Python-Entwicklerhandbuch für Azure Functions
Dieser Leitfaden ist eine Einführung in die Entwicklung von Azure Functions mithilfe von Python. In dem Artikel wird davon ausgegangen, dass Sie das Azure Functions-Entwicklerhandbuch bereits gelesen haben.
Wichtig
In diesem Artikel werden sowohl das v1- als auch das v2-Programmiermodell für Python in Azure Functions unterstützt. Das Python v1-Modell verwendet eine Datei functions.json zum Definieren von Funktionen, mit dem neuen v2-Modell können Sie stattdessen einen decoratorbasierten Ansatz verwenden. Dieser neue Ansatz führt zu einer einfacheren Dateistruktur und ist stärker codezentriert. Wählen Sie oben im Artikel die v2-Auswahl aus, um mehr über dieses neue Programmiermodell zu erfahren.
Für Python-Entwickler sind möglicherweise auch folgende Artikel interessant:
| Erste Schritte | Konzepte | Szenarien und Beispiele |
|---|---|---|
| Erste Schritte | Konzepte | Beispiele |
|---|---|---|
Entwicklungsoptionen
Beide Programmiermodelle für Python-Funktionen unterstützen die lokale Entwicklung in einer der folgenden Umgebungen:
Python v2-Programmiermodell:
Beachten Sie, dass das Python v2-Programmiermodell nur in Version 4.x der Functions-Runtime unterstützt wird. Weitere Informationen finden Sie unter Einstellen von Runtimeversionen von Azure Functions als Ziel.
Python v1-Programmiermodell:
Sie können Python v1-Funktionen auch im Azure-Portal erstellen.
Tipp
Sie können zwar Ihre Python-basierten Azure-Funktionen lokal unter Windows entwickeln, Python wird aber bei der Ausführung in Azure nur in einem Linux-basierten Hostingplan unterstützt. Weitere Informationen finden Sie in der Liste der unterstützten Betriebssystem- und Runtimekombinationen.
Programmiermodell
Azure Functions geht davon aus, dass eine Funktion eine zustandslose Methode in Ihrem Python-Skript ist, die Eingaben verarbeitet und Ausgaben erzeugt. Standardmäßig erwartet die Runtime, dass die Methode als globale Methode mit dem Titel main() in der Datei __init__.py implementiert ist. Sie können auch einen alternativen Einstiegspunkt angeben.
Sie binden Daten an die Funktion von Triggern und Bindungen über Methodenattribute, die die Eigenschaft name verwenden, die in der Datei function.json definiert ist. Beispielsweise beschreibt die folgende function.json-Datei eine einfache Funktion, die von einer HTTP-Anforderung namens req ausgelöst wird:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Basierend auf dieser Definition könnte die Datei __init__.py, die den Funktionscode enthält, wie im folgenden Beispiel aussehen:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
Sie können auch Python-Typanmerkungen verwenden, um die Attributtypen und den Rückgabetyp in der Funktion explizit zu deklarieren. Auf diese Weise können Sie die IntelliSense- und AutoVervollständigen-Funktionen nutzen, die von vielen Python-Code-Editoren bereitgestellt werden.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Verwenden Sie die Python-Anmerkungen im Paket azure.functions.*, um Eingaben und Ausgaben an Ihre Methoden zu binden.
Azure Functions geht davon aus, dass eine Funktion eine zustandslose Methode in Ihrem Python-Skript ist, die Eingaben verarbeitet und Ausgaben erzeugt. Standardmäßig erwartet die Runtime, dass die Methode als globale Methode in der Datei function_app.py implementiert ist.
Trigger und Bindungen können in einer Funktion auf Basis eines Decoratoransatzes deklariert und verwendet werden. Sie werden in derselben Datei function_app.py wie die Funktionen definiert. Als Beispiel stellt die folgende Datei function_app.py einen Funktionstrigger dar, der von einer HTTP-Anforderung ausgelöst wird.
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
Sie können auch Python-Typanmerkungen verwenden, um die Attributtypen und den Rückgabetyp in der Funktion explizit zu deklarieren. Auf diese Weise können Sie die IntelliSense- und AutoVervollständigen-Funktionen nutzen, die von vielen Python-Code-Editoren bereitgestellt werden.
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
Informationen zu bekannten Einschränkungen beim v2-Modell und deren Problemumgehungen finden Sie unter Problembehandlung von Python-Fehlern in Azure Functions.
Alternativer Einstiegspunkt
Sie können das Standardverhalten einer Funktion ändern, indem Sie die Eigenschaften scriptFile und entryPoint in der scriptFile-Datei angeben. Beispielsweise weist die folgende Datei function.json die Runtime an, die Methode customentry() in der main.py-Datei als Einstiegspunkt für Ihre Azure-Funktion zu verwenden.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
Der Einstiegspunkt befindet sich nur in der Datei function_app.py. Auf Funktionen innerhalb des Projekts können Sie jedoch in function_app.py mithilfe von Blaupausen oder durch Importieren verweisen.
Ordnerstruktur
Die empfohlene Ordnerstruktur für ein Python-Funktionsprojekt sieht wie im folgenden Beispiel aus:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
Der Hauptprojektordner (<project_root>) kann die folgenden Dateien enthalten:
- local.settings.json: Wird verwendet, um bei der lokalen Ausführung App-Einstellungen und Verbindungszeichenfolgen zu speichern. Diese Datei wird nicht in Azure veröffentlicht. Weitere Informationen finden Sie unter local.settings.file.
- requirements.txt: Diese Datei enthält die Liste der bei der Veröffentlichung in Azure vom System installierten Python-Pakete.
- host.json: Enthält Konfigurationsoptionen, die sich auf alle Funktionen in einer Funktions-App-Instanz auswirken. Diese Datei wird in Azure veröffentlicht. Nicht alle Optionen werden bei lokaler Ausführung unterstützt. Weitere Informationen finden Sie unter host.json.
- .vscode/: (optional) Diese Datei enthält die gespeicherten Visual Studio Code-Konfigurationen. Weitere Informationen finden Sie unter Visual Studio Code-Einstellungen.
- .venv/: (optional) Diese Datei enthält eine virtuelle Python-Umgebung, die von der lokalen Entwicklung verwendet wird.
- Dockerfile: (optional) Diese Datei wird verwendet, wenn Sie Ihr Projekt in einem benutzerdefinierten Container veröffentlichen.
- tests/: (optional) Diese Datei enthält die Testfälle ihrer Funktions-App.
- .funcignore: (optional) In dieser Datei werden Dateien deklariert, die nicht in Azure veröffentlicht werden sollen. Normalerweise enthält diese Datei .vscode/, um die Editoreinstellung zu ignorieren, .venv/, um die lokale virtuelle Python-Umgebung zu ignorieren, tests/, um Testfälle zu ignorieren, und local.settings.json, um zu verhindern, dass lokale App-Einstellungen veröffentlicht werden.
Jede Funktion verfügt über eine eigene Codedatei sowie über eine eigene Bindungskonfigurationsdatei (function.json).
Die empfohlene Ordnerstruktur für ein Python-Funktionsprojekt sieht wie im folgenden Beispiel aus:
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
Der Hauptprojektordner (<project_root>) kann die folgenden Dateien enthalten:
- .venv/: (optional) Diese Datei enthält eine virtuelle Python-Umgebung, die von der lokalen Entwicklung verwendet wird.
- .vscode/: (optional) Diese Datei enthält die gespeicherten Visual Studio Code-Konfigurationen. Weitere Informationen finden Sie unter Visual Studio Code-Einstellungen.
- function_app.py: Der Standardspeicherort für alle Funktionen und die zugehörigen Trigger und Bindungen.
- additional_functions.py: (Optional) Alle anderen Python-Dateien, die Funktionen (in der Regel für logische Gruppierung) enthalten, auf die in function_app.py über Blaupausen verwiesen wird.
- tests/: (optional) Diese Datei enthält die Testfälle ihrer Funktions-App.
- .funcignore: (optional) In dieser Datei werden Dateien deklariert, die nicht in Azure veröffentlicht werden sollen. Normalerweise enthält diese Datei .vscode/, um die Editoreinstellung zu ignorieren, .venv/, um die lokale virtuelle Python-Umgebung zu ignorieren, tests/, um Testfälle zu ignorieren, und local.settings.json, um zu verhindern, dass lokale App-Einstellungen veröffentlicht werden.
- host.json: Enthält Konfigurationsoptionen, die sich auf alle Funktionen in einer Funktions-App-Instanz auswirken. Diese Datei wird in Azure veröffentlicht. Nicht alle Optionen werden bei lokaler Ausführung unterstützt. Weitere Informationen finden Sie unter host.json.
- local.settings.json: Wird verwendet, um bei lokaler Ausführung App-Einstellungen und Verbindungszeichenfolgen zu speichern. Diese Datei wird nicht in Azure veröffentlicht. Weitere Informationen finden Sie unter local.settings.file.
- requirements.txt: Diese Datei enthält die Liste der bei der Veröffentlichung in Azure vom System installierten Python-Pakete.
- Dockerfile: (optional) Diese Datei wird verwendet, wenn Sie Ihr Projekt in einem benutzerdefinierten Container veröffentlichen.
Wenn Sie Ihr Projekt in einer Funktions-App in Azure bereitstellen, sollte der gesamte Inhalt des Hauptprojektordners (<project_root>) in das Paket aufgenommen werden, jedoch nicht der Ordner selbst. host.json sollte sich also im Paketstammverzeichnis befinden. Es wird empfohlen, die Tests in einem Ordner zusammen mit anderen Funktionen aufzubewahren (in diesem Beispiel tests/). Weitere Informationen finden Sie unter Komponententests.
Mit Datenbank verbinden
Azure Functions lässt sich gut in Azure Cosmos DB für viele Anwendungsfälle integrieren, einschließlich IoT, E-Commerce, Gaming usw.
Beispielsweise sind die beiden Dienste für die Ereignisherkunftsermittlung zur Unterstützung ereignisgesteuerter Architekturen mithilfe der Funktion für den Änderungsfeed von Azure Cosmos DB integriert. Der Änderungsfeed ermöglicht Downstream-Microservices das zuverlässige und inkrementelle Lesen von Einfügungen und Updates (z. B. Bestellereignisse). Diese Funktionalität kann dazu genutzt werden, einen persistenten Ereignisspeicher als Nachrichtenbroker für Ereignisse mit wechselndem Status bereitzustellen und Bestellverarbeitungsworkflows zwischen zahlreichen Microservices (die als serverlose Azure-Funktionen implementiert werden können) zu steuern.
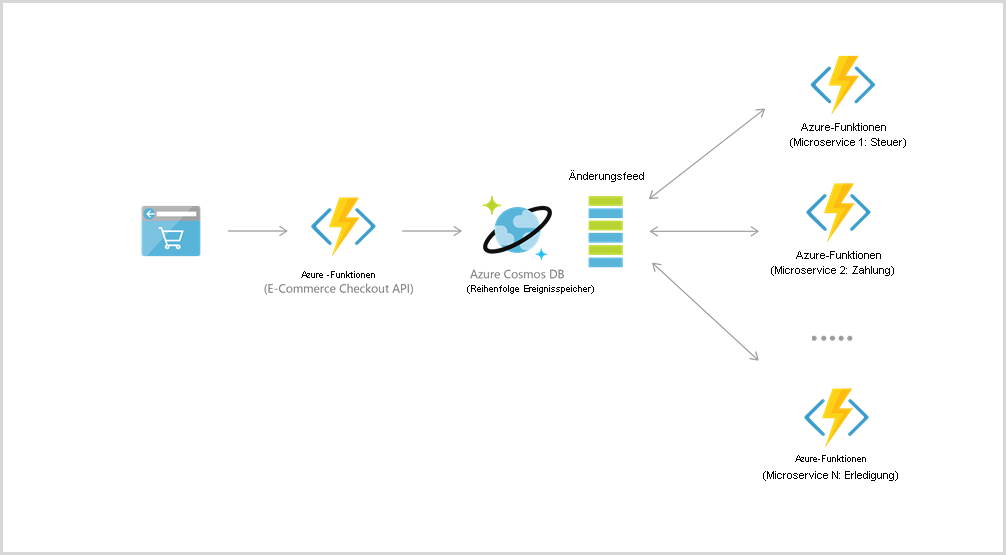
Um eine Verbindung mit Cosmos DB herzustellen, erstellen Sie zuerst ein Konto, eine Datenbank und einen Container. Dann können Sie Funktionen mithilfe von Triggern und Bindungen wie in diesem Beispiel mit Cosmos DB verbinden.
Um komplexere App-Logik zu implementieren, können Sie auch die Python-Bibliothek für Cosmos DB verwenden. Die asynchrone E/A-Implementierung sieht wie folgt aus:
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Blueprints
Das Python v2-Programmiermodell führt das Konzept von Blaupausen ein. Eine Blaupause ist eine neue Klasse, die Instanziiert wird, um Funktionen außerhalb der Kernfunktionsanwendung zu registrieren. Die in Blaupauseninstanzen registrierten Funktionen werden nicht direkt nach Funktionsruntime indiziert. Um diese Blaupausenfunktionen zu indizieren, muss die Funktions-App die Funktionen aus Blaupauseninstanzen registrieren.
Die Verwendung von Blaupausen bietet folgende Vorteile:
- Sie ermöglichen Ihnen das Aufteilen der Funktions-App in modulare Komponenten, mit denen Sie Funktionen in mehreren Python-Dateien definieren und in verschiedene Komponenten pro Datei aufteilen können.
- Sie stellen erweiterbare App-Schnittstellen für öffentliche Funktionen bereit, um eigene APIs zu erstellen und wiederzuverwenden.
Im folgenden Beispiel wird gezeigt, wie Blaupausen verwendet werden:
Zunächst wird in einer Datei http_blueprint.py eine durch HTTP ausgelöste Funktion definiert und einem Blaupausenobjekt hinzugefügt.
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
Dann wird das Blaupausenobjekt in function_app.py importiert, und seine Funktionen werden bei der Funktions-App registriert.
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
Hinweis
Durable Functions unterstützt auch Blaupausen. Um Blaupausen für Durable Functions-Apps zu erstellen, registrieren Sie Ihre Orchestrierungs-, Aktivitäts- und Entitätstrigger und Clientbindungen mithilfe der azure-functions-durableBlueprint-Klasse, wie hier gezeigt. Die resultierende Blaupause kann dann wie gewohnt registriert werden. Ein Beispiel finden Sie in unserer Stichprobe .
Importverhalten
Sie können Module sowohl über relative und als auch über absolute Verweise in Ihren Funktionscode importieren. Auf Basis der oben beschriebenen Ordnerstruktur funktionieren die folgenden Importe innerhalb der Funktionsdatei <project_root>\my_first_function\__init__.py:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Hinweis
Der Ordner shared_code/ muss eine __init__.py-Datei enthalten, durch die er bei Verwendung der absoluten Importsyntax als Python-Paket gekennzeichnet wird.
Der __app__-Import und der relative Import jenseits der obersten Ebene in den folgenden Beispielen sind veraltet, weil sie weder von der statischen Typüberprüfung noch von Python-Testframeworks unterstützt werden:
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Trigger und Eingaben
Eingaben werden in Azure Functions in zwei Kategorien unterteilt: Triggereingaben und andere Eingaben. Obwohl sie sich in der Datei function.json unterscheiden, ist ihre Verwendung im Python-Code identisch. Verbindungszeichenfolgen oder Geheimnisse für Trigger- und Eingabequellen werden bei lokaler Ausführung Werten in der Datei local.settings.json und bei der Ausführung in Azure den Anwendungseinstellungen zugeordnet.
Im folgenden Code wird beispielsweise der Unterschied zwischen beiden Eingaben dargestellt:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Bei Aufruf der Funktion wird die HTTP-Anforderung als req an die Funktion übergeben. Es wird ein Eintrag, der auf der ID in der Routen-URL basiert, aus einem Azure Blob Storage-Konto abgerufen und als obj im Funktionstext verfügbar gemacht. Hier ist das angegebene Speicherkonto die Verbindungszeichenfolge, die in der CONNECTION_STRING-App-Einstellung zu finden ist.
Eingaben werden in Azure Functions in zwei Kategorien unterteilt: Triggereingaben und andere Eingaben. Obwohl sie mithilfe verschiedener Decorator-Elemente definiert werden, ist ihre Verwendung im Python-Code ähnlich. Verbindungszeichenfolgen oder Geheimnisse für Trigger- und Eingabequellen werden bei lokaler Ausführung Werten in der Datei local.settings.json und bei der Ausführung in Azure den Anwendungseinstellungen zugeordnet.
Im folgenden Code wird beispielsweise veranschaulicht, wie eine Blob Storage-Eingabebindung definiert wird:
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>",
"AzureWebJobsFeatureFlags": "EnableWorkerIndexing"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.read_blob(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Bei Aufruf der Funktion wird die HTTP-Anforderung als req an die Funktion übergeben. Es wird ein Eintrag, der auf der ID in der Routen-URL basiert, aus einem Azure Blob Storage-Konto abgerufen und als obj im Funktionstext verfügbar gemacht. Hier ist das angegebene Speicherkonto die Verbindungszeichenfolge, die in der STORAGE_CONNECTION_STRING-App-Einstellung zu finden ist.
Es kann sinnvoll sein, für datenintensive Bindungsvorgänge ein separates Speicherkonto zu verwenden. Weitere Informationen finden Sie im Speicherkontoleitfaden.
Ausgaben
Ausgaben können sowohl im Rückgabewert als auch in Ausgabeparametern angegeben werden. Wenn es nur eine Ausgabe gibt, empfehlen wir, den Rückgabewert zu verwenden. Bei mehreren Ausgaben müssen Sie Ausgabeparameter verwenden.
Um den Rückgabewert einer Funktion als Wert für eine Ausgabebindung zu verwenden, sollte die name-Eigenschaft der Bindung in der Datei function.json auf $return festgelegt werden.
Um mehrere Ausgaben zu erzeugen, verwenden Sie die set()-Methode, die von der azure.functions.Out-Schnittstelle bereitgestellt wird, um der Bindung einen Wert zuzuweisen. Die folgende Funktion kann z. B. mithilfe von Push eine Nachricht an eine Warteschlange übertragen und auch eine HTTP-Antwort zurückgeben.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Ausgaben können sowohl im Rückgabewert als auch in Ausgabeparametern angegeben werden. Wenn es nur eine Ausgabe gibt, empfehlen wir, den Rückgabewert zu verwenden. Bei mehreren Ausgaben müssen Sie Ausgabeparameter verwenden.
Um mehrere Ausgaben zu erzeugen, verwenden Sie die set()-Methode, die von der azure.functions.Out-Schnittstelle bereitgestellt wird, um der Bindung einen Wert zuzuweisen. Die folgende Funktion kann z. B. mithilfe von Push eine Nachricht an eine Warteschlange übertragen und auch eine HTTP-Antwort zurückgeben.
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Protokollierung
Zugriff auf die Azure Functions-Runtimeprotokollierung ist über einen Stamm-logging-Handler in Ihrer Funktions-App verfügbar. Diese Protokollierung ist an Application Insights gebunden und ermöglicht es Ihnen, während der Funktionsausführung aufgetretene Warnungen und Fehler zu kennzeichnen.
Im folgenden Beispiel wird eine Informationsmeldung protokolliert, wenn die Funktion über einen HTTP-Trigger aufgerufen wird.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
Es sind mehr Protokollierungsmethoden verfügbar, mit denen Sie auf anderen Ablaufverfolgungsebenen in die Konsole schreiben können:
| Methode | BESCHREIBUNG |
|---|---|
critical(_message_) |
Schreibt eine Meldung mit der Stufe KRITISCH in die Stammprotokollierung. |
error(_message_) |
Schreibt eine Meldung mit der Stufe ERROR in die Stammprotokollierung. |
warning(_message_) |
Schreibt eine Meldung mit der Stufe WARNUNG in die Stammprotokollierung. |
info(_message_) |
Schreibt eine Meldung mit der Stufe INFO in die Stammprotokollierung. |
debug(_message_) |
Schreibt eine Meldung mit der Stufe DEBUG in die Stammprotokollierung. |
Weitere Informationen über Protokollierung finden Sie unter Überwachen von Azure Functions.
Protokollierung aus erstellten Threads
Um Protokolle anzuzeigen, die aus Ihren erstellten Threads stammen, fügen Sie das context-Argument in die Signatur der Funktion ein. Dieses Argument enthält ein Attribut thread_local_storage, das eine lokale invocation_id speichert. Dies kann auf die aktuelle invocation_id der Funktion festgelegt werden, um sicherzustellen, dass der Kontext geändert wird.
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
Protokollieren benutzerdefinierter Telemetriedaten
Standardmäßig erfasst die Functions-Runtime Protokolle und andere Telemetriedaten, die von Ihren Funktionen generiert werden. Diese Telemetriedaten werden in Application Insights zu Ablaufverfolgungen. Anforderungs- und Abhängigkeitstelemetriedaten für bestimmte Azure-Dienste werden standardmäßig auch über Trigger und Bindungen erfasst.
Um Sammeln von benutzerdefinierten Telemetriedaten zu Anforderungen und Abhängigkeiten außerhalb von Bindungen können Sie die OpenCensus-Python-Erweiterungen verwenden. Diese Erweiterung sendet benutzerdefinierte Telemetriedaten an Ihre Application Insights-Instanz. Eine Liste unterstützter Erweiterungen finden Sie im OpenCensus-Repository.
Hinweis
Um die Python-Erweiterungen für OpenCensus zu verwenden, müssen Sie die Python-Workererweiterungen in Ihrer Funktions-App aktivieren, indem Sie PYTHON_ENABLE_WORKER_EXTENSIONS auf 1 festlegen. Sie müssen auch auf die Verwendung der Verbindungszeichenfolge von Application Insights wechseln, indem Sie die Einstellung APPLICATIONINSIGHTS_CONNECTION_STRING Ihren APPLICATIONINSIGHTS_CONNECTION_STRING hinzufügen, sofern sie noch nicht vorhanden ist.
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
HTTP-Trigger
Der HTTP-Trigger ist in der Datei function.json definiert. Der name der Bindung muss mit dem benannten Parameter in der Funktion identisch sein.
In den vorherigen Beispielen wird der Bindungsname req verwendet. Dieser Parameter ist ein HttpRequest-Objekt, und es wird ein HttpResponse-Objekt zurückgegeben.
Aus dem HttpRequest-Objekt können Sie Anforderungsheader, Abfrageparameter, Routenparameter und den Nachrichtentext extrahieren.
Das folgende Beispiel stammt aus der HTTP-Trigger-Vorlage für Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
In dieser Funktion ermitteln Sie den Wert des name-Abfrageparameters aus dem params-Parameter des HttpRequest-Objekts. Sie lesen den JSON-codierten Nachrichtentext wird mit der get_json-Methode.
Außerdem können Sie status_code und headers für die Antwortnachricht im zurückgegebenen status_code-Objekt festlegen.
Der HTTP-Trigger wird als Methode definiert, die einen benannten Bindungsparameter verwendet, bei dem es sich um ein HttpRequest-Objekt handelt, und es wird ein HttpResponse -Objekt zurückgegeben. Sie wenden den function_name Decorator auf die Methode an, um den Funktionsnamen zu definieren, während der HTTP-Endpunkt durch Anwenden des route Decorators festgelegt wird.
Dieses Beispiel stammt aus der HTTP-Triggervorlage für das Python v2-Programmiermodell, wobei der Name des Bindungsparameters req ist. Dies ist der Beispielcode, der beim Erstellen einer Funktion mit Azure Functions Core Tools oder Visual Studio Code bereitgestellt wird.
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
Aus dem HttpRequest-Objekt können Sie Anforderungsheader, Abfrageparameter, Routenparameter und den Nachrichtentext extrahieren. In dieser Funktion ermitteln Sie den Wert des name-Abfrageparameters aus dem params-Parameter des HttpRequest-Objekts. Sie lesen den JSON-codierten Nachrichtentext wird mit der get_json-Methode.
Außerdem können Sie status_code und headers für die Antwortnachricht im zurückgegebenen status_code-Objekt festlegen.
Um in diesem Beispiel einen Namen zu übergeben, fügen Sie die beim Ausführen der Funktion bereitgestellte URL ein, und fügen Sie dann "?name={name}" an sie an.
Webframeworks
Sie können WSGI-kompatible (Web Server Gateway Interface) und ASGI-kompatible (Asynchronous Server Gateway Interface) Frameworks wie Flask und FastAPI mit Ihren über HTTP ausgelösten Python-Funktionen verwenden. In diesem Abschnitt wird gezeigt, wie Sie Ihre Funktionen ändern, um diese Frameworks zu unterstützen.
Zunächst muss die Datei function.json angepasst werden, um eine route in den HTTP-Trigger einzufügen, wie im folgenden Beispiel gezeigt:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Die Datei host.json muss ebenfalls aktualisiert werden, um ein HTTP-routePrefix einzufügen, wie im folgenden Beispiel gezeigt:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[3.*, 4.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Aktualisieren Sie die Python-Codedatei init.py abhängig von der Schnittstelle, die von Ihrem Framework verwendet wird. Das folgende Beispiel zeigt entweder einen Ansatz mit einem ASGI-Handler oder mit einem WSGI-Wrapper für Flask:
Sie können ASGI-kompatible (Asynchronous Server Gateway Interface) und WSGI-kompatible (Web Server Gateway Interface) Frameworks wie Flask und FastAPI mit Ihren über HTTP ausgelösten Python-Funktionen verwenden. Sie müssen zuerst die Datei host.json aktualisieren, damit sie ein HTTP-routePrefix enthält, wie im folgenden Beispiel gezeigt:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[2.*, 3.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Der Frameworkcode sieht wie das folgende Beispiel aus:
AsgiFunctionApp ist die App-Klasse der Funktion auf obersten Ebene zum Erstellen von ASGI-HTTP-Funktionen.
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
Skalierung und Leistung
Informationen zu den bewährten Methoden für Skalierung und Leistung für Python-Funktions-Apps finden Sie im Artikel Verbessern der Durchsatzleistung von Python-Apps in Azure Functions.
Kontext
Um den Aufrufkontext einer Funktion während der Ausführung abzurufen, nehmen Sie das context-Argument in ihre Signatur auf.
Beispiel:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
Die Context-Klasse weist die folgenden Zeichenfolgenattribute auf:
| attribute | BESCHREIBUNG |
|---|---|
function_directory |
Das Verzeichnis, in dem die Funktion ausgeführt wird. |
function_name |
Der Name der Funktion. |
invocation_id |
Die ID des aktuellen Funktionsaufrufs. |
thread_local_storage |
Der lokale Threadspeicher der Funktion. Enthält eine lokale invocation_id für Protokollierung aus erstellten Threads. |
trace_context |
Der Kontext für verteilte Ablaufverfolgung. Weitere Informationen finden Sie unter Trace Context. |
retry_context |
Der Kontext für Wiederholungsversuche der Funktion. Weitere Informationen finden Sie unter retry-policies. |
Globale Variablen
Es gibt keine Garantie, dass der Status Ihrer App für zukünftige Ausführungen beibehalten wird. Jedoch verwendet die Azure Functions-Runtime oft wieder den gleichen Prozess für mehrere Ausführungen derselben App. Zum Zwischenspeichern der Ergebnisse einer teuren Berechnung deklarieren Sie diese als globale Variable.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Umgebungsvariablen
In Azure Functions werden Anwendungseinstellungen, z. B. Dienstverbindungszeichenfolgen, während der Ausführung als Umgebungsvariablen verfügbar gemacht. Es gibt zwei Hauptmöglichkeiten, auf diese Einstellungen in Ihrem Code zuzugreifen.
| Methode | BESCHREIBUNG |
|---|---|
os.environ["myAppSetting"] |
Versucht, die Anwendungseinstellung nach Schlüsselnamen abzurufen, und gibt einen Fehler aus, wenn dies nicht erfolgreich ist. |
os.getenv("myAppSetting") |
Versucht, die Anwendungseinstellung nach Schlüsselnamen abzurufen, und gibt null zurück, wenn dies nicht erfolgreich ist. |
Beide Methoden erfordern, dass Sie import os deklarieren.
Im folgenden Beispiel wird os.environ["myAppSetting"] verwendet, um die os.environ["myAppSetting"] mit dem Schlüssel namens myAppSetting abzurufen:
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Für die lokale Entwicklung werden Anwendungseinstellungen in der Datei local.settings.json verwaltet.
In Azure Functions werden Anwendungseinstellungen, z. B. Dienstverbindungszeichenfolgen, während der Ausführung als Umgebungsvariablen verfügbar gemacht. Es gibt zwei Hauptmöglichkeiten, auf diese Einstellungen in Ihrem Code zuzugreifen.
| Methode | BESCHREIBUNG |
|---|---|
os.environ["myAppSetting"] |
Versucht, die Anwendungseinstellung nach Schlüsselnamen abzurufen, und gibt einen Fehler aus, wenn dies nicht erfolgreich ist. |
os.getenv("myAppSetting") |
Versucht, die Anwendungseinstellung nach Schlüsselnamen abzurufen, und gibt null zurück, wenn dies nicht erfolgreich ist. |
Beide Methoden erfordern, dass Sie import os deklarieren.
Im folgenden Beispiel wird os.environ["myAppSetting"] verwendet, um die os.environ["myAppSetting"] mit dem Schlüssel namens myAppSetting abzurufen:
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Für die lokale Entwicklung werden Anwendungseinstellungen in der Datei local.settings.json verwaltet.
Wenn Sie das neue Programmiermodell verwenden, aktivieren Sie die folgende App-Einstellung in der Datei local.settings.json, wie hier gezeigt:
"AzureWebJobsFeatureFlags": "EnableWorkerIndexing"
Wenn Sie die Funktion bereitstellen, wird diese Einstellung nicht automatisch erstellt. Sie müssen diese Einstellung explizit in Ihrer Funktions-App in Azure erstellen, damit diese mithilfe des v2-Modells ausgeführt wird.
Python-Version
Azure Functions unterstützt die folgenden Python-Versionen:
| Functions-Version | Python*-Versionen |
|---|---|
| 4.x | 3,11 3.10 3.9 3.8 3,7 |
| 3.x | 3.9 3.8 3,7 |
* Offizielle Python-Distributionen
Wenn Sie beim Erstellen der Funktions-App in Azure eine bestimmte Python-Version anfordern möchten, verwenden Sie die --runtime-version-Option des Befehls az functionapp create. Die Functions-Runtimeversion wird mit der Option --functions-version festgelegt. Die Python-Version wird festgelegt, wenn die Funktions-App erstellt wird, und sie kann nicht für Apps geändert werden, die in einem Verbrauchsplan ausgeführt werden.
Die Runtime verwendet bei lokaler Ausführung die verfügbare Python-Version.
Ändern der Python-Version
Um eine Python-Funktions-App auf eine bestimmte Sprachversion festzulegen, müssen Sie die Sprache und die Sprachversion in der Standortkonfiguration im Feld LinuxFxVersion der Sitekonfiguration angeben. Wenn Sie beispielsweise die Python-App so ändern möchten, dass Python 3.8 verwendet wird, legen Sie python|3.8 für linuxFxVersion fest.
Informationen zum Anzeigen und Ändern der linuxFxVersion-Siteeinstellung finden Sie unter Vorgehensweise: Abzielen auf Azure Functions-Runtimeversionen.
Allgemeine Informationen finden Sie unter Azure Functions Runtimeunterstützungsrichtlinie und Unterstützte Sprachen in Azure Functions.
Paketverwaltung
Bei der lokalen Entwicklung mithilfe der Core Tools oder mithilfe von Visual Studio Code müssen Sie die Namen und Versionen der erforderlichen Pakete in der Datei requirements.txt hinzufügen. Installieren Sie sie dann mithilfe von pip.
Beispielsweise können Sie die folgende Datei requirements.txt und den pip-Befehl verwenden, um das requests-Paket aus PyPI zu installieren.
requests==2.19.1
pip install -r requirements.txt
Wenn Sie Ihre Funktionen in einem App Service-Planausführen, erhalten Abhängigkeiten, die Sie in „requirements.txt“ definieren, Vorrang vor integrierten Python-Modulen, wie z. B. logging. Diese Rangfolge kann Konflikte verursachen, wenn integrierte Module dieselben Namen wie Verzeichnisse in Ihrem Code haben. Bei der Ausführung in einem Verbrauchsplan oder einem Elastic Premium-Plan sind Konflikte weniger wahrscheinlich, da Ihre Abhängigkeiten standardmäßig nicht priorisiert werden.
Um Probleme bei der Ausführung eines App Service-Plans zu vermeiden, benennen Sie Ihre Verzeichnisse nicht wie die nativen Python-Module und nehmen Sie keine nativen Python-Bibliotheken in die Datei requirements.txt Ihres Projekts auf.
Veröffentlichen in Azure
Wenn Sie für die Veröffentlichung bereit sind, stellen Sie sicher, dass alle öffentlich verfügbaren Abhängigkeiten in der Datei requirements.txt aufgelistet sind. Sie finden diese Datei im Stammverzeichnis Ihres Projekts.
Auch Projektdateien und -ordner, die von der Veröffentlichung ausgeschlossen sind, einschließlich des Ordners für die virtuelle Umgebung, finden Sie im Stammverzeichnis Ihres Projekts.
Für die Veröffentlichung Ihres Python-Projekts in Azure werden drei Buildaktionen unterstützt: Remotebuild, lokaler Build und Builds mit benutzerdefinierten Abhängigkeiten.
Sie können auch Azure Pipelines verwenden, um Ihre Abhängigkeiten zu erstellen und mit Continuous Delivery (CD) Veröffentlichungen durchzuführen. Weitere Informationen finden Sie unter Continuous Delivery mit Azure Pipelines.
Remotebuild
Bei Verwendung eines Remotebuilds stimmen die auf dem Server wiederhergestellten Abhängigkeiten und die nativen Abhängigkeiten mit der Produktionsumgebung überein. Dies führt zu einem kleineren Bereitstellungspaket, das hochgeladen werden muss. Verwenden Sie den Remotebuild, wenn Sie Python-Apps unter Windows entwickeln. Wenn Ihr Projekt über benutzerdefinierte Abhängigkeiten verfügt, können Sie den Remotebuild mit einer zusätzlichen Index-URL verwenden.
Abhängigkeiten werden entsprechend dem Inhalt der Datei requirements.txt remote abgerufen. Remotebuild ist die empfohlene Buildmethode. Standardmäßig fordert Core Tools einen Remotebuild an, wenn Sie den folgenden func azure functionapp publish-Befehl zum Veröffentlichen Ihres Python-Projekts in Azure verwenden.
func azure functionapp publish <APP_NAME>
Denken Sie daran, <APP_NAME> durch den Namen Ihrer Funktions-App in Azure zu ersetzen.
Die Azure Functions-Erweiterung für Visual Studio Code fordert ebenfalls standardmäßig einen Remotebuild an.
Lokaler Build
Abhängigkeiten werden entsprechend dem Inhalt der Datei requirements.txt lokal abgerufen. Sie können das Ausführen eines Remotebuilds verhindern, indem Sie mit dem folgenden func azure functionapp publish-Befehl mit einem lokalen Build veröffentlichen:
func azure functionapp publish <APP_NAME> --build local
Denken Sie daran, <APP_NAME> durch den Namen Ihrer Funktions-App in Azure zu ersetzen.
Mit der Option --build local werden Projektabhängigkeiten aus der Datei requirements.txt gelesen, und die betreffenden abhängigen Pakete werden lokal heruntergeladen und installiert. Projektdateien und Abhängigkeiten werden von Ihrem lokalen Computer in Azure bereitgestellt. Dadurch wird ein größeres Bereitstellungspaket in Azure hochgeladen. Wenn Sie aus irgendeinem Grund über Core Tools keine Datei requirements.txt erhalten, müssen Sie für die Veröffentlichung die Option für benutzerdefinierte Abhängigkeiten verwenden.
Es wird nicht empfohlen, bei der lokalen Entwicklungsarbeit unter Windows lokale Builds zu nutzen.
Benutzerdefinierte Abhängigkeiten
Wenn Ihr Projekt über Abhängigkeiten verfügt, die nicht im Index für Python-Pakete gefunden werden, haben Sie zwei Möglichkeiten für die Erstellung des Projekts. Die erste Möglichkeit (die Buildmethode) hängt davon ab, wie Sie das Projekt erstellen.
Remotebuild mit zusätzlicher Index-URL
Verwenden Sie einen Remotebuild, wenn Ihre Pakete über einen zugänglichen benutzerdefinierten Paketindex verfügbar sind. Stellen Sie vor der Veröffentlichung sicher, dass Sie eine App-Einstellung erstellen, die den Namen PIP_EXTRA_INDEX_URL aufweist. Der Wert für diese Einstellung ist die URL Ihres benutzerdefinierten Paketindexes. Mit der Verwendung dieser Einstellung wird der Remotebuild angewiesen, pip install mit der Option --extra-index-url auszuführen. Weitere Informationen finden Sie in der Python-pip install-Dokumentation.
Sie können auch die grundlegenden Anmeldeinformationen für die Authentifizierung mit Ihren zusätzlichen Paketindex-URLs verwenden. Weitere Informationen finden Sie im Abschnitt zu den grundlegenden Anmeldeinformationen für die Authentifizierung in der Python-Dokumentation.
Installieren von lokalen Paketen
Wenn in Ihrem Projekt Pakete verwendet werden, die für unsere Tools nicht öffentlich verfügbar sind, können Sie sie für die App verfügbar machen, indem Sie sie im Verzeichnis __app__/.python_packages ablegen. Führen Sie vor dem Veröffentlichen den folgenden Befehl aus, um die Abhängigkeiten lokal zu installieren:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
Wenn Sie benutzerdefinierte Abhängigkeiten verwenden, sollten Sie die folgende --no-build-Veröffentlichungsoption nutzen, da Sie die Abhängigkeiten bereits im Projektordner installiert haben.
func azure functionapp publish <APP_NAME> --no-build
Denken Sie daran, <APP_NAME> durch den Namen Ihrer Funktions-App in Azure zu ersetzen.
Komponententest
In Python geschriebene Funktionen können wie anderer Python-Code mithilfe von Standardtestframeworks getestet werden. Bei den meisten Bindungen können Sie ein Pseudoeingabeobjekt erstellen, indem Sie eine Instanz einer geeigneten Klasse aus dem azure.functions-Paket erstellen. Da das azure.functions-Paket nicht sofort verfügbar ist, müssen Sie es über Ihre requirements.txt-Datei installieren, wie oben im Abschnitt zur Paketverwaltung beschrieben.
Als Beispiel fungiert my_second_function im folgenden Modelltest einer durch HTTP ausgelösten Funktion:
Erstellen Sie zunächst eine Datei <
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Nun können Sie my_second_function und shared_code.my_second_helper_function implementieren.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Jetzt können Sie mit dem Schreiben von Testfällen für den HTTP-Trigger beginnen.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
Installieren Sie Ihr bevorzugtes Python-Testframework, z. B. pip install pytest, im Ordner der virtuellen Python-Umgebung .venv. Führen Sie dann pytest tests aus, um das Testergebnis zu überprüfen.
Erstellen Sie zunächst die <Datei project_root>/function_app.py, und implementieren Sie die my_second_function-Funktion als HTTP-Trigger und shared_code.my_second_helper_function.
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Jetzt können Sie mit dem Schreiben von Testfällen für den HTTP-Trigger beginnen.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
Installieren Sie Ihr bevorzugtes Python-Testframework, z. B. pip install pytest, im Ordner der virtuellen Python-Umgebung .venv. Führen Sie dann pytest tests aus, um das Testergebnis zu überprüfen.
Temporäre Dateien
Die tempfile.gettempdir()-Methode gibt einen temporären Ordner zurück, der unter Linux /tmp lautet. Die Anwendung kann dieses Verzeichnis zum Speichern von temporären Dateien verwenden, die von ihren Funktionen während der Ausführung generiert und verwendet werden.
Wichtig
Für Dateien, die in das temporäre Verzeichnis geschrieben werden, wird nicht garantiert, dass sie über Aufrufe hinweg beibehalten werden. Beim Aufskalieren werden temporäre Dateien nicht von Instanzen gemeinsam verwendet.
Im folgenden Beispiel wird eine benannte temporäre Datei im temporären Verzeichnis (/tmp) erstellt:
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
Es wird empfohlen, dass Sie Ihre Tests in einem Ordner außerhalb des Projektordners speichern. Dadurch wird die Bereitstellung von Testcode mit der App verhindert.
Vorinstallierte Bibliotheken
Einige Bibliotheken enthalten die Python-Funktionsruntime.
Die Python-Standardbibliothek
Die Python-Standardbibliothek enthält eine Liste mit integrierten Python-Modulen, die in jeder Python-Distribution enthalten sind. Die meisten dieser Bibliotheken dienen Ihnen als Hilfe beim Zugreifen auf die Systemfunktionalität, z. B. Dateieingabe/-ausgabe (E/A). Auf Windows-Systemen werden diese Bibliotheken mit Python installiert. Auf Unix-basierten Systemen werden sie über Paketsammlungen bereitgestellt.
Um die Bibliothek für Ihre Python-Version anzuzeigen, navigieren Sie zu:
- Python 3.8-Standardbibliothek
- Python 3.9-Standardbibliothek
- Python 3.10-Standardbibliothek
- Python 3.11-Standardbibliothek
Azure Functions: Python-Workerabhängigkeiten
Für den Azure Functions-Python-Worker wird ein bestimmter Satz Bibliotheken benötigt. Sie können diese Bibliotheken auch in Ihren Funktionen verwenden, aber sie sind nicht Teil des Python-Standards. Sofern Ihre Funktionen auf einer dieser Bibliotheken basieren, sind sie für Ihren Code ggf. nicht verfügbar, wenn die Ausführung außerhalb von Azure Functions erfolgt. Eine detaillierte Liste mit den Abhängigkeiten finden Sie im Abschnitt „install_requires“ der Datei setup.py.
Hinweis
Wenn die Datei requirements.txt Ihrer Funktions-App den Eintrag azure-functions-worker enthält, müssen Sie ihn entfernen. Der Funktionsworker wird automatisch von der Azure Functions-Plattform verwaltet, und wir aktualisieren ihn regelmäßig mit neuen Features und Fehlerbehebungen. Die manuelle Installation einer alten Version des Workers in der Datei requirements.txt kann zu unerwarteten Problemen führen.
Hinweis
Wenn Ihr Paket bestimmte Bibliotheken enthält, die mit den Abhängigkeiten des Workers in Konflikt stehen können (z. B. protobuf, tensorflow, grpcio), konfigurieren Sie PYTHON_ISOLATE_WORKER_DEPENDENCIES in den App-Einstellungen mit 1, um zu verhindern, dass Ihre Anwendung auf die Abhängigkeiten des Workers verweist.
Die Azure Functions-Python-Bibliothek
Jedes Update eines Python-Workers enthält eine neue Version der Azure Functions-Python-Bibliothek (azure.functions). Dieser Ansatz vereinfacht es, Ihre Python-Funktions-Apps fortlaufend zu aktualisieren, weil jedes Update abwärtskompatibel ist. Eine Liste mit den Releases dieser Bibliothek finden Sie unter azure-functions PyPi.
Die Version der Runtimebibliothek ist in Azure festgelegt und kann mit requirements.txt nicht überschrieben werden. Der Eintrag azure-functions in der Datei requirements.txt dient nur zum Linten und zur Kenntnisnahme durch den Kunden.
Verwenden Sie den folgenden Code, um die tatsächliche Version der Functions-Python-Bibliothek in Ihrer Runtime nachzuverfolgen:
getattr(azure.functions, '__version__', '< 1.2.1')
Runtimesystembibliotheken
Eine Liste mit den vorinstallierten Systembibliotheken in Docker-Images von Python-Workern finden Sie unter den folgenden Links:
| Functions-Runtime | Debian-Version | Python-Versionen |
|---|---|---|
| Version 3.x | Buster | Python 3.7 Python 3.8 Python 3.9 |
Python-Workererweiterungen
Mit dem Python-Workerprozess, der in Azure Functions ausgeführt wird, können Sie Bibliotheken von Drittanbietern in Ihre Funktions-App integrieren. Diese Erweiterungsbibliotheken fungieren als Middleware, die während des Lebenszyklus der Ausführung Ihrer Funktion bestimmte Vorgänge einfügen kann.
Erweiterungen werden ähnlich wie ein Python-Standardbibliotheksmodul in Ihren Funktionscode importiert. Erweiterungen werden basierend auf den folgenden Bereichen ausgeführt:
| `Scope` | BESCHREIBUNG |
|---|---|
| Anwendungsebene | Beim Importieren in einen beliebigen Funktionsauslöser gilt die Erweiterung für jede Funktionsausführung in der App. |
| Funktionsebene | Die Ausführung ist nur auf den entsprechenden Funktionsauslöser beschränkt, in den sie importiert wird. |
Überprüfen Sie die Informationen für jede Erweiterung, um mehr über den Bereich zu erfahren, in dem die Erweiterung ausgeführt wird.
Erweiterungen implementieren eine Python-Workererweiterungsschnittstelle. Damit kann der Python-Workerprozess während des Ausführungslebenszyklus der Funktion den Erweiterungscode aufrufen. Weitere Informationen finden Sie unter Erstellen von Erweiterungen.
Verwenden von Erweiterungen
Sie können eine Python-Workererweiterungsbibliothek in Ihren Python-Funktionen verwenden, indem Sie folgendermaßen vorgehen:
- Fügen Sie das Erweiterungspaket in der Datei requirements.txt für Ihr Projekt hinzu.
- Installieren Sie die Bibliothek in Ihrer App.
- Fügen Sie die folgenden Anwendungseinstellungen hinzu:
- Lokal: Geben Sie
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"im AbschnittValuesIhrer Datei local.settings.json ein. - Azure: Geben Sie
PYTHON_ENABLE_WORKER_EXTENSIONS=1in Ihren App-Einstellungen ein.
- Lokal: Geben Sie
- Importieren Sie das Erweiterungsmodul in Ihren Funktionsauslöser.
- Konfigurieren Sie bei Bedarf die Erweiterungsinstanz. Die Konfigurationsanforderungen sollten in der Dokumentation der Erweiterung aufgeführt sein.
Wichtig
Python-Workererweiterungsbibliotheken von Drittanbietern werden von Microsoft nicht unterstützt bzw. Microsoft übernimmt dahingehend keine Gewährleistungen. Sie müssen sicherstellen, dass alle Erweiterungen, die Sie in Ihrer Funktions-App verwenden, vertrauenswürdig sind, d. h. Sie tragen das volle Risiko im Hinblick auf die Verwendung einer schädlichen oder schlecht geschriebenen Erweiterung.
Drittanbieter sollten die entsprechende Dokumentation zur Installation und Verwendung ihrer Erweiterung in Ihrer Funktions-App bereitstellen. Ein einfaches Beispiel für die Verwendung einer Erweiterung finden Sie unter Nutzen Ihrer Erweiterung.
Im Folgenden finden Sie Beispiele für die Verwendung von Erweiterungen in einer Funktions-App nach Bereichen geordnet:
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
Erstellen von Erweiterungen
Erweiterungen werden von Bibliotheksentwicklern von Drittanbietern erstellt, die Funktionen erstellt haben, die in Azure Functions integriert werden können. Ein Erweiterungsentwickler entwirft, implementiert und veröffentlicht Python-Pakete, die eine benutzerdefinierte Logik enthalten, die speziell für den Kontext der Funktionsausführung entwickelt wurde. Diese Erweiterungen können entweder in der PyPI-Registrierung oder in GitHub-Repositorys veröffentlicht werden.
Informationen zum Erstellen, Packen, Veröffentlichen und Verwenden eines Python-Workererweiterungspakets finden Sie unter Entwickeln von Python-Workererweiterungen für Azure Functions.
Erweiterungen auf Anwendungsebene
Eine von AppExtensionBase geerbte Erweiterung wird in einem Anwendungsbereich ausgeführt.
AppExtensionBase macht die folgenden abstrakten Klassenmethoden verfügbar, die Sie implementieren können:
| Methode | BESCHREIBUNG |
|---|---|
init |
Wird aufgerufen, nachdem die Erweiterung importiert wurde. |
configure |
Wird bei Bedarf vom Funktionscode aufgerufen, um die Erweiterung zu konfigurieren. |
post_function_load_app_level |
Wird direkt nach dem Laden der Funktion aufgerufen. Der Funktionsname und das Funktionsverzeichnis werden an die Erweiterung übergeben. Beachten Sie, dass das Funktionsverzeichnis schreibgeschützt ist, und jeder Versuch, in einelokale Datei in diesem Verzeichnis zu schreiben, fehlschlägt. |
pre_invocation_app_level |
Wird direkt vor dem Auslösen der Funktion aufgerufen. Die Funktionskontext und Funktionsaufrufargumente werden an die Erweiterung übergeben. Sie können in der Regel andere Attribute im Kontextobjekt übergeben, damit der Funktionscode verwendet werden kann. |
post_invocation_app_level |
Wird direkt nach Abschluss der Funktionsausführung aufgerufen. Der Funktionskontext, Funktionsaufrufargumente und das Aufruf-Rückgabeobjekt werden an die Erweiterung übergeben. Diese Implementierung ist ein guter Ort, um zu überprüfen, ob die Ausführung der Lebenszyklushooks erfolgreich war. |
Erweiterungen auf Funktionsebene
Eine Erweiterung, die von FuncExtensionBase geerbt wird, wird in einem spezifischen Funktionsauslöser ausgeführt.
FuncExtensionBase macht die folgenden abstrakten Klassenmethoden zur Implementierung verfügbar:
| Methode | BESCHREIBUNG |
|---|---|
__init__ |
Der Konstruktor der Erweiterung. Sie wird aufgerufen, wenn eine Erweiterungsinstanz in einer bestimmten Funktion initialisiert wird. Wenn Sie diese abstrakte Methode implementieren, sollten Sie einen filename-Parameter akzeptieren und an die super().__init__(filename)-Methode des übergeordneten Elements übergeben, um eine ordnungsgemäße Erweiterungsregistrierung zu erhalten. |
post_function_load |
Wird direkt nach dem Laden der Funktion aufgerufen. Der Funktionsname und das Funktionsverzeichnis werden an die Erweiterung übergeben. Beachten Sie, dass das Funktionsverzeichnis schreibgeschützt ist, und jeder Versuch, in einelokale Datei in diesem Verzeichnis zu schreiben, fehlschlägt. |
pre_invocation |
Wird direkt vor dem Auslösen der Funktion aufgerufen. Die Funktionskontext und Funktionsaufrufargumente werden an die Erweiterung übergeben. Sie können in der Regel andere Attribute im Kontextobjekt übergeben, damit der Funktionscode verwendet werden kann. |
post_invocation |
Wird direkt nach Abschluss der Funktionsausführung aufgerufen. Der Funktionskontext, Funktionsaufrufargumente und das Aufruf-Rückgabeobjekt werden an die Erweiterung übergeben. Diese Implementierung ist ein guter Ort, um zu überprüfen, ob die Ausführung der Lebenszyklushooks erfolgreich war. |
Cross-Origin Resource Sharing
Azure Functions unterstützt jetzt die Ressourcenfreigabe zwischen verschiedenen Ursprüngen (Cross-Origin Resource Sharing, CORS). CORS wird im Portal und über die Azure-Befehlszeilenschnittstelle konfiguriert. Die CORS-Liste der zulässigen Ursprünge gilt auf Funktions-App-Ebene. Wenn CORS aktiviert ist, enthalten Antworten den Access-Control-Allow-Origin-Header. Weitere Informationen finden Sie unter Cross-Origin Resource Sharing (CORS).
CORS (Cross-Origin Resource Sharing) wird für Python-Funktions-Apps vollständig unterstützt.
Async
Standardmäßig kann eine Hostinstanz für Python nur jeweils einen Funktionsaufruf gleichzeitig verarbeiten. Dies liegt daran, dass Python eine Singlethread-Runtime ist. Für eine Funktions-App, die eine große Anzahl von E/A-Ereignissen verarbeitet oder E/A-gebunden ist, können Sie die Leistung erheblich verbessern, indem Sie Funktionen asynchron ausführen. Weitere Informationen finden Sie unter Verbessern der Leistung von Python-Apps in Azure Functions.
Shared Memory (Vorschau)
Um den Durchsatz zu verbessern, ermöglicht Azure Functions eine gemeinsame Speichernutzung durch den Out-of-Process-Python-Sprachworker und den Functions-Hostprozess. Wenn Ihre Funktions-App auf Engpässe stößt, können Sie „Shared Memory“ aktivieren, indem Sie eine Anwendungseinstellung namens FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED mit dem Wert 1 hinzufügen. Wenn „Shared Memory“ aktiviert ist, können Sie dann die Einstellung DOCKER_SHM_SIZE verwenden, um für den gemeinsam genutzten Speicherbereich den Wert 268435456 einzustellen, was 256 MB entspricht.
Sie können beispielsweise die gemeinsame Nutzung des Speichers aktivieren, um Engpässe zu vermeiden, wenn Sie Blob-Storage-Bindungen für die Übertragung von Nutzdaten mit einer Größe von mehr als 1 MB verwenden.
Diese Funktionalität ist nur für Funktions-Apps verfügbar, die in Premium- und dedizierten (Azure App Service) Plänen ausgeführt werden. Weitere Informationen finden Sie unter Gemeinsam genutzter Speicher.
Bekannte Probleme und FAQ
Hier finden Sie zwei Leitfäden zur Problembehandlung für häufig auftretende Probleme:
Dies sind zwei Leitfäden zur Problembehandlung für bekannte Probleme mit dem v2-Programmiermodell:
- Datei oder Assembly konnte nicht geladen werden
- Die Azure Storage-Verbindung mit dem Namen „Storage“ kann nicht aufgelöst werden
Alle bekannten Probleme und Funktionsanfragen werden in einer Liste „GitHub-Probleme“ nachverfolgt. Wenn Sie auf ein Problem stoßen, das in GitHub nicht zu finden ist, öffnen Sie ein neues Issue mit einer ausführlichen Problembeschreibung.
Nächste Schritte
Weitere Informationen finden Sie in den folgenden Ressourcen:
- Dokumentation zur Azure Functions-Paket-API
- Bewährte Methoden für Azure Functions
- Trigger und Bindungen in Azure Functions
- Blob Storage-Bindungen
- HTTP- und Webhook-Bindungen
- Queue Storage-Bindungen
- Timertrigger
Haben Sie Probleme mit der Verwendung von Python? Teilen Sie uns mit, was los ist.