Použití služby Azure Data Factory k migraci dat z místního clusteru Hadoop do služby Azure Storage
PLATÍ PRO: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Vyzkoušejte si službu Data Factory v Microsoft Fabric, řešení pro analýzy typu all-in-one pro podniky. Microsoft Fabric zahrnuje všechno od přesunu dat až po datové vědy, analýzy v reálném čase, business intelligence a vytváření sestav. Přečtěte si, jak začít používat novou zkušební verzi zdarma.
Azure Data Factory poskytuje výkonný, robustní a nákladově efektivní mechanismus pro migraci dat ve velkém měřítku z místního HDFS do služby Azure Blob Storage nebo Azure Data Lake Storage Gen2.
Data Factory nabízí dva základní přístupy k migraci dat z místního HDFS do Azure. Přístup můžete vybrat na základě vašeho scénáře.
- Režim DistCp služby Data Factory (doporučeno): Ve službě Data Factory můžete pomocí DistCp (distribuované kopie) kopírovat soubory tak, jak je, do služby Azure Blob Storage (včetně fázované kopie) nebo Azure Data Lake Store Gen2. Využijte službu Data Factory integrovanou s DistCp k využití existujícího výkonného clusteru, abyste dosáhli nejlepší propustnosti kopírování. Získáte také výhodu flexibilního plánování a jednotného prostředí monitorování ze služby Data Factory. V závislosti na konfiguraci služby Data Factory aktivita kopírování automaticky vytvoří příkaz DistCp, odešle data do clusteru Hadoop a pak monitoruje stav kopírování. Pro migraci dat z místního clusteru Hadoop do Azure doporučujeme režim DistCp služby Data Factory.
- Režim nativního prostředí Integration Runtime služby Data Factory: DistCp není možnost ve všech scénářích. Například v prostředí Azure Virtual Networks nástroj DistCp nepodporuje privátní partnerský vztah Azure ExpressRoute s koncovým bodem virtuální sítě Azure Storage. V některých případech navíc nechcete používat stávající cluster Hadoop jako modul pro migraci dat, takže do clusteru nezatěžujete velké zatížení, což může mít vliv na výkon stávajících úloh ETL. Místo toho můžete jako modul, který kopíruje data z místního HDFS do Azure, použít nativní funkci prostředí Data Factory Integration Runtime.
Tento článek obsahuje následující informace o obou přístupech:
- Výkon
- Odolnost kopírování
- Zabezpečení sítě
- Architektura řešení vysoké úrovně
- Osvědčené postupy implementace
Výkon
V režimu DistCp služby Data Factory je propustnost stejná jako v případě, že nástroj DistCp používáte nezávisle. Režim DistCp služby Data Factory maximalizuje kapacitu stávajícího clusteru Hadoop. DistCp můžete použít pro velké mezi clustery nebo kopírování uvnitř clusteru.
DistCp používá MapReduce k ovlivnění distribuce, zpracování chyb a obnovení a generování sestav. Rozbalí seznam souborů a adresářů do vstupu pro mapování úkolů. Každý úkol zkopíruje oddíl souboru zadaný ve zdrojovém seznamu. Pomocí služby Data Factory integrované s DistCp můžete vytvářet kanály, které plně využívají šířku pásma sítě, IOPS úložiště a šířku pásma k maximalizaci propustnosti přesunu dat pro vaše prostředí.
Nativní režim prostředí Integration Runtime služby Data Factory také umožňuje paralelismus na různých úrovních. Paralelismus můžete použít k plnému využití šířky pásma sítě, IOPS úložiště a šířky pásma k maximalizaci propustnosti přesunu dat:
- Jedna aktivita kopírování může využívat škálovatelné výpočetní prostředky. S místním prostředím Integration Runtime můžete ručně vertikálně navýšit kapacitu počítače nebo vertikálně navýšit kapacitu na více počítačů (až čtyři uzly). Jedna aktivita kopírování rozdělí svoji sadu souborů napříč všemi uzly.
- Jedna aktivita kopírování čte z úložiště dat a zapisuje je do úložiště dat pomocí více vláken.
- Tok řízení služby Data Factory může paralelně spouštět více aktivit kopírování. Můžete například použít smyčku For Each.
Další informace najdete v průvodci výkonem aktivity kopírování.
Odolnost
V režimu DistCp služby Data Factory můžete použít různé parametry příkazového řádku DistCp (například -iignorovat chyby nebo -updatezapisovat data, když se zdrojový soubor a cílový soubor liší velikostí) pro různé úrovně odolnosti.
V režimu nativního prostředí Integration Runtime služby Data Factory má služba Data Factory v jednom spuštění aktivity kopírování integrovaný mechanismus opakování. Dokáže zpracovat určitou úroveň přechodných selhání v úložištích dat nebo v podkladové síti.
Při binárním kopírování z místního HDFS do úložiště objektů blob a z místního HDFS do Data Lake Store Gen2 služba Data Factory automaticky provádí kontrolní body do velkého rozsahu. Pokud spuštění aktivity kopírování selže nebo vyprší časový limit, v dalším opakování (ujistěte se, že počet opakování je > 1), kopírování se obnoví z posledního bodu selhání, a ne na začátku.
Zabezpečení sítě
Služba Data Factory ve výchozím nastavení přenáší data z místního HDFS do úložiště objektů blob nebo Azure Data Lake Storage Gen2 pomocí šifrovaného připojení přes protokol HTTPS. HTTPS poskytuje šifrování přenášených dat a zabraňuje odposlouchávání a útokům typu man-in-the-middle.
Případně pokud nechcete, aby se data přenášela přes veřejný internet, abyste měli vyšší zabezpečení, můžete data přenášet přes privátní partnerský vztah přes ExpressRoute.
Architektura řešení
Tento obrázek znázorňuje migraci dat přes veřejný internet:
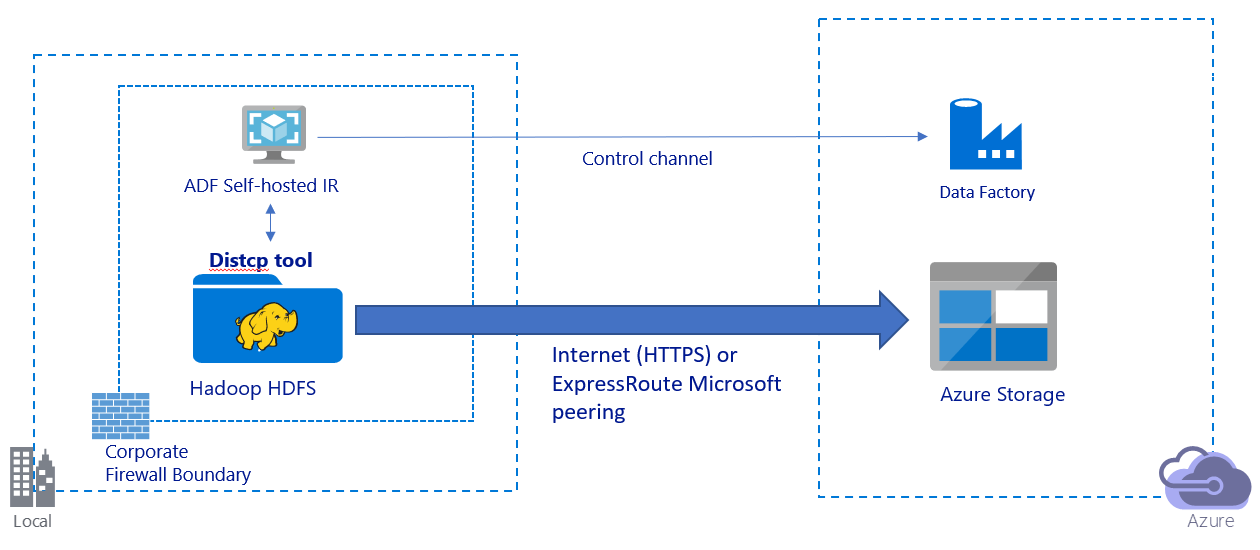
- V této architektuře se data bezpečně přenášejí pomocí protokolu HTTPS přes veřejný internet.
- Režim DistCp služby Data Factory doporučujeme používat v prostředí veřejné sítě. Pokud chcete dosáhnout nejlepší propustnosti kopírování, můžete využít výhod výkonného existujícího clusteru. Získáte také výhod flexibilního plánování a sjednoceného prostředí monitorování ze služby Data Factory.
- Pro tuto architekturu musíte nainstalovat místní prostředí Integration Runtime služby Data Factory na počítač s Windows za podnikovou bránou firewall, abyste odeslali příkaz DistCp do clusteru Hadoop a mohli monitorovat stav kopírování. Vzhledem k tomu, že počítač není motorem, který bude přesouvat data (pouze pro účely řízení), nemá kapacita počítače vliv na propustnost přesunu dat.
- Podporují se existující parametry z příkazu DistCp.
Tento obrázek znázorňuje migraci dat přes privátní propojení:
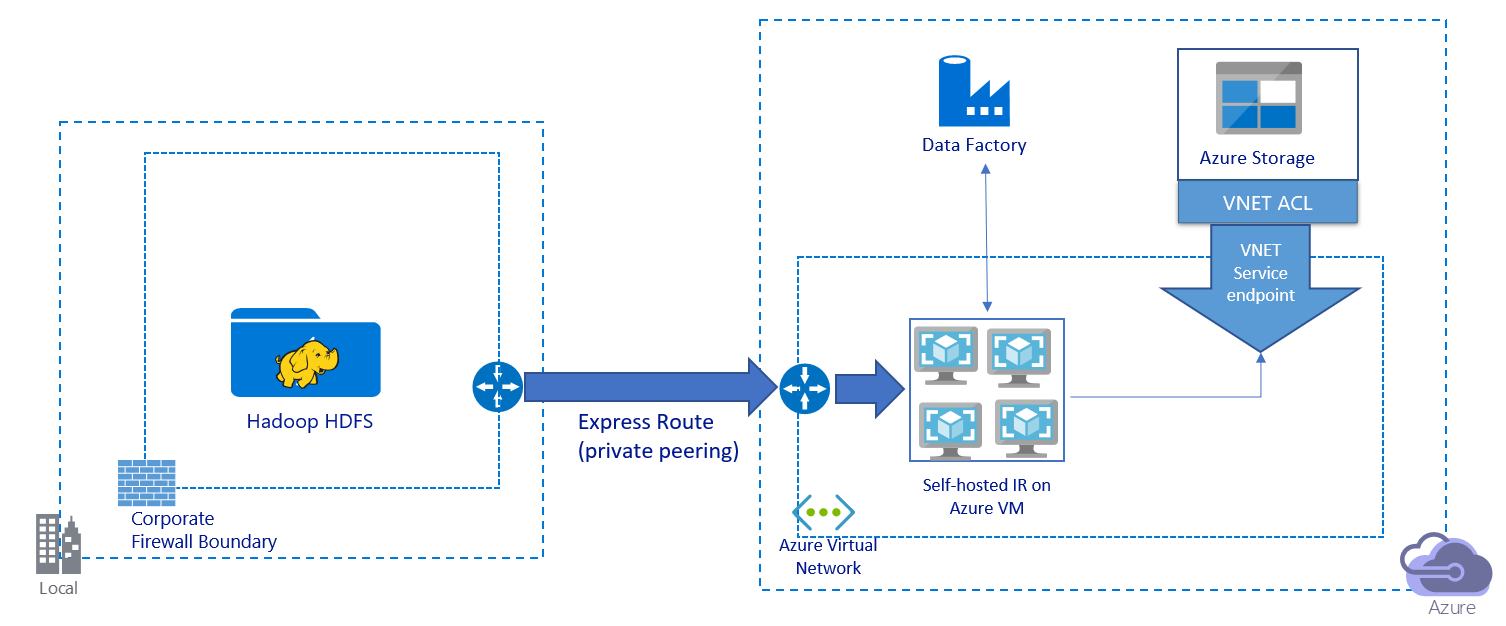
- V této architektuře se data migrují přes privátní partnerský vztah přes Azure ExpressRoute. Data nikdy neprocházejí přes veřejný internet.
- Nástroj DistCp nepodporuje privátní partnerský vztah ExpressRoute s koncovým bodem virtuální sítě Azure Storage. K migraci dat doporučujeme použít nativní funkci služby Data Factory prostřednictvím prostředí Integration Runtime.
- Pro tuto architekturu musíte nainstalovat místní prostředí Integration Runtime služby Data Factory na virtuální počítač s Windows ve vaší virtuální síti Azure. Kapacitu virtuálního počítače můžete vertikálně navýšit nebo vertikálně navýšit kapacitu na několik virtuálních počítačů, abyste plně využili IOPS nebo šířku pásma sítě a úložiště.
- Doporučená konfigurace pro každý virtuální počítač Azure (s nainstalovaným místním prostředím Integration Runtime služby Data Factory) je Standard_D32s_v3 s 32 vCPU a 128 GB paměti. Během migrace dat můžete monitorovat využití procesoru a paměti virtuálního počítače a zjistit, jestli potřebujete vertikálně navýšit kapacitu virtuálního počítače, abyste dosáhli lepšího výkonu, nebo vertikálně snížit kapacitu virtuálního počítače, aby se snížily náklady.
- Horizontální navýšení kapacity můžete také rozšířit přidružením až čtyř uzlů virtuálních počítačů k jednomu místnímu prostředí Integration Runtime. Jedna úloha kopírování spuštěná v místním prostředí Integration Runtime automaticky rozdělí sadu souborů a využívá všechny uzly virtuálních počítačů ke kopírování souborů paralelně. Pro zajištění vysoké dostupnosti doporučujeme začít se dvěma uzly virtuálních počítačů, abyste se při migraci dat vyhnuli scénáři způsobujícím selhání s jedním bodem.
- Při použití této architektury máte k dispozici počáteční migraci dat snímků a rozdílovou migraci dat.
Osvědčené postupy implementace
Při implementaci migrace dat doporučujeme postupovat podle těchto osvědčených postupů.
Ověřování a správa přihlašovacích údajů
- K ověření ve službě HDFS můžete použít windows (Kerberos) nebo anonymní.
- Pro připojení ke službě Azure Blob Storage se podporuje více typů ověřování. Důrazně doporučujeme používat spravované identity pro prostředky Azure. Spravované identity založené na automaticky spravované identitě služby Data Factory v Microsoft Entra ID umožňují konfigurovat kanály bez zadání přihlašovacích údajů v definici propojené služby. Případně se můžete ověřit ve službě Blob Storage pomocí instančního objektu, sdíleného přístupového podpisu nebo klíče účtu úložiště.
- Pro připojení k Data Lake Storage Gen2 se podporuje také více typů ověřování. Důrazně doporučujeme používat spravované identity pro prostředky Azure, ale můžete také použít instanční objekt nebo klíč účtu úložiště.
- Pokud nepoužíváte spravované identity pro prostředky Azure, důrazně doporučujeme ukládat přihlašovací údaje ve službě Azure Key Vault , aby bylo snazší centrálně spravovat a obměňovat klíče bez úprav propojených služeb služby Data Factory. Toto je také osvědčený postup pro CI/CD.
Počáteční migrace dat snímků
V režimu DistCp služby Data Factory můžete vytvořit jednu aktivitu kopírování, která odešle příkaz DistCp a pomocí různých parametrů řídí chování počáteční migrace dat.
V nativním režimu prostředí Integration Runtime služby Data Factory doporučujeme oddíl dat, zejména při migraci více než 10 TB dat. Pokud chcete data rozdělit, použijte názvy složek v HDFS. Každá úloha kopírování data Factory pak může současně kopírovat jeden oddíl složky. Pro lepší propustnost můžete souběžně spustit několik úloh kopírování služby Data Factory.
Pokud některé úlohy kopírování selžou kvůli přechodným problémům se sítí nebo úložištěm dat, můžete znovu spustit neúspěšnou úlohu kopírování a znovu načíst konkrétní oddíl z HDFS. Jiné úlohy kopírování, které načítají jiné oddíly, nejsou ovlivněné.
Rozdílová migrace dat
V režimu DistCp služby Data Factory můžete pro rozdílovou migraci dat použít parametr -updatepříkazového řádku DistCp , zapisovat data, pokud se zdrojový soubor a cílový soubor liší velikostí.
V nativním režimu integrace služby Data Factory je nejvýkonnější způsob identifikace nových nebo změněných souborů z HDFS pomocí konvence vytváření názvů rozdělených podle času. Pokud jsou data v HDFS časově rozdělená s informacemi o časovém řezu v názvu souboru nebo složky (například /yyyy/mm/dd/file.csv), může váš kanál snadno zjistit, které soubory a složky se mají přírůstkově kopírovat.
Pokud data v HDFS nejsou časově dělená, může služba Data Factory identifikovat nové nebo změněné soubory pomocí hodnoty LastModifiedDate . Data Factory prohledá všechny soubory z HDFS a zkopíruje jenom nové a aktualizované soubory s časovým razítkem poslední změny, které jsou větší než nastavená hodnota.
Pokud máte v HDFS velký počet souborů, počáteční prohledávání souborů může trvat dlouhou dobu bez ohledu na to, kolik souborů odpovídá podmínce filtru. V tomto scénáři doporučujeme nejprve rozdělit data pomocí stejného oddílu, který jste použili pro počáteční migraci snímků. Kontrola souborů pak může probíhat paralelně.
Odhad ceny
Zvažte následující kanál pro migraci dat z HDFS do úložiště objektů blob v Azure:
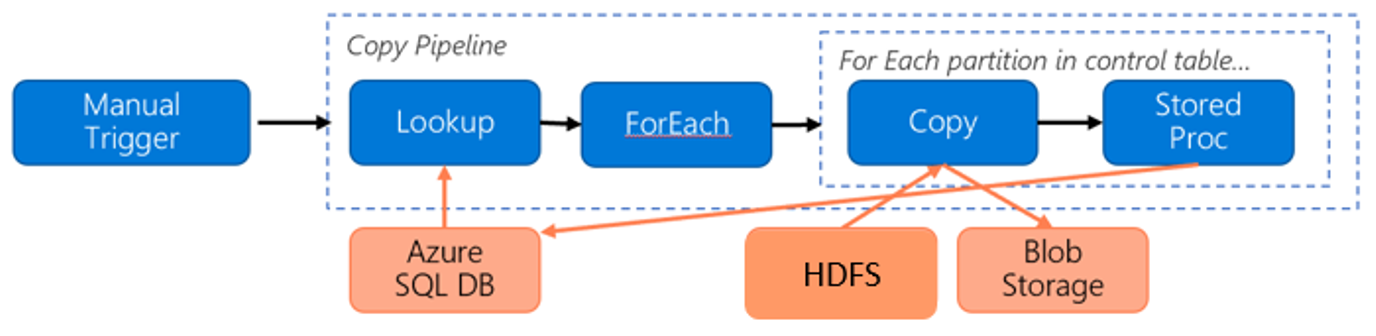
Předpokládejme následující informace:
- Celkový objem dat je 1 PB.
- Migrujete data pomocí nativního režimu prostředí Integration Runtime služby Data Factory.
- 1 PB je rozděleno na 1 000 oddílů a každá kopie přesune jeden oddíl.
- Každá aktivita kopírování je nakonfigurovaná s jedním místním prostředím Integration Runtime, který je přidružený ke čtyř počítačům a který dosahuje propustnosti 500 MB/s.
- Souběžnost ForEach je nastavená na 4 a agregovaná propustnost je 2 GB/s.
- Dokončení migrace trvá celkem 146 hodin.
Tady je odhadovaná cena na základě našich předpokladů:
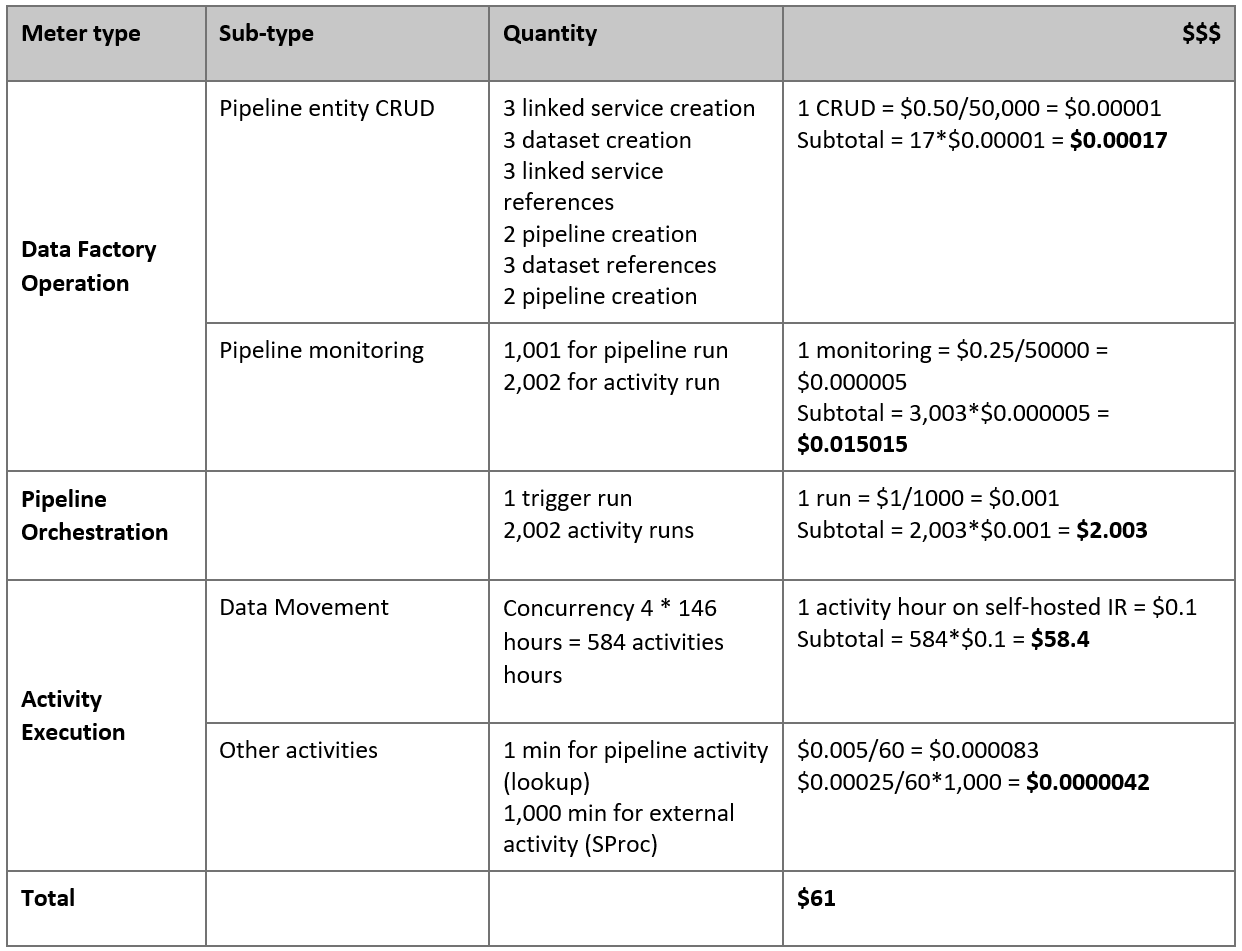
Poznámka:
Jedná se o hypotetický příklad cen. Vaše skutečné ceny závisí na skutečné propustnosti ve vašem prostředí. Cena virtuálního počítače Azure s Windows (s nainstalovaným místním prostředím Integration Runtime) není zahrnutá.
Další odkazy
- Konektor HDFS
- Konektor služby Azure Blob Storage
- Konektor Azure Data Lake Storage Gen2
- průvodce laděním výkonu aktivita Copy
- Vytvoření a konfigurace místního prostředí Integration Runtime
- Vysoká dostupnost a škálovatelnost místního prostředí Integration Runtime
- Aspekty zabezpečení přesunu dat
- Ukládání přihlašovacích údajů ve službě Azure Key Vault
- Přírůstkové kopírování souboru na základě názvu souboru rozděleného podle času
- Kopírování nových a změněných souborů na základě funkce LastModifiedDate
- Stránka s cenami služby Data Factory