Erstellen einer Hochverfügbarkeitsarchitektur und -strategie für SharePoint Server
GILT FÜR: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint in Microsoft 365
SharePoint in Microsoft 365
Eine Hochverfügbarkeitsstrategie stellt eine wichtige Anforderung für eine SharePoint Server-Produktionsumgebung dar. Eine End-to-End-Strategie umfasst Betriebsprozesse, Plattformsteuerung, Architektur sowie technische Lösungen. Dieser Artikel befasst sich mit den Architektur- und Technikaspekten der Hochverfügbarkeit. In dieser Anleitung werden spezifische SharePoint-Designelemente sowie die technischen Optionen erläutert, anhand derer Ihre Strategie für die Hochverfügbarkeit festgelegt ist.
Hinweis
[!HINWEIS] Hochverfügbarkeit und Notfallwiederherstellung sind nicht das Gleiche. Obwohl es eine Überschneidung bei der Planung und den Lösungen gibt, handelt es sich bei beiden um Teilbereiche der Geschäftskontinuität. Der Zweck der Hochverfügbarkeit besteht darin, Stabilität im primären Rechenzentrum und eine geplante Ausfallzeit zu erreichen. Der Zweck der Notfallwiederherstellung besteht darin, dass eine Organisation in einem sekundären Rechenzentrum den Computerbetrieb fortsetzen kann, wenn die Infrastruktur im primären Rechenzentrum aufgrund eines Notfalls nicht mehr verwendet werden kann. Informationen zur Notfallwiederherstellung für SharePoint Server finden Sie im Abschnitt Wählen einer Notfallwiederherstellungsstrategie für SharePoint Server.
Die hohe Verfügbarkeit wird normalerweise verwendet, um die Fähigkeit eines Systems zu beschreiben, den Betrieb fortzusetzen und Ressourcen für die Systembenutzer bereitzustellen, wenn ein Problem in mindestens einer der folgenden Kategorien in einer fehlerhaften Domäne auftritt: Hardware, Software oder Anwendung. Der Grad der Verfügbarkeit wird als Prozentwert der Zeit angegeben, die ein System kontinuierlich betriebsbereit ist, um die Geschäftsfunktionen zu unterstützen. Der erforderliche Grad der Verfügbarkeit variiert je nach Organisation. Diese Anforderung kann auch innerhalb von Geschäftseinheiten variieren - die Vereinbarung zum Servicelevel wird jedoch für die Organisation als Ganzes getroffen. Aus Sicht der Benutzer ist eine SharePoint-Farm verfügbar, wenn Benutzer auf die Farm zugreifen und die Features und Dienste verwenden können, die sie für ihre Arbeit benötigen.
Eine hochverfügbare SharePoint-Farm zeichnet sich durch die folgenden Ziele und Merkmale aus:
Das Farmdesign reduziert potenzielle Fehlerquellen. Da es kaum möglich ist, alle Fehlerquellen zu beseitigen, muss die Gesamtstrategie auf die Behandlung eines Fehlereignisses ausgerichtet sein.
Failoverereignisse erfolgen nahtlos und haben nur minimale Auswirkungen auf die Benutzeraktivitäten.
Die Farm wird weiterhin ausgeführt, wenn auch mit reduzierter Kapazität. Es gibt jedoch keinen vollständigen Ausfall.
Die Farm zeichnet sich durch Ausfallsicherheit aus. Vorgänge, die sich auf den Dienst auswirken, treten nur selten auf, und beim Eintreten solcher Vorgänge werden zeitnah effektive Maßnahmen ergriffen.
Einführung
Bevor Sie eine realistische und wirtschaftliche Hochverfügbarkeitsarchitektur und -strategie für Ihre SharePoint-Umgebung erstellen können, müssen Sie Ihre Verfügbarkeitsziele definieren und quantifizieren. Diese Ziele spiegeln das Maß wider, in dem Ihre Organisation von SharePoint Server abhängt und wie sich ein Ausfall des Diensts auf den Betrieb der Organisation auswirken würde. Die Auswirkungen eines Dienstverlusts sind abhängig von der Art des Verlusts (vollständiger oder teilweiser Verlust) sowie der Dauer des Verlusts.
Eine erfolgreiche Hochverfügbarkeitsstrategie muss die spezifischen Anforderungen Ihrer Organisation widerspiegeln. Darüber hinaus muss Sie eine optimale Balance zwischen den Unternehmensanforderungen, IT-Vereinbarungen zum Servicelevel (Service Level Agreements, SLAs) und der Verfügbarkeit der technischen Lösungen, IT-Supportmöglichkeiten und Infrastrukturkosten darstellen.
Nachdem Sie die Verfügbarkeitsanforderungen für Ihre Organisation ermittelt haben, können Sie mit der Erstellung eines Hochverfügbarkeitsdesigns und einer Strategie zur Reduzierung des Ausfallrisikos und eines reduzierten Betriebs beginnen. IT-Fachleute, die hoch verfügbare Systeme entwickeln und bereitstellen, vertrauen bei der Umsetzung ihrer Ziele auf die folgenden Leitprinzipien:
Einzelne Fehlerquellen für jede fehlerhafte Domäne und das gesamte System auf jeder möglichen Ebene beheben (Betriebssystem, Software und SharePoint-Anwendung).
Eine sehr schnelle Fehlererkennung, -isolation und -behebung implementieren.
Hochverfügbarkeitslösungen sind breit angelegt und stellen eine Reihe systemweiter gemeinsam verwendbarer Ressourcen zur Verfügung, die integriert werden, um vordefinierte erforderliche Dienste bereitzustellen. Die Lösung nutzt verschiedene Kombinationen von Hardware und -software, um die Ausfallzeit zu minimieren und die Dienste wiederherzustellen, wenn das System oder Teile des Systems ausfallen.
Eine fehlertolerante Lösung ist hardwarebezogen und verwendet spezielle Hardware, um Fehler zu erkennen und umgehend auf eine redundante Hardwarekomponente umzuschalten. Bei dieser Komponente kann es sich um einen Prozessor, eine Speicherplatine, ein Netzteil, E/A-Subsystem oder Speichersubsystem handeln. Der Wechsel auf eine redundante Komponente gewährleistet eine hohe Dienstqualität.
Mit einer Kosten-Nutzen-Analyse für fehlertolerante Lösungen und Hochverfügbarkeitslösungen können Organisationen eine wirksame Strategie entwickeln, um die Verfügbarkeitsziele ihrer SharePoint-Farm zu erreichen. Normalerweise liegen für diese beiden Lösungen Kostenkompromisse vor.
Ein Prozess, der eine hohe Verfügbarkeit implementiert, ist eine der kostspieligeren Investitionen in Bezug auf eine SharePoint-Farm. Mit der zunehmenden Verfügbarkeit und der Anzahl der Systeme, für die die hohe Verfügbarkeit gewährleistet werden soll, steigen auch die Komplexität und die Kosten einer Verfügbarkeitslösung.
Durch die Vorteile in der Virtualisierungstechnologie können Unternehmen virtuelle Computer als Hot-Spare-, Warm-Spare- oder Cold-Spare-Computer nutzen. Virtuelle Computer können möglicherweise dieselbe Funktionalität liefern. Die Virtualisierung ermöglicht dabei Flexibilität und Kosteneffizienz. Sie müssen jedoch immer sicherstellen, dass ein virtueller Computer die entsprechende Kapazität aufweist, um die Last des physischen Computers zu verarbeiten, der ersetzt werden soll.
Erstellen einer Farmarchitektur, die Hochverfügbarkeit unterstützt
In der folgenden Abbildung wird gezeigt, wie Sie die verschiedenen Teile einer SharePoint-Umgebung verteilen und konfigurieren können, um die Verfügbarkeit innerhalb einer Farm zu erhöhen. Dieses Beispiel zeigt auch, wie Redundanz zur Behandlung von fehlerhaften Domänen genutzt werden kann.
Hinweis
Das hier gezeigte Beispiel ist nicht vollständig. Es werden z. B. nicht alle fehlerhaften Domänen und sämtliche fehlertolerante Hardware gezeigt.
Beispiele für Redundanz in einer Farmtopologie zur Behandlung von Fehlerquellen
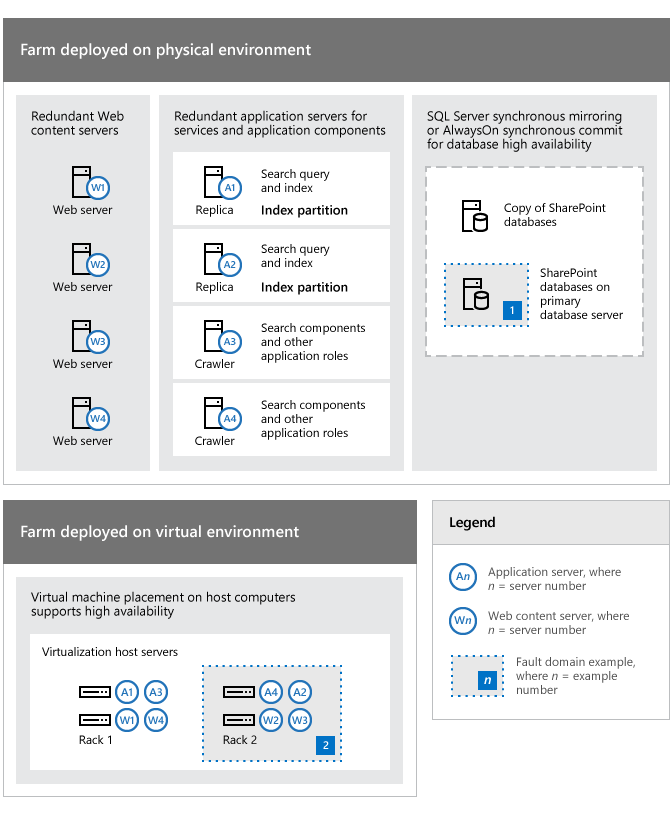
In Bezug auf die Topologie in der vorherigen Abbildung ist Folgendes zu beachten:
Die Farmserver in diesem Beispiel können physische Computer oder virtuelle Computer sein, die auf Hyper-V-Host-Servern bereitgestellt werden. Das Prinzip der Identifizierung und Reaktion auf Fehlerquellen betrifft beide Arten von Umgebungen.
Vier Server (W1-W4) sind für die Bereitstellung von Inhalten vorgesehen, und diese Redundanz erhöht die Verfügbarkeit, wenn ein Fehler auf einem oder mehreren Servern auftritt. Diese Redundanzebene ermöglicht es der Farm auch, den Betrieb fortzusetzen, wenn Softwareupdates angewendet werden.
Vier Anwendungsserver (A1-A4) erhöhen die Verfügbarkeit für Farmdienste und spezifische Anwendungskomponenten wie die Suche. Suchrollen und Komponenten sind redundant.
Die Datenbankserver der Farm sind redundant, und durch die Verwendung von Datenbankspiegelung oder Clustering kann eine Datenbank mit hoher Verfügbarkeit erreicht werden.
In einer virtuellen Umgebung werden die virtuellen Computer auf separaten Hyper-V-Hostservern platziert, um eine einzelne Fehlerquelle zu beseitigen. Dieser Ansatz zur Platzierung des virtuellen Computers entspricht den Best Practice-Richtlinien für die Verfügbarkeit und Leistung.
Der primäre Datenbankserver (mit 1 gekennzeichnet) und Rack 2 (mit 2 gekennzeichnet), das zwei der Hosts für virtuelle Maschinen enthält, werden als fehlerhafte Domänen identifiziert, um zu demonstrieren, wie die Farm und die Infrastruktur als eine Sammlung fehlerhafter Domänen betrachtet werden kann. Hier wird veranschaulicht, wie Sie eine eingehende Analyse Ihrer Umgebung vornehmen können, um eine Gesamtstrategie und eine Kosten-Nutzen-Analyse zu entwickeln.
Sonstige Farmrollen und -Dienste
Unser Beispiel enthält nicht alle Rollen, Dienste und Dienstanwendungen, die in einer bestimmten SharePoint-Farm ausgeführt werden könnten. Sie können in Bezug auf die hohe Verfügbarkeit keinen generischen Ansatz für alle in einer SharePoint-Farm vorhandenen Elemente verfolgen. Einige wichtige Ausschlüsse im Vergleich zur Verwendung eines Standardansatzes für hohe Verfügbarkeit sind folgende:
Der verteilte Cache erfordert spezielle Überlegungen in Bezug auf das Failover. Weitere Informationen hierzu finden Sie unter Planen des verteilten Cachediensts und Verwalten des verteilten Cachediensts in SharePoint Server.
SharePoint Workflow erfordert das kumulative Update 3 für Workflow Manager 1.0. Konfigurieren Sie den Workflow für SharePoint Server 2016 genauso wie für SharePoint Server 2013. Weitere Informationen finden Sie unter Beschreibung des kumulativen Update 3 für Workflow Manager 1.0 und Konfigurieren eines hochgradig verfügbaren Workflows in Workflow Manager 1.0.
Hinweis
[!HINWEIS] Die Konfiguration des Workflows für SharePoint Server 2016 hat sich gegenüber SharePoint Server 2013 nicht geändert. Sie müssen das kumulative Update 3 für Workflow Manager 1.0 installieren.
Obwohl Dienstanwendungen entsprechend der Empfehlung auf mehreren Computern ausgeführt werden können, weisen einige Dienstanwendungen im Hinblick auf die hohe Verfügbarkeit besondere und individuelle Installations- und Konfigurationsanforderungen auf. Ein Beispiel stellt die Benutzerprofil-Anwendung dar.
Verwenden von Fehlertoleranz in der Hochverfügbarkeitslösung
Nachdem Sie eine Architektur entworfen haben, die hochverfügbare Rollen und Workloads unterstützt, können Sie mithilfe fehlertoleranter Komponenten die Verfügbarkeit erhöhen. Fehlertolerante Lösungen sind innerhalb der gesamten Infrastruktur verfügbar, die die Datenbanken enthält.
Eine fehlertolerante Infrastruktur
Fehlertoleranz ist jederzeit für fast jede Hardwarekomponente in der Infrastruktur einer SharePoint-Farm verfügbar. Im Rahmen Ihres Hochverfügbarkeitsdesigns müssen Sie die Teile der Infrastruktur bestimmen, die aus operativer Sicht sowie aus Kostengründen fehlertolerant sein sollten. Auch wenn die Möglichkeit besteht, jede Komponente der Infrastruktur fehlertolerant zu machen, bedeutet dies nicht, dass dies auch sinnvoll ist.
Fehlertolerante Datenbankserver und Datenbanken
Da die SharePoint-Plattform und ihre Anwendungs-Workloads von der Verfügbarkeit und Zuverlässigkeit aller SharePoint-Datenbanken abhängig sind, sind hochverfügbare Datenbanken ein äußerst wichtiger Aspekt Ihrer Hochverfügbarkeitsstrategie. Sie können die folgenden Funktionen, z. B. fehlertolerante Lösungen für SharePoint-Datenbankserver und Datenbanken verwenden:
SQL Server Failoverclustering (Always On Failover Cluster Instances (FCI) in SQL Server 2014 mit Service Pack 1 (SP1)) und SQL Server 2012
Always On Verfügbarkeitsgruppen
SQL Server-Hochverfügbarkeits-Datenbankspiegelung
Informationen zu Always On Failoverclusterinstanzen und Always On-Verfügbarkeitsgruppen
Ein Failovercluster erfordert gemeinsamen Plattenspeicher zwischen zwei Computern. In einer Zwei-Knoten-Konfiguration sind die Computer als aktiv/passiv konfiguriert, sodass eine vollständig redundante Instanz des Primärknotens ermöglicht wird. Der passive Knoten wird im Fall eines Ausfalls des primären Knotens online gestellt. Die gemeinsam verwendete Festplatte wird jeweils nur für einen Computer zur Verfügung gestellt. Diese Konfiguration erfordert in der Regel den größten Teil an zusätzlicher Hardware. In SQL Server 2014 (SP1) und SQL Server 2012 ist diese Art von Clusterkonfiguration eine Always On Failoverclusterinstanz und eine spezifische Möglichkeit zum Installieren von SQL Server. Aufgrund der Konfigurationsanforderungen kann nicht einfach eine Standardinstallation von SQL Server verwendet und diese in eine Failoverclusterinstanz geändert werden.
Eine Always On Verfügbarkeitsgruppe ist eine andere Technologie in SQL Server 2014 (SP1) und SQL Server 2012 (betrachten Sie sie als Nachfolger der Datenbankspiegelung), die einige Features verwendet, die vom Windows-Clustering verfügbar gemacht werden. Allerdings ist hierfür kein gemeinsamer Festplattenspeicher erforderlich, und auf den Computern in einer Verfügbarkeitsgruppe muss keine spezielle Konfiguration von SQL Server installiert sein. Nachdem einem Windows-Cluster ein Datenbankserver hinzugefügt wurde, ist es relativ einfach, Always On Verfügbarkeitsgruppen zu aktivieren und dann die gewünschte Verfügbarkeitsgruppe zu konfigurieren.
Zusammenfassend kann jeder Server, der SQL Server 2014 (SP1) und SQL Server 2012 Enterprise Edition ausführt, Always On Verfügbarkeitsgruppen verwenden, indem er einem Cluster beitritt und die Verfügbarkeitsgruppe konfiguriert. Always On Failovercluster erfordern spezielle Hardware- und Konfigurationsschritte zum Einrichten von Failoverclusterinstanzen. Jede dieser Technologien wird für bestimmte Umgebungen verwendet, und beide sind komplementäre Wettbewerber. Weitere Informationen zu diesen Features finden Sie unter Hochverfügbarkeitslösungen (SQL Server). Hilfe bei der Entscheidung, welche SQL Server Verfügbarkeitstechnologie verwendet werden soll, finden Sie unter Geschäftskontinuität und Datenbankwiederherstellung – SQL Server.
Wichtig
[!WICHTIGER HINWEIS] Da jede Instanz von SQL Server mit Hochverfügbarkeitsoption eigene Merkmale, Stärken und Schwächen aufweist, ist eine Option nicht unbedingt besser als die jeweils andere. In einem bestimmten Szenario, in dem Always On Verfügbarkeitsgruppen verwendet werden, ist beispielsweise die Minimierung von Datenverlusten möglicherweise besser als ein Leistungsgewinn, den Always On Failoverclusterinstanzen erzielen. Sie müssen sich für eine Hochverfügbarkeitslösung entscheiden, die Ihren geschäftlichen Anforderungen und den Anforderungen an die IT-Infrastruktur entspricht.
Einen entscheidenden Faktor bei der Auswahl der zu verwendenden SQL Server-Option stellen die SharePoint-Datenbanken dar. Sie müssen die Eigenschaften der SharePoint Server-Datenbanken verstehen. Jede Datenbank kann spezielle Anforderungen oder Einschränkungen aufweisen, anhand derer die fehlertolerante SQL Server-Lösung bestimmt wird, die für Ihre Produktionsumgebung geeignet ist und vollständig unterstützt wird. Wir empfehlen Ihnen, die folgenden Artikel zu lesen:
SQL Server-Failoverclustering
Failoverclustering bietet Verfügbarkeit für eine Instanz von SQL Server unter SQL Server 2014 (SP1) oder SQL Server 2012.
Ein Failovercluster ist eine Kombination von einem oder mehreren Knoten oder Servern und zwei oder mehr gemeinsam verwendeten Datenträgern. Obwohl eine Instanz eines Failoverclusters als einzelner Computer dargestellt wird, ermöglicht die Instanz die Ausführung eines Failovers von einem Knoten auf einen anderen, wenn der aktuelle Knoten nicht mehr verfügbar ist. SharePoint Server kann unter einer beliebigen Kombination von aktiven und passiven Knoten in einem Cluster ausgeführt werden, das SQL Server unterstützt.
Unter SharePoint Server wird auf den Cluster als Ganzes verwiesen. Daher erfolgt das Failover aus der Perspektive von SharePoint Server automatisch und nahtlos.
Hinweis
Wenn entweder ein geplantes oder ungeplantes Failover erfolgt, werden die Verbindungen gelöscht und müssen beim Übergang von einem Cluster-Knoten auf einen anderen Clusterknoten wiederhergestellt werden.
Ausführliche Informationen zum SQL Server Failoverclustering finden Sie unter Always On Failoverclusterinstanzen (SQL Server).
SQL Server Always On-Verfügbarkeitsgruppen und SQL Server Datenbankspiegelung
Der Hauptvorteil von SQL Server Always On Verfügbarkeitsgruppen und SQL Server Datenbankspiegelung besteht darin, dass beide eine vollständige oder fast vollständige Datenredundanz bereitstellen, je nachdem, wie Sie sie für die Transaktionsverarbeitung konfigurieren. Neben der Minimierung von Datenverlusten minimiert das automatische Failover die Ausfallzeiten für Produktionsdatenbanken.
Wichtig
Obwohl SQL Server 2016, SQL Server 2014 (SP1) und SQL Server 2012 die Datenbankspiegelung unterstützen, ist geplant, dass dieses Feature veraltet ist. Es wird empfohlen, die Verwendung dieses Features bei neuen Entwicklungsvorgängen zu vermeiden. Planen Sie das Ändern von Anwendungen, die dieses Feature derzeit verwenden. Verwenden Sie stattdessen Always On Verfügbarkeitsgruppen.
Always On Verfügbarkeitsgruppen
Das Feature SQL Server Always On Verfügbarkeitsgruppen ist sowohl eine Hochverfügbarkeits- als auch eine Notfallwiederherstellungslösung, die eine Alternative zur Datenbankspiegelung auf Unternehmensebene bietet. Always On Verfügbarkeitsgruppen unterstützen eine Failoverumgebung für eine oder mehrere Benutzerdatenbanken, die in einer benutzerdefinierten Sammlung enthalten sind. Diese Sammlung, eine Verfügbarkeitsgruppe, besteht aus den folgenden Komponenten:
Replikate, die als Verfügbarkeitsdatenbanken bezeichnete eigenständige Benutzerdatenbanken darstellen und als eine Einheit behandelt werden. Eine Verfügbarkeitsgruppe unterstützt ein primäres Replikat und bis zu vier sekundäre Replikate.
Eine bestimmte Instanz von SQL Server zum Hosten jedes Replikats und zum Verwalten einer lokalen Kopie aller Datenbanken, die zu der Verfügbarkeitsgruppe gehören.
Wenn ein Failover einer Verfügbarkeitsgruppe auf eine Zielinstanz oder einen Zielserver ausgeführt wird, wird für alle Datenbanken in der Gruppe ebenfalls ein Failover ausgeführt. Da SQL Server 2014 (SP1) und SQL Server 2012 mehrere Verfügbarkeitsgruppen auf einem einzelnen Server hosten können, können Sie Always On für ein Failover auf SQL Server Instanzen auf verschiedenen Servern konfigurieren. Dies reduziert die Notwendigkeit von Hochleistungs-Standbyservern im Leerlauf, um die volle Last des primären Servers zu bewältigen. Dies ist einer der vielen Vorteile von Verfügbarkeitsgruppen.
Hinweis
Ein Failover wird nicht durch Datenbankprobleme verursacht, z. B. wenn eine Datenbank aufgrund des Verlusts einer Datendatei, des Löschens einer Datenbank oder der Beschädigung eines Transaktionsprotokolls verdächtig ist.
Weitere Informationen zu den Vorteilen von Always On Verfügbarkeitsgruppen und eine Übersicht über die Terminologie Always On Verfügbarkeitsgruppen finden Sie unter Always On Verfügbarkeitsgruppen (SQL Server).
Datenbankspiegelung
Hinweis
Obwohl SQL Server 2016, SQL Server 2014 (SP1) und SQL Server 2012 die Datenbankspiegelung unterstützen, ist geplant, dass dieses Feature veraltet ist. Es wird empfohlen, die Verwendung dieses Features bei neuen Entwicklungsvorgängen zu vermeiden. Planen Sie das Ändern von Anwendungen, die dieses Feature derzeit verwenden. Verwenden Sie stattdessen Always On Verfügbarkeitsgruppen.
Die Datenbankspiegelung bietet Datenbankredundanz, indem eine gespiegelte Kopie der Datenbanken auf dem primären Datenbankserver gespeichert wird. Die Spiegelung wird pro Datenbank implementiert und funktioniert nur mit Datenbanken, die das vollständige Wiederherstellungsmodell verwenden.
Hinweis
[!HINWEIS] Es gibt zwei Spiegelungsmodi. Einer davon, der Hochsicherheitsmodus, unterstützt den synchronen Betrieb. Wenn im Hochsicherheitsmodus eine Sitzung gestartet wird, synchronisiert der Spiegelserver die Spiegeldatenbank und die Prinzipal-Datenbank so schnell wie möglich. Sobald die Datenbanken synchronisiert sind, wird eine Transaktion in die Protokolldatei auf dem sekundären Server geschrieben und dann wiedergegeben. (Die Steuerung wird an den Prinzipalserver zurückgegeben, sobald die Transaktion gefestigt ist.) Der andere Spiegelungsmodus ist die Hochleistungsspiegelung, bei der ein asynchroner Betrieb verwendet wird, um auf Kosten eines erhöhten Datenverlusts die Transaktionslatenz zu reduzieren.
Für eine hochverfügbare Spiegelung in einer SharePoint-Farm müssen Sie den Hochsicherheitsmodus mit automatischem Failover verwenden. Für eine Hochsicherheitsdatenbankspiegelung sind drei Serverinstanzen erforderlich: ein Prinzipalserver, ein Spiegelserver und ein Zeugenserver. Der Zeugenserver ermöglicht das automatische Failover von SQL Server vom Prinzipalserver auf den Spiegelserver. Das Failover von der Prinzipaldatenbank auf die Spiegeldatenbank dauert normalerweise mehrere Sekunden.
Allgemeine Informationen zur Datenbankspiegelung finden Sie unter Datenbankspiegelung.
Wichtig
Datenbanken, die für die Verwendung des Remote-BLOB-Speicheranbieters FILESTREAM von SQL Server konfiguriert wurden, können nicht gespiegelt werden.
Vergleich von Datenbankverfügbarkeits- und Wiederherstellungsstrategien für eine einzelne Farm
Die Wahl einer SQL Server-Technologie für hohe Verfügbarkeit und Notfallwiederherstellung sollte auf die Geschäftsziele Ihres Unternehmens im Hinblick auf die Zielsetzung für den Wiederherstellungspunkt (Recovery Point Objective, RPO) und die Zielsetzung für die Wiederherstellungsdauer (Recovery Time Objective, RTO) ausgerichtet sein. Obwohl RPO und RTO normalerweise mit der Notfallwiederherstellung verbunden sind, liegen einige Fehlerereignisse außerhalb des Anwendungsbereichs eines Notfalls, erfordern jedoch die Wiederherstellung aus lokalen Sicherungsmedien im primären Datencenter.
Wichtig
[!WICHTIGER HINWEIS] Abhängig von der jeweiligen Datenbank unterstützen die verschiedenen SharePoint Server-Datenbanken nur spezifische SQL Server-Hochverfügbarkeitsoptionen. Weitere Informationen finden Sie unter Unterstützte Hochverfügbarkeits- und Notfallwiederherstellungsoptionen für SharePoint-Datenbanken.
In der folgenden Tabelle werden die RPO- und RTO-Ergebnisse verglichen, die mit verfügbaren SQL Server-Lösungen erzielt werden.
Hinweis
[!HINWEIS] Die Zeiten in der folgenden Tabelle gelten für den Vergleich der Datenbankoptionen. In der Praxis hängen alle Zeiten von Arbeitsauslastung, Datenvolumen und Failoverprozedur ab.
Vergleich von RPO und RTO auf Grundlage der Datenbanktechnologie
| SQL Server-Lösung | Potenzieller Datenverlust (RPO) | Potenzielle Wiederherstellungszeit (RTO) | Automatisches Failover | Lesbare sekundäre Rolle Hinweis: SharePoint Server unterstützt lesbare sekundäre Replikate für die Laufzeitnutzung. Weitere Informationen finden Sie unter Kumulatives Office 2013-Update für April 2014 und Ausführen einer Farm, die schreibgeschützte Datenbanken in SharePoint Server verwendet. |
|---|---|---|---|---|
| Always On Verfügbarkeitsgruppe (synchroner Commit) |
Null |
Sekunden |
Ja |
0–2 |
| Always On-Verfügbarkeitsgruppe (asynchroner Commit) |
Sekunden |
Minuten |
Nein |
0–4 |
| Always On-Failoverclusterinstanz |
Nicht zutreffend Eine Failoverclusterinstanz selbst bietet keine Datensicherheit. Der Umfang des Datenverlusts hängt von der Speichersystemimplementierung ab. |
Sekunden bis Minuten |
Ja |
Nicht zutreffend |
| Datenbankspiegelung – Hochsicherheitsmodus (synchroner Modus + Zeugenserver) |
Null |
Sekunden |
Ja |
Nicht zutreffend |
| Datenbankspiegelung – Hochverfügbarkeitsmodus (asynchroner Modus) |
Sekunden |
Minuten |
Nein |
Nicht zutreffend |
| Sichern, Kopieren, Wiederherstellen |
Stunden oder Null, wenn nach dem Fehler auf das Ende des Protokolls zugegriffen werden kann. |
Stunden bis Tage |
Nein |
Nicht während einer Wiederherstellung |
Vergleich von SQL Server Cluster, Always On Verfügbarkeitsgruppe und Datenbankspiegelung
| Prozess | SQL Server-Failovercluster | SQL Server 2014 (SP1) und SQL Server 2012 Always On-Verfügbarkeitsgruppe | SQL Server-Hochverfügbarkeitsspiegel |
|---|---|---|---|
| Zeit bis zum Failover |
Clustermitglied übernimmt sofort bei Auftreten eines Fehlers. Kurze Verzögerung beim Hochfahren des Clusterknotens. |
Replikat übernimmt sofort bei Auftreten eines Fehlers. Kurze Verzögerung beim Hochfahren des sekundären Replikats. |
Spiegelserver übernimmt sofort nach Verarbeitung der Wiederholungswarteschlange. |
| Transaktionskonsistenz |
Ja |
Ja |
Ja |
| Transaktionsparallelität |
Ja |
Ja |
Ja |
| Zeit bis zur Wiederherstellung |
Kürzere Zeit bis zur Wiederherstellung als bei Verfügbarkeitsgruppe. |
Längere Zeit bis zur Wiederherstellung als Failovercluster, aber kürzere Zeit bis zur Wiederherstellung als gespiegelte Lösung. |
Geringfügig längere Zeit bis zur Wiederherstellung als bei Cluster oder Verfügbarkeitsgruppe. |
| Schritte für Failover erforderlich |
Fehler wird automatisch von den Datenbankknoten erkannt. Da von SharePoint Server auf den Cluster verwiesen wird, erfolgt das Failover nahtlos und automatisch. |
Der Verfügbarkeitsgruppenlistener erkennt den Fehler automatisch, das Failover erfolgt nahtlos und automatisch. |
Fehler wird automatisch von der Datenbank erkannt. SharePoint Server verfügt über Informationen zum Speicherort des Spiegels. Wenn dieser richtig konfiguriert wurde, erfolgt das Failover automatisch. |
| Schutz vor Speicherfehlern |
Das Failovercluster selbst bietet keinen Datenschutz. Der Umfang des Datenverlusts ist abhängig vom implementierten Speichersystem. So verfügt beispielsweise eine SAN-Umgebung über redundante Komponenten, z. B. mehrere Dateipfade, RAID und Hot-Spares. |
Schützt vor Speicherfehlern, da das primäre Replikat auf die lokalen Datenträger auf den sekundären Replikaten schreibt. |
Schützt vor Speicherfehlern, da sowohl vom Prinzipaldatenbankserver als auch vom Spiegeldatenbankserver auf lokale Datenträger geschrieben wird. |
| Unterstützte Speichertypen |
Freigegebener Speicher erforderlich (kostspieliger als dedizierter Speicher). |
Kann weniger kostspielige direkt angeschlossene Speicherlösungen (Direct-Attached Storage, DAS) verwenden. |
Kann weniger kostspieligen direkt angeschlossenen Speicher (Direct-Attached Storage, DAS) verwenden. |
| Anforderungen an den Speicherort |
Die Mitglieder des Clusters müssen sich im gleichen Subnetz befinden. Note: Mit SQL Server 2014 (SP1) und SQL Server 2012 ist dies nicht der Fall. |
Replikate können sich in unterschiedlichen Subnetzen befinden, solange keine Leistungsprobleme aufgrund von Latenz auftreten. |
Prinzipal-, Spiegel- und Zeugenserver müssen sich im gleichen LAN (mit einer Roundtriplatenz von max. 1 Millisekunde) befinden. |
| Wiederherstellungsmodell |
SQL Server vollständiges Wiederherstellungsmodell empfohlen. Sie können das SQL Server einfaches Wiederherstellungsmodell verwenden. Der einzige verfügbare Wiederherstellungspunkt, wenn der Cluster verloren geht, ist jedoch die letzte vollständige Sicherung. |
Das vollständige Wiederherstellungsmodell von SQL Server 2014 (SP1) und SQL Server 2012 ist erforderlich. |
Das vollständige Wiederherstellungsmodell von SQL Server ist erforderlich. |
| Beeinträchtigung der Systemleistung |
Während eines Failovers kann eine gewisse Beeinträchtigung der Systemleistung auftreten. Der Server ist während des Failovers nicht verfügbar, und Verbindungen werden gelöscht und anschließend auf dem neuen aktiven Knoten wiederhergestellt. |
Always On Verfügbarkeitsgruppen führen transaktionslatenz aufgrund des synchronen Commits auf den sekundären Replikaten ein. Das Ausmaß der Latenz ist abhängig von der Anzahl der sekundären Replikate, die synchronisiert werden müssen. Die Beeinträchtigungen für Arbeitsspeicher und Prozessorleistung sind größer als beim Clustering, jedoch geringer als bei der Spiegelung. |
Durch die Spiegelung mit hoher Verfügbarkeit entsteht eine Transaktionslatenz, da der Vorgang synchron ist. Außerdem werden zusätzlicher Arbeitsspeicher und Prozessorleistung benötigt. |
| Bedienungsaufwand |
Wird auf Serverebene eingerichtet und gewartet. |
Der Bedienungsaufwand ist höher als bei Clustering und Spiegelung. Always On erfordert zusätzlich zur Windows Server-Ebene mehr Aufwand auf der Ebene des SQL Server Datenbankservers. Hinweis: Objekte auf Serverebene, z. B. Anmeldungen und Agentaufträge, müssen manuell verwaltet werden. Wenn Sie Inhaltsdatenbanken hinzufügen, müssen Sie diese einer Verfügbarkeitsgruppe hinzufügen und anschließend das primäre Replikat mit den sekundären Replikaten synchronisieren. Für eine SharePoint-Farmumgebung sind verschiedene Konfigurationsschritte erforderlich, um sicherzustellen, dass die SharePoint Server-Verbindungszeichenfolge dem Namen des Verfügbarkeitsgruppenlisteners korrekt zugeordnet ist. |
Der Bedienungsaufwand ist höher als beim Clustering. Muss für alle Datenbanken eingerichtet und gewartet werden. Die Neukonfiguration nach dem Failover erfolgt manuell. Hinweis: Objekte auf Serverebene, z. B. Anmeldungen und Agentaufträge, müssen manuell verwaltet werden. Wenn Sie Inhaltsdatenbanken hinzufügen, müssen Sie diese einem Prinzipalserver hinzufügen und anschließend den Prinzipalserver mit dem Spiegelserver synchronisieren. |
Konfigurieren von zwei Rechenzentren als einzelne Farm ("gestreckte" Farm) zur Bereitstellung der hohen Verfügbarkeit
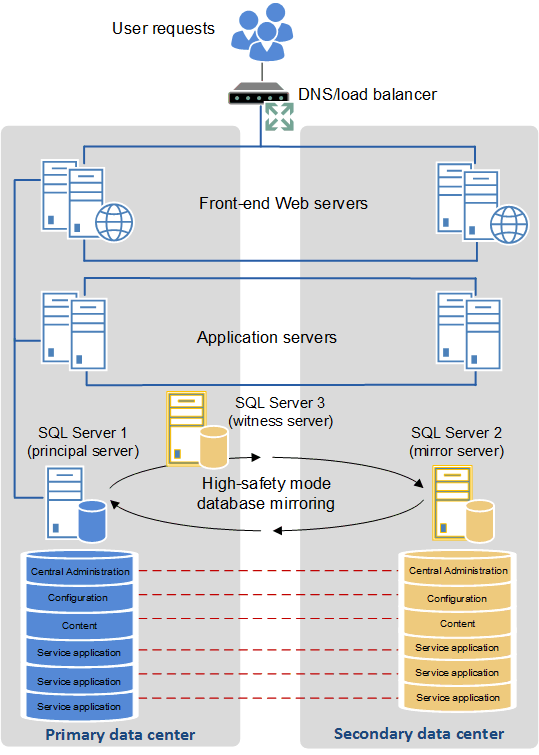
Manche Unternehmen unterhalten Rechenzentren, die sich nah beieinander befinden und die über Glasfaserverbindungen mit hoher Bandbreite miteinander vernetzt sind. Wenn eine solche Umgebung verfügbar ist, besteht die Möglichkeit, die beiden Rechenzentren als eine einzige Farm zu konfigurieren. Diese verteilte Farmtopologie wird als "gestreckte" Farm bezeichnet.
Damit eine gestreckte Farm als Unterstützung für eine Hochverfügbarkeitslösung verwendet werden kann, müssen folgende Voraussetzungen erfüllt sein:
There is a highly consistent intra-farm latency of <1ms (one way), 99.9% of the time over a period of ten minutes. (Intra-farm latency is commonly defined as the latency between the front-end web servers and the database servers.)
Die Bandbreitengeschwindigkeit muss mindestens 1 Gigabit pro Sekunde betragen.
Sie können die Fehlertoleranz in einer gestreckten Farm sicherstellen, indem Sie die gängigen Verfahren für die Konfiguration von redundanten Dienstanwendungen und Datenbanken ausführen.
Die folgende Abbildung zeigt eine gestreckte Farm.
Gestreckte Farm
Einbinden von Sicherungs- und Wiederherstellungsvorgängen in die Hochverfügbarkeitsstrategie
Ihre Hochverfügbarkeitsstrategie muss die entsprechenden Sicherungs- und Wiederherstellungsvorgänge umfassen, um die Ausfallsicherheit der SharePoint-Farm sicherzustellen. Wenn ein Ereignis, z. B. ein Datenträgerfehler oder Benutzerfehler, auftritt, müssen Sie in der Lage sein, den betroffenen Teil der Farmumgebung oder der Farmdaten zeitnah widerherzustellen. Mithilfe einer wirksamen Sicherungs- und Wiederherstellungslösung sollten Sie die von Ihnen definierten Zielsetzungen für die Wiederherstellungsdauer (RTO) und für den für den Wiederherstellungspunkt (RPO) erfüllen können.
Siehe auch
Konzepte
Konzepte für hohe Verfügbarkeit und Notfallwiederherstellung in SharePoint Server
Wählen einer Notfallwiederherstellungsstrategie für SharePoint Server