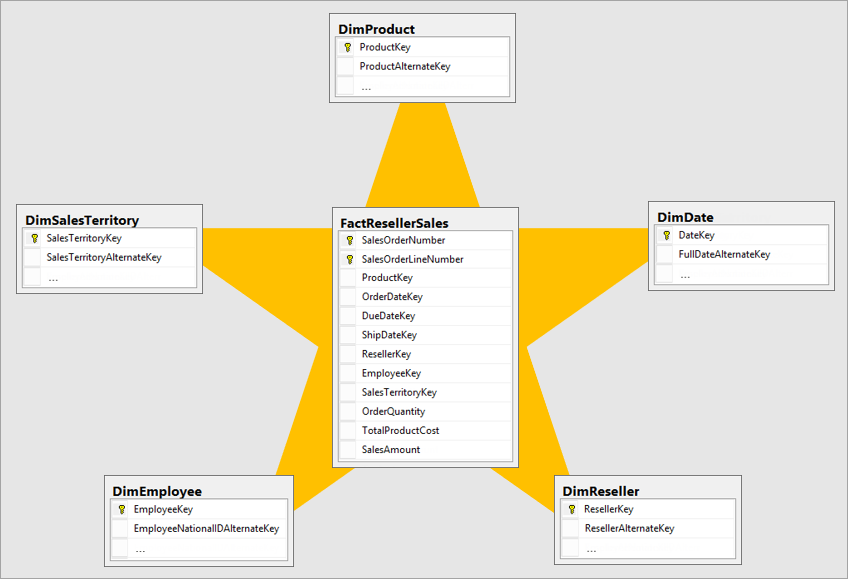
Forstå stjerneskemaet og vigtigheden af Power BI
Denne artikel henvender sig til Power BI Desktop-dataudformere. Den beskriver design af stjerneskemaer og dens relevans for udvikling af Power BI-datamodeller, der er optimeret til ydeevne og anvendelighed.
Denne artikel er ikke beregnet til at give en komplet diskussion om stjerneskemadesign. Du kan finde flere oplysninger i publiceret indhold, f.eks . The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling (3. udgave, 2013) af Ralph Kimball og andre.
Oversigt over stjerneskema
Stjerneskema er en moden modelmetode, der er almindeligt anvendt af relationsdata warehouses. Det kræver, at modeludviklere klassificerer deres modeltabeller som enten dimension eller fakta.
Dimensionstabeller beskriver forretningsobjekter – de ting, du modellerer. Objekter kan omfatte produkter, personer, steder og begreber, herunder selve tiden. Den mest ensartede tabel, du finder i et stjerneskema, er en datodimensionstabel. En dimensionstabel indeholder en nøglekolonne (eller kolonner), der fungerer som et entydigt id og beskrivende kolonner.
Faktatabeller gemmer observationer eller hændelser og kan være salgsordrer, lageropgørelser, valutakurser, temperaturer osv. En faktatabel indeholder kolonner med dimensionsnøgler, der er relateret til dimensionstabeller, og numeriske målingskolonner. Dimensionsnøglekolonnerne bestemmer dimensionaliteten af en faktatabel, mens værdierne for dimensionsnøglen bestemmer granulariteten af en faktatabel. Overvej f.eks. en faktatabel, der er designet til at gemme salgsmål, der har to dimensionsnøglekolonner Dato og ProductKey. Det er nemt at forstå, at tabellen har to dimensioner. Granulariteten kan dog ikke bestemmes uden at tage dimensionsnøgleværdierne i betragtning. I dette eksempel skal du overveje, at de værdier, der er gemt i kolonnen Dato, er den første dag i hver måned. I dette tilfælde er granulariteten på månedsproduktniveau.
Dimensionstabeller indeholder generelt et relativt lille antal rækker. Faktatabeller kan derimod indeholde et meget stort antal rækker og fortsætte med at vokse over tid.
Normalisering vs. denormalisering
For at forstå nogle stjerneskemabegreber, der er beskrevet i denne artikel, er det vigtigt at kende to begreber: normalisering og denormalisering.
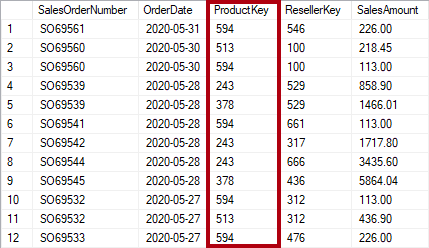
Normalisering er det ord, der bruges til at beskrive data, der er gemt på en måde, der reducerer tilbagevendende data. Overvej en tabel over produkter, der har en entydig nøgleværdikolonne, f.eks. produktnøglen, og yderligere kolonner, der beskriver produktegenskaber, herunder produktnavn, kategori, farve og størrelse. En salgstabel anses for at være normaliseret, når den kun gemmer nøgler, f.eks. produktnøglen. På følgende billede kan du se, at det kun er kolonnen ProductKey , der registrerer produktet.
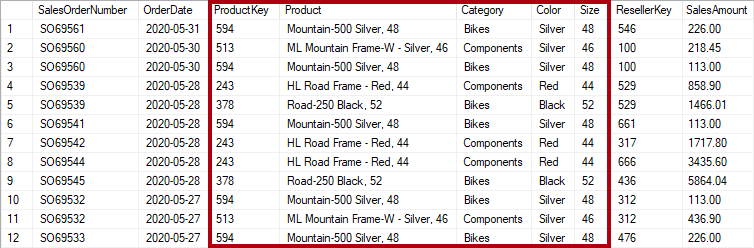
Men hvis salgstabellen gemmer produktoplysninger ud over nøglen, anses den for at være denormaliseret. På følgende billede kan du se, at ProductKey og andre produktrelaterede kolonner registrerer produktet.
Når du henter data fra en eksportfil eller dataudtrækning, er det sandsynligt, at det repræsenterer et deormaliseret datasæt. I dette tilfælde skal du bruge Power Query til at transformere og forme kildedataene til flere normaliserede tabeller.
Som beskrevet i denne artikel skal du bestræbe dig på at udvikle optimerede Power BI-datamodeller med tabeller, der repræsenterer normaliserede fakta- og dimensionsdata. Der er dog én undtagelse, hvor en snowflake-dimension skal denormaliseres for at oprette en enkelt modeltabel.
Relevans for stjerneskemaer i Power BI-modeller
Design af stjerneskemaer og mange relaterede begreber, der introduceres i denne artikel, er yderst relevante for udvikling af Power BI-modeller, der er optimeret til ydeevne og anvendelighed.
Overvej, at hver power BI-rapportvisualisering genererer en forespørgsel, der sendes til Power BI-modellen (som Power BI-tjeneste kalder en semantisk model – tidligere kaldet et datasæt). Disse forespørgsler bruges til at filtrere, gruppere og opsummere modeldata. En veldesignet model er derfor en model, der indeholder tabeller til filtrering og gruppering og tabeller til opsummering. Dette design passer godt sammen med principper for stjerneskemaer:
- Dimensionstabeller understøtter filtrering og gruppering
- Faktatabeller understøtter opsummering
Der er ingen tabelegenskab, som modeludviklere har angivet til at konfigurere tabeltypen som dimension eller fakta. Det bestemmes faktisk af modelrelationerne. En modelrelation etablerer en filteroverførselssti mellem to tabeller, og det er egenskaben Kardinalitet for den relation, der bestemmer tabeltypen. En almindelig relationskardinalitet er en til mange eller den omvendte mange til en. "en"-siden er altid en tabel af dimensionstypen, mens "mange"-siden altid er en tabel af faktatypen. Du kan få flere oplysninger om relationer under Modelrelationer i Power BI Desktop.

Et velstruktureret modeldesign skal indeholde tabeller, der enten er tabeller af dimensionstypen eller tabeller af faktatypen. Undgå at blande de to typer sammen for en enkelt tabel. Vi anbefaler også, at du bestræber dig på at levere det rigtige antal tabeller med de rette relationer på plads. Det er også vigtigt, at tabeller af faktatypen altid indlæser data på et ensartet detaljeringstegn.
Endelig er det vigtigt at forstå, at optimalt modeldesign er en del af videnskab og delkunst. Nogle gange kan du bryde med god vejledning, når det giver mening at gøre det.
Der er mange yderligere begreber, der er relateret til stjerneskemadesign, som kan anvendes på en Power BI-model. Disse begreber omfatter:
- Foranstaltninger
- Erstatningsnøgler
- Snowflake-dimensioner
- Dimensioner med forskellige roller
- Dimensioner, der langsomt ændres
- Dimensionerne for uønsket post
- Degenererede dimensioner
- Faktaløse faktatabeller
Målinger
I design af stjerneskema er en måling en kolonne i faktatabellen, der gemmer værdier, der skal opsummeres.
I en Power BI-model har en måling en anden - men lignende - definition. Det er en formel, der er skrevet i DAX (Data Analysis Expressions), som giver opsummering. Målingsudtryk bruger ofte DAX-sammenlægningsfunktioner som SUM, MIN, MAX, AVERAGE osv. til at producere et skalarværdiresultat på forespørgselstidspunktet (værdier gemmes aldrig i modellen). Målingsudtryk kan variere fra simple kolonnesammenlægninger til mere avancerede formler, der tilsidesætter filterkontekst og/eller relationsoverførsel. Du kan få flere oplysninger i artiklen Grundlæggende om DAX i Power BI Desktop .
Det er vigtigt at forstå, at Power BI-modeller understøtter en anden metode til at opnå opsummering. Alle kolonner – og typisk numeriske kolonner – kan opsummeres af en rapportvisualisering eller Q&A. Disse kolonner kaldes implicitte målinger. De gør det praktisk for dig som modeludvikler, da du i mange tilfælde ikke behøver at oprette målinger. Kolonnen Sales Amount for Adventure Works-forhandlersalg kan f.eks. opsummeres på mange måder (sum, antal, gennemsnit, median, min. maks. osv.), uden at det er nødvendigt at oprette en måling for hver mulig sammenlægningstype.
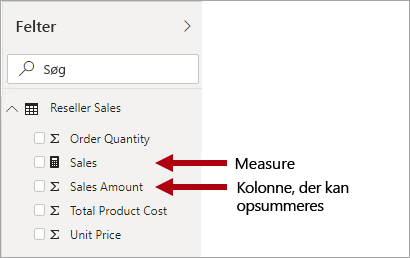
Der er dog tre overbevisende grunde til, at du opretter målinger, selv for simple opsummeringer på kolonneniveau:
- Når du ved, at rapportforfatterne forespørger modellen ved hjælp af FLERdimensionelle udtryk (MDX), skal modellen indeholde eksplicitte målinger. Eksplicitte målinger defineres ved hjælp af DAX. Denne designtilgang er yderst relevant, når der forespørges om et Power BI-datasæt ved hjælp af MDX, fordi MDX ikke kan opnå opsummering af kolonneværdier. MDX bruges især, når du udfører Analysér i Excel, fordi pivottabeller udsteder MDX-forespørgsler.
- Når du ved, at rapportforfatterne opretter sideinddelte Power BI-rapporter ved hjælp af MDX-forespørgselsdesigneren, skal modellen indeholde eksplicitte målinger. Det er kun MDX-forespørgselsdesigneren, der understøtter serveraggregater. Så hvis rapportforfattere skal have målinger evalueret af Power BI (i stedet for af det sideinddelte rapportprogram), skal de bruge MDX-forespørgselsdesigneren.
- Når du har brug for at sikre, at rapportforfatterne kun kan opsummere kolonner på bestemte måder. Kolonnen Unit Price for forhandlersalg (som repræsenterer en enhedssats) kan f.eks. opsummeres, men kun ved hjælp af bestemte sammenlægningsfunktioner. Det bør aldrig lægges sammen, men det er hensigtsmæssigt at opsummere ved hjælp af andre sammenlægningsfunktioner, f.eks. min., maks., gennemsnit osv. I dette tilfælde kan modeludvikleren skjule kolonnen Unit Price og oprette målinger for alle relevante sammenlægningsfunktioner.
Denne designtilgang fungerer godt for rapporter, der er oprettet i Power BI-tjeneste og for Q&A. Direkte forbindelser i Power BI Desktop gør det dog muligt for rapportforfattere at vise skjulte felter i ruden Felter , hvilket kan resultere i omgåelse af denne designtilgang.
Erstatningsnøgler
En surrogatnøgle er et entydigt id, som du føjer til en tabel for at understøtte modellering af stjerneskemaer. Den er pr. definition ikke defineret eller gemt i kildedataene. Surrogatnøgler føjes ofte til dimensionstabeller for relationsdata warehouse for at angive et entydigt id for hver række i dimensionstabellen.
Power BI-modelrelationer er baseret på en enkelt entydig kolonne i én tabel, som overfører filtre til en enkelt kolonne i en anden tabel. Når en tabel af dimensionstypen i din model ikke indeholder en enkelt entydig kolonne, skal du tilføje et entydigt id for at blive "en"-siden af en relation. I Power BI Desktop kan du nemt opfylde dette krav ved at oprette en Power Query-indekskolonne.

Du skal flette denne forespørgsel med forespørgslen "mange", så du også kan føje indekskolonnen til den. Når du indlæser disse forespørgsler i modellen, kan du derefter oprette en en til mange-relation mellem modeltabellerne.
Snowflake-dimensioner
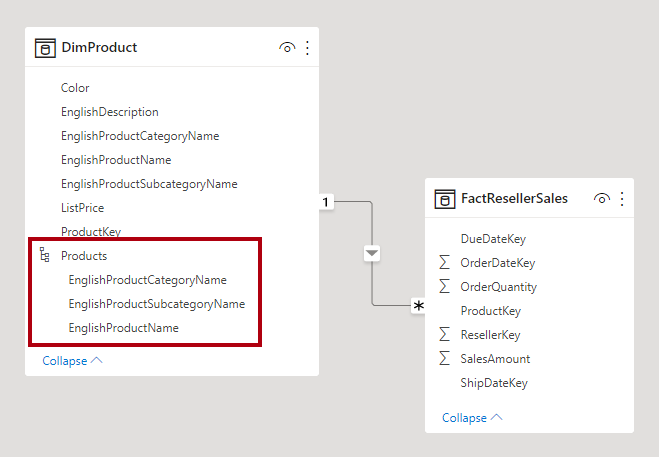
En snowflake-dimension er et sæt normaliserede tabeller for en enkelt forretningsenhed. Adventure Works klassificerer f.eks. produkter efter kategori og underkategori. Produkter tildeles til underkategorier, og underkategorier tildeles igen til kategorier. I det relationelle data warehouse Adventure Works normaliseres og gemmes produktdimensionen i tre relaterede tabeller: DimProductCategory, DimProductSubcategory og DimProduct.
Hvis du bruger din fantasi, kan du forestille dig, at de normaliserede tabeller er placeret udad fra faktatabellen og danner et snefnugdesign.

I Power BI Desktop kan du vælge at efterligne et snowflake-dimensionsdesign (måske fordi dine kildedata gør) eller integrere (denormalisere) kildetabellerne i en enkelt modeltabel. Generelt opvejer fordelene ved en enkelt modeltabel fordelene ved flere modeltabeller. Den mest optimale beslutning kan afhænge af datamængderne og kravene til anvendelighed for modellen.
Når du vælger at efterligne et snowflake-dimensionsdesign:
- Power BI indlæser flere tabeller, hvilket er mindre effektivt fra lager- og ydeevneperspektiver. Disse tabeller skal indeholde kolonner, der understøtter modelrelationer, og det kan resultere i en større modelstørrelse.
- Længere overførselskæder for relationsfiltre skal gennemgås, hvilket sandsynligvis vil være mindre effektivt end filtre, der anvendes på en enkelt tabel.
- Ruden Felter præsenterer flere modeltabeller for rapportforfattere, hvilket kan resultere i en mindre intuitiv oplevelse, især når snowflake-dimensionstabeller kun indeholder én eller to kolonner.
- Det er ikke muligt at oprette et hierarki, der strækker sig over tabellerne.
Når du vælger at integrere i en enkelt modeltabel, kan du også definere et hierarki, der omfatter dimensionens højeste og laveste detaljering. Lagring af redundante denormaliserede data kan muligvis resultere i en øget modellagerstørrelse, især for meget store dimensionstabeller.
Dimensioner, der langsomt ændres
En dimension, der langsomt ændrer sig, er en dimension , der administrerer ændring af dimensionsmedlemmer korrekt over tid. Den gælder, når værdier for forretningsenheder ændres over tid og på ad hoc-måde. Et godt eksempel på en dimension, der langsomt ændrer sig, er en kundedimension, især kolonnerne med kontaktoplysninger, f.eks. mailadresse og telefonnummer. I modsætning hertil anses nogle dimensioner for at være hurtigt skiftende, når en dimensionsattribut ændres ofte, f.eks. en akties markedskurs. Den almindelige designtilgang i disse tilfælde er at gemme hurtigt skiftende attributværdier i en måling i faktatabellen.
Teorien om design af stjerneskemaer refererer til to almindelige SCD-typer: Type 1 og Type 2. En tabel af dimensionstypen kan være Type 1 eller Type 2 eller understøtte begge typer samtidigt for forskellige kolonner.
Type 1 SCD
Et type 1-scd afspejler altid de nyeste værdier, og når der registreres ændringer i kildedataene, overskrives dataene i dimensionstabellen. Denne designtilgang er almindelig for kolonner, der gemmer supplerende værdier, f.eks. en kundes mailadresse eller telefonnummer. Når en kundes mailadresse eller telefonnummer ændres, opdaterer dimensionstabellen kunderækken med de nye værdier. Det er, som om kunden altid har haft disse kontaktoplysninger.
En ikke-trinvis opdatering af en tabel af dimensionstypen power BI-model opnår resultatet af en type 1-scd. Tabeldataene opdateres for at sikre, at de nyeste værdier indlæses.
Type 2 SCD
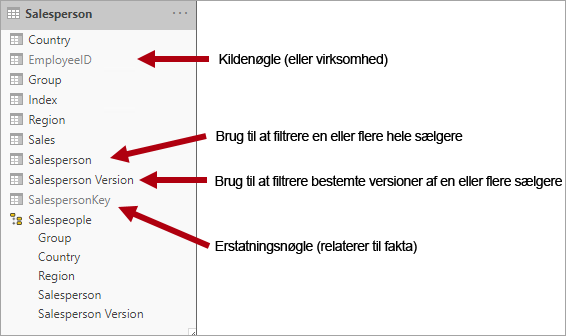
En type 2SCD understøtter versionering af dimensionsmedlemmer. Hvis kildesystemet ikke gemmer versioner, er det normalt indlæsningsprocessen for data warehouse, der registrerer ændringer og administrerer ændringen i en dimensionstabel korrekt. I dette tilfælde skal dimensionstabellen bruge en surrogatnøgle til at angive en entydig reference til en version af dimensionsmedlemmet. Den indeholder også kolonner, der definerer gyldigheden af datointervallet for versionen (f.eks. StartDate og EndDate) og muligvis en flagkolonne (f.eks. IsCurrent), så de nemt kan filtrere efter aktuelle dimensionsmedlemmer.
Adventure Works tildeler f.eks. sælgere til et salgsområde. Når en sælger flytter område, skal der oprettes en ny version af sælgeren for at sikre, at historiske fakta forbliver knyttet til det tidligere område. Dimensionstabellen skal indeholde versioner af sælgere og deres tilknyttede områder for at understøtte nøjagtig historisk analyse af salg efter sælger. Tabellen skal også indeholde værdier for start- og slutdato for at definere tids gyldighed. Aktuelle versioner kan definere en tom slutdato (eller 31-12-9999), hvilket angiver, at rækken er den aktuelle version. Tabellen skal også definere en surrogatnøgle, fordi forretningsnøglen (i denne forekomst medarbejder-id) ikke er entydig.
Det er vigtigt at forstå, at når kildedataene ikke gemmer versioner, skal du bruge et mellemliggende system (f.eks. et data warehouse) til at registrere og gemme ændringer. Indlæsningsprocessen for tabellen skal bevare eksisterende data og registrere ændringer. Når der registreres en ændring, skal indlæsningsprocessen for tabellen udløbe den aktuelle version. Disse ændringer registreres ved at opdatere værdien EndDate og indsætte en ny version, hvor værdien StartDate starter fra den forrige enddate-værdi . Relaterede fakta skal også bruge et tidsbaseret opslag til at hente den dimensionsnøgleværdi, der er relevant for faktadatoen. En Power BI-model, der bruger Power Query, kan ikke give dette resultat. Den kan dog indlæse data fra en forudinstalleret SCD Type 2-dimensionstabel.
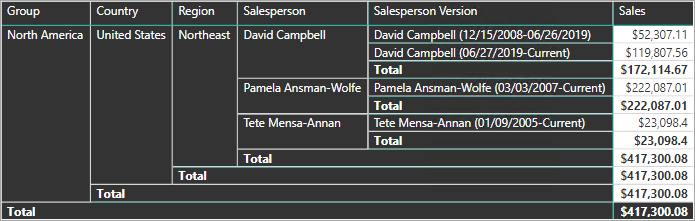
Power BI-modellen bør understøtte forespørgsler om historiske data for et medlem, uanset ændring, og for en version af medlemmet, som repræsenterer en bestemt tilstand for medlemmet i tide. I forbindelse med Adventure Works giver dette design dig mulighed for at forespørge sælgeren, uanset hvilken salgsregion der er tildelt, eller om en bestemt version af sælgeren.
For at opfylde dette krav skal dimensionstabellen for Power BI-modellen indeholde en kolonne til filtrering af sælgeren og en anden kolonne til filtrering af en bestemt version af sælgeren. Det er vigtigt, at versionskolonnen indeholder en ikke-tvetydig beskrivelse, f.eks. "Michael Blythe (15-12-2008-06-26-2019)" eller "Michael Blythe (aktuel)". Det er også vigtigt at oplære rapportforfattere og forbrugere i de grundlæggende funktioner i SCD Type 2, og hvordan du opnår relevante rapportdesign ved at anvende korrekte filtre.
Det er også en god designpraksis at inkludere et hierarki, der gør det muligt for visualiseringer at foretage detailudledning til versionsniveauet.
Dimensioner med forskellige roller
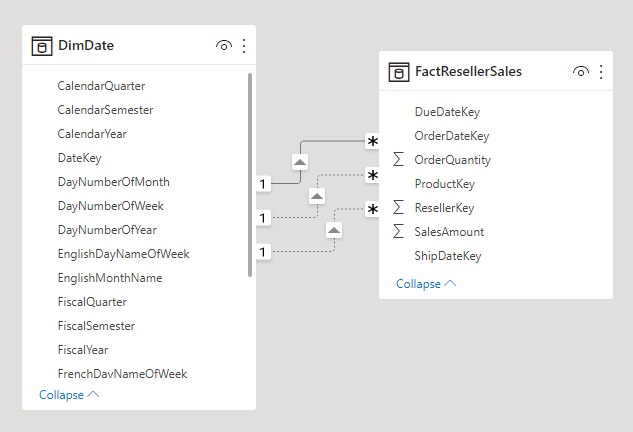
En dimension med forskellige roller er en dimension, der kan filtrere relaterede fakta forskelligt. I Adventure Works har datodimensionstabellen f.eks. tre relationer til fakta om forhandlersalg. Den samme dimensionstabel kan bruges til at filtrere fakta efter ordredato, afsendelsesdato eller leveringsdato.
I et data warehouse er den accepterede designmetode at definere en enkelt datodimensionstabel. På forespørgselstidspunktet oprettes datodimensionens "rolle" af den faktakolonne, du bruger til at joinforbinde tabellerne. Når du f.eks. analyserer salg efter ordredato, relaterer tabeljoinen til kolonnen med dato for forhandlersalgsordre.
I en Power BI-model kan dette design efterlignes ved at oprette flere relationer mellem to tabeller. I eksemplet med Adventure Works har tabellerne dato og forhandlersalg tre relationer. Selvom dette design er muligt, er det vigtigt at forstå, at der kun kan være én aktiv relation mellem to Power BI-modeltabeller. Alle resterende relationer skal angives til inaktive. Hvis du har en enkelt aktiv relation, betyder det, at der er en standardfilteroverførsel fra dato til forhandlersalg. I denne forekomst angives den aktive relation til det mest almindelige filter, der bruges af rapporter, som i Adventure Works er relationen for ordredatoen.
Den eneste måde at bruge en inaktiv relation på er ved at definere et DAX-udtryk, der bruger funktionen USERELATIONSHIP. I vores eksempel skal modeludvikleren oprette målinger for at muliggøre analyse af forhandlersalg efter afsendelsesdato og leveringsdato. Dette arbejde kan være kedeligt, især når forhandlertabellen definerer mange målinger. Det skaber også rod i ruden Felter med en overmængde af målinger. Der er også andre begrænsninger:
- Når rapportforfattere er afhængige af opsummering af kolonner i stedet for at definere målinger, kan de ikke opnå opsummering for de inaktive relationer uden at skrive en måling på rapportniveau. Målinger på rapportniveau kan kun defineres, når du opretter rapporter i Power BI Desktop.
- Med kun én aktiv relationssti mellem dato og forhandlersalg er det ikke muligt samtidig at filtrere forhandlersalg efter forskellige typer datoer. Du kan f.eks. ikke oprette en visualisering, der afbilder ordredatosalg efter leveret salg.
For at overvinde disse begrænsninger er en almindelig Power BI-modelleringsteknik at oprette en tabel af dimensionstypen for hver forekomst af rollespil. Du opretter typisk de ekstra dimensionstabeller som beregnede tabeller ved hjælp af DAX. Ved hjælp af beregnede tabeller kan modellen indeholde en datotabel , en tabel af typen Ship Date og en tabel af typen Leveringsdato , der hver især har en enkelt og aktiv relation til deres respektive kolonner i forhandlersalgstabellen.
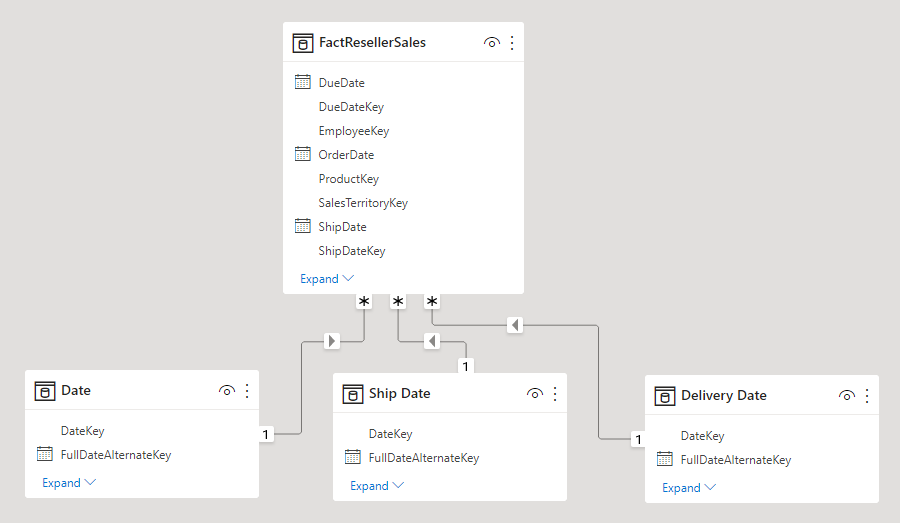
Denne designtilgang kræver ikke, at du definerer flere målinger for forskellige datoroller, og det giver mulighed for samtidig filtrering efter forskellige datoroller. En mindre pris, der skal betales med denne designtilgang, er, at der vil være duplikering af datodimensionstabellen, hvilket resulterer i en øget modellagerstørrelse. Da tabeller af dimensionstypen typisk gemmer færre rækker i forhold til tabeller af faktatypen, er det sjældent et problem.
Se følgende gode designpraksis, når du opretter tabeller af dimensionstypen model for hver rolle:
- Sørg for, at kolonnenavnene beskriver sig selv. Selvom det er muligt at have kolonnen Year i alle datotabeller (kolonnenavne er entydige i deres tabel), er det ikke selvbeskrivende som standard visualtitler. Overvej at omdøbe kolonner i hver dimensionsrolletabel, så tabellen Afsendelsesdato indeholder kolonnen Ship Year osv.
- Når det er relevant, skal du sørge for, at tabelbeskrivelser giver feedback til rapportforfattere (via værktøjstip i ruden Felter ) om, hvordan filteroverførsel er konfigureret. Denne klarhed er vigtig, når modellen indeholder en tabel med et generisk navn, f.eks . Dato, som bruges til at filtrere mange tabeller af faktatypen. Hvis denne tabel f.eks. har en aktiv relation til datokolonnen for forhandlersalgsordren, kan du overveje at angive en tabelbeskrivelse som "Filtrer forhandlersalg efter ordredato".
Du kan finde flere oplysninger under Vejledning til aktive i forhold til inaktive relationer.
Dimensionerne for uønsket post
En dimension for uønsket post er nyttig, når der er mange dimensioner, især bestående af få attributter (måske en), og når disse attributter har få værdier. Gode kandidater omfatter kolonner med ordrestatus eller kundedemografiske kolonner (køn, aldersgruppe osv.).
Designmålet for en uønsket dimension er at konsolidere mange "små" dimensioner i en enkelt dimension for både at reducere størrelsen på modellageret og også reducere rodet i ruden Felter ved at få færre modeltabeller.
En tabel over uønskede dimensioner er typisk det kartesiske produkt for alle medlemmer af dimensionsattributten med en surrogatnøglekolonne. Surrogatnøglen giver en entydig reference til hver række i tabellen. Du kan oprette dimensionen i et data warehouse eller ved hjælp af Power Query til at oprette en forespørgsel, der udfører komplette ydre forespørgselsjoinforbindelser og derefter tilføjer en surrogatnøgle (indekskolonne).
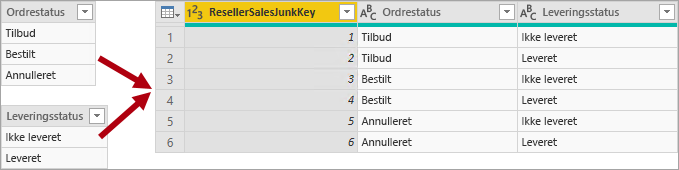
Du indlæser denne forespørgsel i modellen som en tabel af dimensionstypen. Du skal også flette denne forespørgsel med faktaforespørgslen, så indekskolonnen indlæses i modellen for at understøtte oprettelsen af en "en til mange"-modelrelation.
Degenerere dimensioner
En degenereret dimension refererer til en attribut i faktatabellen, der kræves til filtrering. I Adventure Works er forhandlersalgsordrenummeret et godt eksempel. I dette tilfælde giver det ikke god mening at oprette en uafhængig tabel, der kun består af denne ene kolonne, fordi det ville øge størrelsen på modellageret og resultere i rod i ruden Felter .
I Power BI-modellen kan det være hensigtsmæssigt at føje kolonnen med salgsordrenummer til tabellen af faktatypen for at tillade filtrering eller gruppering efter salgsordrenummer. Det er en undtagelse fra den tidligere introducerede regel, at du ikke skal blande tabeltyper (generelt skal modeltabeller være enten dimensionstabeller eller faktatabeller).
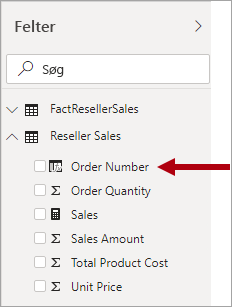
Men hvis tabellen Adventure Works-forhandleres salg indeholder kolonner med ordrenummer og ordrelinjenummer, og de er påkrævet til filtrering, vil en degenereret dimensionstabel være et godt design. Du kan finde flere oplysninger under En til en-relationsvejledning (Degenererede dimensioner).
Faktaløse faktatabeller
En faktaløs faktatabel indeholder ikke nogen målingskolonner. Den indeholder kun dimensionsnøgler.
En faktaløs faktatabel kan indeholde observationer, der er defineret af dimensionsnøgler. På en bestemt dato og et bestemt tidspunkt er en bestemt kunde f.eks. logget på dit websted. Du kan definere en måling for at tælle rækkerne i den faktaløse faktatabel for at analysere, hvornår og hvor mange kunder der er logget på.
En mere overbevisende brug af en faktafri faktatabel er at gemme relationer mellem dimensioner, og det er den power BI-modeldesigntilgang, vi anbefaler, at du definerer mange til mange-dimensionsrelationer. I et design af mange til mange-dimensionsrelationer kaldes den faktaløse faktatabel en brotabel.
Overvej f.eks., at sælgere kan tildeles til et eller flere salgsområder. Brotabellen vil være udformet som en faktaløs faktatabel, der består af to kolonner: sælgernøgle og områdenøgle. Dubletværdier kan gemmes i begge kolonner.

Denne mange til mange-designtilgang er veldokumenteret, og den kan opnås uden en brotabel. Brotabeltilgangen betragtes dog som den bedste praksis, når du relaterer to dimensioner. Du kan finde flere oplysninger i Vejledning til mange til mange-relationer (Relater to tabeller af dimensionstypen).
Relateret indhold
Du kan få flere oplysninger om stjerneskemadesign eller Power BI-modeldesign i følgende artikler:
- Wikipedia-artikel om dimensionel modellering
- Opret og administrer relationer i Power BI Desktop
- Vejledning til en til en-relationer
- Vejledning til mange til mange-relationer
- Vejledning til tovejsrelationer
- Vejledning til aktive forhold i forhold til inaktive relationer
- Spørgsmål? Prøv at spørge Power BI-community'et
- Forslag? Bidrag med idéer til forbedring af Power BI
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om