Vytvoření prvního experimentu pro datové vědy v nástroji Machine Learning Studio (classic)
PLATÍ PRO: Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Důležité
Podpora studia Machine Learning (Classic) skončí 31. srpna 2024. Doporučujeme do tohoto data přejít na službu Azure Machine Learning.
Od 1. prosince 2021 nebude možné vytvářet nové prostředky studia Machine Learning (Classic). Do 31. srpna 2024 můžete pokračovat v používání stávajících prostředků studia Machine Learning (Classic).
- Podívejte se na informace o přesouvání projektů strojového učení ze sady ML Studio (Classic) do Služby Azure Machine Learning.
- Další informace o službě Azure Machine Learning
Dokumentace ke studiu ML (Classic) se vyřazuje z provozu a v budoucnu se nemusí aktualizovat.
V tomto článku vytvoříte experiment strojového učení v nástroji Machine Learning Studio (classic), který predikuje cenu auta na základě různých proměnných, jako jsou například make a technické specifikace.
Pokud s strojovém učení začínáte, představuje video série Data Science for Beginners skvělý úvod do strojového učení pomocí každodenního jazyka a konceptů.
Tento rychlý start se řídí výchozím pracovním postupem experimentu:
- Vytvoření modelu
- Trénování modelu
- Stanovení skóre a otestování modelu
Získání dat
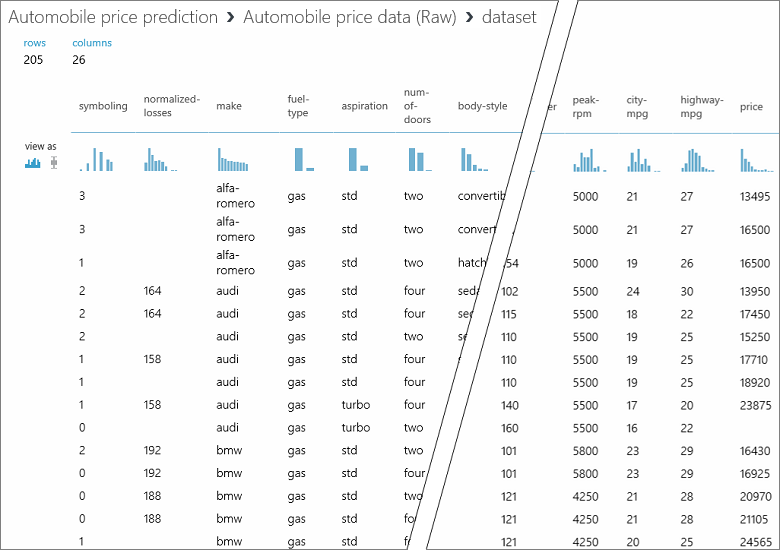
První věc, kterou potřebujete ve strojovém učení, je data. Studio (classic) obsahuje několik ukázkových datových sad, které můžete použít, nebo můžete importovat data z mnoha zdrojů. V tomto příkladu použijeme ukázkovou datovou sadu Automobile price data (Raw), která je součástí vašeho pracovního prostoru. Tato datová sada obsahuje záznamy řady různých automobilů, včetně informací o značce, modelu, technických specifikacích a ceně.
Tip
Pracovní kopii následujícího experimentu najdete v galerii Azure AI. Přejděte do svého prvního experimentu pro datové vědy – predikce cen automobilů a kliknutím na Otevřít v aplikaci Studio stáhněte kopii experimentu do pracovního prostoru Machine Learning Studio (classic).
Tuto datovou sadu dostanete do svého experimentu takto.
Vytvořte nový experiment kliknutím na +NOVÝ v dolní části okna Machine Learning Studia (Classic). Vyberte Experiment>prázdný.
Experimentu se přiřadí výchozí název, který se zobrazí v horní části plátna. Vyberte tento text a přejmenujte jej na něco smysluplného, například Predikce ceny automobilu. Název nemusí být jedinečný.
Nalevo od plátna experimentu je paleta datových sad a modulů. Do pole Hledat v horní části palety zadejte automobile. Vyhledá se datová sada Automobile price data (Raw). Přetáhněte tuto datovou sadu na plátno experimentu.
Pokud chcete zjistit, jak tato data vypadají, klikněte na výstupní port v dolní části datové sady automobilů a pak vyberte Vizualizovat.
Tip
Vstupní a výstupní porty datových sad a modulů jsou reprezentované malými kroužky – vstupní porty v horní části, výstupní porty v dolní části. Pokud chcete vytvořit tok dat prostřednictvím experimentu, připojte výstupní port jednoho modulu ke vstupnímu portu jiného. V libovolném okamžiku můžete kliknout na výstupní port datové sady nebo modulu a prohlédnout si, jak v tomto bodě vypadá tok dat.
V této datové sadě představuje každý řádek automobil a proměnné přidružené k jednotlivým automobilům se zobrazují jako sloupce. Cenu předpovědíme ve sloupci úplně vpravo (sloupec 26 s názvem "price") pomocí proměnných pro konkrétní automobil.
Kliknutím na x v pravém horním rohu zavřete okno vizualizace.
Příprava dat
Před analýzou datové sady bývá zpravidla nutné sadu nějakým způsobem předzpracovat. Možná jste si ve sloupcích různých řádků všimli chybějících hodnot. Tyto chybějící hodnoty se musí vyčistit, aby model mohl data správně analyzovat. Odebereme všechny řádky, u kterých chybí hodnoty. Hodnoty ve sloupci normalized-losses navíc z velké části chybí, proto tento sloupec v modelu zcela vynecháme.
Tip
Vyčištění chybějících hodnot ze vstupních dat je pro většinu modulů nutností.
Nejprve přidáme modul, který úplně odebere sloupec normalizovaných ztrát . Pak přidáme další modul, který odebere všechny řádky s chybějícími daty.
Zadáním sloupců do vyhledávacího pole v horní části palety modulů vyhledejte modul Vybrat sloupce v datové sadě . Potom ho přetáhněte na plátno experimentu. Tento modul umožňuje vybrat, které sloupce dat chceme zahrnout do modelu, nebo je z modelu naopak vyloučit.
Připojte výstupní port datové sady Automobile Price Data (Raw) ke vstupnímu portu výběru sloupců v datové sadě.
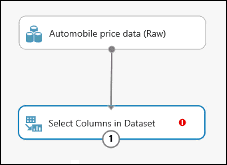
Klikněte na modul Výběr sloupců v datové sadě a v podokně Vlastnosti klikněte na Spustit selektor sloupců.
Vlevo klikněte na S pravidly.
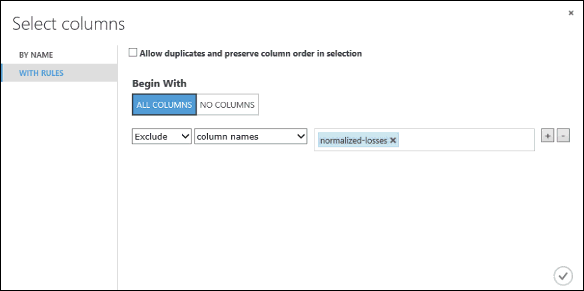
V části Začít s klikněte na Všechny sloupce. Tato pravidla směrují výběr sloupců v datové sadě , aby prošla všechny sloupce (s výjimkou sloupců, které chystáme vyloučit).
V rozevíracích seznamech vyberte Vyloučit a názvy sloupců a klikněte do textového pole. Zobrazí se seznam sloupců. Vyberte sloupec normalized-losses, který se tak přidá do textového pole.
Kliknutím na tlačítko zaškrtnutí (OK) zavřete selektor sloupců (vpravo dole).
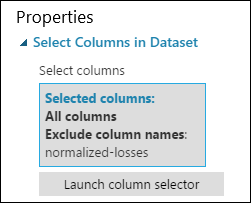
Podokno vlastností modulu Výběr sloupců v datové sadě teď indikuje, že modul bude procházet všechny sloupce datové sady kromě normalized-losses.
Tip
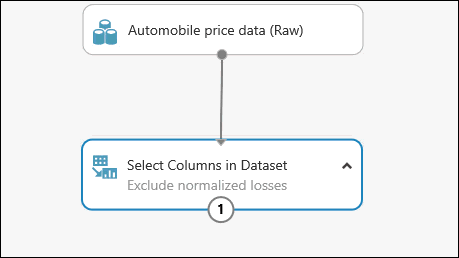
Kliknutím dvakrát na modul a zadáním textu je možné přidat k modulu komentář. To vám může pomoci rychle poznat, jaký je účel modulu v experimentu. V tomto případě klikněte dvakrát na modul Výběr sloupců v datové sadě a zadejte komentář Vyloučit normalized-losses.
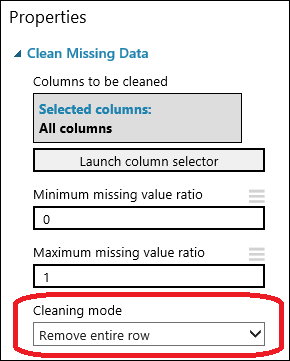
Přetáhněte modul Vyčištění chybějících dat na plátno experimentu a propojte jej s modulem Výběr sloupců v datové sadě. V podokně Vlastnosti vyberte v části Režim čištění možnost Odstranit celý řádek. Tyto možnosti směrují vyčištění chybějících dat k vyčištění dat odebráním řádků s chybějícími hodnotami. Klikněte dvakrát na modul a zadejte komentář Odstranění řádků s chybějícími hodnotami.
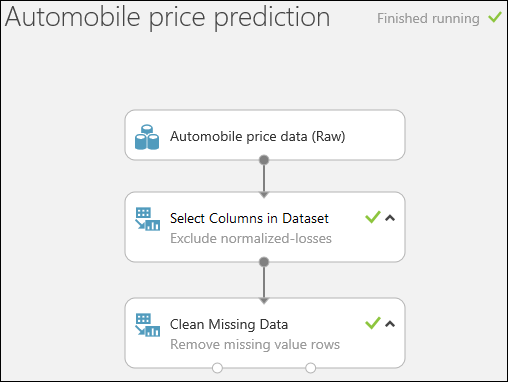
Spusťte experiment kliknutím na SPUSTIT v dolní části stránky.
Až se spuštění experimentu dokončí, u všech modulů se zobrazí zelená značka zaškrtnutí, která označuje, že jejich činnost úspěšně skončila. Všimněte si také stavu Konec běhu v pravém horním rohu.
Tip
Proč jsme experiment teď spustili? Spuštěním experimentu jsme zajistili, aby definice sloupců pro naše data prošly z původní datové sady přes modul Výběr sloupců v datové sadě a přes modul Vyčištění chybějících dat. To znamená, že všechny moduly, které připojíme k modulu Vyčištění chybějících dat, budou také mít tytéž informace.
Teď máme čistá data. Pokud si chcete zobrazit vyčištěnou datovou sadu, klikněte na levý výstupní port modulu Vyčištění chybějících dat a vyberte Vizualizovat. Všimněte si, že již není zobrazen sloupec normalized-losses a že nechybí žádné hodnoty.
Nyní když jsou data vyčištěna, můžete určit, které příznaky použijeme v prediktivním modelu.
Definování funkcí
Ve strojovém učení jsou funkce individuální měřitelné vlastnosti něčeho, co vás zajímá. V naší datové sadě každý řádek představuje jeden automobil a každý sloupec je příznak daného automobilu.
Nalezení správné sady příznaků pro vytvoření prediktivního modelu vyžaduje experimentování a znalost problému, který chcete vyřešit. Některé příznaky jsou pro predikci cíle vhodnější než jiné. Některé funkce mají silnou korelaci s jinými funkcemi a je možné je odebrat. Například příznaky city-mpg a highway-mpg jsou vzájemně těsně propojené, takže stačí jeden z nich odebrat a ponechat jenom ten druhý, aniž by to vytvářenou predikci výrazně ovlivnilo.
Vytvořme model, který používá podmnožinu příznaků naší datové sady. Později můžete vybrat jiné příznaky, spustit experiment znovu a zjistit, jestli nedostanete lepší výsledky. Nejdřív ale vyzkoušíme tyto funkce:
make, body-style, wheel-base, motor-size, horsepower, peak-rpm, highway-mpg, price
Na plátno experimentu přetáhněte další modul Výběr sloupců v datové sadě. Propojte levý výstupní port modulu Vyčištění chybějících dat se vstupem modulu Výběr sloupců v datové sadě.
Poklikejte na modul a zadejte Výběr příznaků pro predikci.
V podokně Vlastnosti klikněte na Spustit selektor sloupců.
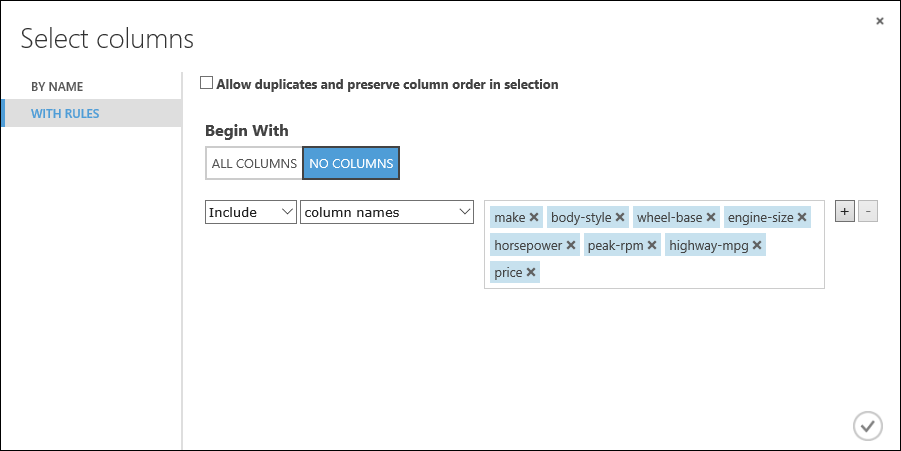
Klikněte na S pravidly.
V části Začít s klikněte na Žádné sloupce. V řádku filtru vyberte Zahrnout a názvy sloupců a vyberte náš seznam názvů sloupců v textovém poli. Tento filtr směruje modul tak, aby neprošel žádnými sloupci (funkcemi), s výjimkou těch, které určíme.
Klikněte na tlačítko zaškrtnutí (OK).
Tento modul vytvoří filtrovanou datovou sadu obsahující pouze funkce, které chceme předat algoritmus učení, který použijeme v dalším kroku. Později se můžete vrátit a zkusit jiný výběr příznaků.
Volba a použití algoritmu
Nyní když jsou data připravena, tvorba prediktivního modelu sestává z trénování a testování. Naše data použijeme pro trénování modelu. Potom model otestujeme a zjistíme, jak přesně dokáže předpovídat ceny.
Klasifikace a regrese jsou dva typy technik strojového učení se supervizí. Klasifikace předpovídá odpověď na základě definované sady kategorií, třeba barvy (červená, modrá nebo zelená). Regrese se používá k předpovědi čísel.
Chceme předpovědět cenu, což je číslo, a tak použijeme regresní algoritmus. V tomto příkladu použijeme lineární regresní model.
Model trénujeme tím, že mu poskytneme sadu dat, která zahrnují cenu. Model projde data a hledá korelaci mezi příznaky automobilu a jeho cenou. Potom model otestujeme. Poskytneme mu sadu příznaků pro automobily, které známe, a uvidíme, do jaké míry se predikce modelu blíží známé ceně.
Naše data můžeme použít jak pro trénování modelu, tak pro jeho otestování. Dají se totiž rozdělit na samostatné sady pro trénování a testování.
Vyberte a přetáhněte na plátno experimentu modul Rozdělení dat a propojte jej s posledním modulem Výběr sloupců v datové sadě.
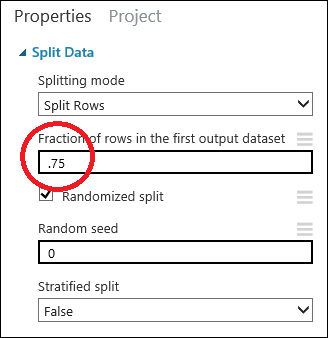
Klikněte na modul Rozdělení dat. Modul se vybere. Vyhledejte Podíl řádků v první výstupní sadě dat (v podokně Vlastnosti napravo od plátna) a nastavte ho na 0,75. Takto použijeme 75 procent dat pro trénování modelu a 25 procent si ponecháme na testování.
Tip
Změnou parametru Náhodná počáteční hodnota je možné pro trénování a testování vytvořit různé náhodné vzorky. Tento parametr řídí nastavování počáteční hodnoty pseudonáhodného generátoru čísel.
Spusťte experiment. Při spuštění experimentu moduly Výběr sloupců v datové sadě a Rozdělení dat předají definice sloupců do modulů, které přidáme jako další.
Nyní vyberte algoritmus učení. Na paletě modulů nalevo od plátna rozbalte kategorii Strojové učení a pak Inicializovat model. Tímto se zobrazí několik kategorií modulů, které je možné použít k inicializaci algoritmů strojového učení. Pro tento experiment vyberte modul Lineární regrese v kategorii Regrese a přetáhněte ho na plátno experimentu. (Tento modul můžete najít i tak, že do pole Hledat palety zadáte lineární regrese.)
Najděte modul Trénování modelu a přetáhněte ho na plátno experimentu. Propojte výstup modulu Lineární regrese s levým vstupem modulu Trénování modelu a potom propojte výstup trénovacích dat (levý port) modulu Rozdělení dat s pravým vstupem modulu Trénování modelu.
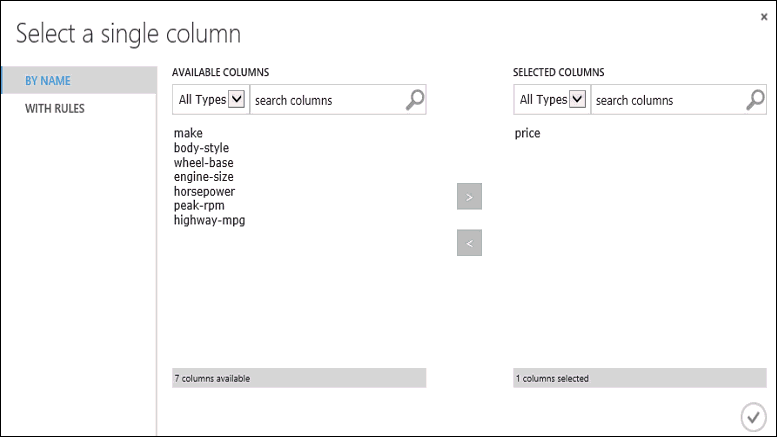
Klikněte na modul Trénování modelu, v podokně Vlastnosti klikněte na Spustit selektor sloupců a vyberte sloupec price. Cena je hodnota, kterou náš model bude predikovat.
V selektoru sloupců vyberete sloupec price – přesunete ho ze seznamu Dostupné sloupce do seznamu Vybrané sloupce.
Spusťte experiment.
Výsledkem je natrénovaný model, který je možné použít ke stanovení skóre pro nová data automobilů a k následné predikci cen.
Predikce cen nových automobilů
Nyní když jsme natrénovali model pomocí 75 procent dat, můžeme model použít ke stanovení skóre u zbylých 25 procent dat a zjistit, jak dobře model funguje.
Najděte modul Určení skóre modelu a přetáhněte ho na plátno experimentu. Propojte výstup modulu Trénování modelu s levým vstupním portem modulu Určení skóre modelu. Propojte výstup testovacích dat (pravý port) modulu Rozdělení dat s pravým vstupním portem modulu Určení skóre modelu.
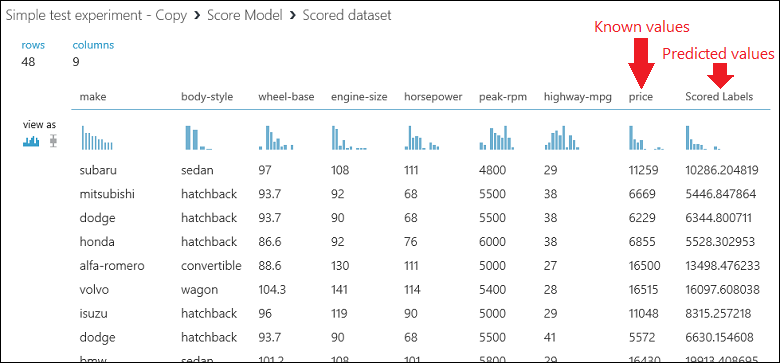
Spusťte experiment a zobrazte výstup z modulu Skóre modelu kliknutím na výstupní port modelu skóre a vyberte Vizualizovat. Na výstupu se zobrazí predikované hodnoty ceny a známé hodnoty v testovacích datech.
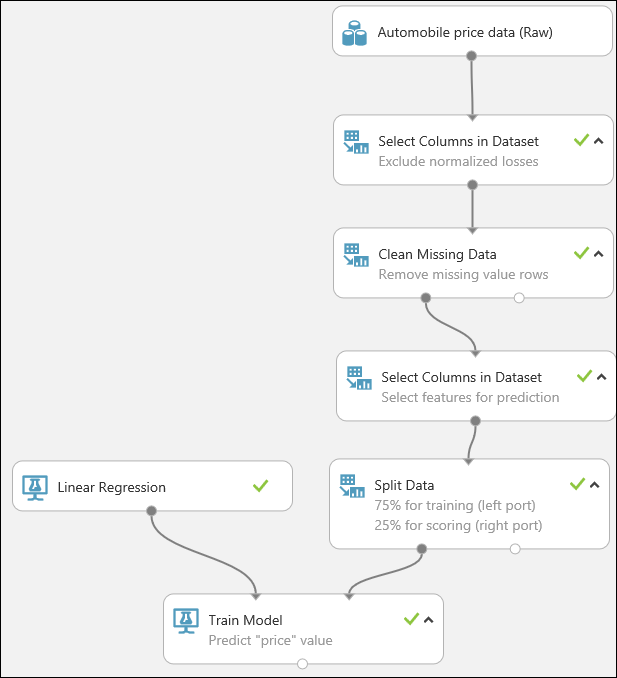
Nakonec otestujeme kvalitu výsledků. Najděte modul Vyhodnocení modelu, přetáhněte ho na plátno experimentu a propojte výstup modulu Určení skóre modelu s levým vstupem modulu Vyhodnocení modelu. Konečný experiment by měl vypadat přibližně takto:
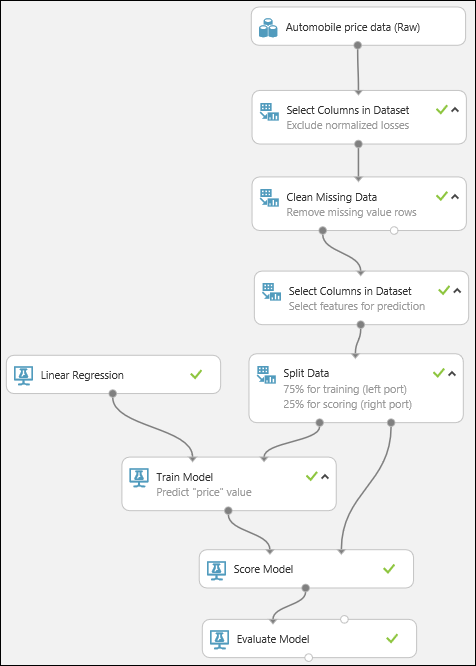
Spusťte experiment.
Zobrazte výstup modulu Vyhodnocení modelu tak, že kliknete na výstupní port a vyberete Vizualizovat.
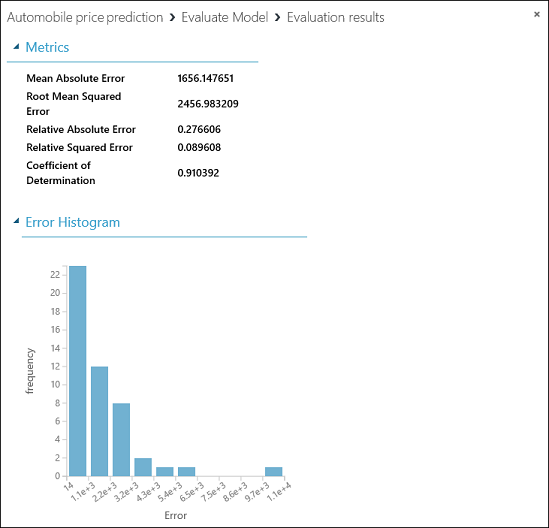
Pro náš model se zobrazí následující statistiky:
- Střední absolutní chyba (MAE): Průměr absolutních chyb (chyba je rozdíl mezi předpovězenou a skutečnou hodnotu)
- Odmocnina střední kvadratické chyby (RMSE): Druhá odmocnina průměru kvadratických chyb předpovědí na základě testovací datové sady
- Relativní absolutní chyba: Průměr absolutních chyb relativních k absolutnímu rozdílu mezi skutečnými hodnotami a průměrem všech skutečných hodnot
- Relativní kvadratická chyba: Průměr kvadratických chyb relativních ke kvadratickému rozdílu mezi skutečnými hodnotami a průměrem všech skutečných hodnot
- Koeficient spolehlivosti: Znám také jako hodnota spolehlivosti R, tedy statistická metrika označující kvalitu přizpůsobení modelu datům
Pro každou statistiku chyb platí, že menší hodnota je lepší. Menší hodnota označuje, že předpověď přesněji odpovídá skutečným hodnotám. V případě koeficientu spolehlivosti platí, že čím bližší je jeho hodnota hodnotě jedna (1,0), tím lepší jsou předpovědi.
Vyčištění prostředků
Pokud už nepotřebujete prostředky, které jste vytvořili pomocí tohoto článku, odstraňte je, abyste se vyhnuli poplatkům. Přečtěte si, jak v článku exportovat a odstranit uživatelská data v produktu.
Další kroky
V tomto rychlém startu jste vytvořili jednoduchý experiment pomocí ukázkové datové sady. Pokud chcete prozkoumat proces vytváření a nasazování modelu podrobněji, pokračujte kurzem prediktivního řešení.