponse<T>.
Async Java SDK V2 (Maven com.microsoft.azure::azure-cosmosdb)
ResourceResponse<Document> response = asyncClient.createDocument(collectionLink, documentDefinition, null, false).toBlocking.single(); response.getRequestCharge();Poplatek za požadavek vrácený v této hlavičce je zlomkem zřízené propustnosti. Pokud máte například zřízeno 2000 RU/s a pokud předchozí dotaz vrátí 1 000 1 kB dokumentů, náklady na operaci jsou 1000. V rámci jedné sekundy server respektuje pouze dva takové požadavky před omezováním rychlosti následných požadavků. Další informace najdete v tématu Jednotky žádostí a kalkulačka jednotek žádosti.
Zpracování omezování rychlosti nebo příliš velké frekvence požadavků
Když se klient pokusí překročit rezervovanou propustnost pro účet, nedojde na serveru ke snížení výkonu a k žádnému využití kapacity propustnosti nad rámec rezervované úrovně. Server předem ukončí požadavek pomocí requestRateTooLarge (stavový kód HTTP 429) a vrátí hlavičku x-ms-retry-after-ms označující dobu v milisekundách, že uživatel musí před opětovným spuštěním požadavku počkat.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Sady SDK všechny implicitně zachytí tuto odpověď, respektují hlavičku opakování zadanou serverem a opakují požadavek. Pokud k vašemu účtu současně přistupuje více klientů, bude další opakování úspěšné.
Pokud máte více než jeden klient, který konzistentně pracuje nad rychlostí požadavků, výchozí počet opakování aktuálně nastavený na 9 interně klient nemusí stačit; v tomto případě klient vyvolá do aplikace výjimku DocumentClientException se stavovým kódem 429. Výchozí počet opakování lze změnit pomocí setRetryOptions v instanci Připojení ionPolicy. Ve výchozím nastavení se výjimka DocumentClientException se stavovým kódem 429 vrátí po kumulativní době čekání 30 sekund, pokud požadavek nadále funguje nad rychlostí požadavků. K tomu dochází i v případě, že je aktuální počet opakování menší než maximální počet opakování, jedná se o výchozí hodnotu 9 nebo uživatelem definovanou hodnotu.
I když automatizované chování opakování pomáhá zlepšit odolnost a použitelnost pro většinu aplikací, může při provádění srovnávacích testů výkonu přicházet k pravděpodobnosti, zejména při měření latence. Latence pozorovaná klientem se zvýší, pokud experiment dosáhne omezení serveru a způsobí tiché opakování klientské sady SDK. Abyste se vyhnuli špičkám latence během experimentů s výkonem, změřte poplatky vrácené jednotlivými operacemi a zajistěte, aby požadavky fungovaly pod rezervovanou rychlostí požadavků. Další informace najdete v tématu Jednotky žádostí.
Návrh menších dokumentů pro vyšší propustnost
Poplatek za žádost (náklady na zpracování požadavku) dané operace přímo koreluje s velikostí dokumentu. Operace s velkými dokumenty stojí více než operace u malých dokumentů.
Další kroky
Další informace o návrhu aplikace pro škálování a vysoký výkon najdete v tématu Dělení a škálování ve službě Azure Cosmos DB.