Kopírování dat do a z Azure Databricks Delta Lake pomocí Azure Data Factory nebo Azure Synapse Analytics
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivita Copy ve službě Azure Data Factory a Azure Synapse kopírovat data do a z Azure Databricks Delta Lake. Vychází z článku aktivita Copy, který představuje obecný přehled aktivity kopírování.
Podporované funkce
Tento konektor Azure Databricks Delta Lake je podporovaný pro následující funkce:
| Podporované funkce | IR |
|---|---|
| aktivita Copy (zdroj/jímka) | ① ② |
| Mapování toku dat (zdroj/jímka) | ① |
| Aktivita Lookup | ① ② |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Služba obecně podporuje Delta Lake s následujícími možnostmi, které vyhovují vašim různým potřebám.
- aktivita Copy podporuje konektor Azure Databricks Delta Lake ke kopírování dat z libovolného podporovaného zdrojového úložiště dat do tabulky Delta Lake Azure Databricks a z tabulky Delta Lake do libovolného podporovaného úložiště dat jímky. Využívá váš cluster Databricks k provedení přesunu dat. Podrobnosti najdete v části Požadavky.
- Mapování Tok dat podporuje obecný formát Delta ve službě Azure Storage jako zdroj a jímku pro čtení a zápis souborů Delta pro soubory ETL bez kódu a běží na spravovaném prostředí Azure Integration Runtime.
- Aktivity Databricks podporují orchestraci úloh ETL orientovaných na kód nebo strojového učení nad delta lake.
Požadavky
Pokud chcete použít tento konektor Azure Databricks Delta Lake, musíte v Azure Databricks nastavit cluster.
- Pokud chcete zkopírovat data do delta lake, aktivita Copy vyvolá cluster Azure Databricks ke čtení dat ze služby Azure Storage, což je původní zdroj nebo pracovní oblast, do které služba nejprve zapisuje zdrojová data prostřednictvím integrované fázované kopie. Přečtěte si další informace o Delta Lake jako jímce.
- Podobně pokud chcete kopírovat data z delta lake, aktivita Copy vyvolá cluster Azure Databricks k zápisu dat do služby Azure Storage, což je původní jímka nebo pracovní oblast, ze které služba pokračuje v zápisu dat do konečné jímky prostřednictvím integrované fázované kopie. Přečtěte si další informace o Delta Lake jako zdroji.
Cluster Databricks musí mít přístup k účtu Azure Blob nebo Azure Data Lake Storage Gen2, a to jak kontejner úložiště, systém souborů používaný pro zdroj, jímku, přípravu, tak kontejner/systém souborů, do kterého chcete zapisovat tabulky Delta Lake.
Pokud chcete použít Azure Data Lake Storage Gen2, můžete v rámci konfigurace Apache Sparku nakonfigurovat instanční objekt v clusteru Databricks. Postupujte podle kroků v Accessu přímo s instančním objektem.
Pokud chcete použít Azure Blob Storage, můžete nakonfigurovat přístupový klíč účtu úložiště nebo token SAS v clusteru Databricks jako součást konfigurace Apache Sparku. Postupujte podle kroků v Accessu k úložišti objektů blob v Azure pomocí rozhraní RDD API.
Pokud se během provádění aktivity kopírování ukončil cluster, který jste nakonfigurovali, služba ji automaticky spustí. Pokud vytváříte kanál pomocí uživatelského rozhraní pro vytváření obsahu, pro operace, jako je náhled dat, potřebujete živý cluster, služba cluster nespustí vaším jménem.
Zadání konfigurace clusteru
V rozevíracím seznamu Režim clusteru vyberte Standard.
V rozevíracím seznamu Verze Modulu runtime Databricks vyberte verzi modulu runtime Databricks.
Zapněte automatickou optimalizaci přidáním následujících vlastností do konfigurace Sparku:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueNakonfigurujte cluster v závislosti na potřebách integrace a škálování.
Podrobnosti o konfiguraci clusteru najdete v tématu Konfigurace clusterů.
Začínáme
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby s Azure Databricks Delta Lake pomocí uživatelského rozhraní
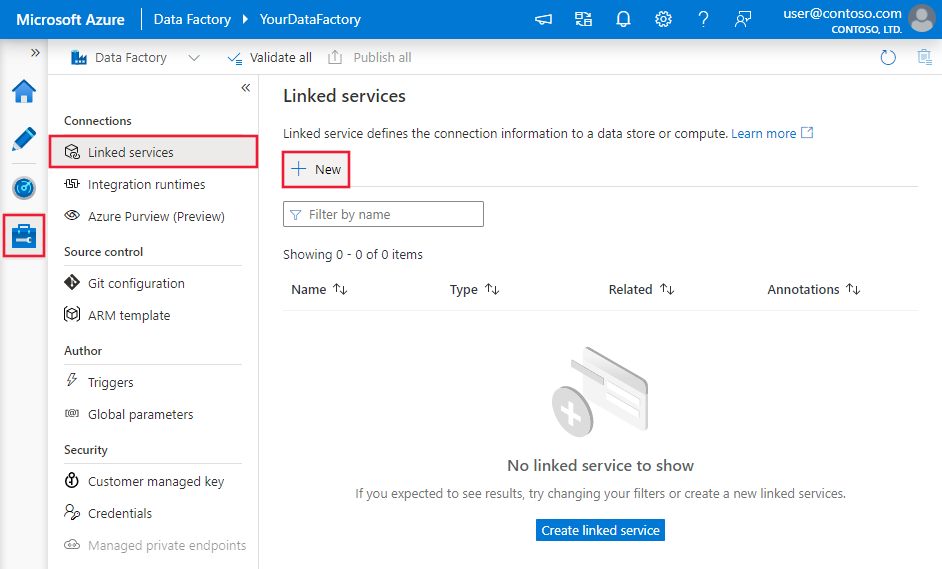
Pomocí následujícího postupu vytvořte propojenou službu s Azure Databricks Delta Lake v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte rozdíl a vyberte konektor Azure Databricks Delta Lake.

Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.
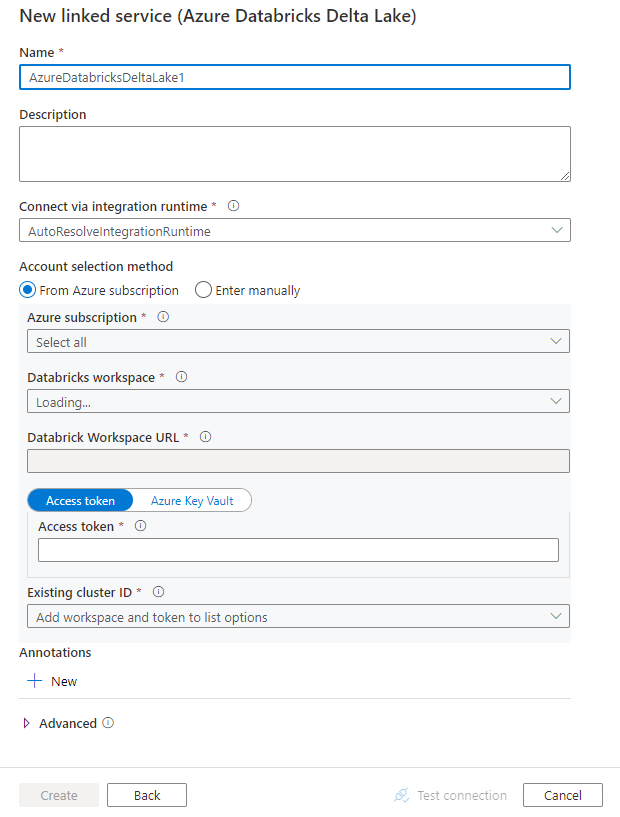

podrobnosti o konfiguraci Připojení oru
Následující části obsahují podrobnosti o vlastnostech, které definují entity specifické pro konektor Azure Databricks Delta Lake.
Vlastnosti propojené služby
Tento konektor Azure Databricks Delta Lake podporuje následující typy ověřování. Podrobnosti najdete v odpovídajících částech.
- Přístupový token
- Ověřování spravované identity přiřazené systémem
- Ověřování spravované identity přiřazené uživatelem
Token přístupu
Propojená služba Azure Databricks Delta Lake podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na AzureDatabricksDeltaLake. | Ano |
| domain | Zadejte adresu URL pracovního prostoru Azure Databricks, například https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Zadejte ID clusteru existujícího clusteru. Měl by se jednat o již vytvořený interaktivní cluster. ID clusteru interaktivního clusteru najdete v pracovním prostoru Databricks –> Clustery –> Název interaktivního clusteru –> Konfigurace –> Značky. Další informace. |
|
| accessToken | Pro ověření ve službě Azure Databricks se vyžaduje přístupový token. Přístupový token je potřeba vygenerovat z pracovního prostoru Databricks. Podrobnější kroky k vyhledání přístupového tokenu najdete tady. | |
| connectVia | Prostředí Integration Runtime , které slouží k připojení k úložišti dat. Můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime (pokud se vaše úložiště dat nachází v privátní síti). Pokud není zadaný, použije výchozí prostředí Azure Integration Runtime. | No |
Příklad:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Ověřování spravované identity přiřazené systémem
Další informace o spravovaných identitách přiřazených systémem pro prostředky Azure najdete v tématu spravovaná identita přiřazená systémem pro prostředky Azure.
Pokud chcete použít ověřování spravované identity přiřazené systémem, přidělte oprávnění následujícím postupem:
Načtěte informace o spravované identitě zkopírováním hodnoty ID objektu spravované identity vygenerovaného spolu s vaší datovou továrnou nebo pracovním prostorem Synapse.
Udělte spravované identitě správná oprávnění v Azure Databricks. Obecně platí, že ve službě Azure Databricks musíte udělit alespoň roli Přispěvatel spravované identitě přiřazené systémem v řízení přístupu (IAM).
Propojená služba Azure Databricks Delta Lake podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na AzureDatabricksDeltaLake. | Ano |
| domain | Zadejte adresu URL pracovního prostoru Azure Databricks, například https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Ano |
| clusterId | Zadejte ID clusteru existujícího clusteru. Měl by se jednat o již vytvořený interaktivní cluster. ID clusteru interaktivního clusteru najdete v pracovním prostoru Databricks –> Clustery –> Název interaktivního clusteru –> Konfigurace –> Značky. Další informace. |
Ano |
| workspaceResourceId | Zadejte ID prostředku pracovního prostoru vaší služby Azure Databricks. | Ano |
| connectVia | Prostředí Integration Runtime , které slouží k připojení k úložišti dat. Můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime (pokud se vaše úložiště dat nachází v privátní síti). Pokud není zadaný, použije výchozí prostředí Azure Integration Runtime. | No |
Příklad:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ověřování spravované identity přiřazené uživatelem
Další informace o spravovaných identitách přiřazených uživatelem pro prostředky Azure najdete v tématu spravované identity přiřazené uživatelem.
Pokud chcete použít ověřování spravované identity přiřazené uživatelem, postupujte takto:
Vytvořte jednu nebo více spravovaných identit přiřazených uživatelem a udělte oprávnění ve službě Azure Databricks. Obecně platí, že pro spravovanou identitu přiřazenou uživatelem v Řízení přístupu (IAM) v Azure Databricks musíte udělit alespoň roli Přispěvatel.
Přiřaďte jedné nebo více spravovaných identit přiřazených uživatelem k pracovnímu prostoru datové továrny nebo Synapse a vytvořte přihlašovací údaje pro každou spravovanou identitu přiřazenou uživatelem.
Propojená služba Azure Databricks Delta Lake podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na AzureDatabricksDeltaLake. | Ano |
| domain | Zadejte adresu URL pracovního prostoru Azure Databricks, například https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Ano |
| clusterId | Zadejte ID clusteru existujícího clusteru. Měl by se jednat o již vytvořený interaktivní cluster. ID clusteru interaktivního clusteru najdete v pracovním prostoru Databricks –> Clustery –> Název interaktivního clusteru –> Konfigurace –> Značky. Další informace. |
Ano |
| přihlašovací údaje | Jako objekt přihlašovacích údajů zadejte spravovanou identitu přiřazenou uživatelem. | Ano |
| workspaceResourceId | Zadejte ID prostředku pracovního prostoru vaší služby Azure Databricks. | Ano |
| connectVia | Prostředí Integration Runtime , které slouží k připojení k úložišti dat. Můžete použít prostředí Azure Integration Runtime nebo místní prostředí Integration Runtime (pokud se vaše úložiště dat nachází v privátní síti). Pokud není zadaný, použije výchozí prostředí Azure Integration Runtime. | No |
Příklad:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v článku Datové sady .
Pro datovou sadu Azure Databricks Delta Lake se podporují následující vlastnosti.
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavena na AzureDatabricksDeltaLakeDataset. | Ano |
| database | Název databáze. | Ne pro zdroj, ano pro jímku |
| table | Název tabulky delta | Ne pro zdroj, ano pro jímku |
Příklad:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Vlastnosti aktivity kopírování
Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v článku Pipelines . Tato část obsahuje seznam vlastností podporovaných zdrojem a jímkou Azure Databricks Delta Lake.
Delta Lake jako zdroj
Pokud chcete kopírovat data z Azure Databricks Delta Lake, podporují se v části zdroje aktivita Copy následující vlastnosti.
Přímá kopie z delta lake
Pokud úložiště a formát dat jímky splňují kritéria popsaná v této části, můžete pomocí aktivita Copy přímo kopírovat z tabulky Azure Databricks Delta do jímky. Služba zkontroluje nastavení a selže aktivita Copy spustit, pokud nejsou splněna následující kritéria:
Propojená služba jímky je Azure Blob Storage nebo Azure Data Lake Storage Gen2. Přihlašovací údaje účtu by měly být předem nakonfigurované v konfiguraci clusteru Azure Databricks. Další informace najdete v požadavcích.
Formát dat jímky je Parquet, text s oddělovači nebo Avro s následujícími konfiguracemi a odkazuje na složku místo souboru.
- U formátu Parquet není komprimační kodek žádný, přichycení nebo gzip.
- Formát textu s oddělovači:
rowDelimiterje libovolný jeden znak.compressionnemůže být žádný, bzip2, gzip.encodingNameUTF-7 se nepodporuje.
- U formátu Avro není komprimační kodek žádný, deflate nebo přichycení.
Ve zdroji
additionalColumnsaktivita Copy není zadán.Pokud kopírujete data do textu s oddělovači,
fileExtensionmusí být v jímce aktivity kopírování ".csv".V mapování aktivita Copy není povolen převod typu.
Příklad:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Fázovaná kopie z delta lake
Pokud úložiště dat nebo formát jímky neodpovídá kritériím přímého kopírování, jak je uvedeno v poslední části, povolte integrovanou fázovanou kopii pomocí dočasné instance úložiště Azure. Funkce fázovaného kopírování také poskytuje lepší propustnost. Služba exportuje data z Azure Databricks Delta Lake do přípravného úložiště, pak zkopíruje data do jímky a nakonec vyčistí dočasná data z přípravného úložiště. Podrobnosti o kopírování dat pomocí přípravy najdete v části Fázovaná kopie .
Pokud chcete tuto funkci použít, vytvořte propojenou službu Azure Blob Storage nebo propojenou službu Azure Data Lake Storage Gen2, která odkazuje na účet úložiště jako průběžnou přípravu. Potom zadejte enableStaging vlastnosti a stagingSettings vlastnosti v aktivita Copy.
Poznámka:
Přihlašovací údaje pracovního účtu úložiště by měly být předem nakonfigurované v konfiguraci clusteru Azure Databricks. Další informace najdete v požadavcích.
Příklad:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta Lake as sink
Pokud chcete zkopírovat data do Azure Databricks Delta Lake, podporují se v části aktivita Copy jímky následující vlastnosti.
Přímé kopírování do delta lake
Pokud vaše zdrojové úložiště dat a formát splňují kritéria popsaná v této části, můžete použít aktivita Copy k přímému kopírování ze zdroje do Azure Databricks Delta Lake. Služba zkontroluje nastavení a selže aktivita Copy spustit, pokud nejsou splněna následující kritéria:
Zdrojová propojená služba je Azure Blob Storage nebo Azure Data Lake Storage Gen2. Přihlašovací údaje účtu by měly být předem nakonfigurované v konfiguraci clusteru Azure Databricks. Další informace najdete v požadavcích.
Zdrojový formát dat je Parquet, text s oddělovači nebo Avro s následující konfigurací a odkazuje na složku místo souboru.
- U formátu Parquet není komprimační kodek žádný, přichycení nebo gzip.
- Formát textu s oddělovači:
rowDelimiterje výchozí nebo libovolný jednotlivý znak.compressionnemůže být žádný, bzip2, gzip.encodingNameUTF-7 se nepodporuje.
- U formátu Avro není komprimační kodek žádný, deflate nebo přichycení.
Ve zdroji aktivita Copy:
wildcardFileNameobsahuje pouze zástupný znak*, ale nikoli?awildcardFolderNamenení zadán.prefix,modifiedDateTimeStartmodifiedDateTimeEnd, aenablePartitionDiscoverynejsou zadány.additionalColumnsnení zadán.
V mapování aktivita Copy není povolen převod typu.
Příklad:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReadrQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Fázovaná kopie do delta lake
Pokud zdrojové úložiště dat nebo formát neodpovídá kritériím přímého kopírování, jak je uvedeno v poslední části, povolte integrovanou fázovanou kopii pomocí dočasné instance úložiště Azure. Funkce fázovaného kopírování také poskytuje lepší propustnost. Služba automaticky převede data tak, aby splňovala požadavky na formát dat, do přípravného úložiště a pak je načítá do delta lake. Nakonec vyčistí dočasná data z úložiště. Podrobnosti o kopírování dat pomocí přípravy najdete v části Fázovaná kopie .
Pokud chcete tuto funkci použít, vytvořte propojenou službu Azure Blob Storage nebo propojenou službu Azure Data Lake Storage Gen2, která odkazuje na účet úložiště jako průběžnou přípravu. Potom zadejte enableStaging vlastnosti a stagingSettings vlastnosti v aktivita Copy.
Poznámka:
Přihlašovací údaje pracovního účtu úložiště by měly být předem nakonfigurované v konfiguraci clusteru Azure Databricks. Další informace najdete v požadavcích.
Příklad:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Sledování
Stejné prostředí pro monitorování aktivit kopírování je k dispozici i pro ostatní konektory. Vzhledem k tomu, že načítání dat z/do delta lake běží v clusteru Azure Databricks, můžete zobrazit podrobné protokoly clusteru a monitorovat výkon.
Vlastnosti aktivity vyhledávání
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivita Copy najdete v podporovaných úložištích a formátech dat.