Kurz: Analýza dat Apache Sparku pomocí Power BI ve službě HDInsight
V tomto kurzu se dozvíte, jak pomocí Microsoft Power BI vizualizovat data v clusteru Apache Spark ve službě Azure HDInsight.
V tomto kurzu se naučíte:
- Vizualizace dat Sparku pomocí Power BI
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
Dokončete článek Kurz: Načtení dat a spouštění dotazů v clusteru Apache Spark ve službě Azure HDInsight.
Volitelné: Zkušební předplatné Power BI
Ověření dat
Poznámkový blok Jupyter, který jste vytvořili v předchozím kurzu , obsahuje kód pro vytvoření hvac tabulky. Tato tabulka je založená na souboru CSV, který je k dispozici ve všech clusterech HDInsight Spark na adrese \HdiSamples\HdiSamples\SensorSampleData\hvac\hvac.csv. Pomocí následujícího postupu ověřte data.
Z poznámkového bloku Jupyter Vložte následující kód a stiskněte SHIFT +ENTER. Kód ověří existenci tabulek.
%%sql SHOW TABLESVýstup vypadá takto:
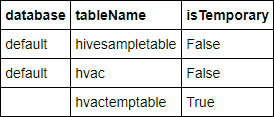
Pokud jste poznámkový blok před zahájením tohoto kurzu zavřeli, tabulka
hvactemptableje vyčištěná, takže se ve výstupu nezobrazí. Z nástrojů BI je možný přístup pouze k tabulkám Hive uloženým v metastoru (ty mají ve sloupci isTemporary označení False). V tomto kurzu se připojíte k tabulce hvac, kterou jste vytvořili.Do prázdné buňky vložte následující kód a pak stiskněte SHIFT + ENTER. Kód ověří data v tabulce.
%%sql SELECT * FROM hvac LIMIT 10Výstup vypadá takto:
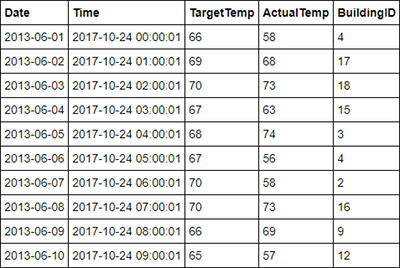
V nabídce Soubor poznámkového bloku vyberte Zavřít a zastavit. Vypněte poznámkový blok a uvolněte tak prostředky.
Vizualizace dat
V této části pomocí Power BI vytvoříte vizualizace, sestavy a řídicí panely z dat v clusteru Spark.
Vytvoření sestavy v Power BI Desktopu
Prvními kroky při práci se Sparkem je připojení ke clusteru v Power BI Desktopu, načtení dat z clusteru a vytvoření základní vizualizace na základě těchto dat.
Otevřete Power BI Desktop. Pokud se otevře úvodní obrazovka, zavřete úvodní obrazovku.
Na kartě Domů přejděte na Získat další data>...
Zadejte
Sparkdo vyhledávacího pole, vyberte Azure HDInsight Spark a pak vyberte Připojení.
Do textového pole Server zadejte adresu URL clusteru (ve formuláři).
mysparkcluster.azurehdinsight.netV části Režim připojení k datům vyberte DirectQuery. Pak vyberte OK.
V případě Sparku můžete použít jakýkoli režim připojení dat. Pokud použijete DirectQuery, změny se v sestavách projeví bez nutnosti aktualizace celé datové sady. Pokud data importujete, musíte datovou sadu aktualizovat, aby se změny projevily. Další informace o tom, jak a kdy použít DirectQuery, najdete v tématu Použití DirectQuery v Power BI.
Zadejte informace o přihlašovacím účtu SLUŽBY HDInsight a pak vyberte Připojení. Výchozí název účtu je admin.
hvacVyberte tabulku, počkejte, až se zobrazí náhled dat, a pak vyberte Načíst.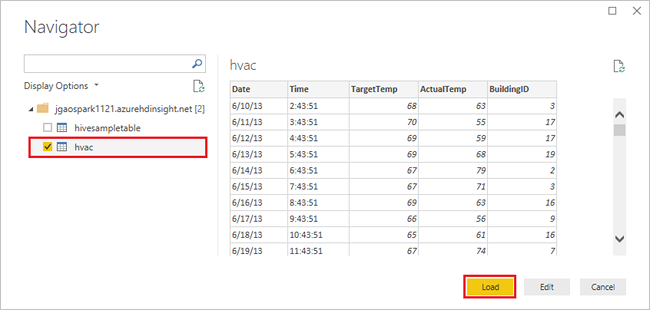
Power BI Desktop má všechny potřebné informace pro připojení ke clusteru Spark a načtení dat z tabulky
hvac. Tabulka a její sloupce se zobrazí v podokně Pole.Vizualizujte rozdíl mezi cílovou teplotou a skutečnou teplotou jednotlivých budov:
V podokně VIZUALIZACE vyberte Plošný graf.
Přetáhněte pole BuildingID (ID budovy) do části Osa a pole ActualTemp (Skutečná teplota) a TargetTemp (Cílová teplota) do části Hodnota.

Diagram vypadá takto:
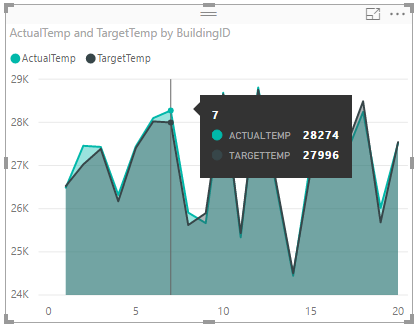
Vizualizace ve výchozím nastavení zobrazí pro ActualTemp a TargetTemp součet hodnot. V podokně Vizualizace vyberte šipku dolů vedle položky ActualTemp a TragetTemp. Zobrazí se vybraná možnost Součet.
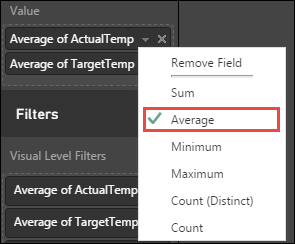
V podokně Vizualizace vyberte šipky dolů vedle položky ActualTemp a TragetTemp , výběrem možnosti Průměr získáte průměr skutečných a cílových teplot pro každou budovu.
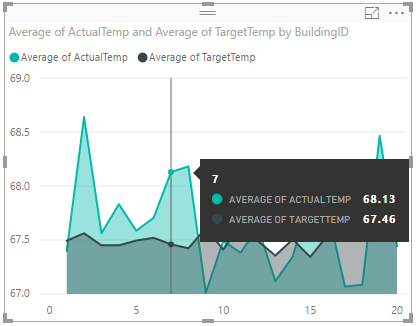
Vaše vizualizace dat by měla vypadat podobně jako na následujícím snímku obrazovky. Přesunutím kurzoru nad vizualizaci zobrazte popisky s relevantními daty.
Přejděte na Uložit soubor>, zadejte název
BuildingTemperaturesouboru a pak vyberte Uložit.
Publikování sestavy ve službě Power BI (volitelné)
Služba Power BI umožňuje sdílet sestavy a řídicí panely napříč organizací. V této části nejprve publikujete datovou sadu a sestavu. Pak sestavu připnete na řídicí panel. Řídicí panely se obvykle používají k zaměření na podmnožinu dat v sestavě. V sestavě máte jenom jednu vizualizaci, ale přesto je užitečné si projít kroky.
Otevřete Power BI Desktop.
Na kartě Domovská stránka vyberte Publikovat.

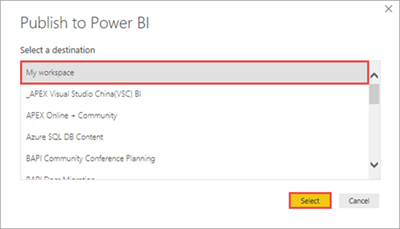
Vyberte pracovní prostor, do které chcete publikovat datovou sadu a sestavu, a pak vyberte Vybrat. Na následujícím obrázku je vybraný výchozí pracovní prostor My Workspace.
Po úspěšném publikování v Power BI vyberte Otevřít BuildingTemperature.pbix.
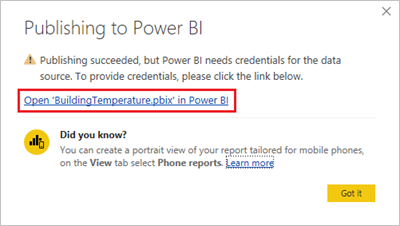
V služba Power BI vyberte Zadat přihlašovací údaje.

Vyberte Upravit přihlašovací údaje.
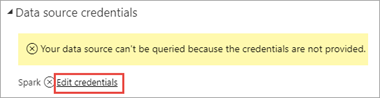
Zadejte informace o přihlašovacím účtu SLUŽBY HDInsight a pak vyberte Přihlásit se. Výchozí název účtu je admin.

V levém podokně přejděte do části Pracovní prostory Moje sestavy> pracovního prostoru>a pak vyberte BuildingTemperature.
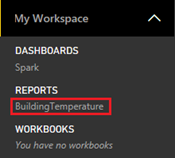
V části DATOVÉ SADY v levém podokně by se také měla zobrazit datová sada BuildingTemperature.
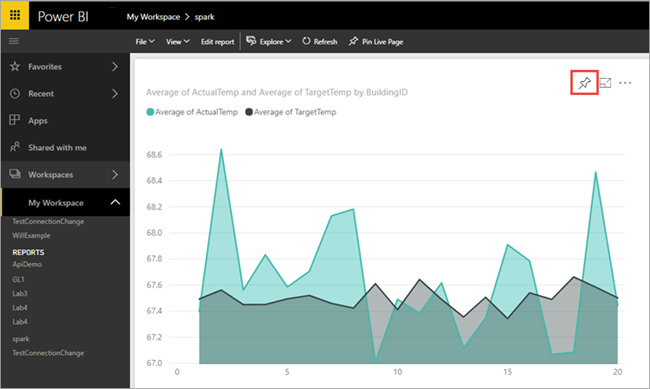
Vizuál, který jste vytvořili v Power BI Desktopu, je teď dostupný ve službě Power BI.
Najeďte myší na vizualizaci a pak vyberte ikonu připínáčku v pravém horním rohu.
Vyberte Nový řídicí panel, zadejte název
Building temperaturea pak vyberte Připnout.
V sestavě vyberte Přejít na řídicí panel.
Váš vizuál je připnutý na řídicím panelu. Do sestavy můžete přidat další vizuály a připnout je na stejný řídicí panel. Další informace o sestavách a řídicích panelech najdete v tématu Sestavy v Power BI a řídicích panelech v Power BI.
Vyčištění prostředků
Po dokončení kurzu můžete cluster odstranit. S HDInsight jsou vaše data uložená ve službě Azure Storage, takže můžete cluster bezpečně odstranit, když se nepoužívá. Za cluster HDInsight se vám také účtují poplatky, i když se nepoužívá. Vzhledem k tomu, že poplatky za cluster jsou mnohokrát vyšší než poplatky za úložiště, dává smysl odstranit clustery, když se nepoužívají.
Pokud chcete cluster odstranit, přečtěte si téma Odstranění clusteru HDInsight pomocí prohlížeče, PowerShellu nebo Azure CLI.
Další kroky
V tomto kurzu jste zjistili, jak pomocí Microsoft Power BI vizualizovat data v clusteru Apache Spark ve službě Azure HDInsight. V dalším článku se dozvíte, jak můžete vytvořit aplikaci strojového učení.