Tipy a triky pro vytváření sestav v Power BI Desktopu
Pokud chcete získat maximum z dat, někdy potřebujete trochu další pomoc. Tento článek obsahuje tipy a triky, které můžete použít při vytváření sestav v Microsoft Power BI Desktopu. Tyto tipy fungují také v edicích Microsoft Excelu 2016 nebo Excelu 2013 Pro-Plus s povoleným doplňkem Power Pivot a nainstalovaným a povoleným Power Query.
Naučte se používat Editor Power Query
Editor Power Query v Power BI Desktopu se podobá funkci doplňku Power Query v Excelu 2013. I když podpora Power BI obsahuje několik užitečných článků, můžete si také projít dokumentaci k Power Query na support.office.com, abyste mohli začít.
Další informace získáte z Centra prostředků Power Query.
Můžete také zobrazit odkaz na vzorec.
Datové typy v Editor Power Query
Editor Power Query v Power BI Desktopu načítá data pomocí nejlepšího zjišťování datových typů odhadu. U vzorců se někdy nastavení datového typu u sloupců nezachová. Po provedení následujících operací se ujistěte, že datový typ sloupců je správný: Nejprve načtěte data do Editor Power Query, první řádek jako záhlaví, Přidat sloupec, Seskupit podle, Sloučit, Připojit a před prvním načtením dat.
Jednou z klíčových věcí, kterou je potřeba si zapamatovat: kurzíva v datové mřížce neznamená, že je datový typ správně nastavený, znamená to, že data se nepovažují za text.
Referenční dotazy v Editor Power Query
Když v Power BI Desktopu v navigátoru Editor Power Query kliknete pravým tlačítkem na některý z dotazů, zobrazí se možnost Reference. To je užitečné z následujícího důvodu:
- Při použití souborů jako zdroje dat pro dotaz se v dotazu uloží absolutní cesta k souboru. Když sdílíte nebo přesunete soubor Power BI Desktopu nebo excelový sešit, ušetříte čas při aktualizaci cest aktualizací souboru nebo sešitu jednou místo aktualizace cest.
Ve výchozím nastavení se všechny dotazy načítají do datového modelu. Některé dotazy jsou zprostředkujícími kroky, které nejsou určené koncovým uživatelům. Když odkazujete na dotazy, jak jsme zmínili dříve, často se jedná o případ. Chování načítání dotazů můžete řídit tak, že kliknete pravým tlačítkem myši na dotaz v Navigátoru a přepnete možnost Povolit načtení. Pokud možnost Povolit načtení nemá vedle sebe značku zaškrtnutí, je dotaz stále dostupný v Editor Power Query a můžete ho použít s dalšími dotazy. Je zvlášť užitečná v kombinaci s transformacemi sloučení, připojení a odkazu. Vzhledem k tomu, že se výsledky dotazu nenačtou do datového modelu, nebude dotaz nepřehledný seznam polí sestav ani datový model.
Bodové grafy potřebují identifikátor bodu.
Podívejte se na příklad jednoduché tabulky Teploty a čas, kdy bylo čtení pořízeno. Pokud vykreslíte přímo bodový graf, Power BI agreguje všechny hodnoty do jednoho bodu. Pokud chcete zobrazit jednotlivé datové body, musíte do kontejneru Podrobnosti v seznamu polí přidat pole. Jednoduchý způsob, jak to udělat v Power BI Desktopu, je na Editor Power Query pomocí možnosti Přidat indexový sloupec na pásu karet Přidat sloupec.
Referenční řádky v sestavě
K definování referenční čáry můžete použít počítaný sloupec v Power BI Desktopu. Určete tabulku a sloupec, na kterém chcete vytvořit referenční čáru. Na kartě Domů vyberte nový sloupec na pásu karet a do řádku vzorců zadejte následující vzorec:
Target Value = 100
Tento počítaný sloupec vrátí hodnotu 100 bez ohledu na to, kde se používá. Nový sloupec se zobrazí v seznamu polí. Přidejte do spojnicového grafu počítaný sloupec Cílová hodnota, abyste ukázali, jak každá řada souvisí s danou referenční čárou.
Seřadit podle jiného sloupce
Pokud v Power BI použijete hodnotu kategorií (řetězec) pro osy grafu nebo v průřezu nebo filtru, výchozí pořadí je abecední. Pokud potřebujete toto pořadí přepsat , například pro dny v týdnu nebo měsíce, můžete Power BI Desktopu říct, aby seřadil podle jiného sloupce. Další informace najdete v tématu Řazení jednoho sloupce podle jiného sloupce v Power BI.
Vytváření map snadněji pomocí tipů pro Bing
Power BI se integruje s Bingem a poskytuje výchozí souřadnice map v procesu označovaného jako geografické kódování, takže vytváření map je jednodušší. Bing používá algoritmy a rady k pokusu o získání správného umístění, ale je to nejlepší odhad. Pokud chcete zvýšit pravděpodobnost správného geografického kódování, můžete použít následující tipy:
Když vytváříte mapu, často chcete vykreslit země/oblasti, státy a města. Pokud v Power BI Desktopu pojmenujete sloupce za zeměpisným označením, Bing dokáže lépe najít, co chcete zobrazit. Pokud máte například pole názvů států USA, například "Kalifornie" a "Washington", Bing může místo státu Washington vrátit místo státu Washington místo státu Washington slovo "Washington". Pojmenování sloupce State zlepšuje geografické kódování. Totéž platí pro sloupce s názvem "Země nebo oblast" a "Město".
Některá označení jsou nejednoznačná v kontextu více zemí nebo oblastí. V některých případech se jedna země nebo oblast považuje za "stát" za "provincii", "okres" nebo jiné označení. Přesnost geografického kódování můžete zvýšit tak, že vytvoříte sloupce, které připojí více polí dohromady, a použijete je k vykreslení umístění dat. Příkladem může být místo předání pouze "Wiltshire", můžete předat "Wiltshire, Anglie", abyste získali přesnější výsledek geografického kódování.
V Power BI Desktopu nebo služba Power BI můžete vždy zadat konkrétní umístění zeměpisné šířky a délky. Když to uděláte, musíte také předat pole Umístění. V opačném případě se data ve výchozím nastavení agregují, takže umístění zeměpisné šířky a délky nemusí odpovídat očekávanému umístění.
Kategorizace geografických polí tak, aby naznačovala geografické kódování Bingu
Dalším způsobem, jak zajistit správné geografické kódování polí, je nastavení kategorie dat u datových polí. V Power BI Desktopu vyberte požadovanou tabulku, přejděte na pás karet Upřesnit a pak nastavte kategorii dat na Adresu, Město, Kontinent, Země/oblast, PSČ, Stát nebo Provincie. Tyto kategorie dat pomáhají Bingu správně zakódovat data. Další informace najdete v tématu Určení kategorií dat v Power BI Desktopu.
Lepší geografické kódování s konkrétnějšími umístěními
Někdy je i nastavení kategorií dat pro mapování nedostatečné. Pomocí Editor Power Query v Power BI Desktopu můžete vytvořit konkrétnější umístění, jako je adresa ulice. K vytvoření vlastního sloupce použijte funkci Přidat sloupec. Potom vytvořte požadované umístění následujícím způsobem:
= [Field1] & " " & [Field2]
Pak toto výsledné pole použijte ve vizualizacích mapy. To je užitečné při vytváření poštovních adres z polí dodacích adres, která jsou v datových sadách společná. Jednou z poznámek je, že zřetězení funguje jenom s textovými poli. V případě potřeby převeďte číslo ulice na textový datový typ, než ho použijete k vytvoření adresy.
Histogramy ve fázi dotazu
V Power BI Desktopu můžete vytvářet histogramy několika způsoby:
Nejjednodušší histogramy: Určete, který dotaz obsahuje pole, na kterém chcete vytvořit histogram. Pomocí možnosti Odkaz pro dotaz vytvořte nový dotaz a pojmenujte ho Histogram FieldName. Použijte možnost Seskupovat podle na pásu karet Transformace a vyberte agregované řádky počtu. Ujistěte se, že datový typ je číslo výsledného agregovaného sloupce. Pak vizualizovat tato data na stránce sestav. Tento histogram je rychlý a snadno se sestavuje, ale nefunguje dobře, pokud máte mnoho datových bodů a neumožňuje štětce napříč vizuály.
Definování kontejnerů pro sestavení histogramu: Určete, který dotaz má pole, na kterém chcete vytvořit histogram. Pomocí možnosti Odkaz pro dotaz vytvořte nový dotaz a pojmenujte ho FieldName. Teď definujte kontejnery pomocí pravidla. Použijte možnost Přidat vlastní sloupec na pásu karet Přidat sloupec a vytvořte vlastní pravidlo. Jednoduché pravidlo dělení na kontejnery může vypadat takto:
if([FieldName] \< 2) then "\<2 min" else
if([FieldName] \< 5) then "\<5 min" else
if([FieldName] \< 10) then "\<10 min" else
if([FieldName] \< 30) then "\<30 min" else
"longer")
Ujistěte se, že datový typ je číslo výsledného agregovaného sloupce. Teď můžete použít skupinu podle techniky popsané v nejjednodušším histogramu k dosažení histogramu. Tato možnost zpracovává více datových bodů, ale přesto nepomůže s čištěním.
Definování histogramu, který podporuje štětce: Štětce je, když jsou vizuály propojené dohromady, takže když uživatel vybere datový bod v jednom vizuálu, ostatní vizuály na stránce sestavy zvýrazní nebo vyfiltrují datové body související s vybraným datovým bodem. Vzhledem k tomu, že pracujete s daty v době dotazu, musíte vytvořit relaci mezi tabulkami a zajistit, abyste věděli, která položka podrobností souvisí s kontejnerem v histogramu a naopak.
Spusťte proces pomocí možnosti Odkaz na dotaz, na který má pole, na které chcete vytvořit histogram. Pojmenujte nový dotaz Buckets. V tomto příkladu zavoláme podrobnosti původního dotazu. Potom odeberte všechny sloupce kromě sloupce, který chcete použít jako kontejner histogramu. Teď v dotazu použijte funkci Odebrat duplicity . Funkce je v nabídce po kliknutí pravým tlačítkem myši , když vyberete sloupec, takže zbývající hodnoty jsou jedinečné hodnoty ve sloupci. Pokud máte desetinná čísla, můžete nejprve pomocí tipu definovat kontejnery a vytvořit histogram a získat spravovatelnou sadu kontejnerů. Teď zkontrolujte data zobrazená v náhledu dotazu. Pokud se zobrazí prázdné hodnoty nebo hodnota null, musíte je před vytvořením relace opravit. Použití tohoto přístupu může být problematické kvůli potřebě řazení.
Poznámka:
Před vytvářením vizuálů je vhodné se zamyslet nad pořadím řazení.
Dalším krokem v procesu je definování relace mezi dotazy Buckets a Details ve sloupci buckets. V Power BI Desktopu vyberte Správa relací na pásu karet. Vytvořte relaci, ve které jsou kontejnery v levé tabulce a podrobnosti v pravé tabulce, a vyberte pole, které používáte pro histogram.
Posledním krokem je vytvoření histogramu. Přetáhněte pole Bucket z tabulky Buckets . Odeberte výchozí pole z výsledného sloupcového grafu. Teď z tabulky Details přetáhněte pole histogramu do stejného vizuálu. V seznamu polí změňte výchozí agregaci na Počet. Výsledkem je histogram. Pokud vytvoříte další vizuál, jako je mapa stromové struktury z tabulky Podrobností, vyberte datový bod v mapě stromové struktury, abyste viděli zvýraznění histogramu a zobrazili histogram pro vybraný datový bod vzhledem k trendu celé datové sady.
Histogramy
V Power BI Desktopu můžete k definování histogramu použít počítané pole. Identifikujte tabulku a sloupec, na které chcete vytvořit histogram. Do oblasti výpočtu zadejte následující vzorec:
Frequency:=COUNT(<název> sloupce)
Uložte změny a vraťte se do sestavy. <Přidejte název> sloupce a frekvenci do tabulky a pak převeďte na pruhový graf. Ujistěte se, <že je název> sloupce na ose x a počítané pole Frekvence je na ose y.
Tipy a triky pro vytváření relací v Power BI Desktopu
Při načítání podrobných datových sad z více zdrojů často dochází k problémům, jako jsou hodnoty null, prázdné hodnoty nebo duplicitní hodnoty, brání vytváření relací.
Podívejme se na příklad s načtenými datovými sadami aktivních žádostí zákaznické podpory a další sadou dat pracovních položek, které mají následující schémata:
CustomerIncidents: {IncidentID, CustomerName, IssueName, OpenedDate, Status} WorkItems: {WorkItemID, IncidentID, WorkItemName, OpenedDate, Status, CustomerName }
Při sledování všech incidentů a pracovních položek, které se vztahují ke konkrétnímu názvu zákazníka, není možné pouze vytvořit relaci mezi těmito dvěma datovými sadami. Některé pracovní položky nemusí souviset s názvem CustomerName, takže toto pole by mělo být prázdné nebo null. V Pracovních pojezcích a customerIncidentech může existovat více záznamů pro libovolné jméno zákazníka.
Vytváření relací v Power BI Desktopu, pokud data mají hodnoty null nebo prázdné hodnoty
Datové sady často obsahují sloupce s hodnotami null nebo prázdnými hodnotami. To může způsobit problémy při pokusu o použití relací. V podstatě máte dvě možnosti řešení problémů.
- Můžete odebrat řádky, které mají hodnoty null nebo prázdné hodnoty. Můžete to provést buď pomocí funkce filtru v Editor Power Query, nebo pokud slučujete dotazy, výběrem možnosti Zachovat pouze odpovídající řádky.
- Alternativně můžete nahradit hodnoty null nebo prázdné hodnotami hodnotami, které fungují v relacích, obvykle řetězce jako "NULL" a "(Blank)".
Tady není žádný správný přístup. Filtrování řádků ve fázi dotazu odebere řádky a může ovlivnit souhrnné statistiky a výpočty. Nahrazení hodnot zachovává datové řádky, ale může způsobit, že nesouvisející řádky se v modelu zobrazí jako související, což vede k chybnému výpočtu. Pokud použijete tuto druhou možnost, ujistěte se, že používáte filtry v zobrazení nebo grafu, kde je to vhodné, abyste měli jistotu, že získáváte přesné výsledky. Nejdůležitější je vyhodnotit, které řádky se uchovávají nebo odebírají, a porozumět celkovému dopadu na analýzu.
Vytváření relací v Power BI Desktopu, pokud data mají duplicitní hodnoty
Při načítání podrobných datových sad z více zdrojů často duplicitní hodnoty dat brání ve vytváření relací. Můžete to překonat vytvořením tabulky dimenzí s jedinečnými hodnotami z obou datových sad.
Podívejme se na příklad s načtenými datovými sadami aktivních žádostí zákaznické podpory a další sadou dat pracovních položek, které mají následující schémata:
CustomerInicdents: {IncidentID, CustomerName, IssueName, OpenedDate, Status} WorkItems: {WorkItemID, IncidentID, WorkItemName, OpenedDate, Status, CustomerName }
Při sledování všech incidentů a pracovních položek, které se vztahují ke konkrétnímu názvu zákazníka, není možné pouze vytvořit relaci mezi těmito dvěma datovými sadami. Některé pracovní položky nemusí souviset s názvem CustomerName, takže toto pole by mělo být prázdné nebo null. Pokud máte v tabulce CustomerNames nějaké prázdné hodnoty nebo hodnotu null, možná nebudete moct vytvořit relaci. Pro jeden název zákazníka může existovat více pracovních položek a customerIncidentů.
Pokud chcete v tomto případě vytvořit relaci, nejprve vytvořte logickou datovou sadu všech customerNames napříč těmito dvěma datovými sadami. V Editor Power Query můžete k vytvoření logické datové sady použít následující posloupnost:
- Duplikujte oba dotazy a pojmnujte první temp a druhé CustomerNames.
- V každém dotazu odeberte všechny sloupce kromě sloupce CustomerName.
- V každém dotazu použijte možnost Odebrat duplikát.
- V dotazu CustomerNames vyberte na pásu karet možnost Připojit, vyberte možnost Temp dotazu.
- V dotazu CustomerNames vyberte Odebrat duplicity.
Teď máte tabulku dimenzí, kterou můžete použít k relaci se CustomerIncidents a WorkItems , které obsahují všechny hodnoty každého.
Vzory, které vám použijí Editor Power Query
Editor Power Query je výkonný v tom, jak může manipulovat s daty, tvarovat a vyčistit je tak, aby byla data připravená k vizualizaci nebo modelování. Existuje několik vzorů, o které byste měli vědět.
Dočasné sloupce je možné odstranit po výpočtu výsledku.
V Power BI Desktopu často potřebujete vytvořit výpočet, který transformuje data z více sloupců do jednoho nového sloupce. Může to být složité. Jedním ze snadných způsobů, jak tento problém překonat, je rozložit operaci do kroků.
- Duplikujte počáteční sloupce.
- Sestavte dočasné sloupce.
- Vytvořte sloupec pro konečný výsledek.
- Odstraňte dočasné sloupce, aby konečná sada dat nebyla nepotřebná.
Je to možné, protože Editor Power Query provádí kroky v pořadí.
Duplicitní dotazy nebo odkazy následované sloučením s původním dotazem
Někdy je užitečné vypočítat souhrnné statistiky pro datovou sadu. Snadný způsob, jak to udělat, je duplikovat nebo odkazovat na dotaz v Editor Power Query. Pak pomocí funkce Seskupit podle vypočítáte souhrnnou statistiku. Souhrnná statistika vám pomůže normalizovat data v původních datech, takže jsou srovnatelnější. To je užitečné zejména při porovnávání jednotlivých hodnot s celku. Uděláte to tak, že přejdete na původní dotaz a vyberete možnost sloučení . Potom sloučíte data ze souhrnného dotazu na statistiku odpovídající příslušným identifikátorům. Teď jste připraveni normalizovat data podle potřeby pro analýzu.
První použití jazyka DAX
JAZYK DAX je jazyk vzorců výpočtů v Power BI Desktopu. Je optimalizovaná pro analýzy BI. Je to trochu jiné než to, co možná znáte, pokud jste používali jenom standardizovaný dotazovací jazyk, jako je SQL. K dispozici jsou dobré zdroje informací online a v literaturě pro výuku jazyka DAX.
Seznámení se základy jazyka DAX v Power BI Desktopu
služba Power BI a Power BI Desktop
Přečtěte si nebo se podívejte na "Jak navrhovat vizuálně působivé sestavy (a řídicí panely)"
Člen komunity Miguel Myers je datový vědec a grafický návrhář.
Zamyslete se nad cílovou skupinou
Jaké jsou klíčové metriky, které vaší cílové skupině pomůžou při rozhodování? Jak se sestava použije? Co se naučilo nebo kulturní předpoklady můžou ovlivnit volby návrhu? Jaké informace musí být vaše cílová skupina úspěšná?
Kde se má sestava zobrazit? Pokud bude na velkém monitoru, můžete na něj umístit další obsah. Pokud si ji čtenáři budou prohlížet na tabletech, bude čitelnější méně vizualizací.
Řekněte příběh a udržujte ho na jedné obrazovce.
Každá stránka sestavy by měla na první pohled vyprávět příběh. Můžete se vyhnout posuvníkům na stránkách? Je sestava příliš nepotřebná nebo příliš zaneprázdněná? Odeberte všechny základní informace, které lze snadno číst a interpretovat.
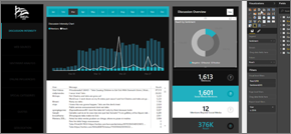
Zvětšujte nejdůležitější informace
Pokud mají text a vizualizace na stránce sestavy stejnou velikost, budou mít čtenáři potíže soustředit se na to, co je nejdůležitější. Vizualizace karet jsou například dobrým způsobem, jak zobrazit důležité číslo zřetelně:

Nezapomeňte ale poskytnout kontext.
Pomocí funkcí, jako jsou textová pole a popisy, můžete do vizualizací přidat kontext.
Vložte nejdůležitější informace do horního rohu.
Většinalidíchm souborům čte z horního do dolního rohu, takže na začátek umístěte nejvyšší úroveň podrobností a zobrazte další podrobnosti ve směru, kterým cílová skupina používá čtení (zleva doprava, zprava doleva).
Použijte správnou vizualizaci dat a naformátujte je pro snadné čtení.
Vyhněte se nejrůznějším vizualizacím. Vizualizace by měly nakreslit obrázek a být snadno čitelné a interpretované. U některých dat a vizualizací stačí jednoduchá grafická vizualizace. Jiná data ale můžou volat složitější vizualizaci – nezapomeňte použít názvy a popisky a další přizpůsobení, které čtenářům pomůžou.
- Při použití grafů, které zkreslují realitu, například prostorové grafy a grafy, které nezačínaly nulou, buďte opatrní. Mějte na paměti, že je pro lidský mozek obtížnější interpretovat kruhové tvary. Výsečové grafy, prstencové grafy, měřidla a jiné typy kruhových grafů můžou vypadat hezky, ale možná existuje jiný vizuál, který můžete použít?
- Buďte konzistentní s měřítky grafu na osách, řazením dimenzí grafu a také barvami používanými pro hodnoty dimenzí v grafech.
- Nezapomeňte zakódovat kvantitativní data pěkně. Při zobrazení čísel nepoužívejte maximálně tři nebo čtyři číslice. Zobrazí míry na jednu nebo dvě číslice vlevo od desetinné čárky a škálují se pro tisíce nebo miliony. Například 3,4 milionu není 3 400 000.
- Snažte se vyhnout kombinování úrovní přesnosti a času. Ujistěte se, že časové rámce jsou dobře srozumitelné. Nemáte jeden graf, který má poslední měsíc vedle vyfiltrovaných grafů z konkrétního měsíce v roce.
- Snažte se také vyhnout kombinování velkých a malých měr ve stejném měřítku, jako je spojnicový nebo pruhový graf. Jedna míra může být například v milionech a druhá míra v tisících. V takovém velkém měřítku je obtížné vidět rozdíly v míře, která je v tisících. Pokud potřebujete kombinovat vizualizaci, jako je kombinovaný graf, který umožňuje použití druhé osy.
- Vyhněte se nepotřebným grafům popisky dat, které nejsou potřeba. Hodnoty v pruhových grafech, pokud jsou dostatečně velké, jsou obvykle srozumitelné bez zobrazení skutečného čísla.
- Věnujte pozornost způsobu řazení grafů. Pokud chcete upozornit na nejvyšší nebo nejnižší číslo, seřaďte je podle míry. Pokud chcete, aby lidé mohli rychle najít konkrétní kategorii v mnoha dalších kategoriích, seřaďte je podle osy.
- Výsečové grafy jsou nejlepší, pokud mají méně než osm kategorií. Vzhledem k tomu, že nemůžete porovnat hodnoty vedle sebe, je obtížnější porovnat hodnoty ve výsečovém grafu než v pruhových a sloupcových grafech. Výsečové grafy můžou být vhodné pro zobrazení vztahů mezi částmi, nikoli pro porovnání částí. Grafy měřidla jsou skvělé pro zobrazení aktuálního stavu v kontextu cíle.
Další pokyny specifické pro vizualizaci najdete v tématu Typy vizualizací v Power BI.
Další informace o návrhu řídicího panelu osvědčených postupů
Mezi některé z našich oblíbených knih patří:
- Storytelling with Data by Cole Nussbaumer Knafic
- Datové body od Nathan Yau
- Pravdivý umění Alberto Káhira
- Teď ji uvidíte od Stephena Fewa
- Představování informací edwardem Tuftem
- Advanced Presentations Design by Andrew Abela
Související obsah
- Návrh efektivních sestav v Power BI
- Základní koncepty pro návrháře v služba Power BI
- Sestavy v Power BI
Máte ještě další otázky? Zeptejte se Komunita Power BI
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro