Dieses Beispielszenario zeigt, wie Daten aus einem lokalen Data Warehouse in einer Cloudumgebung erfasst und anschließend mit einem Business Intelligence-Modell (BI) verarbeitet werden können. Dieser Ansatz kann das Ziel oder ein erster Schritt zur vollständigen Modernisierung mithilfe cloudbasierter Komponenten sein.
Die folgenden Schritte bauen auf dem Szenario einer End-to-End-Analyse mit Azure Synapse auf. Hierbei wird Azure Pipelines genutzt, um Daten aus einer SQL-Datenbank in Azure Synapse SQL-Pools zu erfassen und die Daten anschließend für die Analyse zu transformieren.
Aufbau

Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
Datenquelle
- Die Quelldaten befinden sich in einer SQL Server-Datenbank in Azure. Um die lokale Umgebung zu simulieren, wird mit den Bereitstellungsskripts für dieses Szenario eine Azure SQL-Datenbank bereitgestellt. Als Quelldatenschema und Beispieldaten wird die AdventureWorks-Beispieldatenbank verwendet. Informationen zum Kopieren von Daten aus einer lokalen Datenbank finden Sie unter Kopieren und Transformieren von Daten in und aus SQL Server.
Erfassung und Datenspeicherung
Azure Data Lake Gen2 wird während der Datenerfassung als temporärer Stagingbereich verwendet. Anschließend können Sie PolyBase zum Kopieren von Daten in einen dedizierten Azure Synapse SQL-Pool verwenden.
Azure Synapse Analytics ist ein verteiltes System, das für die Analyse großer Datenmengen konzipiert ist. Es unterstützt massive Parallelverarbeitung (Massive Parallel Processing, MPP), die die Ausführung von Hochleistungsanalysen ermöglicht. Der dedizierte Azure Synapse SQL-Pool dient als Ziel für die fortlaufende Erfassung von Daten aus lokalen Systemen. Er kann für die weitere Verarbeitung genutzt werden und die Daten für Power BI über DirectQuery bereitstellen.
Azure Pipelines dient zur Orchestrierung der Datenerfassung und -transformation in Ihrem Azure Synapse-Arbeitsbereich.
Analysen und Berichte
- Der Datenmodellierungsansatz in diesem Szenario beruht auf einer Kombination des Unternehmensmodells mit dem BI-Semantikmodell. Das Unternehmensmodell wird in einem dedizierten Azure Synapse SQL-Pool, das BI-Semantikmodell in Power BI Premium-Kapazitäten gespeichert. Power BI greift über DirectQuery auf die Daten zu.
Komponenten
Für dieses Szenario werden die folgenden Komponenten verwendet:
Vereinfachte Architektur
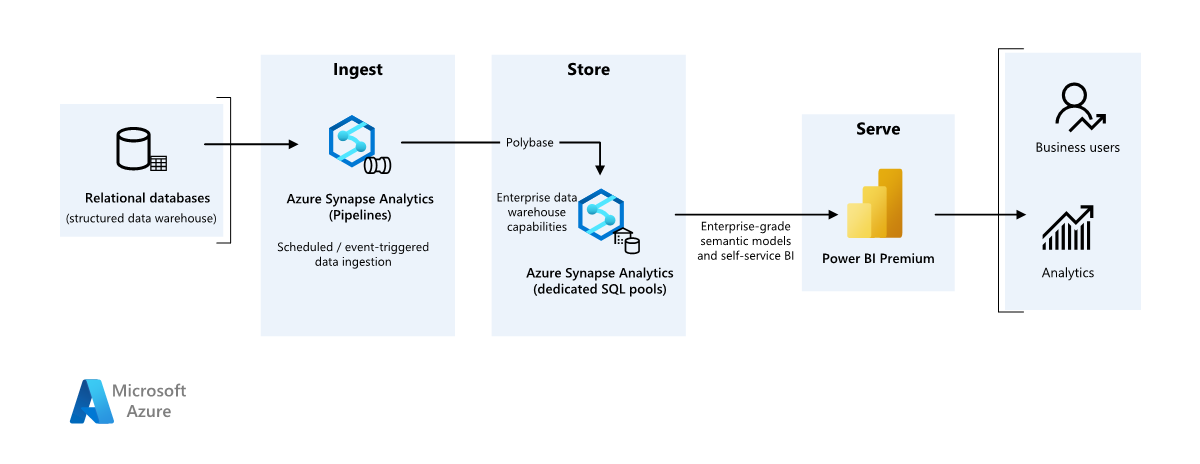
Szenariodetails
Eine Organisation verfügt über ein großes lokales Data Warehouse, das in einer SQL-Datenbank gespeichert ist. Die Organisation möchte mithilfe von Azure Synapse Analysen durchführen und die gewonnenen Erkenntnisse dann mit Power BI aufbereiten.
Authentifizierung
Benutzer*innen, die sich mit Power BI-Dashboards und -Apps verbinden, werden über Microsoft Entra authentifiziert. Für die Verbindungsherstellung mit der Datenquelle im Azure Synapse-Pool wird einmaliges Anmelden (Single Sign-On, SSO) verwendet. Die Autorisierung erfolgt in der Quelle.
Inkrementelles Laden
Beim Ausführen eines automatisierten ETL- (Extrahieren, Transformieren, Laden) oder ELT-Prozesses (Extrahieren, Laden, Transformieren) ist es am effizientesten, nur die Daten zu laden, die sich seit der letzten Ausführung geändert haben. Dies wird als inkrementeller Ladevorgang bezeichnet – im Gegensatz zu einem vollständigen Ladevorgang, bei dem alle Daten geladen werden. Zum Ausführen eines inkrementellen Ladevorgangs benötigen Sie eine Möglichkeit zum Identifizieren, welche Daten sich geändert haben. Der gängigste Ansatz ist die Verwendung eines hohen Grenzwerts, der den aktuellen Wert einer Spalte in der Quelltabelle nachverfolgt (entweder eine datetime-Spalte oder eine Spalte mit eindeutigen Ganzzahlen).
Ab SQL Server 2016 können Sie temporale Tabellen verwenden, d. h. Tabellen mit Systemversionsverwaltung, die einen vollständigen Verlauf der Datenänderungen enthalten. Die Datenbank-Engine zeichnet den Verlauf aller Änderungen automatisch in einer separaten Verlaufstabelle auf. Sie können die historischen Daten abfragen, indem Sie einer Abfrage eine FOR SYSTEM_TIME-Klausel hinzufügen. Intern fragt die Datenbank-Engine die Verlaufstabelle ab, aber diese Abfrage erfolgt transparent für die Anwendung.
Hinweis
Für frühere Versionen von SQL Server können Sie Change Data Capture (CDC) verwenden. Dieser Ansatz ist weniger geeignet als temporale Tabellen, da Sie eine separate Änderungstabelle abfragen müssen, und Änderungen werden anhand einer Protokollfolgenummer anstatt eines Zeitstempels nachverfolgt.
Temporale Tabellen sind hilfreich für Dimensionsdaten, die sich im Laufe der Zeit ändern können. Faktentabellen stellen in der Regel eine unveränderliche Transaktion wie einen Verkauf dar, und in diesem Fall ist das Beibehalten des Systemversionsverlaufs nicht sinnvoll. Stattdessen weisen Transaktionen normalerweise eine Spalte auf, die das Transaktionsdatum darstellt, das als Wasserzeichenwert verwendet werden kann. Im Data Warehouse von AdventureWorks verfügen die SalesLT.*-Tabellen zum Beispiel über ein LastModified-Feld.
Dies ist der allgemeine Ablauf für die ELT-Pipeline:
Verfolgen Sie für jede Tabelle in der Quelldatenbank den Trennzeitpunkt der Ausführung des letzten ELT-Auftrags nach. Speichern Sie diese Informationen im Data Warehouse. Bei der Ersteinrichtung sind alle Zeiten auf
1-1-1900festgelegt.Während des Datenexportschritts wird der Trennzeitpunkt als Parameter an einen Satz von gespeicherten Prozeduren in der Quelldatenbank übergeben. Diese gespeicherten Prozeduren fragen alle Datensätze ab, die nach dem Trennzeitpunkt geändert oder erstellt wurden. Für alle Tabellen im Beispiel können Sie die Spalte
ModifiedDateverwenden.Wenn die Datenmigration abgeschlossen ist, aktualisieren Sie die Tabelle, in der die Trennzeitpunkte gespeichert werden.
Datenpipeline
In diesem Szenario wird die AdventureWorks-Beispieldatenbank als Datenquelle verwendet. Durch die Implementierung des Musters zum inkrementellen Laden von Daten wird sichergestellt, dass nur Daten geladen werden, die nach der letzten Pipelineausführung geändert oder hinzugefügt wurden.
Tool zum metadatengesteuerten Kopieren
Das integrierte Tool zum metadatengesteuerten Kopieren in Azure Pipelines lädt inkrementell alle Tabellen, die in unserer relationalen Datenbank enthalten sind. Wenn Sie durch den Assistenten navigieren, können Sie das Tool zum Kopieren von Daten mit der Quelldatenbank verbinden und das inkrementelle oder vollständige Laden für jede Tabelle konfigurieren. Das Tool zum Kopieren von Daten erstellt dann sowohl die Pipelines als auch die SQL-Skripts, um die Steuertabelle zu generieren, die zum Speichern der Daten für den inkrementellen Ladeprozess benötigt wird, z. B. den hohen Grenzwert/die Spalte für jede Tabelle. Sobald diese Skripts ausgeführt werden, ist die Pipeline bereit, alle Tabellen im Quell-Data Warehouse in den dedizierten Synapse-Pool zu laden.
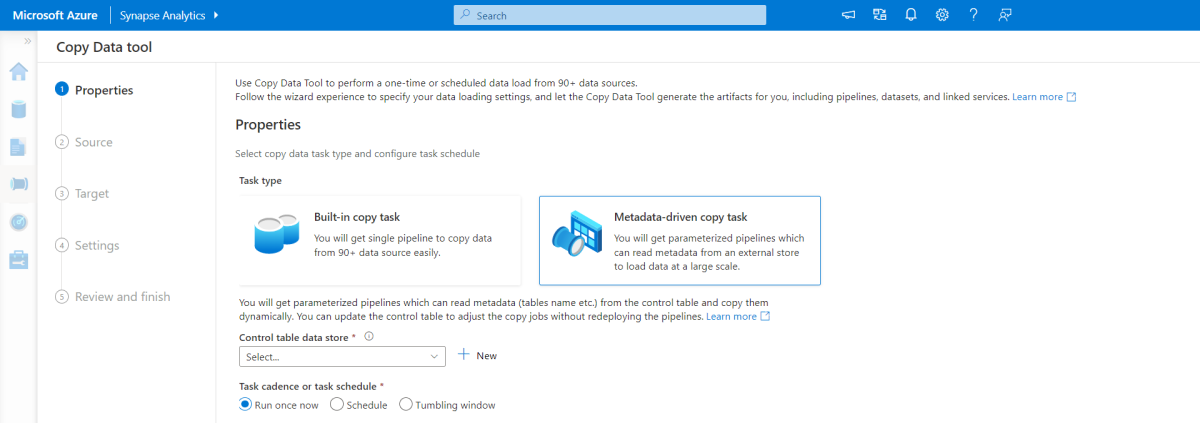
Das Tool erstellt drei Pipelines, um alle Tabellen in der Datenbank zu durchlaufen, bevor die Daten geladen werden.
Die mit dem Tool generierten Pipelines führen folgende Aufgaben aus:
- Zählen der Anzahl von Objekten (z. B. Tabellen), die bei der Pipelineausführung kopiert werden sollen
- Durchlaufen aller Objekte, die geladen/kopiert werden sollen, anschließend:
- Überprüfen, ob ein Deltaladevorgang erforderlich ist; andernfalls Ausführen eines normalen Vorgangs zum Laden der vollständigen Daten
- Abrufen des hohen Grenzwerts aus der Steuertabelle
- Kopieren der Daten aus den Quelltabellen in das Stagingkonto in ADLS Gen2
- Laden der Daten in den dedizierten SQL-Pool über die gewählte Kopiermethode, z. B. Polybase, Copy-Befehl
- Aktualisieren des hohen Grenzwerts in der Steuertabelle
Laden von Daten in den Azure Synapse SQL-Pool
Die Copy-Aktivität kopiert Daten aus der SQL-Datenbank in den Azure Synapse SQL-Pool. Da sich unsere SQL-Datenbank in Azure befindet, verwenden wir in diesem Beispiel die Azure Integration Runtime, um Daten aus der SQL-Datenbank zu lesen und die Daten in die angegebene Stagingumgebung zu schreiben.
Anschließend wird die Copy-Anweisung verwendet, um Daten aus der Stagingumgebung in den dedizierten Synapse-Pool zu laden.
Verwendung von Azure Pipelines
In Azure Synapse wird mithilfe von Pipelines der geordnete Satz von Aktivitäten für das Muster zum inkrementellen Laden von Daten definiert. Zum Starten der Pipeline werden Trigger verwendet, die manuell oder zu einem festgelegten Zeitpunkt ausgelöst werden können.
Transformieren der Daten
Da die Beispieldatenbank in unserer Referenzarchitektur nicht sehr groß ist, haben wir replizierte Tabellen ohne Partitionen erstellt. Bei Produktionsworkloads verbessert die Verwendung von verteilten Tabellen wahrscheinlich die Abfrageleistung. Weitere Informationen finden Sie im Leitfaden für das Entwerfen verteilter Tabellen in Azure Synapse. Die Beispielskripts führen die Abfragen mithilfe einer statischen Ressourcenklasse aus.
In einer Produktionsumgebung sollten Sie Stagingtabellen mit Round-Robin-Verteilung erstellen. Transformieren und verschieben Sie die Daten anschließend in Produktionstabellen mit gruppierten Columnstore-Indizes, da diese die beste Gesamtabfrageleistung bieten. Columnstore-Indizes sind für Abfragen optimiert, die viele Datensätze überprüfen. Columnstore-Indizes sind nicht für Singleton-Suchvorgänge (d. h. Suchen in einer einzelnen Zeile) geeignet. Wenn Sie häufig Singleton-Suchvorgänge ausführen müssen, können Sie einen nicht gruppierten Index einer Tabelle hinzufügen. Singleton-Suchvorgänge können mit einem nicht gruppierten Index erheblich schneller ausgeführt werden. Jedoch sind Singleton-Suchvorgänge in der Regel in Data Warehouse-Szenarien weniger gebräuchlich als OLTP-Workloads. Weitere Informationen finden Sie unter Indizieren von Tabellen in Azure Synapse.
Hinweis
Gruppierte Columnstore-Tabellen bieten keine Unterstützung für die Datentypen varchar(max), nvarchar(max) oder varbinary(max). Ziehen Sie in diesem Fall einen Heap- oder gruppierten Index in Erwägung. Sie können diese Spalten in eine separate Tabelle einfügen.
Verwenden von Power BI Premium für Zugriff, Modellierung und Visualisierung von Daten
Power BI Premium unterstützt verschiedene Optionen für die Verbindungsherstellung zu Datenquellen in Azure, insbesondere für den in Azure Synapse bereitgestellten Pool:
- Import: Die Daten werden in das Power BI-Modell importiert.
- DirectQuery: Daten werden direkt aus dem relationalen Speicher abgerufen.
- Zusammengesetztes Modell: Kombinieren Sie den Import für einige Tabellen mit dem DirectQuery-Ansatz für andere Tabellen.
Dieses Szenario wird mit dem DirectQuery-Dashboard umgesetzt, da der Umfang der verwendeten Daten und die Komplexität des Modells nicht sehr hoch sind, sodass wir ein gutes Benutzererlebnis bieten können. DirectQuery delegiert die Abfrage an die zugrunde liegende leistungsstarke Compute-Engine und nutzt umfangreiche Sicherheitsfunktionen für die Quelle. Auch stellt die Verwendung von DirectQuery sicher, dass die Ergebnisse immer mit den neuesten Quelldaten konsistent sind.
Der Importmodus bietet die schnellste Antwortzeit für Abfragen und sollte in Betracht gezogen werden, wenn das Modell vollständig in den Arbeitsspeicher von Power BI geladen werden kann, die Wartezeit zwischen den Datenaktualisierungen tolerierbar ist und möglicherweise einige komplexe Transformationen zwischen dem Quellsystem und dem endgültigen Modell erfolgen. In diesem Fall benötigen die Endbenutzer vollständigen Zugriff auf die neuesten Daten (ohne Verzögerungen durch die Power BI-Aktualisierung ) sowie auf alle historischen Daten. Dies überschreitet die Datenmenge, die ein Power BI-Dataset verarbeiten kann – je nach Größe der Kapazität zwischen 25 und 400 GB. Da das Datenmodell im dedizierten SQL-Pool bereits in einem Sternschema vorliegt und nicht transformiert werden muss, ist DirectQuery eine geeignete Wahl.
Mit Power BI Premium Gen2 können Sie große Modelle, paginierte Berichte, Bereitstellungspipelines und einen integrierten Analysis Services-Endpunkt nutzen. Sie können auch dedizierte Kapazitäten verwenden, die ein besonderes Wertversprechen bieten.
Wenn das BI-Modell wächst oder die Komplexität des Dashboards zunimmt, können Sie zu zusammengesetzten Modellen wechseln und beginnen, Teile von Nachschlagetabellen (über Hybridtabellen) und einige vorab aggregierte Daten zu importieren. Für importierte Datasets können Sie in Power BI die Zwischenspeicherung von Abfragen sowie die Verwendung von dualen Tabellen für die Speichermoduseigenschaft aktivieren.
Innerhalb des zusammengesetzten Modells fungieren die Datasets als virtuelle Passthrough-Ebene. Wenn der Benutzer mit Visualisierungen interagiert, generiert Power BI SQL-Abfragen an Synapse SQL-Pools mit Speichermodus „Dual“: im Speicher oder als direkte Abfrage, je nachdem, was effizienter ist. Die Engine entscheidet, wann sie von der In-Memory-Abfrage zur direkten Abfrage wechselt und überträgt die Logik an den Synapse SQL-Pool. Je nach Kontext der Abfragetabellen können diese entweder als zwischengespeicherte (importierte) oder nicht zwischengespeicherte zusammengesetzte Modelle fungieren. Wählen Sie aus, welche Tabelle im Arbeitsspeicher zwischengespeichert werden soll, kombinieren Sie Daten aus einer oder mehreren DirectQuery-Quellen und/oder kombinieren Sie Daten aus DirectQuery-Quellen und importierten Daten.
Empfehlungen: Bei Verwendung von DirectQuery über einen mit Azure Synapse Analytics bereitgestellten Pool:
- Verwenden Sie die Zwischenspeicherung von Resultsets von Azure Synapse, um Abfrageergebnisse in der Benutzerdatenbank für die wiederholte Verwendung zwischenzuspeichern, die Abfrageleistung im Millisekundenbereich zu verbessern und die Nutzung von Rechenressourcen zu reduzieren. Abfragen, die zwischengespeicherte Resultsets verwenden, verbrauchen keine Parallelitätsslots in Azure Synapse Analytics und werden daher nicht auf vorhandene Parallelitätslimits angerechnet.
- Nutzen Sie die materialisierten Sichten von Azure Synapse, um Daten wie eine Tabelle vorab zu berechnen, zu speichern und zu verwalten. Abfragen, bei denen alle oder eine Teilmenge der Daten in materialisierten Ansichten genutzt werden, können eine höhere Leistung bieten und müssen nicht direkt auf die definierte materialisierte Ansicht verweisen, um sie zu nutzen.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“.
Häufige Überschriften über Datenschutzverletzungen, Infektionen mit Schadsoftware und Einfügung von böswilligem Code gehören zu einer umfangreichen Liste von Sicherheitsaspekten für Unternehmen, die sich mit Cloudmodernisierung befassen. Unternehmenskunden benötigen einen Cloudanbieter oder eine Servicelösung zur Erfüllung ihrer Anforderungen, da sie sich keine Fehler leisten können.
In diesem Szenario werden die anspruchsvollsten Sicherheitsanforderungen durch eine Kombination aus Sicherheitskontrollen auf mehreren Ebenen erfüllt: Netzwerk, Identität, Datenschutz und Autorisierung. Der Großteil der Daten wird in einem von Azure Synapse bereitgestellten Pool gespeichert, wobei Power BI DirectQuery über SSO nutzt. Sie können Microsoft Entra ID für die Authentifizierung verwenden. Außerdem gibt es umfangreiche Sicherheitskontrollen für die Datenautorisierung von bereitgestellten Pools.
Einige der häufig gestellten Sicherheitsfragen sind:
- Wie kann ich kontrollieren, wer welche Daten sehen kann?
- Organisationen müssen ihre Daten schützen, um die Richtlinien des Bundes, der lokalen Gesetzgebung und des Unternehmens einzuhalten, um Risiken durch Datenverstöße zu minimieren. Azure Synapse bietet verschiedene Datenschutzfunktionen zum Erzielen von Compliance.
- Welche Optionen gibt es zum Überprüfen der Identität eines Benutzers?
- Azure Synapse unterstützt eine umfangreiche Palette von Funktionen, um über Zugriffssteuerung und Authentifizierung zu steuern, wer auf welche Daten zugreifen kann.
- Welche Netzwerksicherheitstechnologie kann ich verwenden, um die Integrität, Vertraulichkeit und den Zugriff auf meine Netzwerke und Daten zu schützen?
- Zum Schutz von Azure Synapse stehen Ihnen eine Reihe von Netzwerksicherheitsoptionen zur Verfügung.
- Welche Tools können Bedrohungen erkennen und mich benachrichtigen?
- Azure Synapse bietet viele Funktionen zur Bedrohungserkennung, darunter z. B. SQL-Überwachung, SQL-Bedrohungserkennung und Sicherheitsrisikobewertung, um Datenbanken zu überprüfen, zu schützen und zu überwachen.
- Wie kann ich die Daten in meinem Speicherkonto schützen?
- Azure Storage-Konten eignen sich ideal für Workloads, die schnelle und konsistente Antwortzeiten erfordern oder eine hohe Anzahl von Ein-/Ausgabevorgängen pro Sekunde (IOPS) aufweisen. Speicherkonten enthalten sämtliche Ihrer Azure Storage-Datenobjekte und bieten zahlreiche Optionen für die Speicherkontosicherheit.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
In diesem Abschnitt finden Sie Informationen zu den Preisen für die verschiedenen in dieser Lösung eingesetzten Dienste. Darüber hinaus werden die für dieses Szenario getroffenen Entscheidungen anhand eines Beispieldatasets erläutert.
Azure Synapse
Mit der serverlosen Architektur von Azure Synapse Analytics können Sie Ihre Compute- und Speicherebene unabhängig voneinander skalieren. Computeressourcen werden nutzungsbasiert abgerechnet und können nach Bedarf skaliert oder angehalten werden. Speicherressourcen werden nach Terabyte abgerechnet. Ihre Kosten steigen also, wenn Sie mehr Daten erfassen.
Azure Pipelines
Einzelheiten zu den Preisen für Pipelines in Azure Synapse finden Sie auf der Registerkarte Datenintegration der Seite Azure Synapse – Preise. Es gibt drei Hauptkomponenten, die den Preis einer Pipeline beeinflussen:
- Datenpipelineaktivitäten und Integration Runtime-Laufzeit (in Stunden)
- Clustergröße für Datenflüsse und Ausführung
- Betriebskosten
Der Preis variiert je nach Komponenten oder Aktivitäten, Häufigkeit und Anzahl der Integration Runtime-Einheiten.
Für das Beispieldataset wird die von Azure gehostete Standard-Integration Runtime, die Aktivität zum Kopieren von Daten für den Kern der Pipeline, nach einem täglichen Zeitplan für alle Entitäten (Tabellen) in der Quelldatenbank ausgelöst. Das Szenario enthält keine Datenflüsse. Es fallen keine Betriebskosten an, da pro Monat weniger als 1 Million Vorgänge mit Pipelines durchgeführt werden.
Dedizierter Azure Synapse-Pool und -Speicher
Einzelheiten zu den Preisen für den dedizierten Azure Synapse-Pool finden Sie auf der Registerkarte Data Warehousing der Seite Azure Synapse – Preise. Beim Verbrauchsmodell „Dedicated“ erfolgt die Abrechnung pro bereitgestellter DWU-Einheit und nach Betriebszeit pro Stunde. Ein weiterer Faktor sind die Kosten für die Datenspeicherung: Größe der ruhenden Daten + Momentaufnahmen + Georedundanz (falls vorhanden).
Für das Beispieldataset können Sie 500 DWU bereitstellen, womit eine gute Leistung für die Analysedatenlast gewährleistet ist. Sie können die Computeressourcen während der Geschäftszeiten zur Berichterstattung ausführen. Bei einem Wechsel in die Produktion ist die reservierte Data Warehouse-Kapazität eine attraktive Option für das Kostenmanagement. Zur Maximierung der in den vorangegangenen Abschnitten erläuterten Kosten- und Leistungsmetriken sollten verschiedene Techniken angewendet werden.
Blob Storage
Erwägen Sie die Nutzung von reservierten Kapazitäten für Azure Storage, um die Speicherkosten zu senken. Bei diesem Modell erhalten Sie einen Rabatt, wenn Sie eine feste Speicherkapazität für ein oder drei Jahre reservieren. Weitere Informationen finden Sie unter Optimieren der Kosten für Blobspeicher mit reservierter Kapazität.
In diesem Szenario wird kein beständiger Speicher verwendet.
Power BI Premium
Einzelheiten zu den Preisen von Power BI Premium finden Sie auf der Seite Power BI – Preise.
In diesem Szenario werden Power BI Premium-Arbeitsbereiche mit einer Reihe von integrierten Leistungsverbesserungen verwendet, um anspruchsvolle Analyseanforderungen zu erfüllen.
Optimaler Betrieb
Die Säule „Optimaler Betrieb“ deckt die Betriebsprozesse ab, die für die Bereitstellung einer Anwendung und deren Ausführung in der Produktion sorgen. Weitere Informationen finden Sie unter Übersicht über die Säule „Optimaler Betrieb“.
DevOps-Empfehlungen
Erstellen Sie separate Ressourcengruppen für Produktions-, Entwicklungs- und Testumgebungen. Separate Ressourcengruppen erleichtern das Verwalten von Bereitstellungen, das Löschen von Testbereitstellungen und das Zuweisen von Zugriffsrechten.
Platzieren Sie jede Workload in einer separaten Bereitstellungsvorlage, und speichern Sie die Ressourcen in Quellcodeverwaltungssystemen. Sie können die Vorlagen gemeinsam oder einzeln im Rahmen eines CI/CD-Prozesses (Continuous Integration/Continuous Delivery) bereitstellen. Dies erleichtert den Automatisierungsprozess. In dieser Architektur sind vier Hauptworkloads enthalten:
- Der Data Warehouse-Server und zugehörige Ressourcen
- Azure Synapse-Pipelines
- Power BI-Ressourcen: Dashboards, Apps, Datasets
- Ein simuliertes Lokal-zu-Cloud-Szenario
Streben Sie an, für jede der Workloads eine eigene Bereitstellungsvorlage zu erstellen.
Ziehen Sie ein Staging Ihrer Workloads in Betracht, wo dies sinnvoll ist. Nehmen Sie die Bereitstellung in verschiedenen Stages vor, und führen Sie auf jeder Stage Überprüfungen durch, bevor Sie zur nächsten Stage wechseln. Auf diese Weise können Sie Updates auf kontrollierte Weise in Ihre Produktionsumgebungen einspielen und unvorhergesehene Probleme bei der Bereitstellung minimieren. Nutzen Sie die Strategien der Blau-Grün-Bereitstellung und Canary-Releases, um Liveproduktionsumgebungen zu aktualisieren.
Sorgen Sie für eine gute Rollbackstrategie für die Behandlung fehlerhafter Bereitstellungen. Sie können beispielsweise automatisch eine frühere, erfolgreiche Bereitstellung aus Ihrem Bereitstellungsverlauf bereitstellen. Siehe das Flag
--rollback-on-errorin der Azure CLI.Azure Monitor ist die empfohlene Option zum Analysieren der Leistung Ihres Data Warehouse und der gesamten Azure Analytics-Plattform; hiermit verfügen Sie über eine integrierte Überwachungsumgebung. Azure Synapse Analytics bietet eine Überwachungsfunktion im Azure-Portal, die Erkenntnisse zu Ihrer Data Warehouse-Workload liefert. Das Azure-Portal ist das empfohlene Tool zum Überwachen Ihrer Data Warehouse-Instanz, weil es eine konfigurierbare Aufbewahrungsdauer, Warnungen, Empfehlungen und anpassbare Diagramme und Dashboards für Metriken und Protokolle bietet.
Schnellstart
- Portal: Proof of Concept für Azure Synapse
- Azure CLI: Erstellen eines Azure Synapse-Arbeitsbereich mit der Azure CLI
- Terraform: Modernes Data Warehousing mit Terraform und Microsoft Azure
Effiziente Leistung
Leistungseffizienz ist die Fähigkeit Ihrer Workload, auf effiziente Weise eine den Anforderungen der Benutzer entsprechende Skalierung auszuführen. Weitere Informationen finden Sie unter Übersicht über die Säule „Leistungseffizienz“.
In diesem Abschnitt finden Sie Einzelheiten zu den Größenentscheidungen für dieses Dataset.
In Azure Synapse bereitgestellter Pool
Es gibt eine Reihe von Data Warehouse-Konfigurationen, aus denen Sie wählen können.
| Data Warehouse-Einheiten | Anzahl von Serverknoten | Anzahl von Verteilungen pro Knoten |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Damit die Leistungsvorteile der Skalierung spürbar werden, insbesondere bei größeren Data Warehouse-Einheiten, verwenden Sie mindestens ein 1-TB-Dataset. Ermitteln Sie durch Hoch- und Herunterskalieren die optimale Anzahl von Data Warehouse-Einheiten für Ihren dedizierten SQL-Pool. Führen Sie nach dem Laden Ihrer Daten einige Abfragen mit verschiedenen Mengen an Datawarehouse-Einheiten aus. Da die Skalierung schnell erfolgt, können Sie innerhalb einer Stunde verschiedene Leistungsebenen ausprobieren.
Ermitteln der optimalen Anzahl von Data Warehouse-Einheiten
Bei einem dedizierten SQL-Pool in der Entwicklung sollten Sie zunächst eine kleinere Anzahl von Data Warehouse-Einheiten auswählen. Ein guter Startpunkt ist DW400c oder DW200c. Überwachen Sie die Anwendungsleistung, und beobachten Sie dabei die Anzahl der ausgewählten Data Warehouse-Einheiten im Vergleich zur beobachteten Leistung. Gehen Sie von einer linearen Skalierung aus, und bestimmen Sie, um wie viel Sie die Data Warehouse-Einheiten erhöhen oder verringern müssen. Nehmen Sie weitere Anpassungen vor, bis Sie die optimale Leistungsstufe für Ihre geschäftlichen Anforderungen erreichen.
Skalieren des Synapse SQL-Pools
- Skalieren von Computeressourcen für den Synapse SQL-Pool mit dem Azure-Portal
- Skalieren von Computeressourcen für den dedizierten SQL-Pool mit Azure PowerShell
- Skalieren von Computeressourcen für einen dedizierten SQL-Pool in Azure Synapse Analytics mithilfe von T-SQL
- Anhalten, Überwachen und Automatisieren
Azure Pipelines
Informationen zur Skalierbarkeit und Leistungsoptimierung von Pipelines in Azure Synapse und der verwendeten Copy-Aktivität finden Sie im Leitfaden zu Leistung und Skalierbarkeit der Copy-Aktivität.
Power BI Premium
Dieser Artikel verwendet Power BI Premium Gen 2 zur Veranschaulichung der BI-Funktionen. Die Kapazitäts-SKUs für Power BI Premium reichen derzeit von P1 (acht virtuelle Kerne) bis P5 (128 virtuelle Kerne). Der beste Ansatz zur Auswahl der benötigten Kapazität ist eine Bewertung der Kapazitätsauslastung, die Installation der Gen 2-Metrik-App zur fortlaufenden Überwachung und die Verwendung der Autoskalierung mit Power BI Premium.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Galina Polyakova | Senior Cloud Solution Architect
- Noah Costar | Cloud Solution Architect
- George Stevens | Cloud Solution Architect
Andere Mitwirkende:
- Jim McLeod | Cloud Solution Architect
- Miguel Myers | Senior Program Manager
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Was ist Power BI Premium?
- Was ist Microsoft Entra ID?
- Zugreifen auf Azure Data Lake Storage Gen2 und Blob Storage mit Azure Databricks
- Was ist Azure Synapse Analytics?
- Pipelines und Aktivitäten in Azure Data Factory und Azure Synapse Analytics
- Was ist Azure SQL?