Azure Storage-Anbieter (Azure Functions)
In diesem Dokument werden die Merkmale des Durable Functions Azure Storage-Anbieters beschrieben, wobei der Schwerpunkt auf den Aspekten Leistung und Skalierbarkeit liegt. Der Azure Storage-Anbieter ist der Standardanbieter. Er speichert Instanzzustände und Warteschlangen in einem Azure Storage-Konto (klassisch).
Hinweis
Weitere Informationen zu den unterstützten Speicheranbietern für Durable Functions und deren Vergleich finden Sie unter Durable Functions-Speicheranbieter-Dokumentation.
Im Azure Storage-Anbieter werden alle Funktionsausführungen von Azure Storage-Warteschlangen gesteuert. Orchestrierungs- und Entitätsstatus und -verlauf werden in Azure-Tabellen gespeichert. Azure-Blobs und Blob-Leases werden verwendet, um Orchestrierungsinstanzen und Entitäten auf mehrere App-Instanzen (auch als Worker oder einfach VMsbezeichnet) zu verteilen. In diesem Abschnitt werden die verschiedenen Azure Storage Artefakte und deren Auswirkungen auf Leistung und Skalierbarkeit ausführlicher erläutert.
Speicherdarstellung
Ein Aufgabenhub bewahrt alle Instanzzustände und alle Nachrichten dauerhaft auf. Eine kurze Übersicht darüber, wie diese verwendet werden, um den Fortschritt einer Orchesterung zu verfolgen, finden Sie im Ausführungsbeispiel des Aufgabenhubs.
Der Azure Storage-Anbieter stellt den Aufgabenhub im Speicher mithilfe der folgenden Komponenten dar:
- Zwischen zwei und drei Azure-Tabellen. Zwei Tabellen werden verwendet, um den Verlauf und den Zustand von Instanzen darzustellen. Wenn der Tabellenpartitions-Manager aktiviert ist, wird eine dritte Tabelle zum Speichern von Partitionsinformationen eingeführt.
- Eine Azure-Warteschlange speichert die Aktivitätsnachrichten.
- Mindestens eine Azure-Warteschlange speichert die Instanznachrichten. Jede dieser sogenannten Steuerungswarteschlangen stellt eine Partition dar, der basierend auf dem Hash der Instanz-ID eine Teilmenge aller Instanznachrichten zugeordnet wird.
- Einige zusätzliche Blob-Container, die für Leaseblobs und/oder große Nachrichten verwendet werden.
Beispielsweise enthält ein Aufgabenhub mit dem Namen xyz mit PartitionCount = 4 die folgenden Warteschlangen und Tabellen:

Im Folgenden werden diese Komponenten und ihre Rolle genauer beschrieben.
Verlaufstabelle
Die Verlaufstabelle ist eine Azure Storage-Tabelle, die die Verlaufsereignisse für alle Orchestrierungsinstanzen innerhalb eines Aufgabenhubs enthält. Der Name dieser Tabelle hat das Format „AufgabenhubnameHistory“. Während Instanzen ausgeführt werden, werden dieser Tabelle neue Zeilen hinzugefügt. Der Partitionsschlüssel dieser Tabelle wird von der Instanzen-ID der Orchestrierung abgeleitet. Instanz-IDs sind standardmäßig zufällig und stellen eine optimale Verteilung interner Partitionen in Azure Storage sicher. Der Zeilenschlüssel für diese Tabelle ist eine Sequenznummer, die zum Sortieren der Verlaufsereignisse verwendet wird.
Wenn eine Orchestrierungsinstanz ausgeführt werden muss, werden die entsprechenden Zeilen der Verlaufstabelle mithilfe einer Bereichsabfrage innerhalb einer einzelnen Tabellenpartition in den Arbeitsspeicher geladen. Diese Verlaufsereignisse werden dann im Orchestratorfunktionscode erneut wiedergegeben, um diesen wieder in den Zustand des vorherigen Prüfpunkts zu versetzen. Die Verwendung des Ausführungsverlaufs zum Neuerstellen des Zustands auf diese Weise hängt vom Ereignissourcingmuster ab.
Tipp
In der Tabelle Verlauf gespeicherte Daten der Orchestrierung enthalten Ausgabenutzlasten von Aktivitäts- und Unterorchestrierungsfunktionen. Nutzlasten von externen Ereignissen werden auch in der Verlaufstabelle gespeichert. Da der vollständige Verlauf jedes Mal in den Arbeitsspeicher geladen wird, wenn ein Orchestrator ausgeführt werden muss, kann ein ausreichend großer Verlauf zu einer erheblichen Arbeitsspeicherauslastung auf einem bestimmten virtuellen Computer führen. Die Länge und Größe des Orchestrierungsverlaufs kann reduziert werden, indem große Orchestrationen in mehrere Sub-Orchestrationen aufgeteilt werden oder indem die Größe der Ausgaben reduziert wird, die von der Aktivität und den von ihr aufgerufenen Sub-Orchestratorfunktionen zurückgegeben werden. Alternativ können Sie die Speicherauslastung verringern, indem Sie die Parallelitätsdrosselungen pro virtuellem Computer verringern, um zu begrenzen, wie viele Orchestrierungen gleichzeitig in den Arbeitsspeicher geladen werden.
Instanzentabellen
Die Instanzentabelle enthält die Statuswerte aller Orchestrierungs- und Entitätsinstanzen innerhalb eines Aufgabenhubs. Während der Erstellung von Instanzen werden dieser Tabelle neue Zeilen hinzugefügt. Der Partitionsschlüssel dieser Tabelle ist die Orchestrierungsinstanz-ID oder der Entitätsschlüssel, und der Zeilenschlüssel ist eine leere Zeichenfolge. Es gibt eine Zeile pro Orchestrierungs- oder Entitätsinstanz.
Diese Tabelle wird verwendet, um Instanzabfrageanforderungen vom Code sowie die HTTP-Statusabfrage-API zu erfüllen. Sie wird letztendlich konsistent mit dem Inhalt der oben genannten Verlaufstabelle gehalten. Die Verwendung einer separaten Azure Storage-Tabelle zur wirksamen Erfüllung von Instanzabfragevorgängen auf diese Weise hängt vom CQRS-Muster (Command and Query Responsibility Segregation) ab.
Tipp
Durch die Partitionierung der Instanztabelle können Millionen von Orchestrierungsinstanzen gespeichert werden, ohne dass sich dies auf die Laufzeitleistung oder -skalierung auswirken kann. Die Anzahl der Instanzen kann sich jedoch erheblich auf die Leistung von Abfragen mit mehreren Instanzen auswirken. Um die Menge der in diesen Tabellen gespeicherten Daten zu steuern, sollten Sie in regelmäßigen Abständen alte Instanzdaten bereinigen.
Partitionstabelle
Hinweis
Diese Tabelle nur dann im Aufgabenhub angezeigt, wenn Table Partition Manager aktiviert ist. Um sie anzuwenden, konfigurieren Sie die useTablePartitionManagement-Einstellung in der host.json-Datei Ihrer App.
Die Partitionstabelle speichert den Status der Partitionen für die Durable Functions-App und wird verwendet, um die Partitionen auf die Worker Ihrer App zu verteilen. Für jede Partition ist eine Zeile vorhanden.
Warteschlangen
Sowohl Orchestrator-, Entitäts- als auch Aktivitätsfunktionen werden durch interne Warteschlangen im Aufgabenhub der Funktions-App ausgelöst. Diese Verwendung von Warteschlangen bietet eine zuverlässige „At-Least-Once“-Garantie bei der Nachrichtenübermittlung. Es gibt zwei Arten von Warteschlangen in Durable Functions: die Steuerelement-Warteschlange ( control queue) und die Warteschlange für Arbeitsaufgaben (work-item queue).
Warteschlange für Arbeitsaufgaben
In Durable Functions gibt es eine Warteschlange für Arbeitsaufgaben pro Aufgabenhub. Dies ist eine grundlegende Warteschlange, und sie verhält sich ähnlich wie jede andere queueTrigger-Warteschlange in Azure Functions. Diese Warteschlange wird verwendet, um zustandslose Aktivitätsfunktionen auszulösen. Dabei wird jeweils eine einzelne Nachricht aus der Warteschlange entfernt. Jede dieser Nachrichten enthält Eingaben der Aktivitätsfunktionen und zusätzliche Metadaten, z.B. welche Funktion auszuführen ist. Wenn eine Durable Functions-Anwendung für mehrere virtuelle Computer horizontal hochskaliert wird, konkurrieren alle diese virtuellen Computer miteinander, um Arbeitsaufgaben aus der Warteschlange für Arbeitsaufgaben abzurufen.
Steuerelement-Warteschlange(n)
In Durable Functions gibt es mehrere Steuerelement-Warteschlangen pro Aufgabenhub. Eine Steuerelement-Warteschlange ist komplexer als die einfachere Warteschlange für Arbeitsaufgaben. Steuerwarteschlangen werden verwendet, um zustandsbehaftete Orchestrator- und Entitätsfunktionen auszulösen. Da es sich bei den Orchestrator- und Entitätsfunktionsinstanzen um zustandsbehaftete Singletons handelt, ist es wichtig, dass jede Orchestrierung oder Entität nur von einem Worker gleichzeitig verarbeitet wird. Um diese Einschränkung zu erreichen, wird jede Orchestrierungsinstanz oder -entität einer einzelnen Steuerungswarteschlange zugewiesen. Für diese Steuerungswarteschlangen wird ein Lastenausgleich über Worker hinweg vorgenommen, um sicherzustellen, dass jede Warteschlange jeweils nur von einem Worker verarbeitet wird. Weitere Informationen zu diesem Verhalten finden Sie in den folgenden Abschnitten.
Steuerelement-Warteschlangen enthalten eine Vielzahl von Orchestrierung-Lebenszyklus-Nachrichtentypen. Beispiele hierfür sind orchestrator control messages (Orchestratorsteuerungsmeldungen), Aktivitätsfunktion-Antwort-Nachrichten und Timernachrichten. Bis zu 32 Nachrichten werden in einer einzelnen Abfrage aus einer Steuerelement-Warteschlange entfernt. Diese Nachrichten enthalten Nutzlastdaten sowie Metadaten, einschließlich der Orchestrierungsinstanz, für die eine Nachricht jeweils vorgesehen ist. Wenn mehrere aus der Warteschlange entfernte Nachrichten für dieselbe Orchestrierungsinstanz vorgesehen sind, werden sie als Batch verarbeitet.
Steuerungswarteschlangennachrichten werden ständig mithilfe eines Hintergrund-Threads abgefragt. Die Batchgröße jeder Warteschlangen-Umfrage wird durch die Einstellung controlQueueBatchSize in host.json gesteuert und hat den Standardwert 32 (der von Azure-Warteschlangen unterstützte Höchstwert). Die maximale Anzahl vorab abgerufener Nachrichten der Steuerelementwarteschlange, die im Arbeitsspeicher gepuffert werden, wird durch die Einstellung controlQueueBufferThreshold in host.json gesteuert. Der Standardwert für controlQueueBufferThreshold variiert abhängig von einer Vielzahl von Faktoren, einschließlich der Art des Hosting-Plans. Weitere Informationen zu diesen Einstellungen finden Sie in der Dokumentation host.json Schema.
Tipp
Durch Erhöhen des Werts für controlQueueBufferThreshold kann eine einzelne Orchestrierung oder Entität Ereignisse schneller verarbeiten. Die Erhöhung dieses Werts kann jedoch auch zu einer höheren Speicherauslastung führen. Die höhere Speicherauslastung ist zum Teil darauf zurückzuführen, dass mehr Nachrichten aus der Warteschlange abgerufen werden und zum Teil darauf, dass mehr Orchestrierungsverläufe in den Arbeitsspeicher abgerufen werden. Das Reduzieren des Werts für controlQueueBufferThreshold kann daher eine effektive Möglichkeit sein, die Speicherauslastung zu reduzieren.
Abrufen von Warteschlangen
Die Durable Task-Erweiterung implementiert einen zufälligen exponentiellen Backoffalgorithmus, um die Auswirkungen des Abrufs von Warteschlangen im Leerlauf auf Speichertransaktionskosten zu reduzieren. Wenn eine Nachricht gefunden wird, überprüft die Laufzeit sofort ob eine andere Nachricht vorhanden ist. Wenn keine Nachricht gefunden wird, wartet sie für eine Zeit, bevor der Versuch wiederholt wird. Nach aufeinander folgenden fehlerhaften Versuchen, eine Warteschlangennachricht abzurufen, erhöht sich die Wartezeit immer mehr, bis die maximale Wartezeit (standardmäßig eine 30 Sekunden) erreicht ist.
Die maximale Abrufverzögerung kann über die Eigenschaft maxQueuePollingInterval in der Datei host.json konfiguriert werden. Die Festlegung dieser Eigenschaft auf einen höheren Wert kann zu höherer Latenz bei der Nachrichtenverarbeitung führen. Eine höhere Latenz wird nur nach Zeiträumen ohne Aktivität erwartet. Die Festlegung dieser Eigenschaft auf einen niedrigeren Wert kann aufgrund vermehrter Speichertransaktionen zu höheren Speicherkosten führen.
Hinweis
Bei der Ausführung in Verbrauchs- und Premium-Tarifen von Azure Functions ruft der Azure Functions-Skalierungscontroller alle Steuerelement- und Arbeitselement-Warteschlangen einmal alle 10 Sekunden ab. Dieser zusätzliche Abruf ist erforderlich, um zu ermitteln, wann die Instanzen der Funktions-Apps aktiviert und Skalierungsentscheidungen getroffen werden sollen. Zum Zeitpunkt der Erstellung dieses Artikels ist dieses Intervall von 10 Sekunden konstant und kann nicht konfiguriert werden.
Verzögerungen beim Starten der Orchestrierung
Orchestrierungsinstanzen werden gestartet, indem eine ExecutionStarted-Nachricht zu einer der Steuerungswarteschlangen des Taskhubs hinzugefügt wird. Unter bestimmten Umständen sind möglicherweise Verzögerungen von mehreren Sekunden zwischen der geplanten Ausführung einer Orchestrierung und der tatsächlichen Ausführung zu beobachten. Während dieses Zeitraums verbleibt die Orchestrierungsinstanz im Zustand Pending. Für diese Verzögerungen gibt es zwei mögliche Gründe:
Steuerungswarteschlangen im Rückstand: Wenn die Steuerungswarteschlange für diese Instanz eine große Anzahl von Nachrichten enthält, kann es eine Weile dauern, bis die
ExecutionStarted-Nachricht von der Runtime empfangen und verarbeitet wird. Nachrichtenrückstände können entstehen, wenn Orchestrierungen viele Ereignisse gleichzeitig verarbeiten. Ereignisse, die zur Steuerungswarteschlange hinzugefügt werden, umfassen Startereignisse für Orchestrierungen, den Abschluss von Aktivitäten, permanente Timer, die Beendigung und externe Ereignisse. Wenn diese Verzögerungen unter normalen Umständen auftreten, sollten Sie das Erstellen eines neuen Taskhubs mit einer größeren Anzahl von Partitionen in Erwägung ziehen. Das Konfigurieren von mehr Partitionen bewirkt, dass die Runtime weitere Steuerungswarteschlangen für die Lastverteilung erstellt. Jede Partition entspricht 1:1 einer Steuerungswarteschlange mit maximal 16 Partitionen.Verzögerungen durch Backoffabruf: Eine weitere häufige Ursache für Verzögerungen bei Orchestrierungen ist das zuvor beschriebene Backoffabrufverhalten für Steuerungswarteschlangen. Diese Verzögerung wird jedoch nur erwartet, wenn eine App auf zwei oder mehr Instanzen aufskaliert wird. Wenn nur eine App-Instanz vorhanden ist oder die App-Instanz, die die Orchestrierung startet, die Instanz ist, die auch die Zielsteuerungswarteschlange abruft, entstehen bei Warteschlangenabrufen keine Verzögerungen. Sie können Verzögerungen durch Backoffabruf reduzieren, indem Sie die Einstellungen für host.json wie zuvor beschrieben aktualisieren.
BLOBs
In den meisten Fällen nutzt Durable Functions keine Azure Storage-Blobs für das Speichern der Daten. Allerdings gelten für Warteschlangen und Tabellen Größenbeschränkungen, die verhindern können, dass Durable Functions alle erforderlichen Daten dauerhaft in einer Speicherzeile oder Warteschlangennachricht speichern kann. Wenn beispielsweise ein Datenelement, das in einer Warteschlange gespeichert werden soll, nach der Serialisierung größer als 45 KB ist, werden die Daten von Durable Functions komprimiert und stattdessen in einem Blob gespeichert. Wenn Daten auf diese Weise in Blob Storage gespeichert werden, speichert Durable Functions einen Verweis auf dieses Blob in der Tabellenzeile bzw. der Warteschlangennachricht. Wenn Durable Functions die Daten abrufen muss, erfolgt dies automatisch aus dem Blob. Diese Blobs werden im Blobcontainer <taskhub>-largemessages gespeichert.
Überlegungen zur Leistung
Die zusätzlichen Schritte für die Komprimierung und Speicherung im Blob bei großen Nachrichten können hohe Kosten in Bezug auf CPU und E/A-Latenz verursachen. Darüber hinaus muss Durable Functions persistente Daten in den Arbeitsspeicher laden, und zwar möglicherweise für viele verschiedene Funktionsausführungen gleichzeitig. Folglich kann das Beibehalten umfangreicher Nutzdaten auch zu einer hohen Speicherauslastung führen. Um den Arbeitsspeicherverbrauch zu minimieren, sollten Sie umfangreiche Nutzdaten manuell speichern (z. B. in Blob Storage) und stattdessen Verweise auf diese Daten übergeben. Auf diese Weise kann Ihr Code die Daten erst bei Bedarf laden und so redundante Lasten während der Wiedergabe von Orchestratorfunktionen vermeiden. Das Speichern von Nutzdaten auf lokalen Datenträgern wird jedoch nicht empfohlen, da die Verfügbarkeit des Datenträgers nicht garantiert ist. Dies liegt daran, dass Funktionen während ihrer Lebensdauer auf unterschiedlichen VMs ausgeführt werden können.
Auswahl des Speicherkontos
Die in Durable Functions verwendeten Warteschlangen, Tabellen und Blobs werden in einem konfigurierten Azure Storage-Konto erstellt. Das zu verwendende Konto kann über die Einstellung durableTask/storageProvider/connectionStringName (oder die Einstellung durableTask/azureStorageConnectionStringName in Durable Functions 1.x) in der Datei host.json angegeben werden.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"connectionStringName": "MyStorageAccountAppSetting"
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"azureStorageConnectionStringName": "MyStorageAccountAppSetting"
}
}
}
Wenn kein Konto angegeben ist, wird das Standardspeicherkonto AzureWebJobsStorage verwendet. Bei leistungsabhängigen Workloads wird jedoch die Konfiguration eines nicht standardmäßigen Speicherkontos empfohlen. In Durable Functions wird Azure Storage stark ausgelastet. Durch die Nutzung eines dedizierten Speicherkontos wird die Speicherverwendung durch Durable Functions von der internen Verwendung durch den Azure Functions-Host getrennt.
Hinweis
Für die universelle Verwendung des Azure Storage-Anbieters sind allgemeine Azure Storage-Standardkonten erforderlich. Alle anderen Speicherkontotypen werden nicht unterstützt. Es wird dringend empfohlen, universelle Legacy-v1-Speicherkonten für Durable Functions zu verwenden. Die neueren v2-Speicherkonten können für Durable Functions Workloads erheblich teurer sein. Weitere Informationen zu Azure Storage-Kontotypen finden Sie in der Dokumentation unter Speicherkontoübersicht.
Horizontales Skalieren des Orchestrators
Obwohl Aktivitätsfunktionen unendlich aufskaliert werden können, indem weitere VMs elastisch hinzugefügt werden, sind einzelne Orchestratorinstanzen und -entitäten auf eine einzelne Partition beschränkt, und die maximale Anzahl von Partitionen wird durch die partitionCount-Einstellung in Ihrer Datei host.json begrenzt.
Hinweis
Im Allgemeinen sollten Orchestratorfunktionen einfach sein und keine große Rechenleistung in Anspruch nehmen. Daher ist es nicht erforderlich, eine große Anzahl von Steuerwarteschlange-Partitionen zu erstellen, um einen erhöhten Durchsatz für Orchestrierungen zu erzielen. Der größte Teil der intensiven Vorgänge sollte in zustandslosen Aktivitätsfunktionen erfolgen, die unbegrenzt horizontal hochskaliert werden können.
Die Anzahl der Steuerelement-Warteschlangen wird in der Datei host.json definiert. Mit dem folgenden Beispielcodeausschnitt in „host.json“ wird die durableTask/storageProvider/partitionCount-Eigenschaft (oder durableTask/partitionCount in Durable Functions 1.x) auf 3 festgelegt. Beachten Sie, dass es so viele Steuerungswarteschlangen gibt, wie Partitionen vorhanden sind.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Ein Aufgabenhub kann mit 1 bis 16 Partitionen konfiguriert werden. Wenn keine Anzahl angegeben ist, werden standardmäßig 4 Partitionen verwendet.
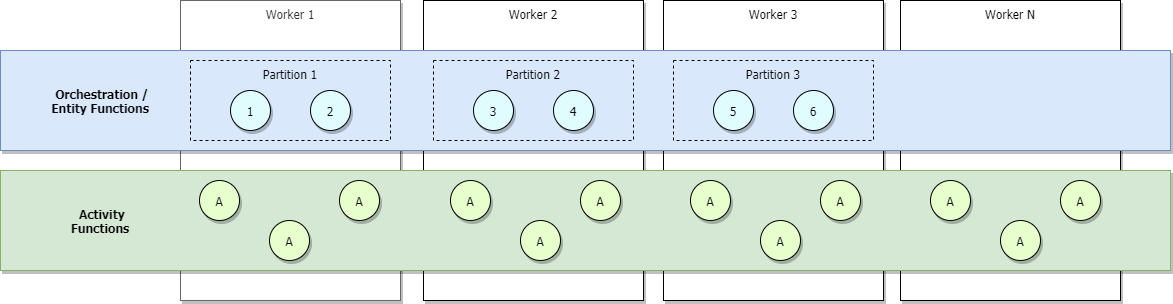
Bei Szenarios mit geringem Datenverkehr wird Ihre Anwendung abskaliert, sodass Partitionen von einer geringen Anzahl von Workern verwaltet werden. Sehen Sie sich als Beispiel das folgende Diagramm an.

Im vorherigen Diagramm ist zu sehen, dass bei den Orchestratoren 1 bis 6 über Partitionen hinweg ein Lastenausgleich erfolgt. Ebenso erfolgt bei Partitionen, ähnlich wie für Aktivitäten, über Worker hinweg ein Lastenausgleich. Der Lastenausgleich bei Partitionen über Worker hinweg erfolgt unabhängig von der Anzahl von Orchestratoren, die gestartet werden.
Wenn Sie den Verbrauchstarif oder den Tarif „Elastisch Premium“ von Azure Functions verwenden, oder wenn Sie Lastenausgleich mit automatischer Skalierung konfiguriert haben, werden mit zunehmendem Datenverkehr mehr Worker zugeordnet, und es erfolgt schließlich ein Lastenausgleich für die Partitionen über alle Worker hinweg. Wenn wir weiterhin aufskalieren, wird schließlich jede Partition von einem einzelnen Worker verwaltet. Für Aktivitäten erfolgt hingegen weiterhin der Lastenausgleich über alle Worker hinweg. Dies ist in der folgenden Abbildung zu sehen.
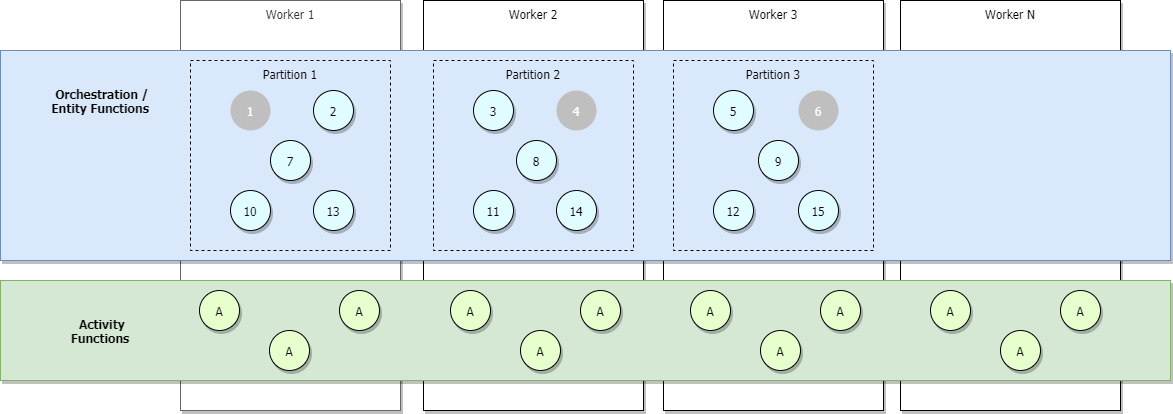
Die Obergrenze der maximalen Anzahl gleichzeitiger aktiver Orchestrierungen zu jedem Zeitpunkt ist gleich der Anzahl der Ihrer Anwendung zugeordneten Worker, multipliziert mit Ihrem Wert für maxConcurrentOrchestratorFunctions. Diese Obergrenze kann präziser bestimmt werden, wenn Ihre Partitionen vollständig über die Worker hinweg aufskaliert sind. Bei vollständiger Aufskalierung, und weil jeder Worker nur über eine einzelne Functions-Hostinstanz verfügt, entspricht die maximale Anzahl aktiver gleichzeitiger Orchestratorinstanzen Ihrer Anzahl von Partitionen, multipliziert mit Ihrem Wert für maxConcurrentOrchestratorFunctions.
Hinweis
In diesem Kontext bedeutet aktiv, dass eine Orchestrierung oder Entität in den Arbeitsspeicher geladen wird und neue Ereignisseverarbeitet. Wenn die Orchestrierung oder Entität auf weitere Ereignisse wartet, z. B. den Rückgabewert einer Aktivitätsfunktion, wird sie aus dem Arbeitsspeicher entladen und nicht mehr als aktiv betrachtet. Orchestrierungen und Entitäten werden anschließend nur dann erneut in den Arbeitsspeicher geladen, wenn neue Ereignisse verarbeitet werden müssen. Es gibt praktisch keine totale maximale Anzahl von Gesamtorchestrierungen oder Entitäten, die auf einem einzelnen virtuellen Computer ausgeführt werden können, auch wenn sie sich alle im Status „Wird ausgeführt“ befinden. Die einzige Einschränkung ist die Anzahl gleichzeitig aktiver Orchestrierungs- oder Entitätsinstanzen.
Die folgende Abbildung veranschaulicht ein vollständig aufskaliertes Szenario, in dem weitere Orchestratoren hinzugefügt werden, wovon aber einige inaktiv sind (grau dargestellt).
Bei der horizontalen Skalierung werden Steuerungswarteschlangen-Leases möglicherweise neu über Functions-Host-Instanzen verteilt, um sicherzustellen, dass Partitionen gleichmäßig verteilt werden. Diese Leases werden intern als Blob Storage-Leases implementiert und stellen sicher, dass jede einzelne Orchestrierungsinstanz oder -entität jeweils nur in einer einzelnen Hostinstanz ausgeführt wird. Wenn ein Aufgabenhub mit drei Partitionen (und somit drei Steuerungswarteschlangen) konfiguriert ist, kann der Lastenausgleich für die Orchestrierungsinstanzen und -entitäten über alle drei Lease-Hostinstanzen ausgeführt werden. Zusätzliche virtuelle Computer können zum Erhöhen der Kapazität für die Ausführung der Aktivitätsfunktion hinzugefügt werden.
Das folgende Diagramm veranschaulicht, wie der Azure Functions-Host mit den Speicherentitäten in einer horizontal skalierten Umgebung interagiert.
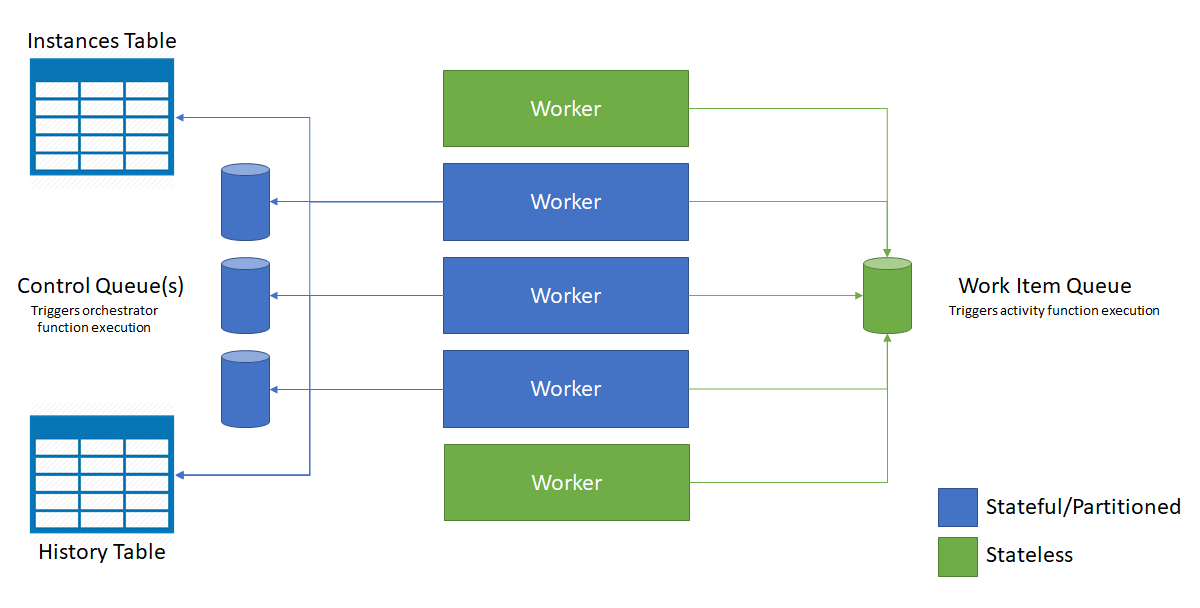
Wie im Diagramm oben dargestellt, konkurrieren alle virtuellen Computer um Nachrichten in der Warteschlange für Arbeitsaufgaben. Allerdings können nur drei virtuelle Computer Nachrichten aus Steuerelement-Warteschlangen abrufen, und jeder virtuelle Computer sperrt eine einzige Steuerelement-Warteschlange.
Orchestrierungsinstanzen und Entitäten sind auf alle Steuerwarteschlangeninstanzen verteilt. Die Verteilung erfolgt durch Ausführen einer Hashfunktion mit der Instanz-ID der Orchestrierung oder des Name-Schlüssel-Paars der Entität. Orchestrierungsinstanz-IDs sind standardmäßig zufällige GUIDs, sodass sichergestellt ist, dass Instanzen gleichmäßig auf alle Steuerearteschlangen verteilt werden.
Im Allgemeinen sollten Orchestratorfunktionen einfach sein und keine große Rechenleistung in Anspruch nehmen. Daher ist es nicht erforderlich, eine große Anzahl von Steuerwarteschlange-Partitionen zu erstellen, um einen erhöhten Durchsatz für Orchestrierungen zu erzielen. Der größte Teil der intensiven Vorgänge sollte in zustandslosen Aktivitätsfunktionen erfolgen, die unbegrenzt horizontal hochskaliert werden können.
Erweiterte Sitzungen
„Erweiterte Sitzungen“ ist ein Zwischenspeichermechanismus, der Orchestrierungen und Entitäten auch im Speicher beibehält, nachdem die Verarbeitung von Nachrichten abgeschlossen wurde. Die typische Auswirkung der Aktivierung von erweiterten Sitzungen sind reduzierte E/A-Vorgänge gegen den zugrunde liegenden dauerhaften Speicher und ein insgesamt verbesserter Durchsatz.
Sie können erweiterte Sitzungen aktivieren, indem durableTask/extendedSessionsEnabled in der Datei host.json auf true festgelegt wird. Mit der Einstellung durableTask/extendedSessionIdleTimeoutInSeconds kann gesteuert werden, wie lange eine Leerlaufsitzung im Arbeitsspeicher verbleibt:
Functions 2.0
{
"extensions": {
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
}
Functions 1.0
{
"durableTask": {
"extendedSessionsEnabled": true,
"extendedSessionIdleTimeoutInSeconds": 30
}
}
Es gibt zwei mögliche Nachteile dieser Einstellung, die Sie beachten sollten:
- Die Arbeitsspeicherauslastung der Funktions-App steigt insgesamt, da Instanzen im Leerlauf nicht so schnell aus dem Arbeitsspeicher entladen werden.
- Es kann zu einer Verringerung des Gesamtdurchsatzes kommen, wenn es viele gleichzeitige, unterschiedliche, kurzlebige Orchestrator- oder Entity-Funktionsausführungen gibt.
Wenn durableTask/extendedSessionIdleTimeoutInSeconds beispielsweise auf 30 Sekunden festgelegt ist, belegt eine Orchestrator- oder Entitätsfunktionsfolge mit kurzer Dauer, die in weniger als 1 Sekunde ausgeführt wird, dennoch 30 Sekunden lang den Arbeitsspeicher. Zudem wird sie auf das zuvor erwähnte Kontingent durableTask/maxConcurrentOrchestratorFunctions angerechnet, sodass möglicherweise verhindert wird, dass andere Orchestrator- oder Entitätsfunktionen ausgeführt werden.
Die spezifischen Auswirkungen von erweiterten Sitzungen auf Orchestrator- und Entitätsfunktionen werden in den nächsten Abschnitten beschrieben.
Hinweis
Erweiterte Sitzungen werden derzeit nur in .NET-Programmiersprachen wie C# oder F# unterstützt. Wenn Sie extendedSessionsEnabled für andere Plattformen auf true festlegen, kann dies zu Laufzeitproblemen führen. So kann z. B. die Ausführung von durch Aktivitäten und Orchestrierung ausgelöste Funktionen ohne Meldung Fehler verursachen.
Wiedergabe von Orchestratorfunktionen
Wie zuvor erwähnt, werden Orchestratorfunktionen unter Verwendung der Inhalte der Verlaufstabelle wiedergegeben. Standardmäßig wird der Orchestratorfunktionscode immer dann wiedergegeben, wenn ein Batch von Nachrichten aus einer Steuerelement-Warteschlange entfernt wird. Auch wenn Sie das Muster „Auffächern nach außen/innen“ verwenden und den Abschluss aller Aufgaben erwarten (z. B. mit Task.WhenAll() in .NET, context.df.Task.all() in JavaScript, oder context.task_all() in Python) wird es zu Wiedergaben kommen, die auftreten, wenn Batches von Aufgaben im Laufe der Zeit verarbeitet werden. Wenn erweiterte Sitzungen aktiviert sind, verbleiben Orchestratorfunktionsinstanzen länger im Arbeitsspeicher, und neue Nachrichten können ohne eine vollständige Verlaufswiedergabe verarbeitet werden.
Die Leistungsverbesserung erweiterter Sitzungen wird in den folgenden Situationen am häufigsten beobachtet:
- Wenn eine begrenzte Anzahl von Orchestrierungsinstanzen gleichzeitig ausgeführt wird.
- Wenn Orchestrierungen eine große Anzahl sequenzieller Aktionen (z.B. Hunderte von Aktivitätsfunktionsaufrufen) aufweisen, die schnell abgeschlossen werden.
- Wenn Orchestrierungen eine große Anzahl von Aktionen nach außen und innen auffächern, die ungefähr zur gleichen Zeit abgeschlossen werden.
- Wenn Orchestratorfunktionen große Nachrichten verarbeiten oder CPU-intensive Datenverarbeitung ausführen müssen.
In allen anderen Fällen gibt es in der Regel keine beobachtbare Leistungsverbesserung für Orchestratorfunktionen.
Hinweis
Diese Einstellungen sollten nur verwendet werden, nachdem eine Orchestratorfunktion vollständig entwickelt und getestet wurde. Das standardmäßige aggressive Wiedergabeverhalten kann nützlich sein, um Verstöße gegen die Einschränkungen des Orchestratorfunktionscodes zur Entwicklungszeit zu erkennen, und ist daher standardmäßig deaktiviert.
Leistungsziele
In der folgenden Tabelle sind die erwarteten maximalen Durchsatzzahlen für die Szenarien aufgeführt, die im Abschnitt "Leistungsziele" des Artikels "Leistung und Skalierung" beschrieben sind.
„Instanz“ bezieht sich auf eine einzelne Instanz einer Orchestratorfunktion, die auf einem einzelnen kleinen (A1) virtuellen Computer in Azure App Service ausgeführt wird. In allen Fällen wird angenommen, dass erweiterte Sitzungen aktiviert sind. Die tatsächlichen Ergebnisse können je nach den durch den Funktionscode ausgeführten CPU- oder E/A-Vorgängen variieren.
| Szenario | Maximaler Durchsatz |
|---|---|
| Sequenzielle Aktivitätsausführung | 5 Aktivitäten pro Sekunde pro Instanz |
| Parallele Aktivitätsausführung (Auffächern nach außen) | 100 Aktivitäten pro Sekunde pro Instanz |
| Parallele Antwortverarbeitung (Auffächern nach innen) | 150 Antworten pro Sekunde pro Instanz |
| Externe Ereignisverarbeitung | 50 Ereignisse pro Sekunde pro Instanz |
| Verarbeitung von Entitätsvorgängen | 64 Vorgänge pro Sekunde |
Wenn Sie nicht die erwarteten Durchsatzzahlen erreichen und die CPU- und die Speicherauslastung fehlerfrei zu sein scheinen, überprüfen Sie, ob die Ursache auf die Integrität Ihres Speicherkontos zurückzuführen ist. Die Durable Functions-Erweiterung kann eine beträchtliche Auslastung eines Azure Storage-Kontos verursachen, und entsprechend hohe Auslastungen können zu einer Drosselung des Speicherkontos führen.
Tipp
In einigen Fällen können Sie den Durchsatz externer Ereignisse, Aktivitätsauffächerung und Entitätsvorgänge erheblich erhöhen, indem Sie den Wert der controlQueueBufferThreshold-Einstellung in host.json erhöhen. Das Erhöhen dieses Werts über den Standardwert hinaus bewirkt, dass der Durable Task Framework-Speicheranbieter mehr Arbeitsspeicher verwendet, um diese Ereignisse aggressiver vorabzurufen, wodurch Verzögerungen reduziert werden, die mit dem Löschen von Nachrichten aus der Azure Storage Steuerwarteschlangen verbunden sind. Weitere Informationen finden Sie in der Referenzdokumentation zu host.json.
Verarbeitung mit hohem Durchsatz
Die Architektur des Azure Storage Back-Ends unterliegt bestimmten Einschränkungen hinsichtlich der maximalen theoretischen Leistung und Skalierbarkeit von Durable Functions. Wenn Ihre Tests zeigen, dass Durable Functions auf Azure Storage Ihre Durchsatzanforderungen nicht erfüllen, sollten Sie stattdessen in Erwägung ziehen den Netherite-Speicheranbieter für Durable Functionsverwenden.
Informationen zum Vergleich des erreichbaren Durchsatzes für verschiedene grundlegende Szenarien finden Sie im Abschnitt "Grundlegende Szenarien" der Dokumentation des Netherite-Speicheranbieters.
Das Netherite-Speicher-Back-End wurde von Microsoft Research entworfen und entwickelt. Dabei werden, zusätzlich zu Azure-Seiten-Blobs, Azure Event Hubs sowie die FASTER-Datenbanktechnologie verwendet. Das Design von Netherite ermöglicht im Vergleich zu anderen Anbietern eine Verarbeitung von Orchestrierungen und Entitäten mit deutlich höherem Durchsatz. In einigen Benchmark-Szenarien wurde deutlich, dass der Durchsatz im Vergleich zum Azure Storage-Standardanbieter um mehr als eine Größenordnung zunimmt.
Weitere Informationen zu den unterstützten Speicheranbietern für Durable Functions und deren Vergleich finden Sie unter Durable Functions-Speicheranbieter-Dokumentation.