Kurz 1: Predikce úvěrového rizika – Machine Learning Studio (classic)
PLATÍ PRO: Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Důležité
Podpora studia Machine Learning (Classic) skončí 31. srpna 2024. Doporučujeme do tohoto data přejít na službu Azure Machine Learning.
Od 1. prosince 2021 nebude možné vytvářet nové prostředky studia Machine Learning (Classic). Do 31. srpna 2024 můžete pokračovat v používání stávajících prostředků studia Machine Learning (Classic).
- Podívejte se na informace o přesouvání projektů strojového učení ze sady ML Studio (Classic) do Služby Azure Machine Learning.
- Další informace o službě Azure Machine Learning
Dokumentace ke studiu ML (Classic) se vyřazuje z provozu a v budoucnu se nemusí aktualizovat.
V tomto kurzu se podíváme na proces vývoje řešení prediktivní analýzy. V nástroji Machine Learning Studio (classic) vyvíjíte jednoduchý model. Model pak nasadíte jako webovou službu Machine Learning. Tento nasazený model může vytvářet předpovědi pomocí nových dat. Tento kurz je součástí třídílné série kurzů.
Předpokládejme, že potřebujete předpovědět úvěrové riziko u jednotlivých zákazníků na základě údajů, které uvedli v žádosti o úvěr.
Hodnocení úvěrového rizika je složitý problém, ale tento kurz ho trochu zjednoduší. Použijete ho jako příklad, jak můžete vytvořit řešení prediktivní analýzy pomocí nástroje Machine Learning Studio (classic). Pro toto řešení použijete aMachine Learning Studio (classic) a webovou službu Machine Learning.
V tomto třídílném kurzu začnete s veřejně dostupnými údaji o úvěrovém riziku. Potom vyvíjíte a trénujete prediktivní model. Nakonec model nasadíte jako webovou službu.
V této části kurzu:
- Vytvoření pracovního prostoru Machine Learning Studio (Classic)
- Nahrání existujících dat
- Vytvoření experimentu
Tento experiment pak můžete použít k trénování modelů v části 2 a jejich nasazení v části 3.
Požadavky
V tomto kurzu se předpokládá, že jste použili Machine Learning Studio (klasické) alespoň jednou předtím a že máte představu o konceptech strojového učení. Bere ale v úvahu, že nejste odborníkem ani na jedno.
Pokud jste nástroj Machine Learning Studio (classic) ještě nikdy nepoužili, možná budete chtít začít s rychlým startem a vytvořit první experiment pro datové vědy v nástroji Machine Learning Studio (classic). Rychlý start vás poprvé provede aplikací Machine Learning Studio (Classic). Ukáže vám základy toho, jak pomocí myši přetáhnout moduly do experimentu, vzájemně je propojit, spustit experiment a prohlédnout si výsledky.
Tip
Pracovní kopii experimentu, který vyvíjíte v tomto kurzu, najdete v galerii Azure AI. Přejděte na kurz – Predikce úvěrového rizika a kliknutím na Otevřít v aplikaci Studio stáhněte kopii experimentu do pracovního prostoru Machine Learning Studio (Classic).
Vytvoření pracovního prostoru Machine Learning Studio (Classic)
Pokud chcete použít Machine Learning Studio (classic), musíte mít pracovní prostor Machine Learning Studia (Classic). Tento pracovní prostor obsahuje nástroje potřebné k vytváření, správě a publikování experimentů.
Pokud chcete vytvořit pracovní prostor, přečtěte si téma Vytvoření a sdílení pracovního prostoru Machine Learning Studia (classic).
Po vytvoření pracovního prostoru otevřete Machine Learning Studio (Classic).https://studio.azureml.net/Home Pokud máte více pracovních prostorů, můžete ho vybrat na panelu nástrojů v pravém horním rohu okna.
Tip
Pokud jste vlastníkem pracovního prostoru, můžete experimenty, na kterých pracujete, sdílet tak, že pozvete ostatní do pracovního prostoru. Můžete to udělat v nástroji Machine Learning Studio (classic) na stránce NASTAVENÍ . Pro každého uživatele stačí účet Microsoft nebo účet organizace.
Na stránce NASTAVENÍ klikněte na UŽIVATELÉ a potom v dolní části okna klikněte na POZVAT DALŠÍ UŽIVATELE .
Nahrání existujících dat
K vývoji prediktivního modelu pro úvěrové riziko potřebujete data, která můžete použít k trénování a otestování modelu. Pro účely tohoto kurzu použijete datovou sadu UCI Statlog (german credit data) z úložiště UC Irvine Machine Learning. Najdete ho tady:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Použijete soubor s názvem german.data. Stáhněte si tento soubor na místní pevný disk.
Datová sada german.data obsahuje řádky 20 proměnných pro 1000 předchozích uchazečů o kredit. Tyto 20 proměnných představují sadu funkcí datové sady ( vektor funkce), která poskytuje charakteristiky pro každého žadatele o kredit. Další sloupec v každém řádku představuje vypočítané úvěrové riziko žadatele, přičemž 700 uchazečů je označeno jako nízké úvěrové riziko a 300 jako vysoké riziko.
Web UCI poskytuje popis atributů vektoru funkce pro tato data. Tato data zahrnují finanční informace, historii úvěru, stav zaměstnání a osobní údaje. Pro každého žadatele byla udělena binární hodnocení označující, zda se jedná o nízké nebo vysoké úvěrové riziko.
Tato data použijete k trénování prediktivního analytického modelu. Až to budete mít, model by měl být schopný přijmout vektor funkce pro nového jednotlivce a předpovědět, jestli se jedná o nízké nebo vysoké úvěrové riziko.
Tady je zajímavý twist.
Popis datové sady na webu UCI uvádí, jaké náklady stojí, pokud nesprávně klasifikujete úvěrové riziko osoby. Pokud model předpovídá vysoké úvěrové riziko pro někoho, kdo je ve skutečnosti nízkým úvěrovém rizikem, model provedl chybné klasifikaci.
Ale obrácená chybná klasifikace je pro finanční instituci pětkrát nákladnější: pokud model předpovídá nízké úvěrové riziko pro někoho, kdo je ve skutečnosti vysokým úvěrovém rizikem.
Proto chcete model vytrénovat tak, aby náklady na tento druhý typ chybné klasifikace byly pětkrát vyšší než nesprávně klasifikovat jiným způsobem.
Jedním z jednoduchých způsobů, jak to udělat při trénování modelu v experimentu, je duplikování (pětkrát) těchto položek, které představují někoho s vysokým úvěrovém rizikem.
Pokud pak model nesprávně klasifikuje někoho jako nízké úvěrové riziko, pokud je ve skutečnosti vysokým rizikem, model provede stejnou chybnou klasifikaci pětkrát jednou pro každý duplikát. Tím se zvýší náklady na tuto chybu ve výsledcích trénování.
Převod formátu datové sady
Původní datová sada používá prázdný formát oddělený. Machine Learning Studio (classic) funguje lépe se souborem s hodnotami oddělenými čárkami (CSV), takže datovou sadu převedete nahrazením mezer čárkami.
Tato data lze převést mnoha způsoby. Jedním ze způsobů je použití následujícího příkazu Windows PowerShell:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Dalším způsobem je použití příkazu Unix sed:
sed 's/ /,/g' german.data > german.csv
V obou případech jste vytvořili verzi dat oddělenou čárkou v souboru s názvemgerman.csv , kterou můžete použít v experimentu.
Nahrání datové sady do nástroje Machine Learning Studio (classic)
Jakmile se data převedou do formátu CSV, musíte je nahrát do nástroje Machine Learning Studio (classic).
Otevřete domovskou stránkuhttps://studio.azureml.net nástroje Machine Learning Studio (Classic).
Klikněte na nabídku
 V levém horním rohu okna klikněte na Azure Machine Learning, vyberte Studio a přihlaste se.
V levém horním rohu okna klikněte na Azure Machine Learning, vyberte Studio a přihlaste se.Klikněte na +NOVÝ v dolní části okna.
Vyberte DATOVOU SADU.
Vyberte Z MÍSTNÍHO SOUBORU.
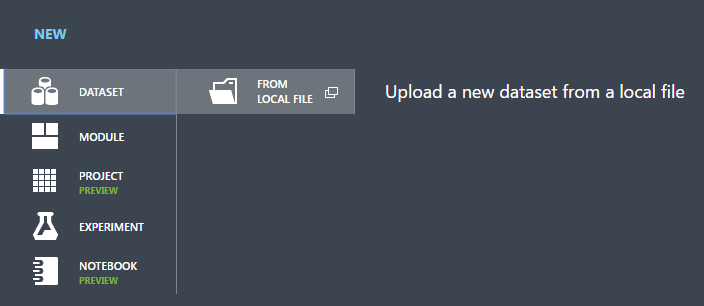
V dialogovém okně Nahrát novou datovou sadu klikněte na Procházet a vyhledejte german.csv soubor, který jste vytvořili.
Zadejte název datové sady. Pro účely tohoto kurzu ji pojmenujte "UCI German Credit Card Data".
U datového typu vyberte Obecný soubor CSV bez záhlaví (.nh.csv).
Pokud chcete, přidejte popis.
Klikněte na značku zaškrtnutí OK .

Tím se data nahrají do modulu datové sady, který můžete použít v experimentu.
Datové sady, které jste nahráli do studia (classic), můžete spravovat kliknutím na kartu DATASETS (DATASETS ) vlevo od okna Studia (classic).
Další informace o importu dalších typů dat do experimentu najdete v tématu Import trénovacích dat do nástroje Machine Learning Studio (classic).
Vytvoření experimentu
Dalším krokem v tomto kurzu je vytvoření experimentu v nástroji Machine Learning Studio (classic), který používá datovou sadu, kterou jste nahráli.
V aplikaci Studio (classic) klikněte v dolní části okna na +NOVÝ .
Vyberte EXPERIMENT a pak vyberte Prázdný experiment.
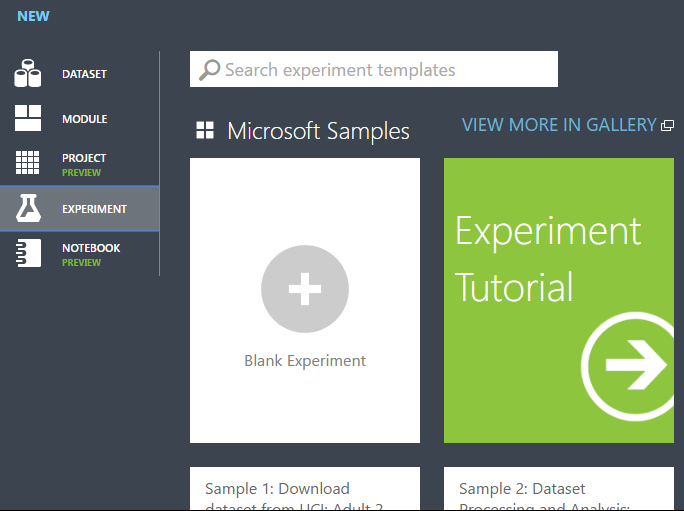
Vyberte výchozí název experimentu v horní části plátna a přejmenujte ho na něco smysluplného.

Tip
Je vhodné vyplnit souhrn a popis experimentu v podokně Vlastnosti . Díky těmto vlastnostem můžete experiment zdokumentovat, aby každý, kdo se na něj později podívá, porozuměl vašim cílům a metodologii.

Na paletě modulů vlevo od plátna experimentu rozbalte uložené datové sady.
Najděte datovou sadu, kterou jste vytvořili v části Moje datové sady , a přetáhněte ji na plátno. Datovou sadu můžete najít také zadáním názvu do vyhledávacího pole nad paletou.
Příprava dat
Můžete zobrazit prvních 100 řádků dat a některé statistické informace pro celou datovou sadu: Klikněte na výstupní port datové sady (malý kruh dole) a vyberte Vizualizovat.
Vzhledem k tomu, že datový soubor nepřišel s záhlavími sloupců, poskytuje Studio (klasické) obecné nadpisy (Col1, Col2 atd.). Dobré nadpisy nejsou pro vytvoření modelu nezbytné, ale usnadňují práci s daty v experimentu. Když tento model nakonec publikujete ve webové službě, nadpisy pomáhají identifikovat sloupce uživateli služby.
Záhlaví sloupců můžete přidat pomocí modulu Upravit metadata .
Pomocí modulu Upravit metadata můžete změnit metadata přidružená k datové sadě. V tomto případě ho použijete k zadání popisnějších názvů záhlaví sloupců.
Chcete-li použít upravit metadata, nejprve určíte, které sloupce se mají upravit (v tomto případě všechny.) Dále zadáte akci, která se má provést u těchto sloupců (v tomto případě se změní záhlaví sloupců.)
Na paletě modulů zadejte do vyhledávacího pole "metadata". V seznamu modulů se zobrazí metadata pro úpravy .
Klikněte na plátno a přetáhněte modul Upravit metadata a přesuňte ho pod datovou sadu, kterou jste přidali dříve.
Připojte datovou sadu k upravit metadata: Klikněte na výstupní port datové sady (malý kruh v dolní části datové sady), přetáhněte na vstupní port Upravit metadata (malý kruh v horní části modulu) a uvolněte tlačítko myši. Datová sada a modul zůstanou připojené i v případě, že se pohybujete na plátně.
Experiment by teď měl vypadat nějak takto:
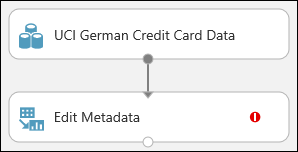
Červená vykřičník označuje, že jste ještě nenastavili vlastnosti tohoto modulu. Uděláte to za chvíli.
Tip
Kliknutím dvakrát na modul a zadáním textu je možné přidat k modulu komentář. To vám může pomoci rychle poznat, jaký je účel modulu v experimentu. V tomto případě poklikejte na modul Upravit metadata a zadejte komentář "Přidat záhlaví sloupců". Kliknutím na libovolné místo na plátně zavřete textové pole. Pokud chcete komentář zobrazit, klikněte na šipku dolů v modulu.

Vyberte Upravit metadata a v podokně Vlastnosti napravo od plátna klikněte na tlačítko Spustit selektor sloupců.
V dialogovém okně Vybrat sloupce vyberte všechny řádky v dostupných sloupcích a kliknutím > je přesuňte do vybraných sloupců. Dialogové okno by mělo vypadat takto:
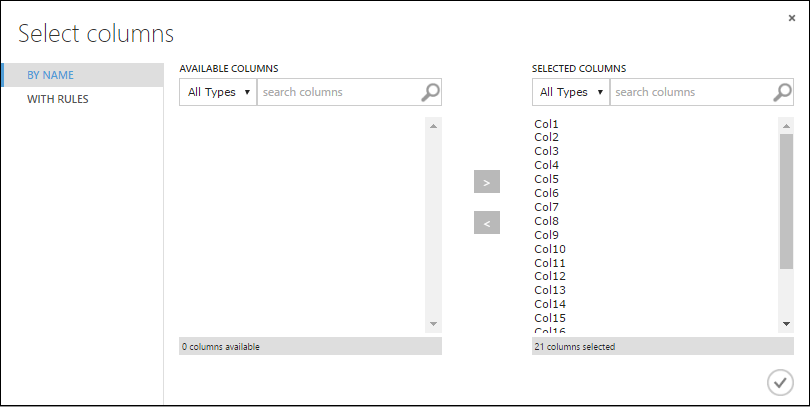
Klikněte na značku zaškrtnutí OK .
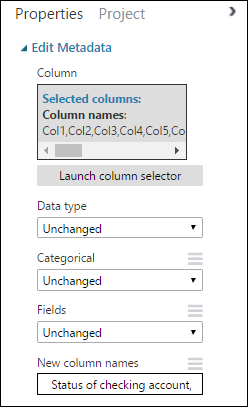
Zpátky v podokně Vlastnosti vyhledejte parametr New column names (Nové názvy sloupců ). V tomto poli zadejte seznam názvů pro 21 sloupců v datové sadě oddělené čárkami a v pořadí sloupců. Názvy sloupců můžete získat z dokumentace k datové sadě na webu UCI nebo můžete zkopírovat a vložit následující seznam:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskPodokno Vlastnosti vypadá takto:
Tip
Pokud chcete ověřit záhlaví sloupců, spusťte experiment (klikněte na SPUSTIT pod plátnem experimentu). Po dokončení spuštění (u možnosti Upravit metadata se zobrazí zelená značka zaškrtnutí), klikněte na výstupní port modulu Upravit metadata a vyberte Vizualizovat. Výstup libovolného modulu můžete zobrazit stejným způsobem, jak zobrazit průběh dat prostřednictvím experimentu.
Vytváření trénovacích a testovacích datových sad
K trénování modelu a k jeho otestování potřebujete nějaká data. V dalším kroku experimentu tedy datovou sadu rozdělíte do dvou samostatných datových sad: jednu pro trénování našeho modelu a jednu pro testování.
K tomu použijete modul Split Data .
Najděte modul Split Data , přetáhněte ho na plátno a připojte ho k modulu Upravit metadata .
Ve výchozím nastavení je poměr rozdělení 0,5 a parametr randomizovaného rozdělení je nastavený. To znamená, že náhodná polovina dat je výstupem jednoho portu modulu Split Data a polovina přes druhý. Tyto parametry můžete upravit, stejně jako náhodný počáteční parametr, abyste změnili rozdělení mezi trénovacími a testovacími daty. V tomto příkladu je necháte tak, jak je.
Tip
Vlastnost Zlomek řádků v první výstupní datové sadě určuje, kolik dat je výstupu přes levý výstupní port. Pokud například nastavíte poměr na 0,7, pak 70 % dat je výstupem přes levý port a 30 % přes pravý port.
Poklikejte na modul Rozdělit data a zadejte komentář trénovací/testovací data rozdělená 50 %.
Můžete ale použít výstupy modulu Split Data , ale pojďme se rozhodnout použít levý výstup jako trénovací data a správný výstup jako testovací data.
Jak jsme zmínili v předchozím kroku, náklady na nesprávnou klasifikaci vysokého úvěrového rizika jako nízké je pětkrát vyšší než náklady na chybné klasifikace nízkého úvěrového rizika jako vysoké. Pro účely tohoto účtu vygenerujete novou datovou sadu, která odráží tuto nákladovou funkci. V nové datové sadě se každý příklad s vysokým rizikem replikuje pětkrát, zatímco každý příklad nízkého rizika se nereplikuje.
Tuto replikaci můžete provést pomocí kódu R:
Najděte a přetáhněte modul Execute R Script na plátno experimentu.
Připojte levý výstupní port modulu Split Data k prvnímu vstupnímu portu ("Dataset1") modulu Execute R Script .
Poklikejte na modul Spustit skript R a zadejte komentář Nastavit úpravu nákladů.
V podokně Vlastnosti odstraňte výchozí text v parametru skriptu jazyka R a zadejte tento skript:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")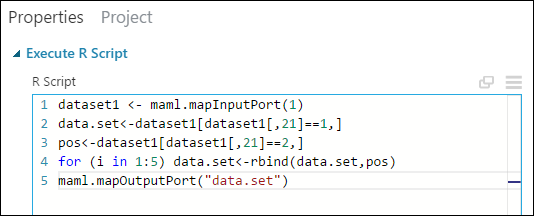
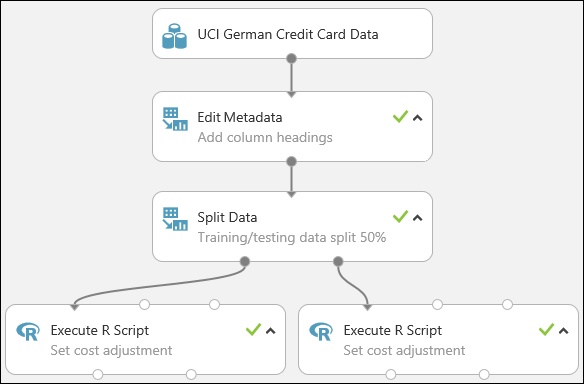
Pro každý výstup modulu Split Data je potřeba provést stejnou operaci replikace, aby trénovací a testovací data měla stejnou úpravu nákladů. Nejjednodušším způsobem, jak to udělat, je duplikováním modulu Execute R Script , který jste právě vytvořili a připojili k dalšímu výstupnímu portu modulu Split Data .
Klikněte pravým tlačítkem na modul Spustit skript jazyka R a vyberte Kopírovat.
Klikněte pravým tlačítkem na plátno experimentu a vyberte Vložit.
Přetáhněte nový modul na pozici a pak připojte správný výstupní port modulu Split Data k prvnímu vstupnímu portu tohoto nového modulu Execute R Script .
V dolní části plátna klikněte na Spustit.
Tip
Kopie modulu Execute R Script obsahuje stejný skript jako původní modul. Když zkopírujete a vložíte modul na plátno, kopie zachová všechny vlastnosti originálu.
Náš experiment teď vypadá nějak takto:
Další informace o používání skriptů jazyka R v experimentech najdete v tématu Rozšíření experimentu pomocí jazyka R.
Vyčištění prostředků
Pokud už nepotřebujete prostředky, které jste vytvořili pomocí tohoto článku, odstraňte je, abyste se vyhnuli poplatkům. Přečtěte si, jak v článku exportovat a odstranit uživatelská data v produktu.
Další kroky
V tomto kurzu jste dokončili tyto kroky:
- Vytvoření pracovního prostoru nástroje Machine Learning Studio (Classic)
- Nahrání existujících dat do pracovního prostoru
- Vytvoření experimentu
Teď jste připraveni trénovat a vyhodnocovat modely pro tato data.