Architektura řešení BI ve center of Excellence
Tento článek se zaměřuje na IT profesionály a správce IT. Seznámíte se s architekturou řešení BI v COE a o různých používaných technologiích. Mezi technologie patří Azure, Power BI a Excel. Společně je můžete využít k poskytování škálovatelné cloudové platformy BI řízené daty.
Návrh robustní platformy BI je poněkud jako vytvoření mostu; most, který spojuje transformovaná a rozšířená zdrojová data s příjemci dat. Návrh takové složité struktury vyžaduje technické myšlení, i když to může být jedna z nejkreavějších a odměňující it architektur, které byste mohli navrhnout. Ve velké organizaci se architektura řešení BI může skládat z těchto:
- Zdroje dat
- Příjem dat
- Příprava velkých objemů dat / dat
- Datový sklad
- Sémantické modely BI
- Sestavy
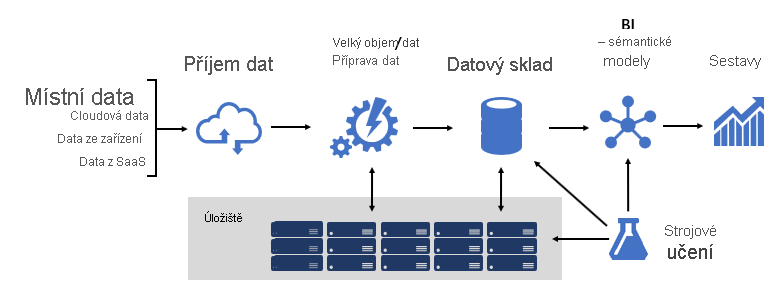
Platforma musí podporovat specifické požadavky. Konkrétně musí škálovat a provádět, aby splňoval očekávání obchodních služeb a spotřebitelů dat. Zároveň musí být zabezpečené od samého začátku. A musí být dostatečně odolný, aby se přizpůsobil změnám – protože je jisté, že v čase musí být nové údaje a předmětné oblasti uvedeny do online režimu.
Architektury
V Microsoftu jsme od počátku přijali přístup podobný systémům tím, že investovali do vývoje architektury. Architektury technických a obchodních procesů zvyšují opakované použití návrhu a logiky a poskytují konzistentní výsledek. Nabízejí také flexibilitu v architektuře využívající mnoho technologií a zjednodušují a snižují technickou režii prostřednictvím opakovatelných procesů.
Zjistili jsme, že dobře navržené architektury zvyšují přehled o rodokmenu dat, analýze dopadu, údržbě obchodní logiky, správě taxonomie a správě zásad správného řízení. Vývoj se také zrychlil a spolupráce napříč velkými týmy se stala rychlejší a efektivnější.
V tomto článku si popíšeme několik našich architektur.
Datové modely
Datové modely poskytují kontrolu nad strukturou a přístupem k datům. Pro obchodní služby a uživatele dat jsou datové modely jejich rozhraní s platformou BI.
Platforma BI může poskytovat tři různé typy modelů:
- Podnikové modely
- Sémantické modely BI
- Modely strojového Učení (ML)
Podnikové modely
Podnikové modely vytvářejí a spravují it architekti. Někdy se označují jako dimenzionální modely nebo datová tržiště. Data se obvykle ukládají v relačním formátu jako tabulky dimenzí a faktů. Tyto tabulky ukládají vyčištěná a rozšířená data konsolidovaná z mnoha systémů a představují autoritativní zdroj pro vytváření sestav a analýzy.
Podnikové modely poskytují konzistentní a jediný zdroj dat pro vytváření sestav a BI. Sestavují se jednou a sdílí se jako firemní standard. Zásady správného řízení zajišťují zabezpečení dat, takže přístup k citlivým sadám dat, jako jsou informace o zákaznících nebo finanční údaje, je omezený na základě potřeb. Přijmou zásady vytváření názvů, které zajišťují konzistenci, a tím dále získají důvěryhodnost údajů a kvalitu.
V cloudové platformě BI je možné podnikové modely nasadit do fondu Synapse SQL ve službě Azure Synapse. Fond Synapse SQL se pak stane jedinou verzí pravdy, na které se organizace může spolehnout, a získat tak rychlé a robustní přehledy.
Sémantické modely BI
Sémantické modely BI představují sémantickou vrstvu nad podnikovými modely. Vytvářejí a spravují je vývojáři BI a podnikoví uživatelé. Vývojáři BI vytvářejí základní sémantické modely BI, které vytvářejí data z podnikových modelů. Podnikoví uživatelé můžou vytvářet menší, nezávislé modely nebo můžou rozšířit základní sémantické modely BI s využitím oddělení nebo externích zdrojů. Sémantické modely BI se často zaměřují na jednu předmětnou oblast a často se často sdílejí.
Obchodní funkce nejsou povolené jenom daty, ale sémantické modely BI, které popisují koncepty, vztahy, pravidla a standardy. Představují tak intuitivní a snadno pochopitelné struktury, které definují relace dat a zapouzdřují obchodní pravidla jako výpočty. Můžou také vynucovat jemně odstupňovaná oprávnění k datům a zajistit tak správným lidem přístup ke správným datům. Důležité je, že urychlují výkon dotazů a poskytují extrémně rychlou interaktivní analýzu – i přes terabajty dat. Podobně jako u podnikových modelů přijímají sémantické modely BI konvence vytváření názvů, které zajišťují konzistenci.
Vývojáři BI můžou v cloudové platformě BI nasazovat sémantické modely BI do azure Analysis Services, kapacitPower BI Premium kapacit Microsoft Fabric.
Důležité
Někdy se tento článek týká Power BI Premium nebo jejích předplatných kapacity (SKU P). Mějte na paměti, že Microsoft v současné době konsoliduje možnosti nákupu a vyřazuje Power BI Premium na skladové položky kapacity. Místo toho by měli noví a stávající zákazníci zvážit nákup předplatných kapacity Fabric (SKU F).
Další informace najdete v tématu Důležité aktualizace týkající se licencování Power BI Premium a nejčastějších dotazů k Power BI Premium.
Pokud se používá jako vrstva pro vytváření sestav a analýzy, doporučujeme ji nasadit do Power BI. Tyto produkty podporují různé režimy úložiště, což umožňuje tabulkám datového modelu ukládat data do mezipaměti nebo používat DirectQuery, což je technologie, která předává dotazy podkladovému zdroji dat. DirectQuery je ideální režim úložiště, když tabulky modelů představují velké objemy dat nebo je potřeba dodávat výsledky téměř v reálném čase. Tyto dva režimy úložiště je možné kombinovat: Složené modely kombinují tabulky, které používají různé režimy úložiště v jednom modelu.
U silně dotazovaných modelů je možné Azure Load Balancer použít k rovnoměrné distribuci zatížení dotazů mezi repliky modelu. Umožňuje také škálovat aplikace a vytvářet vysoce dostupné sémantické modely BI.
Modely Machine Learning
Modely strojového Učení (ML) vytvářejí a spravují datoví vědci. Většinou se vyvíjejí z nezpracovaných zdrojů v datovém jezeře.
Vytrénované modely ML můžou odhalit vzory v datech. V mnoha případech se tyto vzory dají použít k předpovědím, které lze použít k obohacení dat. Například nákupní chování se dá použít k predikci četnosti změn zákazníků nebo segmentování zákazníků. Výsledky predikce je možné přidat do podnikových modelů, které umožňují analýzu podle segmentu zákazníků.
V cloudové platformě BI můžete pomocí služby Azure Machine Učení trénovat, nasazovat, automatizovat, spravovat a sledovat modely ML.
Datový sklad
Jádrem platformy BI je datový sklad, který hostuje vaše podnikové modely. Je to zdroj schválených dat – jako systém záznamů a jako centrum – sloužící podnikovým modelům pro vytváření sestav, BI a datové vědy.
Řada obchodních služeb, včetně obchodních aplikací (LOB), může spoléhat na datový sklad jako autoritativní a řízený zdroj podnikových znalostí.
V Microsoftu je náš datový sklad hostovaný v Azure Data Lake Storage Gen2 (ADLS Gen2) a Azure Synapse Analytics.
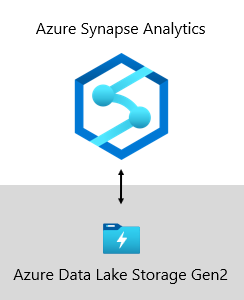
- ADLS Gen2 představuje Azure Storage jako základ pro vytváření podnikových datových jezer v Azure. Je navržená tak, aby obsluha několika petabajtů informací při zachování stovek gigabitů propustnosti. Nabízí také nízkonákladovou kapacitu úložiště a transakce. Navíc podporuje přístup kompatibilní s Hadoopem, který umožňuje spravovat a přistupovat k datům stejně jako u systému souborů HDFS (Hadoop Distributed File System). Azure HDInsight, Azure Databricks a Azure Synapse Analytics mají ve skutečnosti přístup k datům uloženým v ADLS Gen2. V platformě BI je tedy vhodné ukládat nezpracovaná zdrojová data, částečně zpracovávaná nebo fázovaná data a data připravená pro produkční prostředí. Používáme ho k ukládání všech obchodních dat.
- Azure Synapse Analytics je analytická služba, která spojuje podnikové datové sklady a analýzy velkých objemů dat. Dává vám možnost dotazovat se na data podle toho, jak vám to vyhovuje, s využitím bezserverové architektury na vyžádání, nebo zřízených prostředků, a to ve velkém měřítku. Synapse SQL, což je součást Azure Synapse Analytics, podporuje kompletní analýzy založené na T-SQL, takže je ideální hostovat podnikové modely, které tvoří tabulky dimenzí a faktů. Tabulky je možné efektivně načíst z ADLS Gen2 pomocí jednoduchých dotazů Polybase T-SQL . Pak máte možnost MPP spouštět vysoce výkonné analýzy.
Architektura stroje obchodních pravidel
Vyvinuli jsme architekturu BRE (Business Rules Engine ) pro katalog veškeré obchodní logiky, kterou je možné implementovat ve vrstvě datového skladu. Bre může znamenat mnoho věcí, ale v kontextu datového skladu je užitečné vytvářet počítané sloupce v relačních tabulkách. Tyto počítané sloupce jsou obvykle reprezentovány jako matematické výpočty nebo výrazy pomocí podmíněných příkazů.
Záměrem je rozdělit obchodní logiku od základního kódu BI. Obchodní pravidla jsou tradičně pevně zakódovaná do uložených procedur SQL, takže často vede k tomu, že je při změně obchodních potřeb mnoho úsilí. V bre se obchodní pravidla definují jednou a používají se vícekrát, když se použijí na různé entity datového skladu. Pokud je potřeba změnit logiku výpočtu, je potřeba ji aktualizovat pouze na jednom místě a ne v mnoha uložených procedurách. Existuje také vedlejší výhoda: architektura BRE zvyšuje transparentnost a přehled o implementované obchodní logice, která se dá zpřístupnit prostřednictvím sady sestav, které vytvářejí dokumentaci k samoobslužné aktualizaci.
Zdroje dat
Datový sklad může konsolidovat data prakticky z jakéhokoli zdroje dat. Je většinou postavená na zdrojích obchodních dat, což jsou běžně relační databáze, které ukládají data specifická pro předměty pro prodej, marketing, finance atd. Tyto databáze můžou být hostované v cloudu nebo se můžou nacházet místně. Jiné zdroje dat můžou být založené na souborech, zejména webové protokoly nebo data IOT ze zařízení. Kromě toho je možné data zdrojovat od dodavatelů SaaS (Software-as-a-Service).
V Microsoftu některé z našich interních systémů vypíše provozní data přímo do ADLS Gen2 pomocí nezpracovaných formátů souborů. Kromě datového jezera tvoří další zdrojové systémy relační obchodní aplikace, excelové sešity, další zdroje založené na souborech a hlavní Správa dat (MDM) a vlastní úložiště dat. Úložiště MDM nám umožňují spravovat hlavní data, abychom zajistili autoritativní, standardizované a ověřené verze dat.
Příjem dat
Pravidelně a podle rytmu firmy se data ingestují ze zdrojových systémů a načítají se do datového skladu. Může to být jednou denně nebo častěji. Příjem dat se zabývá extrakcí, transformací a načítáním dat. Nebo možná jinak zaokrouhlit: extrahování, načítání a následné transformace dat. Rozdíl spočívá v tom, kde se transformace provádí. Transformace se použijí k vyčištění, přizpůsobení, integraci a standardizaci dat. Další informace najdete v tématu Extrakce, transformace a načítání (ETL).
Cílem je nakonec načíst správná data do podnikového modelu co nejrychleji a co nejefektivněji.
V Microsoftu používáme Azure Data Factory (ADF). Služby se používají k plánování a orchestraci ověření dat, transformací a hromadného načítání z externích zdrojových systémů do datového jezera. Spravuje se vlastními architekturami, aby zpracovávala data paralelně a ve velkém měřítku. Kromě toho se provádí komplexní protokolování, které podporuje řešení potíží, monitorování výkonu a spouštění oznámení výstrah při splnění konkrétních podmínek.
Azure Databricks – analytická platforma založená na Apache Sparku optimalizovaná pro platformu cloudových služeb Azure – mezitím provádí transformace speciálně pro datové vědy. Sestavuje a spouští modely ML také pomocí poznámkových bloků Pythonu. Skóre z těchto modelů ML se načtou do datového skladu a integrují předpovědi s podnikovými aplikacemi a sestavami. Vzhledem k tomu, že Azure Databricks přistupuje k souborům Data Lake přímo, eliminuje nebo minimalizuje potřebu kopírování nebo získávání dat.
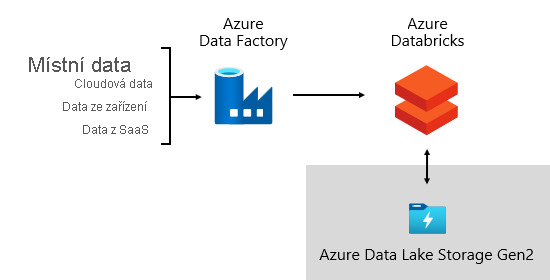
Architektura příjmu dat
Jako sadu konfiguračních tabulek a postupů jsme vyvinuli architekturu pro příjem dat. Podporuje přístup řízený daty k získání velkých objemů dat s vysokou rychlostí a s minimálním kódem. Stručně řečeno, tato architektura zjednodušuje proces získávání dat pro načtení datového skladu.
Architektura závisí na konfiguračních tabulkách, které ukládají informace o zdroji dat a cíli dat, jako je typ zdroje, server, databáze, schéma a podrobnosti související s tabulkami. Tento přístup k návrhu znamená, že nemusíme vyvíjet konkrétní kanály ADF ani balíčky SSIS (SQL Server Integration Services). Místo toho jsou procedury napsané v jazyce podle našeho výběru k vytvoření kanálů ADF, které se dynamicky generují a spouštějí za běhu. Získávání dat se tedy stává konfiguračním cvičením, které je snadno zprovozněno. Tradičně by vyžadovalo rozsáhlé vývojové prostředky k vytvoření pevně zakódovaných balíčků ADF nebo SSIS.
Architektura příjmu dat byla navržena tak, aby zjednodušila proces zpracování změn nadřazeného zdrojového schématu. Při zjištění změn schématu za účelem získání nově přidaných atributů ve zdrojovém systému je snadné aktualizovat konfigurační data – ručně nebo automaticky.
Architektura orchestrace
Vyvinuli jsme architekturu orchestrace pro zprovoznění a orchestraci datových kanálů. Používá návrh řízený daty, který závisí na sadě konfiguračních tabulek. Tyto tabulky ukládají metadata popisující závislosti kanálu a způsob mapování zdrojových dat na cílové datové struktury. Investice do vývoje tohoto adaptivního rámce se od té doby zaplatila za sebe; Už není nutné pevně zakódovat každý přesun dat.
Úložiště dat
Datové jezero může ukládat velké objemy nezpracovaných dat pro pozdější použití spolu s přípravnými transformacemi dat.
V Microsoftu jako jediný zdroj pravdy používáme ADLS Gen2. Ukládá nezpracovaná data společně s fázovanými daty a daty připravenými pro produkční prostředí. Poskytuje vysoce škálovatelné a nákladově efektivní řešení data lake pro analýzy velkých objemů dat. Kombinace výkonu vysoce výkonného systému souborů s obrovským škálováním je optimalizovaná pro úlohy analýzy dat, čímž se zrychluje doba získání přehledu.
ADLS Gen2 poskytuje to nejlepší ze dvou světů: je to blob storage a vysoce výkonný obor názvů systému souborů, který konfigurujeme s jemně odstupňovanými přístupovými oprávněními.
Zpřesněná data se pak ukládají do relační databáze, aby poskytovala vysoce výkonné vysoce škálovatelné úložiště dat pro podnikové modely s možnostmi zabezpečení, zásad správného řízení a možností správy. Datová tržiště specifická pro konkrétní předmět jsou uložená ve službě Azure Synapse Analytics, která jsou načtená dotazy Azure Databricks nebo Polybase T-SQL.
Spotřeba dat
Ve vrstvě vytváření sestav obchodní služby využívají podniková data ze zdrojového datového skladu. Přistupují také k datům přímo v datovém jezeře pro úlohy ad hoc analýzy nebo datových věd.
Jemně odstupňovaná oprávnění se vynucují ve všech vrstvách: v data lake, podnikových modelech a sémantických modelech BI. Oprávnění zajišťují, aby uživatelé dat viděli jenom data, ke kterým mají oprávnění k přístupu.
V Microsoftu používáme sestavy a řídicí panely Power BI a stránkované sestavy Power BI. Některé sestavy a ad hoc analýzy se provádějí v Excelu , zejména pro finanční sestavy.
Publikujeme slovníky dat, které poskytují referenční informace o našich datových modelech. Jsou zpřístupněny našim uživatelům, aby mohli zjišťovat informace o naší platformě BI. Slovníky dokumentují návrhy modelů a poskytují popisy entit, formátů, struktury, rodokmenu dat, relací a výpočtů. Azure Data Catalog používáme k tomu, aby byly naše zdroje dat snadno zjistitelné a srozumitelné.
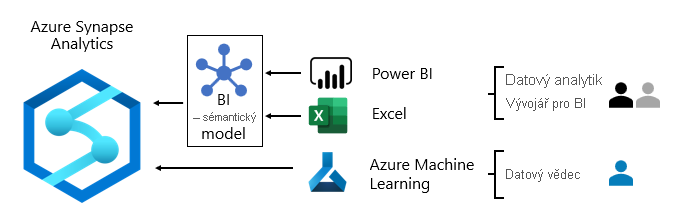
Vzory spotřeby dat se obvykle liší v závislosti na roli:
- Datoví analytici se připojují přímo k základním sémantickým modelům BI. Pokud základní sémantické modely BI obsahují všechna data a logiku, které potřebují, používají živá připojení k vytváření sestav a řídicích panelů Power BI. Když potřebují rozšířit modely o data oddělení, vytvoří složené modely Power BI. Pokud potřebujete sestavy ve stylu tabulky, používají Excel k vytváření sestav založených na základních sémantických modelech BI nebo sémantických modelech BI oddělení.
- Vývojáři BI a autoři provozních sestav se připojují přímo k podnikovým modelům. K vytváření analytických sestav živého připojení používají Power BI Desktop. Můžou také vytvářet sestavy BI provozního typu jako stránkované sestavy Power BI, psát nativní dotazy SQL pro přístup k datům z podnikových modelů Azure Synapse Analytics pomocí T-SQL nebo sémantických modelů Power BI pomocí jazyka DAX nebo MDX.
- Datoví vědci se připojují přímo k datům v datovém jezeře. Používají poznámkové bloky Azure Databricks a Python k vývoji modelů ML, které jsou často experimentální a vyžadují speciální dovednosti pro produkční použití.
Související obsah
Další informace o tomto článku najdete v následujících zdrojích informací:
- Plán přechodu na prostředky infrastruktury: Center of Excellence
- Enterprise BI v Azure s využitím Azure Synapse Analytics
- Otázky? Zkuste se zeptat Komunita Power BI
- Návrhy? Přispívání nápadů ke zlepšení Power BI
Profesionální služby
Certifikovaní partneři Power BI jsou k dispozici, aby pomohli vaší organizaci uspět při nastavování COE. Můžou vám poskytnout nákladově efektivní trénování nebo audit dat. Pokud chcete zapojit partnera Power BI, navštivte portál pro partnery Power BI.
Můžete se také spojit se zkušenými konzultačními partnery. Můžou vám pomoct vyhodnotit, vyhodnotit nebo implementovat Power BI.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro