Kopírování dat z Teradata Vantage pomocí Azure Data Factory a Synapse Analytics
PLATÍ PRO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Tento článek popisuje, jak pomocí aktivity kopírování v kanálech Azure Data Factory a Synapse Analytics kopírovat data z Teradata Vantage. Vychází z přehledu aktivity kopírování.
Podporované funkce
Tento konektor Teradata je podporovaný pro následující funkce:
| Podporované funkce | IR |
|---|---|
| aktivita Copy (zdroj/-) | ① ② |
| Aktivita Lookup | ① ② |
(1) Prostředí Azure Integration Runtime (2) Místní prostředí Integration Runtime
Seznam úložišť dat podporovaných jako zdroje nebo jímky aktivitou kopírování najdete v tabulce Podporované úložiště dat.
Konkrétně tento konektor Teradata podporuje:
- Teradata verze 14.10, 15.0, 15.10, 16.0, 16.10 a 16.20.
- Kopírování dat pomocí základního ověřování, Windows nebo LDAP
- Paralelní kopírování ze zdroje Teradata Podrobnosti najdete v části Paralelní kopie z teradata .
Požadavky
Pokud se vaše úložiště dat nachází uvnitř místní sítě, virtuální sítě Azure nebo amazonového privátního cloudu, musíte nakonfigurovat místní prostředí Integration Runtime pro připojení k němu.
Pokud je vaše úložiště dat spravovanou cloudovou datovou službou, můžete použít Azure Integration Runtime. Pokud je přístup omezený na IP adresy schválené v pravidlech brány firewall, můžete do seznamu povolených přidat IP adresy prostředí Azure Integration Runtime.
K přístupu k místní síti bez nutnosti instalace a konfigurace místního prostředí Integration Runtime můžete také použít funkci Runtime integrace spravované virtuální sítě ve službě Azure Data Factory.
Další informace o mechanismech zabezpečení sítě a možnostech podporovaných službou Data Factory najdete v tématu Strategie přístupu k datům.
Pokud používáte místní prostředí Integration Runtime, mějte na paměti, že poskytuje integrovaný ovladač Teradata od verze 3.18. Nemusíte ručně instalovat žádný ovladač. Ovladač vyžaduje distribuovatelné součásti Visual C++ 2012 Update 4 na počítači s místním prostředím Integration Runtime. Pokud ho ještě nemáte nainstalovaný, stáhněte si ho odtud.
Začínáme
K provedení aktivita Copy s kanálem můžete použít jeden z následujících nástrojů nebo sad SDK:
- Nástroj pro kopírování dat
- Azure Portal
- Sada .NET SDK
- Sada Python SDK
- Azure PowerShell
- Rozhraní REST API
- Šablona Azure Resource Manageru
Vytvoření propojené služby s Teradata pomocí uživatelského rozhraní
Pomocí následujícího postupu vytvořte propojenou službu s Teradata v uživatelském rozhraní webu Azure Portal.
Přejděte na kartu Správa v pracovním prostoru Azure Data Factory nebo Synapse a vyberte Propojené služby a pak klikněte na Nový:
Vyhledejte Teradata a vyberte konektor Teradata.
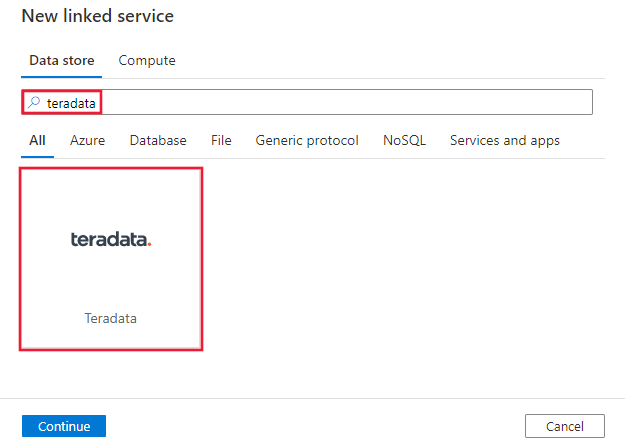
Nakonfigurujte podrobnosti o službě, otestujte připojení a vytvořte novou propojenou službu.

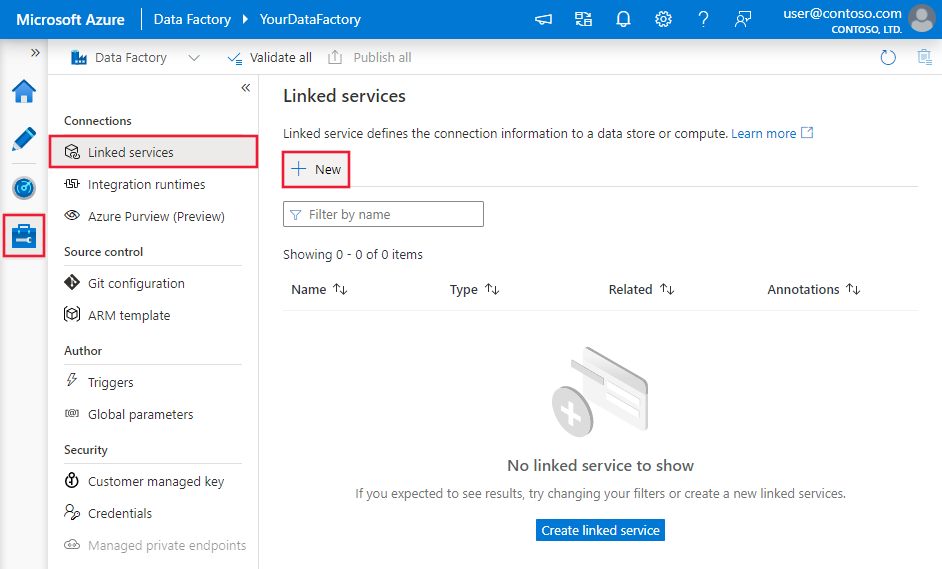

podrobnosti o konfiguraci Připojení oru
Následující části obsahují podrobnosti o vlastnostech, které slouží k definování entit služby Data Factory specifických pro konektor Teradata.
Vlastnosti propojené služby
Propojená služba Teradata podporuje následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu musí být nastavena na Teradata. | Ano |
| připojovací řetězec | Určuje informace potřebné pro připojení k instanci Teradata. Projděte si následující ukázky. Můžete také zadat heslo do služby Azure Key Vault a vytáhnout password konfiguraci z připojovací řetězec. Další podrobnosti najdete v tématu Ukládání přihlašovacích údajů ve službě Azure Key Vault . |
Ano |
| username | Zadejte uživatelské jméno pro připojení k Teradata. Platí pro použití ověřování systému Windows. | No |
| Heslo | Zadejte heslo pro uživatelský účet, který jste zadali pro uživatelské jméno. Můžete také odkazovat na tajný kód uložený ve službě Azure Key Vault. Platí pro použití ověřování systému Windows nebo odkazování na heslo ve službě Key Vault pro základní ověřování. |
No |
| connectVia | Prostředí Integration Runtime , které se má použít pro připojení k úložišti dat. Další informace najdete v části Požadavky . Pokud není zadaný, použije výchozí prostředí Azure Integration Runtime. | No |
Další vlastnosti připojení, které můžete nastavit v připojovací řetězec podle vašeho případu:
| Vlastnost | Popis | Default value |
|---|---|---|
| TdmstPortNumber | Počet portů používaných pro přístup k databázi Teradata. Tuto hodnotu neměňte, pokud to neudělá technická podpora. |
1025 |
| UseDataEncryption | Určuje, jestli se má šifrovat veškerá komunikace s databází Teradata. Povolené hodnoty jsou 0 nebo 1. - 0 (zakázáno, výchozí): Šifruje pouze ověřovací informace. - 1 (povoleno): Šifruje všechna data předávaná mezi ovladačem a databází. |
0 |
| Znaková sada | Znaková sada, která se má použít pro relaci. Např. CharacterSet=UTF16Tato hodnota může být uživatelsky definovaná znaková sada nebo jedna z následujících předdefinovaných znakových sad: -ASCII - UTF8 - UTF16 - LATIN1252_0A - LATIN9_0A - LATIN1_0A - Shift-JIS (Systém Windows, kompatibilní se systémem DOS, KANJISJIS_0S) - EUC (kompatibilní se systémem Unix, KANJIEC_0U) - IBM Mainframe (KANJIEBCDIC5035_0I) - KANJI932_1S0 - BIG5 (TCHBIG5_1R0) – GB (SCHGB2312_1T0) - SCHINESE936_6R0 - TCHINESE950_8R0 - NetworkKorean (HANGULKSC5601_2R4) - HANGUL949_7R0 - ARABIC1256_6A0 - CYRILLIC1251_2A0 - HEBREW1255_5A0 - LATIN1250_1A0 - LATIN1254_7A0 - LATIN1258_8A0 - THAI874_4A0 |
ASCII |
| MaxRespSize | Maximální velikost vyrovnávací paměti odpovědi pro požadavky SQL v kilobajtech (KB). Např. MaxRespSize=10485760Pro databázi Teradata verze 16.00 nebo novější je maximální hodnota 7361536. Pro připojení, která používají starší verze, je maximální hodnota 1048576. |
65536 |
| Název mechanismu | Chcete-li k ověření připojení použít protokol LDAP, zadejte MechanismName=LDAP. |
– |
Příklad použití základního ověřování
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad použití ověřování systému Windows
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>",
"username": "<username>",
"password": "<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Příklad použití ověřování LDAP
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;MechanismName=LDAP;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Poznámka:
Následující datová část se stále podporuje. V budoucnu byste ale měli použít nový.
Předchozí datová část:
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<Basic/Windows>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vlastnosti datové sady
Tato část obsahuje seznam vlastností podporovaných datovou sadou Teradata. Úplný seznam oddílů a vlastností dostupných pro definování datových sad najdete v tématu Datové sady.
Pokud chcete kopírovat data z Teradata, podporují se následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu datové sady musí být nastavena na TeradataTablehodnotu . |
Ano |
| database | Název instance Teradata. | Ne (pokud je zadán dotaz ve zdroji aktivity) |
| table | Název tabulky v instanci Teradata | Ne (pokud je zadán dotaz ve zdroji aktivity) |
Příklad:
{
"name": "TeradataDataset",
"properties": {
"type": "TeradataTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
}
}
}
Poznámka:
RelationalTable datová sada typu je stále podporovaná. Doporučujeme ale použít novou datovou sadu.
Předchozí datová část:
{
"name": "TeradataDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Vlastnosti aktivity kopírování
Tato část obsahuje seznam vlastností podporovaných zdrojem Teradata. Úplný seznam oddílů a vlastností dostupných pro definování aktivit najdete v tématu Kanály.
Teradata jako zdroj
Tip
Pokud chcete efektivně načítat data z Teradata pomocí dělení dat, přečtěte si další informace z části Paralelní kopírování z části Teradata .
Pokud chcete kopírovat data z Teradata, podporují se v části zdroje aktivity kopírování následující vlastnosti:
| Vlastnost | Popis | Povinní účastníci |
|---|---|---|
| type | Vlastnost typu zdroje aktivity kopírování musí být nastavena na TeradataSourcehodnotu . |
Ano |
| query | Ke čtení dat použijte vlastní dotaz SQL. Příklad: "SELECT * FROM MyTable".Když povolíte dělené zatížení, musíte připojit všechny odpovídající předdefinované parametry oddílu v dotazu. Příklady najdete v části Paralelní kopírování z části Teradata . |
Ne (pokud je zadaná tabulka v datové sadě) |
| partitionOptions | Určuje možnosti dělení dat používané k načtení dat z Teradata. Povolené hodnoty jsou: None (výchozí), Hash a DynamicRange. Pokud je povolená možnost oddílu (tj. ne None), stupeň paralelismu pro souběžné načtení dat z Teradata se řídí parallelCopies nastavením aktivity kopírování. |
No |
| oddíl Nastavení | Zadejte skupinu nastavení pro dělení dat. Použít, pokud není možnost oddílu None. |
No |
| partitionColumnName | Zadejte název zdrojového sloupce, který bude použit oddílem rozsahu nebo oddílem hash pro paralelní kopírování. Pokud není zadaný, primární index tabulky se automaticky rozdetekuje a použije se jako sloupec oddílu. Použít, pokud je Hash možnost oddílu nebo DynamicRange. Pokud k načtení zdrojových dat použijete dotaz, zahodíte ?AdfHashPartitionCondition nebo ?AdfRangePartitionColumnName v klauzuli WHERE. Viz příklad paralelní kopie z části Teradata . |
No |
| partitionUpperBound | Maximální hodnota sloupce oddílu pro zkopírování dat. Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfRangePartitionUpbound do klauzule WHERE. Příklad najdete v části Paralelní kopírování z části Teradata . |
No |
| partitionLowerBound | Minimální hodnota sloupce oddílu pro zkopírování dat. Použít, pokud je DynamicRangemožnost oddílu . Pokud k načtení zdrojových dat použijete dotaz, připojte se ?AdfRangePartitionLowbound do klauzule WHERE. Příklad najdete v části Paralelní kopírování z části Teradata . |
No |
Poznámka:
RelationalSource Zdroj kopírování typu je stále podporovaný, ale nepodporuje nové integrované paralelní načítání z Teradata (možnosti oddílů). Doporučujeme ale použít novou datovou sadu.
Příklad: Kopírování dat pomocí základního dotazu bez oddílu
"activities":[
{
"name": "CopyFromTeradata",
"type": "Copy",
"inputs": [
{
"referenceName": "<Teradata input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Paralelní kopírování z Teradata
Konektor Teradata poskytuje integrované dělení dat pro paralelní kopírování dat z Teradata. Možnosti dělení dat najdete v tabulce Zdroj aktivity kopírování.

Když povolíte dělené kopírování, služba spustí paralelní dotazy na váš zdroj Teradata, aby načetla data podle oddílů. Paralelní stupeň se řídí parallelCopies nastavením aktivity kopírování. Pokud například nastavíte parallelCopies hodnotu čtyři, služba souběžně vygeneruje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z vašeho Teradata.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat z teradata. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky | Možnost oddílu: Hodnota hash. Během provádění služba automaticky rozpozná primární indexový sloupec, použije proti němu hodnotu hash a zkopíruje data podle oddílů. |
| Načtěte velké množství dat pomocí vlastního dotazu. | Možnost oddílu: Hodnota hash. Dotaz: SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý pro použití oddílu hash. Pokud není zadaný, služba automaticky zjistí sloupec PK tabulky, kterou jste zadali v datové sadě Teradata. Během provádění služba nahradí ?AdfHashPartitionCondition logikou oddílu hash a odešle ji do Teradata. |
| Načtěte velké množství dat pomocí vlastního dotazu, který má celočíselnou hodnotu s rovnoměrně distribuovanou hodnotou pro dělení rozsahu. | Možnosti oddílu: Oddíl dynamického rozsahu Dotaz: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Rozdělení na sloupec můžete provést pomocí celočíselného datového typu. Horní mez oddílu a dolní mez oddílu: Určete, jestli chcete filtrovat podle sloupce oddílu, aby se načítala data pouze mezi dolním a horním rozsahem. Během provádění služba nahradí ?AdfRangePartitionColumnNamea ?AdfRangePartitionUpboundza skutečný název sloupce a ?AdfRangePartitionLowbound rozsahy hodnot pro každý oddíl a odešle do Teradata. Pokud je například sloupec oddílu "ID" nastavený s dolní mezí jako 1 a horní mez jako 80, s paralelním kopírováním nastaveným jako 4, služba načte data o 4 oddíly. Jejich ID jsou mezi [1,20], [21, 40], [41, 60] a [61, 80], v uvedeném pořadí. |
Příklad: Dotaz s oddílem hash
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>",
"partitionOption": "Hash",
"partitionSettings": {
"partitionColumnName": "<hash_partition_column_name>"
}
}
Příklad: Dotaz s oddílem dynamického rozsahu
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Mapování datových typů pro Teradata
Při kopírování dat z Teradata platí následující mapování z datových typů Teradata na interní datové typy používané službou. Informace o tom, jak aktivita kopírování mapuje zdrojové schéma a datový typ na jímku, najdete v tématu Mapování schématu a datového typu.
| Datový typ Teradata | Dočasný datový typ služby |
|---|---|
| BigInt | Int64 |
| Objekt blob | Bajt[] |
| Byte | Bajt[] |
| ByteInt | Int16 |
| Char | String |
| Clob | Řetězcové |
| Date | DateTime |
| Desetinné | Desetinné |
| Hodnota s dvojitou přesností | Hodnota s dvojitou přesností |
| Grafické | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Integer | Int32 |
| Den intervalu | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval den až hodina | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval den až minuta | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval den až sekunda | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Hodina intervalu | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval hodina až minuta | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval hodina až sekunda | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Minuta intervalu | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Minuta do sekundy intervalu | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval Month | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval sekundy | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval Year | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Interval Year To Month | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Počet | Hodnota s dvojitou přesností |
| Období (datum) | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Období (čas) | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Období (čas s časovým pásmem) | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Období (časové razítko) | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Období (časové razítko s časovým pásmem) | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| Smallint | Int16 |
| Čas | TimeSpan |
| Čas s časovým pásmem | TimeSpan |
| Časové razítko | DateTime |
| Časové razítko s časovým pásmem | DateTime |
| VarByte | Bajt[] |
| Varchar | String |
| VarGraphic | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
| XML | Nepodporováno Použití explicitního přetypování ve zdrojovém dotazu |
Vlastnosti aktivity vyhledávání
Podrobnosti o vlastnostech najdete v aktivitě Vyhledávání.
Související obsah
Seznam úložišť dat podporovaných jako zdroje a jímky aktivitou kopírování najdete v tématu Podporované úložiště dat.