Kurz: Vytvoření doporučovače filmů pomocí maticové faktorizace s ML.NET
V tomto kurzu se dozvíte, jak vytvořit nástroj pro doporučování filmů s ML.NET v konzolové aplikaci .NET Core. Postup používá C# a Visual Studio 2019.
V tomto kurzu se naučíte:
- Výběr algoritmu strojového učení
- Příprava a načtení dat
- Sestavení a trénování modelu
- Vyhodnocení modelu
- Nasazení a využití modelu
Zdrojový kód pro tento kurz najdete v úložišti dotnet/samples .
Pracovní postup strojového učení
K provedení úkolu a všech dalších ML.NET úkolů použijete následující kroky:
Požadavky
Vyberte příslušnou úlohu strojového učení.
Existuje několik způsobů, jak přistupovat k problémům s doporučeními, například doporučit seznam filmů nebo seznam souvisejících produktů, ale v tomto případě předpovíte, jaké hodnocení (1–5) uživatel udělí konkrétnímu filmu, a doporučíte ho, pokud je vyšší než definovaná prahová hodnota (čím vyšší je hodnocení, tím vyšší je pravděpodobnost, že se uživateli bude konkrétní film líbit).
Vytvoření konzolové aplikace
Vytvoření projektu
Vytvořte konzolovou aplikaci jazyka C# s názvem MovieRecommender. Klikněte na tlačítko Další .
Jako architekturu, kterou chcete použít, zvolte .NET 6. Klikněte na tlačítko Vytvořit.
Vytvořte v projektu adresář s názvem Data pro uložení datové sady:
V Průzkumník řešení klikněte pravým tlačítkem na projekt a vyberte Přidat>novou složku. Zadejte "Data" a stiskněte Enter.
Nainstalujte balíčky NuGet Microsoft.ML a Microsoft.ML.Recommender :
Poznámka
Tato ukázka používá nejnovější stabilní verzi uvedených balíčků NuGet, pokud není uvedeno jinak.
V Průzkumník řešení klikněte pravým tlačítkem na projekt a vyberte Spravovat balíčky NuGet. Jako zdroj balíčku zvolte "nuget.org", vyberte kartu Procházet , vyhledejte Microsoft.ML, v seznamu vyberte balíček a vyberte tlačítko Nainstalovat . V dialogovém okně Náhled změn vyberte tlačítko OK a pak v dialogovém okně Přijetí licence vyberte tlačítko Souhlasím, pokud souhlasíte s licenčními podmínkami pro uvedené balíčky. Opakujte tento postup pro Microsoft.ML.Recommender.
Na začátek souboru Program.cs přidejte následující
usingpříkazy:using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Stažení vašich dat
Stáhněte si tyto dvě datové sady a uložte je do složky Data , kterou jste předtím vytvořili:
Klikněte pravým tlačítkem na recommendation-ratings-train.csv a vyberte Uložit odkaz (nebo cíl) jako.
Klikněte pravým tlačítkem na recommendation-ratings-test.csv a vyberte Uložit odkaz (nebo cíl) jako.
Nezapomeňte buď uložit soubory *.csv do složky Data , nebo po uložení jinam přesunout *.csv soubory do složky Data .
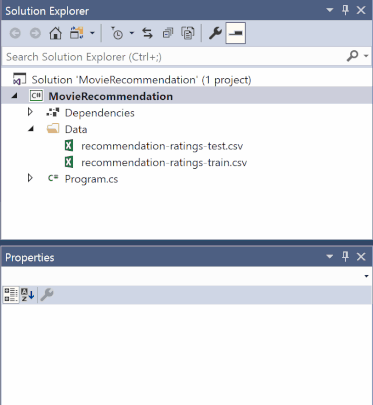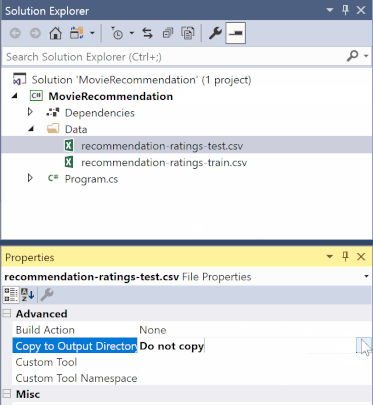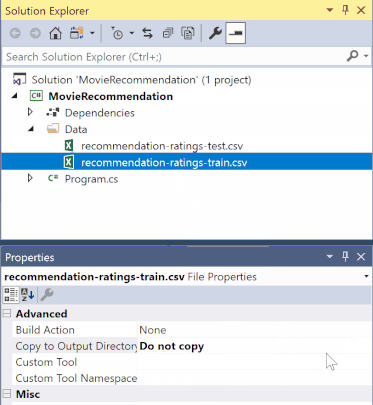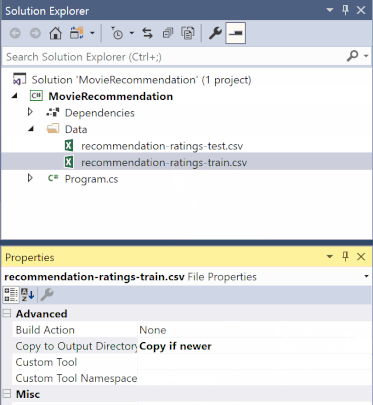
V Průzkumník řešení klikněte pravým tlačítkem na jednotlivé soubory *.csv a vyberte Vlastnosti. V části Upřesnit změňte hodnotu Kopírovat do výstupního adresáře na Kopírovat, pokud je novější.
Načtení dat
Prvním krokem v procesu ML.NET je příprava a načtení trénovacích a testovacích dat modelu.
Data hodnocení doporučení jsou rozdělená na Train datové sady a Test . Data Train se používají tak, aby vyhovovala vašemu modelu. Data se Test používají k předpovědím s natrénovaným modelem a k vyhodnocení výkonu modelu. Je běžné mít rozdělení 80/20 s daty Train a Test .
Níže je náhled dat z *.csv souborů:
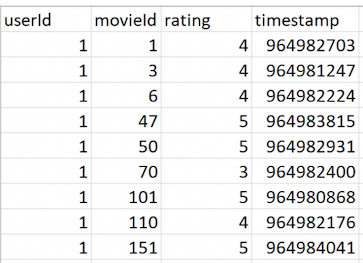
V souborech *.csv jsou čtyři sloupce:
userIdmovieIdratingtimestamp
Ve strojovém učení se sloupce, které slouží k vytvoření předpovědi, nazývají funkce a sloupec s vrácenou predikcí se nazývá Popisek.
Chcete předpovědět hodnocení filmů, takže sloupec hodnocení je .Label Další tři sloupce , userIdmovieIda timestamp se Features používají k predikci Label.
| Funkce | Popisek |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Je na vás, abyste se rozhodli, které Features se použijí k predikci Label. Můžete také použít metody, jako je důležitost funkce permutace , které vám pomůžou s výběrem nejlepší Featuresfunkce .
V tomto případě byste měli sloupec vyloučit timestamp jako, Feature protože časové razítko nemá ve skutečnosti vliv na to, jak uživatel oceňuje daný film, a proto by nepřispěl k přesnější předpovědi:
| Funkce | Popisek |
|---|---|
userId |
rating |
movieId |
Dále musíte definovat datovou strukturu pro vstupní třídu.
Přidejte do projektu novou třídu:
V Průzkumník řešení klikněte pravým tlačítkem myši na projekt a pak vyberte Přidat > novou položku.
V dialogovém okně Přidat novou položku vyberte Třída a změňte pole Název na MovieRatingData.cs. Pak vyberte tlačítko Přidat .
Soubor MovieRatingData.cs se otevře v editoru kódu. Na začátek souboru MovieRatingData.cs přidejte následující using příkaz:
using Microsoft.ML.Data;
Vytvořte třídu s názvem MovieRating odebráním existující definice třídy a přidáním následujícího kódu do souboru MovieRatingData.cs:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating určuje vstupní datovou třídu. Atribut LoadColumn určuje, které sloupce (podle indexu sloupců) v datové sadě se mají načíst. Sloupce userId a movieId jsou vaše Features (vstupy, které dáte modelu k predikci Label), a sloupec hodnocení je Label ten, který budete predikovat (výstup modelu).
Vytvořte další třídu , MovieRatingPredictionkterá bude reprezentovat predikované výsledky přidáním následujícího kódu za MovieRating třídu v Souboru MovieRatingData.cs:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
V souboru Program.cs nahraďte Console.WriteLine("Hello World!") kódem následujícím:
MLContext mlContext = new MLContext();
Třída MLContext je výchozím bodem pro všechny operace ML.NET a inicializace mlContext vytvoří nové ML.NET prostředí, které lze sdílet napříč objekty pracovního postupu vytváření modelu. Koncepčně DBContext je to podobné jako v Entity Frameworku.
V dolní části souboru vytvořte metodu s názvem LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Poznámka
Tato metoda zobrazí chybu, dokud v následujících krocích nepřidáte návratový příkaz.
Inicializace proměnných cesty k datům, načtení dat ze souborů *.csv a vrácení Train dat a Test jako IDataView objektů přidáním následujícího řádku kódu v LoadData():
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Data v ML.NET jsou reprezentována jako rozhraní IDataView. IDataView je flexibilní a efektivní způsob popisu tabulkových dat (číselných a textových). Data je možné načíst z textového souboru nebo v reálném čase (například z databáze SQL nebo souborů protokolu) do objektu IDataView .
LoadFromTextFile() definuje datové schéma a čte v souboru. Přebírá proměnné cesty k datům a vrací IDataViewhodnotu . V tomto případě zadáte cestu k souborům a Train označíte Test jak záhlaví textového souboru (aby mohl správně používat názvy sloupců), tak oddělovač dat čárky (výchozí oddělovač je tabulátor).
Přidejte následující kód, který zavolá metodu LoadData()Train a vrátí data a Test :
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Sestavení a trénování modelu
Vytvořte metodu BuildAndTrainModel() hned za metodou LoadData() pomocí následujícího kódu:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Poznámka
Tato metoda zobrazí chybu, dokud v následujících krocích nepřidáte návratový příkaz.
Definujte transformace dat přidáním následujícího kódu do BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
movieId Vzhledem k tomuuserId, že a představují uživatele a názvy filmů, nikoli skutečné hodnoty, použijete metodu MapValueToKey() k transformaci každého userId z nich movieId na sloupec typu Feature číselného klíče (formát přijímaný algoritmy doporučení) a přidáte je jako nové sloupce datové sady:
| userId | ID filmu | Popisek | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | klíč uživatele1 | klíč_videa1 |
| 1 | 3 | 4 | klíč uživatele1 | klíč_videa2 |
| 1 | 6 | 4 | klíč uživatele1 | klíč_videa3 |
Zvolte algoritmus strojového učení a připojte ho k definicím transformace dat přidáním následujícího řádku kódu do BuildAndTrainModel():
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer je váš algoritmus trénování podle doporučení. Maticová faktorizace je běžný přístup k doporučení, pokud máte data o tom, jak uživatelé hodnotili produkty v minulosti, což je případ datových sad v tomto kurzu. Pokud máte k dispozici různá data, existují i další algoritmy doporučení (další informace najdete níže v části Další algoritmy doporučení ).
V tomto případě Matrix Factorization algoritmus používá metodu nazvanou "filtrování založené na spolupráci", která předpokládá, že pokud má uživatel 1 stejný názor jako uživatel 2 na určitý problém, pak je pravděpodobnější, že uživatel 1 bude mít stejný pocit jako uživatel 2 ohledně jiného problému.
Pokud například uživatelé 1 a Uživatel 2 hodnotí filmy podobně, pak je pravděpodobnější, že se uživatel 2 bude těšit na film, který uživatel 1 sledoval a který má vysoké hodnocení:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Uživatel 1 | Sledovaný a lajkovaný film | Sledovaný a lajkovaný film | Sledovaný a lajkovaný film |
| Uživatel 2 | Sledovaný a lajkovaný film | Sledovaný a lajkovaný film | Neshlédnul(a) - DOPORUČIT film |
Školitel Matrix Factorization má několik možností, o kterých si můžete přečíst více v části Algoritmy hyperparametry níže.
Přiřažte model datům Train a vraťte vytrénovaný model přidáním následujícího řádku kódu do BuildAndTrainModel() metody:
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Metoda Fit() trénuje model pomocí poskytnuté trénovací datové sady. Technicky vzato Estimator provede definice transformací dat a použitím trénování a vrátí zpět natrénovaný model, což je Transformer.
Další informace o pracovním postupu trénování modelu v ML.NET najdete v tématu Co je ML.NET a jak funguje?.
Jako další řádek kódu pod volání LoadData() metody přidejte následující kód, který zavolá metodu BuildAndTrainModel() a vrátí vytrénovaný model:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Vyhodnocení modelu
Po vytrénování modelu použijte testovací data k vyhodnocení výkonu modelu.
Vytvořte metodu EvaluateModel() hned za metodou BuildAndTrainModel() pomocí následujícího kódu:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Transformujte Test data přidáním následujícího kódu do EvaluateModel():
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Metoda Transform() provádí předpovědi pro více zadaných vstupních řádků testovací datové sady.
Model vyhodnotíte tak, že do metody přidáte následující řádek kódu EvaluateModel() :
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Jakmile máte nastavenou predikci, vyhodnotí metoda Evaluate() model, která porovná předpovězené hodnoty se skutečnými Labels hodnotami v testovací datové sadě a vrátí metriky týkající se výkonu modelu.
Vytiskněte metriky vyhodnocení do konzoly tak, že jako další řádek kódu v metodě přidáte EvaluateModel() následující kód:
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Jako další řádek kódu pod volání BuildAndTrainModel() metody pro volání metody EvaluateModel() přidejte následující kód:
EvaluateModel(mlContext, testDataView, model);
Dosavadní výstup by měl vypadat podobně jako následující text:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
V tomto výstupu je 20 iterací. V každé iteraci míra chyby klesá a konverguje blíže a blíž k hodnotě 0.
Hodnota root of mean squared error (RMS nebo RMSE) se používá k měření rozdílů mezi předpovězenými hodnotami modelu a pozorovanými hodnotami testovací datové sady. Technicky je to druhá odmocnina průměru druhých mocnin chyb. Nižší je, tím lepší je model.
R Squared označuje, jak dobře data odpovídají modelu. Rozsahy od 0 do 1. Hodnota 0 znamená, že data jsou náhodná nebo jinak nemůžou být pro model vhodná. Hodnota 1 znamená, že model přesně odpovídá datům. Chcete R Squared , aby vaše skóre bylo co nejblíže 1.
Vytváření úspěšných modelů je iterativní proces. Tento model má počáteční nižší kvalitu, protože kurz k zajištění rychlého trénování modelu používá malé datové sady. Pokud s kvalitou modelu nejste spokojení, můžete ji zkusit vylepšit poskytnutím větších trénovacích datových sad nebo výběrem různých trénovacích algoritmů s různými hyperparametry pro každý algoritmus. Další informace najdete v části Vylepšení modelu níže.
Použití modelu
Trénovaný model teď můžete použít k vytváření předpovědí u nových dat.
Vytvořte metodu UseModelForSinglePrediction() hned za metodou EvaluateModel() pomocí následujícího kódu:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
Pomocí příkazu PredictionEngine můžete předpovědět hodnocení přidáním následujícího kódu do UseModelForSinglePrediction():
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine je rozhraní API pro pohodlí, které umožňuje provádět předpovědi pro jednu instanci dat. PredictionEngine není bezpečná pro přístup z více vláken. Je přijatelné používat v jednovláknovém nebo prototypovém prostředí. Pokud chcete zvýšit výkon a bezpečnost vláken v produkčních prostředích, použijte PredictionEnginePool službu , která vytvoří PredictionEngineObjectPool objekt objektů pro použití v celé aplikaci. Projděte si tohoto průvodce používáním PredictionEnginePool ve webovém rozhraní API ASP.NET Core.
Poznámka
PredictionEnginePool rozšíření služby je aktuálně ve verzi Preview.
Vytvořte instanci MovieRating s názvem testInput a předejte ji modulu predikcí tak, že jako další řádky kódu v metodě přidáte UseModelForSinglePrediction() následující kód:
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
Funkce Predict() vytvoří předpověď pro jeden sloupec dat.
Pomocí , nebo predikovaného hodnocení pak Scoremůžete určit, jestli chcete doporučit film s ID filmu 10 uživateli 6. Čím vyšší Scoreje , tím vyšší je pravděpodobnost, že se uživateli líbí konkrétní film. V tomto případě řekněme, že doporučíte filmy s předpokládaným hodnocením > 3,5.
Pokud chcete výsledky vytisknout, přidejte do metody následující kód jako další řádky UseModelForSinglePrediction() kódu:
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Za volání EvaluateModel() metody pro volání metody UseModelForSinglePrediction() přidejte následující kód jako další řádek kódu:
UseModelForSinglePrediction(mlContext, model);
Výstup této metody by měl vypadat podobně jako následující text:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Uložení modelu
Pokud chcete model použít k vytváření predikcí v aplikacích koncových uživatelů, musíte ho nejdřív uložit.
Vytvořte metodu SaveModel() hned za metodou UseModelForSinglePrediction() pomocí následujícího kódu:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Natrénovaný model uložte přidáním následujícího kódu do SaveModel() metody :
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Tato metoda uloží trénovaný model do souboru .zip (do složky Data), který pak můžete použít v jiných aplikacích .NET k vytváření předpovědí.
Za volání UseModelForSinglePrediction() metody pro volání metody SaveModel() přidejte následující kód jako další řádek kódu:
SaveModel(mlContext, trainingDataView.Schema, model);
Použití uloženého modelu
Jakmile natrénovaný model uložíte, můžete ho využívat v různých prostředích. Informace o operacionalizaci natrénovaného modelu strojového učení v aplikacích najdete v tématu Ukládání a načítání natrénovaných modelů .
Výsledky
Po provedení výše uvedených kroků spusťte konzolovou aplikaci (Ctrl + F5). Výsledky z jedné výše uvedené předpovědi by se měly podobat následujícímu. Může se zobrazit upozornění nebo zpracování zpráv, ale tyto zprávy byly odebrány z následujících výsledků pro přehlednost.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Gratulujeme! Teď jste úspěšně vytvořili model strojového učení pro doporučování filmů. Zdrojový kód pro tento kurz najdete v úložišti dotnet/samples .
Vylepšení modelu
Existuje několik způsobů, jak můžete zlepšit výkon modelu, abyste mohli získat přesnější předpovědi.
Data
Přidáním dalších trénovacích dat, která mají dostatek ukázek pro každého uživatele a ID filmu, může pomoct zlepšit kvalitu modelu doporučení.
Křížové ověřování je technika vyhodnocování modelů, která náhodně rozděluje data na podmnožinu (místo extrahování testovacích dat z datové sady jako v tomto kurzu) a přebírá některé skupiny jako trénovací data a některé skupiny jako testovací data. Tato metoda předčí rozdělení trénování a testování z hlediska kvality modelu.
Funkce
V tomto kurzu použijete pouze tři Features (user id, movie ida rating), které datová sada poskytuje.
I když je to dobrý začátek, ve skutečnosti můžete chtít přidat další atributy nebo Features (například věk, pohlaví, geografickou polohu atd.), pokud jsou součástí datové sady. Přidání relevantnějších Features může pomoct zlepšit výkon modelu doporučení.
Pokud si nejste jisti, co Features může být pro vaši úlohu strojového učení nejrelevantnější, můžete také využít funkci Výpočet příspěvku funkcí (FCC) a důležitost permutace, což ML.NET poskytuje k objevení nejvlivnější Featuresfunkce .
Hyperparametry algoritmu
I když ML.NET poskytuje dobré výchozí trénovací algoritmy, můžete výkon dále doladit změnou hyperparametrů algoritmu.
V případě Matrix Factorizationmůžete experimentovat s hyperparametry, jako jsou NumberOfIterations a ApproximationRank , abyste zjistili, jestli vám to poskytuje lepší výsledky.
Například v tomto kurzu jsou možnosti algoritmu:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Další algoritmy doporučení
Algoritmus faktorizace matice s filtrováním založeným na spolupráci je pouze jedním z přístupů k provádění doporučení filmů. V mnoha případech nemusí být data hodnocení k dispozici a historie filmů je dostupná jenom od uživatelů. V jiných případech můžete mít více než jen data o hodnocení uživatele.
| Algoritmus | Scenario | Ukázka |
|---|---|---|
| Faktorizace matice jedné třídy | Tuto možnost použijte, pokud máte jenom userId a movieId. Tento styl doporučení je založen na scénáři spoluprodeje nebo na produktech, které se často kupují společně, což znamená, že zákazníkům doporučí sadu produktů na základě jejich vlastní historie nákupních objednávek. | >Vyzkoušet |
| Stroje pro faktorizaci s informacemi o terénu | Tato možnost slouží k vytváření doporučení, pokud máte více funkcí nad rámec userId, productId a ratingu (například popis produktu nebo cena produktu). Tato metoda také používá metodu filtrování založeného na spolupráci. | >Vyzkoušet |
Nový uživatelský scénář
Jedním z běžných problémů při společném filtrování je problém s studeným startem, kdy máte nového uživatele bez předchozích dat, ze kterých by bylo odvozování odvozeno. Tento problém se často řeší tak, že požádáte nové uživatele, aby vytvořili profil a například ohodnotili filmy, které viděli v minulosti. I když tato metoda uživatele trochu zatěžuje, poskytuje nová data pro nové uživatele bez historie hodnocení.
Zdroje informací
Data použitá v tomto kurzu jsou odvozená z datové sady MovieLens.
Další kroky
V tomto kurzu jste se naučili:
- Výběr algoritmu strojového učení
- Příprava a načtení dat
- Sestavení a trénování modelu
- Vyhodnocení modelu
- Nasazení a využití modelu
Další informace najdete v dalším kurzu.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro