Kurz: Trénování modelu v Pythonu pomocí automatizovaného strojového učení
Azure Machine Učení je cloudové prostředí, které umožňuje trénovat, nasazovat, automatizovat, spravovat a sledovat modely strojového učení.
V tomto kurzu použijete automatizované strojové učení ve službě Azure Machine Učení k vytvoření regresního modelu, který předpovídá ceny jízdy taxíkem. Tento proces dosáhne nejlepšího modelu tím, že přijme trénovací data a nastavení konfigurace a automaticky iteruje kombinacemi různých metod, modelů a nastavení hyperparametrů.
V tomto kurzu se naučíte:
- Stáhněte si data pomocí Apache Sparku a Azure Open Datasets.
- Transformujte a vyčistěte data pomocí datových rámců Apache Sparku.
- Trénování regresního modelu v automatizovaném strojovém učení
- Výpočet přesnosti modelu
Než začnete
- Vytvořte bezserverový fond Apache Sparku pomocí rychlého startu Vytvoření bezserverového fondu Apache Sparku.
- Pokud nemáte existující pracovní prostor azure Učení, dokončete kurz nastavení pracovního prostoru Azure Machine Učení.
Upozorňující
- Od 29. září 2023 ukončí Azure Synapse oficiální podporu pro moduly Runtime Sparku 2.4. Po 29. září 2023 nebudeme řešit žádné lístky podpory související se Sparkem 2.4. Pro chyby nebo opravy zabezpečení pro Spark 2.4 nebude zaveden žádný kanál verze. Využití Sparku 2.4 po datu ukončení podpory se provádí na vlastním riziku. Důrazně nedoporučujeme jeho trvalé používání kvůli potenciálním obavám o zabezpečení a funkčnost.
- V rámci procesu vyřazení Apache Sparku 2.4 bychom vás chtěli upozornit, že AutoML ve službě Azure Synapse Analytics bude také zastaralé. To zahrnuje rozhraní s nízkým kódem i rozhraní API používaná k vytváření zkušebních verzí AutoML prostřednictvím kódu.
- Mějte na paměti, že funkce AutoML byla výhradně dostupná prostřednictvím modulu runtime Spark 2.4.
- Zákazníkům, kteří chtějí dál využívat funkce AutoML, doporučujeme ukládat data do účtu Azure Data Lake Storage Gen2 (ADLSg2). Odtud můžete bez problémů přistupovat k prostředí AutoML prostřednictvím služby Azure Machine Učení (AzureML). Další informace týkající se tohoto alternativního řešení najdete tady.
Vysvětlení regresních modelů
Regresní modely predikují číselné výstupní hodnoty na základě nezávislých prediktorů. Cílem regrese je pomoct vytvořit vztah mezi těmito nezávislými proměnnými prediktoru odhadem toho, jak jedna proměnná ovlivňuje ostatní.
Příklad založený na datech taxislužby v New Yorku
V tomto příkladu pomocí Sparku provedete analýzu dat o tipech pro výlet taxi z New Yorku (NYC). Data jsou k dispozici prostřednictvím Azure Open Datasets. Tato podmnožina datové sady obsahuje informace o žlutých cestách taxi, včetně informací o jednotlivých cestách, počátečním a koncovém čase a umístění a nákladech.
Důležité
Za vyžádání těchto dat z umístění úložiště můžou být účtovány další poplatky. V následujících krocích vytvoříte model pro predikci cen jízdného taxislužby NYC.
Stažení a příprava dat
Postupujte následovně:
Vytvořte poznámkový blok pomocí jádra PySpark. Pokyny najdete v tématu Vytvoření poznámkového bloku.
Poznámka:
Kvůli jádru PySpark nemusíte explicitně vytvářet žádné kontexty. Kontext Sparku se automaticky vytvoří za vás při spuštění první buňky kódu.
Vzhledem k tomu, že nezpracovaná data jsou ve formátu Parquet, můžete použít kontext Sparku k načtení souboru přímo do paměti jako datového rámce. Vytvořte datový rámec Sparku načtením dat prostřednictvím rozhraní API Open Datasets. V této části použijete vlastnosti datového rámce
schema on readSparku k odvození datových typů a schématu.blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" blob_sas_token = r"" # Allow Spark to read from the blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),blob_sas_token) # Spark read parquet; note that it won't load any data yet df = spark.read.parquet(wasbs_path)V závislosti na velikosti fondu Sparku můžou být nezpracovaná data příliš velká nebo může trvat příliš dlouho, než se bude pracovat. Pomocí filtrů
end_datemůžete tato data filtrovat na něco menšího, třeba na měsíc datstart_date. Po filtrování datového rámce spustítedescribe()funkci také na novém datovém rámci, abyste viděli souhrnné statistiky pro každé pole.Na základě souhrnných statistik můžete vidět, že v datech jsou některé nesrovnalosti. Statistika například ukazuje, že minimální vzdálenost jízdy je menší než 0. Tyto nepravidelné datové body musíte vyfiltrovat.
# Create an ingestion filter start_date = '2015-01-01 00:00:00' end_date = '2015-12-31 00:00:00' filtered_df = df.filter('tpepPickupDateTime > "' + start_date + '" and tpepPickupDateTime< "' + end_date + '"') filtered_df.describe().show()Vygenerujte z datové sady funkce výběrem sady sloupců a vytvořením různých časových funkcí z pole vyzvednutí
datetime. Vyfiltrujte odlehlé hodnoty, které byly identifikovány v předchozím kroku, a odeberte posledních několik sloupců, protože pro trénování nejsou potřeba.from datetime import datetime from pyspark.sql.functions import * # To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) taxi_df = sampled_taxi_df.select('vendorID', 'passengerCount', 'tripDistance', 'startLon', 'startLat', 'endLon' \ , 'endLat', 'paymentType', 'fareAmount', 'tipAmount'\ , column('puMonth').alias('month_num') \ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , date_format('tpepPickupDateTime', 'EEEE').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month') ,(unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('trip_time'))\ .filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\ & (sampled_taxi_df.tipAmount >= 0)\ & (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\ & (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\ & (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 200)\ & (sampled_taxi_df.rateCodeId <= 5)\ & (sampled_taxi_df.paymentType.isin({"1", "2"}))) taxi_df.show(10)Jak vidíte, vytvoří se nový datový rámec s dalšími sloupci pro den v měsíci, hodinu vyzvednutí, pracovní den a celkovou dobu jízdy.

Generování testovacích a ověřovacích datových sad
Jakmile budete mít konečnou datovou sadu, můžete data rozdělit do trénovacích a testovacích sad pomocí funkce ve Sparku random_ split . Pomocí zadaných váhy tato funkce náhodně rozdělí data do trénovací datové sady pro trénování modelu a ověřovací datovou sadu pro testování.
# Random split dataset using Spark; convert Spark to pandas
training_data, validation_data = taxi_df.randomSplit([0.8,0.2], 223)
Tento krok zajistí, že se datové body k otestování hotového modelu nepoužívaly k trénování modelu.
Připojení do pracovního prostoru Azure Machine Učení
V azure Machine Učení je pracovní prostor třídou, která přijímá informace o vašem předplatném a prostředcích Azure. Vytvoří také cloudový prostředek pro monitorování a sledování spuštění modelu. V tomto kroku vytvoříte objekt pracovního prostoru z existujícího pracovního prostoru Azure Machine Učení.
from azureml.core import Workspace
# Enter your subscription id, resource group, and workspace name.
subscription_id = "<enter your subscription ID>" #you should be owner or contributor
resource_group = "<enter your resource group>" #you should be owner or contributor
workspace_name = "<enter your workspace name>" #your workspace name
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
Převod datového rámce na datovou sadu azure machine Učení
Pokud chcete odeslat vzdálený experiment, převeďte datovou sadu na instanci azure machine UčeníTabularDatset. TabularDataset představuje data v tabulkovém formátu parsováním zadaných souborů.
Následující kód získá existující pracovní prostor a výchozí úložiště dat azure machine Učení. Potom předá úložiště dat a umístění souborů do parametru cesty, aby se vytvořila nová TabularDataset instance.
import pandas
from azureml.core import Dataset
# Get the Azure Machine Learning default datastore
datastore = ws.get_default_datastore()
training_pd = training_data.toPandas().to_csv('training_pd.csv', index=False)
# Convert into an Azure Machine Learning tabular dataset
datastore.upload_files(files = ['training_pd.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset_training = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/training_pd.csv')])

Odeslání automatizovaného experimentu
Následující části vás provedou procesem odeslání experimentu automatizovaného strojového učení.
Definování nastavení trénování
Pokud chcete experiment odeslat, musíte definovat parametr experimentu a nastavení modelu pro trénování. Úplný seznam nastavení najdete v tématu Konfigurace experimentů automatizovaného strojového učení v Pythonu.
import logging automl_settings = { "iteration_timeout_minutes": 10, "experiment_timeout_minutes": 30, "enable_early_stopping": True, "primary_metric": 'r2_score', "featurization": 'auto', "verbosity": logging.INFO, "n_cross_validations": 2}Předejte definovaná nastavení trénování jako
kwargsparametr objektuAutoMLConfig. Protože používáte Spark, musíte také předat kontext Sparku, který je automaticky přístupný proměnnousc. Kromě toho zadáte trénovací data a typ modelu, což je v tomto případě regrese.from azureml.train.automl import AutoMLConfig automl_config = AutoMLConfig(task='regression', debug_log='automated_ml_errors.log', training_data = dataset_training, spark_context = sc, model_explainability = False, label_column_name ="fareAmount",**automl_settings)
Poznámka:
Kroky předběžného zpracování automatizovaného strojového učení se stanou součástí základního modelu. Mezi tyto kroky patří normalizace funkcí, zpracování chybějících dat a převod textu na číselnou hodnotu. Při použití modelu pro předpovědi se na vstupní data automaticky použijí stejné kroky předběžného zpracování použité během trénování.
Trénování modelu automatické regrese
Dále vytvoříte objekt experimentu v pracovním prostoru Azure Machine Učení. Experiment funguje jako kontejner pro jednotlivá spuštění.
from azureml.core.experiment import Experiment
# Start an experiment in Azure Machine Learning
experiment = Experiment(ws, "aml-synapse-regression")
tags = {"Synapse": "regression"}
local_run = experiment.submit(automl_config, show_output=True, tags = tags)
# Use the get_details function to retrieve the detailed output for the run.
run_details = local_run.get_details()
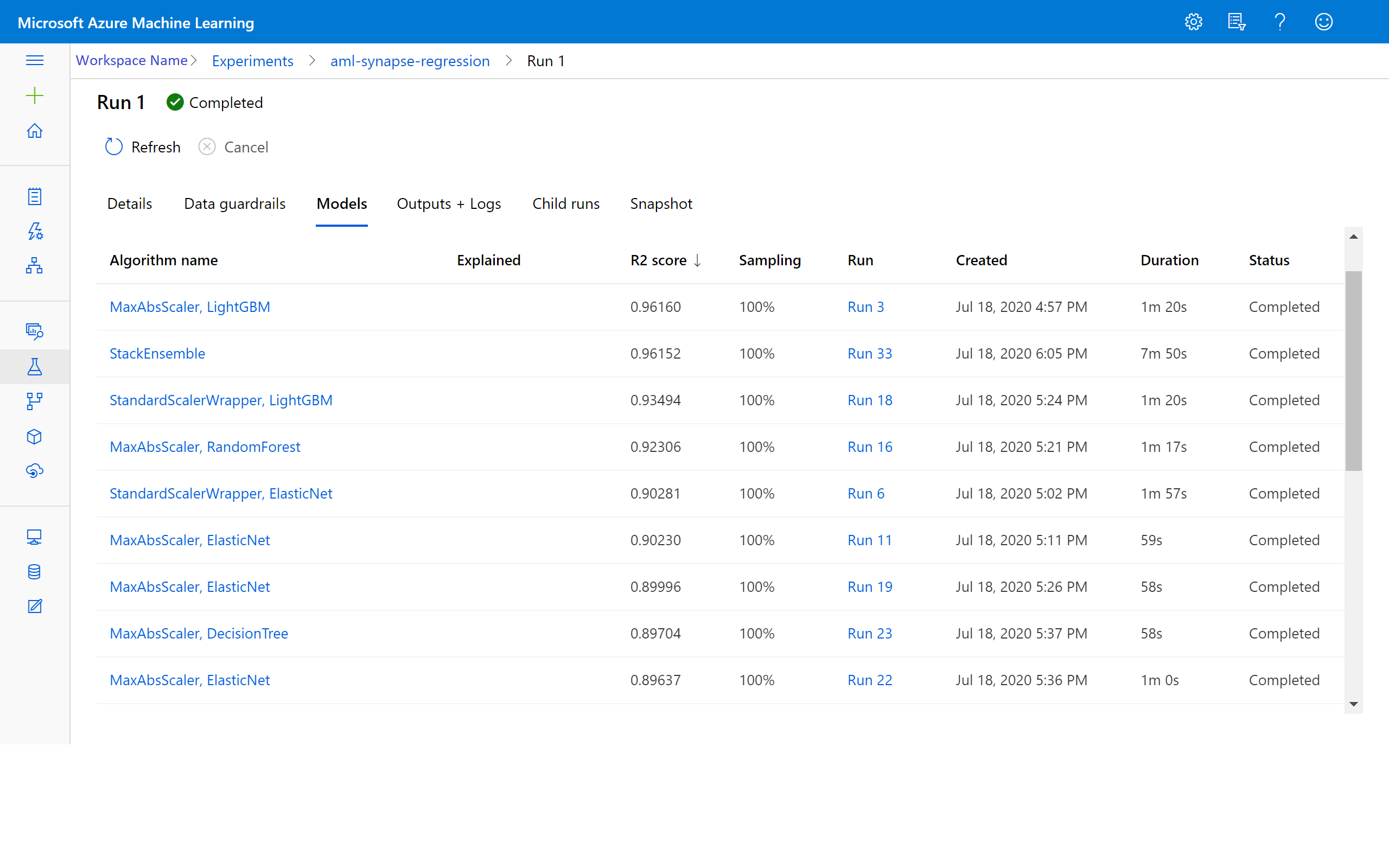
Po dokončení experimentu vrátí výstup podrobnosti o dokončených iteracích. Pro každou iteraci uvidíte typ modelu, dobu trvání běhu a přesnost trénování. Pole BEST sleduje nejlepší skóre trénování na základě vašeho typu metriky.

Poznámka:
Po odeslání experimentu automatizovaného strojového učení spustí různé iterace a typy modelů. Spuštění obvykle trvá 60 až 90 minut.
Načtení nejlepšího modelu
Pokud chcete vybrat nejlepší model z iterací, použijte get_output funkci k vrácení nejlepšího běhu a fitovaný model. Následující kód načte nejlepší běh a fitovaný model pro všechny protokolované metriky nebo konkrétní iteraci.
# Get best model
best_run, fitted_model = local_run.get_output()
Přesnost testovacího modelu
Pokud chcete otestovat přesnost modelu, použijte nejlepší model ke spuštění predikcí jízdy taxíkem v testovací datové sadě. Funkce
predictpoužívá nejlepší model a předpovídá hodnotyy(množství jízdného) z ověřovací datové sady.# Test best model accuracy validation_data_pd = validation_data.toPandas() y_test = validation_data_pd.pop("fareAmount").to_frame() y_predict = fitted_model.predict(validation_data_pd)Hlavní střední kvadratická chyba je často používaným měřítkem rozdílů mezi vzorovými hodnotami předpovídanými modelem a pozorovanými hodnotami. Výsledek vypočítáte tak, že porovnáte
y_testdatový rámec s hodnotami predikovanými modelem.Funkce
mean_squared_errorpřebírá dvě pole a vypočítá průměrnou kvadratická chybu mezi nimi. Pak vezmete druhou odmocninu výsledku. Tato metrika udává přibližnou vzdálenost předpovědí jízdy taxíkem od skutečných hodnot jízdného.from sklearn.metrics import mean_squared_error from math import sqrt # Calculate root-mean-square error y_actual = y_test.values.flatten().tolist() rmse = sqrt(mean_squared_error(y_actual, y_predict)) print("Root Mean Square Error:") print(rmse)Root Mean Square Error: 2.309997102577151Chyba odmocnina střední kvadratická je dobrou mírou toho, jak přesně model predikuje odpověď. Z výsledků vidíte, že model je poměrně dobrý při předpovídání jízdného taxíkem z funkcí datové sady, obvykle ve výši 2,00 USD.
Spuštěním následujícího kódu vypočítejte střední absolutní procentuální chybu. Tato metrika vyjadřuje přesnost jako procento chyby. Provede to výpočtem absolutního rozdílu mezi jednotlivými predikovanými a skutečnými hodnotami a následným součtem všech rozdílů. Pak se tento součet vyjadřuje jako procento součtu skutečných hodnot.
# Calculate mean-absolute-percent error and model accuracy sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)Model MAPE: 0.03655071038487368 Model Accuracy: 0.9634492896151263Ze dvou metrik přesnosti predikce vidíte, že model je poměrně dobrý při předpovídání jízdného taxíkem od funkcí datové sady.
Po přizpůsobení modelu lineární regrese teď potřebujete určit, jak dobře model vyhovuje datům. Uděláte to tak, že vykreslíte skutečné hodnoty jízdné proti předpovídanému výstupu. Kromě toho vypočítáte míru R-squared, abyste pochopili, jak jsou data blízko fitované regresní přímce.
import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import mean_squared_error, r2_score # Calculate the R2 score by using the predicted and actual fare prices y_test_actual = y_test["fareAmount"] r2 = r2_score(y_test_actual, y_predict) # Plot the actual versus predicted fare amount values plt.style.use('ggplot') plt.figure(figsize=(10, 7)) plt.scatter(y_test_actual,y_predict) plt.plot([np.min(y_test_actual), np.max(y_test_actual)], [np.min(y_test_actual), np.max(y_test_actual)], color='lightblue') plt.xlabel("Actual Fare Amount") plt.ylabel("Predicted Fare Amount") plt.title("Actual vs Predicted Fare Amount R^2={}".format(r2)) plt.show()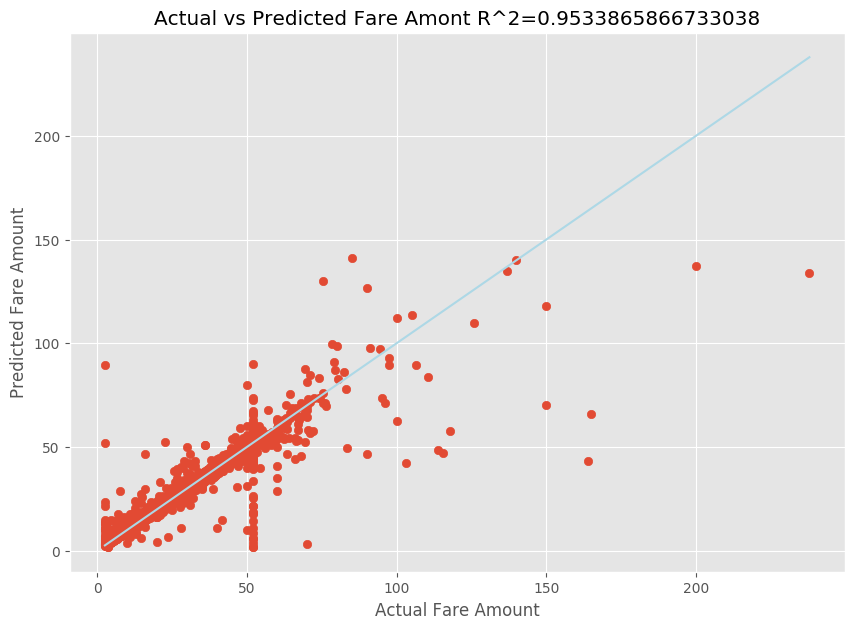
Z výsledků vidíte, že míra R-squared představuje 95 procent rozptylu. To je také ověřeno skutečným grafem a pozorovaným grafem. Čím větší je rozptyl, pro který regresní model počítá, tím blíže datové body spadají do fitované regresní přímky.
Registrace modelu do služby Azure Machine Učení
Jakmile ověříte svůj nejlepší model, můžete ho zaregistrovat do služby Azure Machine Učení. Pak můžete stáhnout nebo nasadit registrovaný model a přijmout všechny soubory, které jste zaregistrovali.
description = 'My automated ML model'
model_path='outputs/model.pkl'
model = best_run.register_model(model_name = 'NYCYellowTaxiModel', model_path = model_path, description = description)
print(model.name, model.version)
NYCYellowTaxiModel 1
Zobrazení výsledků ve službě Azure Machine Učení
K výsledkům iterací se dostanete také tak, že přejdete na experiment ve svém pracovním prostoru Azure Machine Učení. Tady můžete získat další podrobnosti o stavu spuštění, pokusech o modely a dalších metrikách modelu.