Řešení potíží s Apache Sparkem s využitím služby Azure HDInsight
Seznamte se s hlavními problémy a jejich řešeními při práci s datovými částmi Apache Sparku v Apache Ambari.
Jak na clusterech nakonfigurovat aplikaci Apache Spark pomocí Apache Ambari?
Hodnoty konfigurace Sparku je možné ladit, abyste se vyhnuli výjimce aplikace OutofMemoryError Apache Spark. Následující kroky ukazují výchozí hodnoty konfigurace Sparku ve službě Azure HDInsight:
Přihlaste se k Ambari pomocí
https://CLUSTERNAME.azurehdidnsight.netpřihlašovacích údajů clusteru. Na úvodní obrazovce se zobrazí řídicí panel přehledu. Mezi HDInsight 4.0 existují mírné kosmetické rozdíly.Přejděte do konfigurací Spark2>.
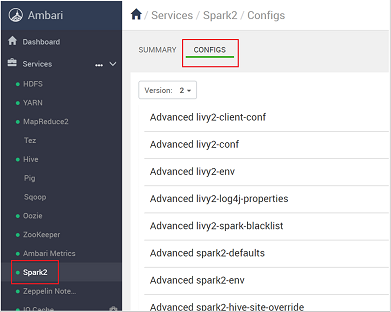
V seznamu konfigurací vyberte a rozbalte custom-spark2-defaults.
Vyhledejte nastavení hodnoty, které potřebujete upravit, například spark.executor.memory. V tomto případě je hodnota 9728m příliš vysoká.
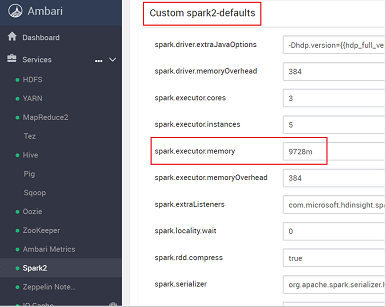
Nastavte hodnotu na doporučené nastavení. Pro toto nastavení se doporučuje hodnota 2048 min .
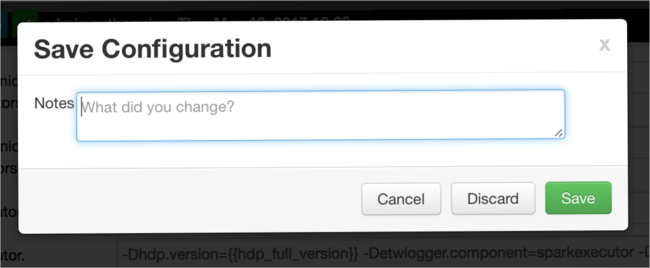
Uložte hodnotu a uložte konfiguraci. Zvolte Uložit.

Napište poznámku o změnách konfigurace a pak vyberte Uložit.
Pokud nějaké konfigurace vyžadují pozornost, budete upozorněni. Poznamenejte si položky a pak vyberte Přesto pokračovat.

Při každém uložení konfigurace se zobrazí výzva k restartování služby. Vyberte Restartovat.
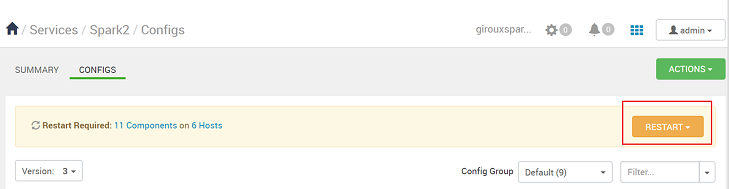
Potvrďte restartování.
Můžete zkontrolovat spuštěné procesy.
Můžete přidat konfigurace. V seznamu konfigurací vyberte Custom-spark2-defaults a pak vyberte Přidat vlastnost.
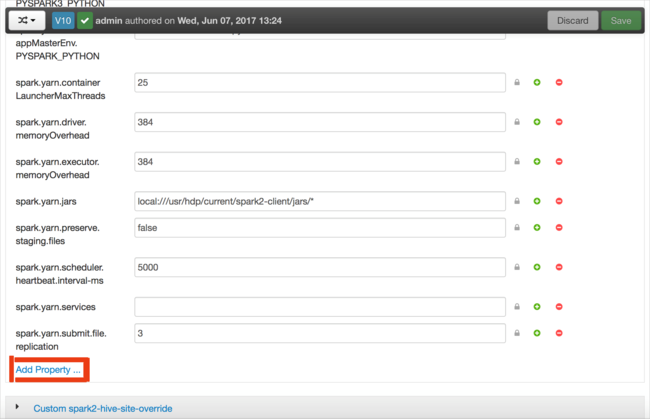
Definujte novou vlastnost. Jednu vlastnost můžete definovat pomocí dialogového okna pro konkrétní nastavení, jako je datový typ. Nebo můžete definovat více vlastností pomocí jedné definice na řádek.
V tomto příkladu je vlastnost spark.driver.memory definována s hodnotou 4g.

Uložte konfiguraci a restartujte službu, jak je popsáno v krocích 6 a 7.
Tyto změny jsou v rámci clusteru, ale při odesílání úlohy Sparku je možné je přepsat.
Návody nakonfigurovat aplikaci Apache Spark pomocí poznámkového bloku Jupyter v clusterech?
V první buňce aplikace Jupyter Notebook za direktivou %%configure zadejte konfigurace Sparku v platném formátu JSON. Podle potřeby změňte skutečné hodnoty:

Jak na clusterech nakonfigurovat aplikaci Apache Spark pomocí Apache Livy?
Odešlete aplikaci Spark do Livy pomocí klienta REST, jako je cURL. Použijte příkaz podobný následujícímu. Podle potřeby změňte skutečné hodnoty:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Jak na clusterech nakonfigurovat aplikaci Apache Spark pomocí příkazu spark-submit?
Spusťte spark-shell pomocí příkazu podobného následujícímu. Podle potřeby změňte skutečnou hodnotu konfigurací:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Extra čtení
Odeslání úlohy Apache Sparku v clusterech HDInsight
Další kroky
Pokud jste problém neviděli nebo nemůžete problém vyřešit, navštivte jeden z následujících kanálů, kde najdete další podporu:
Přehled správy paměti Sparku
Ladění aplikace Spark v clusterech HDInsight
Získejte odpovědi od odborníků na Azure prostřednictvím podpory komunity Azure.
Připojení s @AzureSupport – oficiálním účtem Microsoft Azure pro zlepšení zkušeností zákazníků. Připojení komunity Azure k správným prostředkům: odpovědi, podpora a odborníci.
Pokud potřebujete další pomoc, můžete odeslat žádost o podporu z webu Azure Portal. V řádku nabídek vyberte možnost Podpora nebo otevřete centrum nápovědy a podpory . Podrobnější informace najdete v tématu Vytvoření žádosti o podpora Azure. Součástí předplatného Microsoft Azure je přístup ke správě předplatného a podpora fakturace. Technická podpora se poskytuje prostřednictvím některého z plánů podpory Azure.