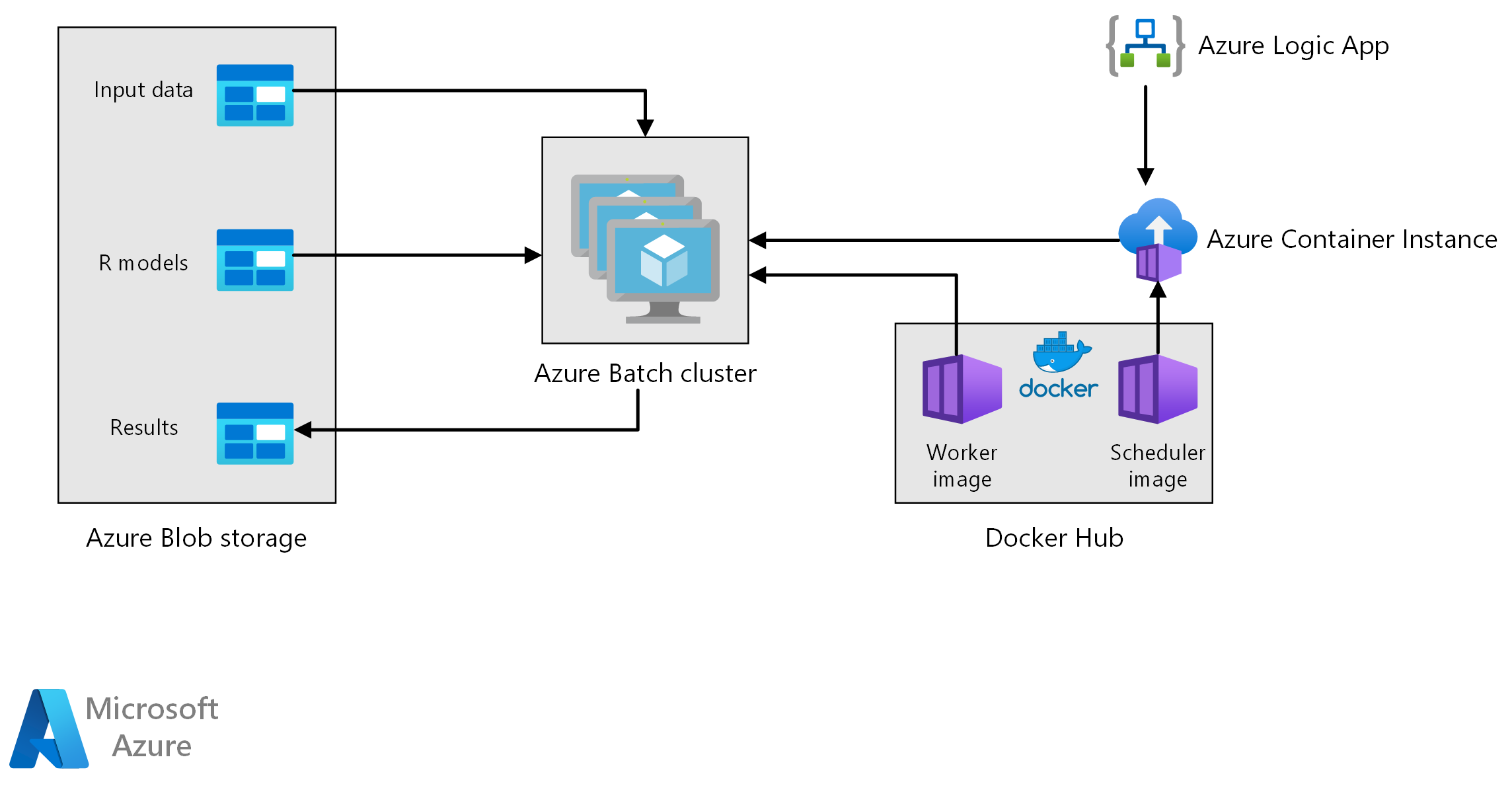
Diese Referenzarchitektur zeigt, wie Sie die Batchbewertung mit R-Modellen mithilfe von Azure Batch ausführen. Azure Batch funktioniert gut mit systeminternen parallelen Workloads und umfasst eine Auftragsplanung und Computeverwaltung. Der Batchrückschluss (Bewertung) wird häufig verwendet, um Kunden zu unterteilen, Umsätze zu prognostizieren, das Kundenverhalten und den Wartungsbedarf vorherzusagen oder die Cybersicherheit zu verbessern.
Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
Diese Architektur umfasst die folgenden Komponenten.
Azure Batch führt Aufträge zur Vorhersagengenerierung parallel in einem Cluster von virtuellen Computern aus. Vorhersagen werden mithilfe vorab trainierter Machine Learning-Modelle getroffen, die in R implementiert sind. Azure Batch kann die Anzahl der VMs basierend auf der Anzahl der Aufträge, die an den Cluster übermittelt werden, automatisch skalieren. Auf jedem Knoten wird ein R-Skript zum Bewerten von Daten und Generieren von Vorhersagen in einem Docker-Container ausgeführt.
Azure Blob Storage speichert die Eingabedaten, die vorab trainierten Machine Learning-Modelle und die Vorhersageergebnisse. Blob Storage bietet kostengünstigen Speicher für die Leistung, die diese Workload erfordert.
Azure Container Instances ermöglicht serverlose Computevorgänge nach Bedarf. In diesem Fall wird eine Containerinstanz nach einem Zeitplan bereitgestellt, um Batchaufträge auszulösen, die die Prognosen generieren. Die Batchaufträge werden von einem R-Skript unter Verwendung des doAzureParallel-Pakets ausgelöst. Die Containerinstanz wird automatisch beendet, sobald die Aufträge abgeschlossen sind.
Azure Logic Apps löst den gesamten Workflow durch Bereitstellung der Containerinstanzen nach einem Zeitplan aus. Ein Azure Container Instances-Connector in Logic Apps ermöglicht, dass eine Instanz bei einer Reihe von Auslöseereignissen bereitgestellt werden kann.
Komponenten
Details zur Lösung
Das Szenario basiert auf Vorhersagen zu Umsätzen in Einzelhandelsgeschäften, aber die zugrunde liegende Architektur kann für jedes Szenario verallgemeinert werden, das die Generierung umfassenderer Vorhersagen mithilfe von R-Modellen erfordert. Eine Referenzimplementierung für diese Architektur ist auf GitHub verfügbar.
Mögliche Anwendungsfälle
Eine Supermarktkette muss Produktverkäufe für das bevorstehende Quartal prognostizieren. Die Vorhersage ermöglicht dem Unternehmen, seine Lieferkette besser zu verwalten und sicherzustellen, die Nachfrage nach Produkten in allen Filialen zu erfüllen. Das Unternehmen aktualisiert seine Prognosen jede Woche, wenn neue Verkaufsdaten aus der vorherigen Woche verfügbar sind und die Produktmarketingstrategie für das nächste Quartal festgelegt ist. Quantilvorhersagen werden generiert, um die Ungewissheit bei einzelnen Umsatzprognosen einzuschätzen.
Die Verarbeitung umfasst die folgenden Schritte:
Eine Azure-Logik-App löst einmal pro Woche die Vorhersagengenerierung aus.
Die Logik-App startet eine Azure-Containerinstanz, auf der der Planer-Docker-Container ausgeführt wird, der die Bewertungsaufträge im Batch-Cluster startet.
Bewertungsaufträge werden parallel die Knoten des Clusters übergreifend ausgeführt. Jeder Knoten:
Ruft das Worker-Docker-Image ab und startet einen Container.
Liest die Eingabedaten und vortrainierten R-Modelle aus Azure Blob Storage.
Bewertet die Daten, um Prognosen zu erstellen.
Schreibt Prognoseergebnisse in Blob Storage.
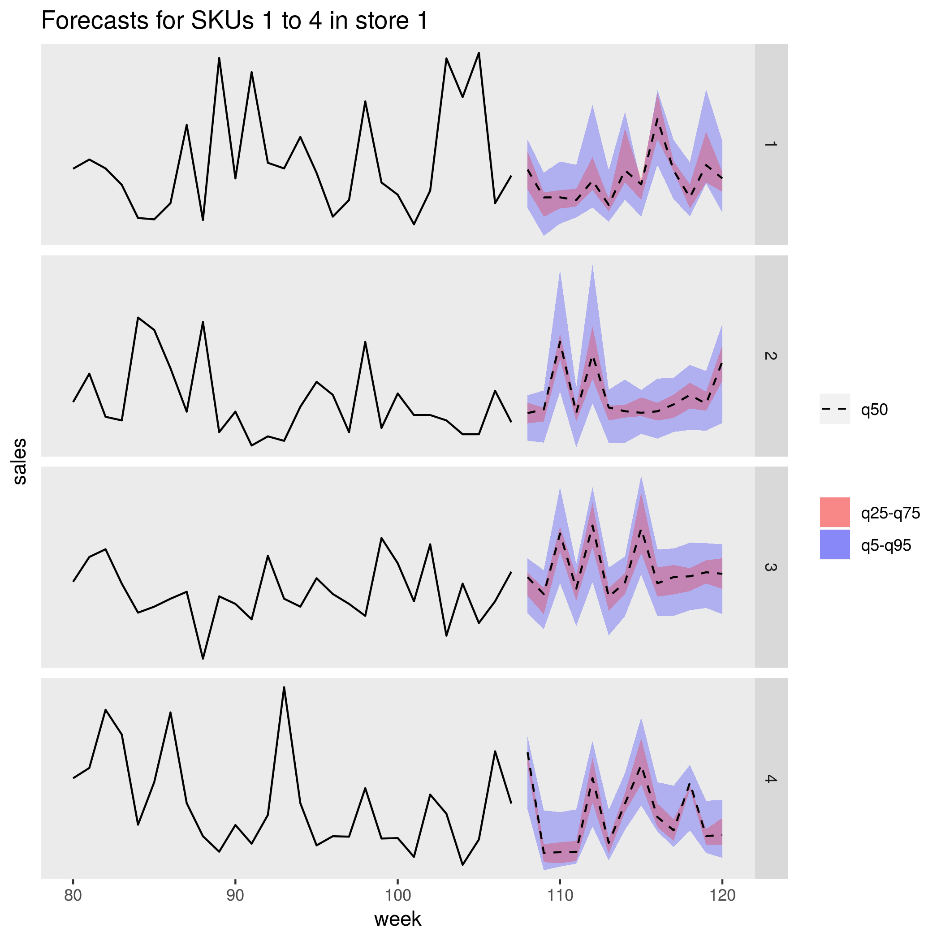
Die folgende Abbildung zeigt die vorhergesagten Verkäufe für vier Produkte (SKUs) in einer Filiale. Die schwarze Linie ist der Umsatzverlauf, die gestrichelte Linie ist die Medianvorhersage (q50), das rosa Band stellt das 25. und 75. Perzentil dar und das blaue Band das 50. und 95. Perzentil.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Leistung
Containerbereitstellung
Bei dieser Architektur werden alle R-Skripts in Docker-Containern ausgeführt. Durch die Nutzung von Containern wird sichergestellt, dass die Skripts jedes Mal in einer konsistenten Umgebung, mit der gleichen R-Version und den gleichen Paketversionen ausgeführt werden. Für den Planer- und Worker-Container werden separate Docker-Images verwendet, da jeder einen anderen Satz von R-Paketabhängigkeiten hat.
Azure Container Instances bietet eine serverlose Umgebung zum Ausführen des Planer-Containers. Der Planer-Container führt ein R-Skript aus, das die einzelnen in einem Azure Batch-Cluster ausgeführten Bewertungsaufträge auslöst.
Jeder Knoten des Batch-Clusters führt den Worker-Container aus, der das Bewertungsskript ausführt.
Parallelisieren der Workload
Erwägen Sie bei der Batchbewertung von Daten mit R-Modellen, wie Sie die Workload parallelisieren. Die Eingabedaten müssen so partitioniert werden, dass der Bewertungsvorgang auf die Clusterknoten verteilt werden kann. Probieren Sie unterschiedliche Ansätze aus, um die beste Wahl für die Verteilung Ihrer Workload zu ermitteln. Berücksichtigen Sie auf Fall-zu-Fall-Basis Folgendes:
- Wie viele Daten in den Arbeitsspeicher eines einzelnen Knotens geladen und dort verarbeitet werden können.
- Den Mehraufwand, jeden einzelnen Batchauftrag zu starten.
- Den Mehraufwand, die R-Modelle zu laden.
In dem für dieses Beispiel verwendeten Szenario sind die Modellobjekte umfangreich, und es dauert nur wenige Sekunden, um eine Vorhersage für die einzelnen Produkte zu generieren. Aus diesem Grund können Sie die Produkte gruppieren und einen einzelnen Batchauftrag pro Knoten ausführen. Eine Schleife innerhalb jedes Auftrags generiert sequenziell Vorhersagen für die Produkte. Es zeigt sich, dass diese bestimmte Workload mit dieser Methode am effizientesten parallelisiert werden kann. Sie vermeidet den zusätzlichen Aufwand, viele kleinere Batchaufträge zu starten und die R-Modelle wiederholt zu laden.
Ein alternativer Ansatz ist, einen Batchauftrag pro Produkt auszulösen. Azure Batch bildet automatisch eine Warteschlange mit Aufträgen und übermittelt sie zur Ausführung an den Cluster, sobald Knoten verfügbar sind. Passen Sie mit der automatischen Skalierung die Anzahl der Knoten im Cluster entsprechend der Anzahl der Aufträge an. Dieser Ansatz ist nützlich, wenn es relativ lange dauert, jeden Bewertungsvorgang auszuführen, sodass der Aufwand, die Aufträge zu starten und die Modellobjekte erneut zu laden, gerechtfertigt ist. Zudem ist er einfacher zu implementieren und bietet Ihnen die Flexibilität, die automatische Skalierung zu verwenden – ein wichtiger Aspekt, wenn die Größe der gesamten Workload im Voraus nicht bekannt ist.
Überwachen von Azure Batch-Aufträgen
Überwachen und beenden Sie Batchaufträge vom Bereich Aufträge des Batchkontos im Azure-Portal aus. Überwachen Sie den Batchcluster einschließlich des Status der einzelnen Knoten vom Bereich Pools aus.
Protokollieren mit „doAzureParallel“
Das doAzureParallel-Paket erfasst automatisch Protokolle aller stdout-/stderr-Vorgänge für jeden an Azure Batch übermittelten Auftrag. Diese Protokolle finden Sie im beim Setup erstellten Speicherkonto. Verwenden Sie für die Anzeige ein Speichernavigationstool wie z. B. den Azure Storage-Explorer oder das Azure-Portal.
Um Batchaufträge während der Entwicklung schnell zu debuggen, sehen Sie sich die Protokolle in Ihrer lokalen R-Sitzung an. Weitere Informationen finden Sie unter Konfigurieren und Übermitteln von Trainingsausführungen.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Die in dieser Referenzarchitektur genutzten Computeressourcen sind die teuersten Komponenten. Für dieses Szenario wird ein Cluster mit fester Größe erstellt, wenn der Auftrag ausgelöst wird, und dann nach Abschluss des Auftrags heruntergefahren. Kosten fallen nur an, während die Clusterknoten gestartet, ausgeführt oder heruntergefahren werden. Dieser Ansatz eignet sich für ein Szenario, in dem die zum Generieren der Vorhersagen benötigten Computeressourcen von Job zu Job relativ konstant bleiben.
In Szenarien, in denen die zum Ausführen des Auftrags erforderliche Computekapazität nicht im Voraus bekannt ist, kann es unter Umständen sinnvoller sein, die automatische Skalierung zu verwenden. Bei diesem Ansatz wird die Größe des Clusters abhängig von der Größe des Auftrags nach oben oder unten skaliert. Azure Batch unterstützt eine Reihe von Formeln für die Autoskalierung, die Sie festlegen können, wenn Sie den Cluster mit der doAzureParallel-API definieren.
Für einige Szenarien ist die Zeit zwischen Aufträgen möglicherweise zu kurz, um den Cluster herunterzufahren und wieder zu starten. Behalten Sie in diesen Fällen die Ausführung des Clusters zwischen Aufträgen nach Möglichkeit bei.
Azure Batch und doAzureParallel unterstützen die Verwendung von VMs mit niedriger Priorität. Diese virtuellen Computer bieten einen erheblichen Rabatt, doch besteht das Risiko, das andere Workloads mit höherer Priorität sich diese VMs aneignen. Die Verwendung dieser virtuellen Computer mit niedriger Priorität ist daher für entscheidende Produktionsworkloads nicht zu empfehlen. Sie sind jedoch nützlich für experimentelle Ansätze oder Entwicklungsworkloads.
Bereitstellen dieses Szenarios
Befolgen Sie die Schritte im GitHub-Repository, um diese Referenzarchitektur bereitzustellen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Angus Taylor | Senior Data Scientist
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.