Verwenden eines Azure KI Vision-Containers mit Kubernetes und Helm
Eine Möglichkeit zur lokalen Verwaltung Ihrer Azure KI Vision-Container ist die Verwendung von Kubernetes und Helm. Hier erfahren Sie, wie Sie ein Kubernetes-Paket erstellen und dabei Kubernetes und Helm verwenden, um ein Azure KI Vision-Containerimage zu definieren. Dieses Paket wird dann lokal für einen Kubernetes-Cluster bereitgestellt. Außerdem erfahren Sie, wie Sie die bereitgestellten Dienste testen. Weitere Informationen zum Ausführen von Docker-Containern ohne Kubernetes-Orchestrierung finden Sie unter Installieren und Ausführen von Azure KI Vision-Containern.
Voraussetzungen
Die folgenden Voraussetzungen müssen erfüllt sein, bevor Azure KI Vision-Container lokal verwendet werden können:
| Erforderlich | Zweck |
|---|---|
| Azure-Konto | Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. |
| Kubernetes-Befehlszeilenschnittstelle | Mithilfe der Kubernetes-Befehlszeilenschnittstelle werden die gemeinsam genutzten Anmeldeinformationen aus der Containerregistrierung verwaltet. Kubernetes wird außerdem vor Helm (Kubernetes-Paket-Manager) benötigt. |
| Helm-Befehlszeilenschnittstelle | Installieren Sie die Helm-Befehlszeilenschnittstelle. Sie wird zum Installieren eines Helm-Charts (Containerpaketdefinition) verwendet. |
| Ressource für maschinelles Sehen | Um den Container zu verwenden, benötigen Sie Folgendes: Eine Ressource vom Typ Maschinelles Sehen sowie den zugehörigen API-Schlüssel und Endpunkt-URI. Beide Werte stehen auf der Übersichts- und auf der Schlüsselseite der Ressource zur Verfügung und werden zum Starten des Containers benötigt. {API_KEY} : Einer der beiden verfügbaren Ressourcenschlüssel auf der Seite Schlüssel {ENDPOINT_URI} : Der Endpunkt, der auf der Seite Übersicht angegeben ist |
Erfassen erforderlicher Parameter
Für alle Azure KI-Container werden drei primäre Parameter benötigt. Die Microsoft-Software-Lizenzbedingungen müssen mit dem Wert accept vorhanden sein. Außerdem werden ein Endpunkt-URI und ein API-Schlüssel benötigt.
Endpunkt-URI
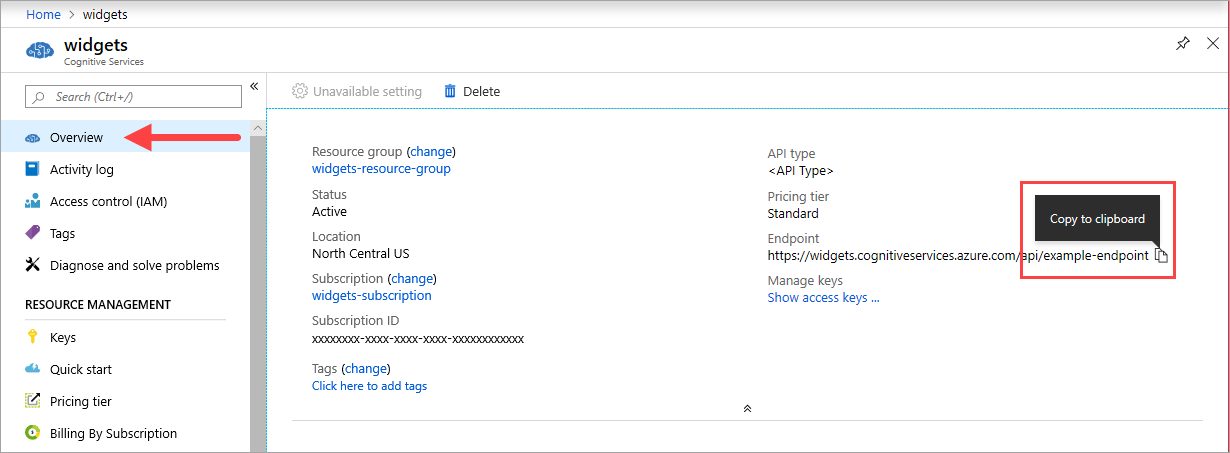
Der {ENDPOINT_URI}-Wert ist im Azure-Portal auf der Seite Übersicht der entsprechenden Azure KI Services-Ressource verfügbar. Wechseln Sie zur Seite Übersicht, zeigen Sie auf den Endpunkt, und das Symbol In Zwischenablage kopieren wird angezeigt. Kopieren Sie den Endpunkt, und verwenden Sie ihn bei Bedarf.
Tasten
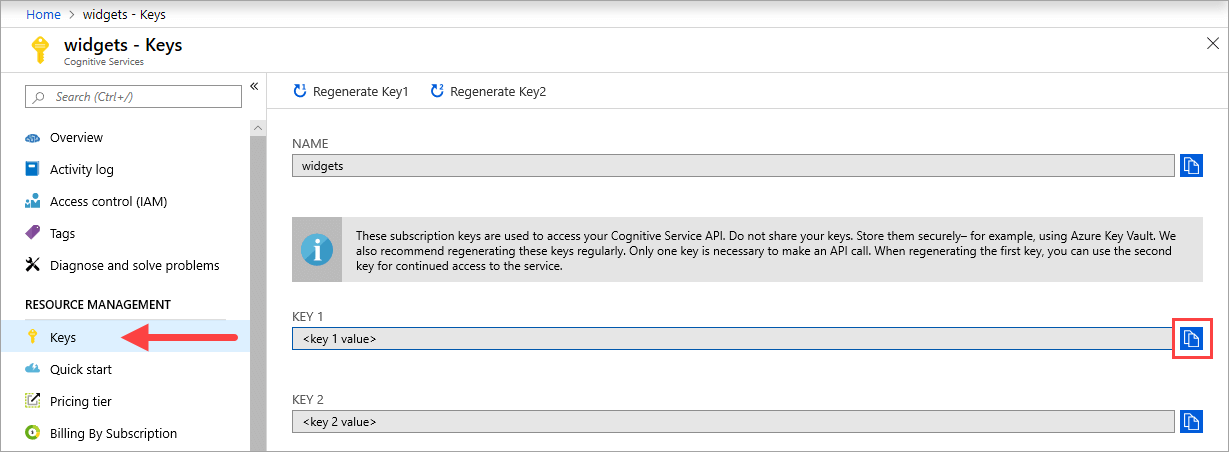
Der {API_KEY}-Wert wird zum Starten des Containers verwendet und ist im Azure-Portal auf der Seite Schlüssel der entsprechenden Azure KI Services-Ressource verfügbar. Wechseln Sie zur Seite Schlüssel, und wählen Sie das Symbol In Zwischenablage kopieren aus.
Wichtig
Diese Abonnementschlüssel werden für den Zugriff auf Ihre Azure KI Services-API verwendet. Geben Sie Ihre Schlüssel nicht weiter. Speichern Sie diese sicher. Verwenden Sie beispielsweise Azure Key Vault. Außerdem wird empfohlen, diese Schlüssel regelmäßig neu zu generieren. Für einen API-Aufruf ist nur ein Schlüssel erforderlich. Beim Neugenerieren des ersten Schlüssels können Sie den zweiten Schlüssel für kontinuierlichen Zugriff auf den Dienst verwenden.
Der Hostcomputer
Der Host ist ein x64-basierter Computer, auf dem der Docker-Container ausgeführt wird. Dies kann ein lokaler Computer oder ein Docker-Hostingdienst in Azure sein, z. B.:
- Azure Kubernetes Service
- Azure Container Instances
- Ein in Azure Stack bereitgestellter Kubernetes-Cluster Weitere Informationen finden Sie unter Bereitstellen von Kubernetes in Azure Stack.
Containeranforderungen und -empfehlungen
Hinweis
Die Anforderungen und Empfehlungen basieren auf Benchmarks mit einer einzelnen Anforderung pro Sekunde, wobei ein 523 KB großes Bild eines gescannten Geschäftsbriefs mit 29 Zeilen und insgesamt 803 Zeichen verwendet wird. Die empfohlene Konfiguration führte im Vergleich zur Mindestkonfiguration zu einer etwa doppelt so schnellen Reaktion.
In der folgenden Tabelle werden die minimale und empfohlene Zuordnung von Ressourcen für jeden OCR-Container für das Lesen beschrieben.
| Container | Minimum | Empfohlen |
|---|---|---|
| Read 3.2 2022-04-30 | 4 Kerne, 8 GB Arbeitsspeicher | 8 Kerne, 16 GB Arbeitsspeicher |
| Read 3.2 2021-04-12 | 4 Kerne, 16 GB Arbeitsspeicher | 8 Kerne, 24 GB Arbeitsspeicher |
- Jeder Kern muss eine Geschwindigkeit von mindestens 2,6 GHz aufweisen.
Kern und Arbeitsspeicher entsprechen den Einstellungen --cpus und --memory, die im Rahmen des Befehls docker run verwendet werden.
Herstellen einer Verbindung mit dem Kubernetes-Cluster
Für den Hostcomputer muss ein verfügbarer Kubernetes-Cluster vorhanden sein. Das Konzept der Bereitstellung eines Kubernetes-Clusters für einen Hostcomputer wird im Tutorial Bereitstellen eines Azure Kubernetes Service-Clusters (AKS) erläutert. Weitere Informationen zu Bereitstellungen finden Sie in der Kubernetes-Dokumentation.
Konfigurieren von Helm-Chart-Werten für die Bereitstellung
Erstellen Sie zunächst einen Ordner mit dem Namen read. Fügen Sie dann den folgenden YAML-Inhalt in eine neue Datei mit dem Namen chart.yaml ein:
apiVersion: v2
name: read
version: 1.0.0
description: A Helm chart to deploy the Read OCR container to a Kubernetes cluster
dependencies:
- name: rabbitmq
condition: read.image.args.rabbitmq.enabled
version: ^6.12.0
repository: https://kubernetes-charts.storage.googleapis.com/
- name: redis
condition: read.image.args.redis.enabled
version: ^6.0.0
repository: https://kubernetes-charts.storage.googleapis.com/
Kopieren Sie zum Konfigurieren der Standardwerte des Helm-Charts den folgenden YAML-Code, und fügen Sie ihn in eine Datei namens values.yaml ein. Ersetzen Sie die Kommentare # {ENDPOINT_URI} und # {API_KEY} durch Ihre eigenen Werte. Konfigurieren Sie bei Bedarf resultExpirationPeriod, Redis und RabbitMQ.
# These settings are deployment specific and users can provide customizations
read:
enabled: true
image:
name: cognitive-services-read
registry: mcr.microsoft.com/
repository: azure-cognitive-services/vision/read
tag: 3.2-preview.1
args:
eula: accept
billing: # {ENDPOINT_URI}
apikey: # {API_KEY}
# Result expiration period setting. Specify when the system should clean up recognition results.
# For example, resultExpirationPeriod=1, the system will clear the recognition result 1hr after the process.
# resultExpirationPeriod=0, the system will clear the recognition result after result retrieval.
resultExpirationPeriod: 1
# Redis storage, if configured, will be used by read OCR container to store result records.
# A cache is required if multiple read OCR containers are placed behind load balancer.
redis:
enabled: false # {true/false}
password: password
# RabbitMQ is used for dispatching tasks. This can be useful when multiple read OCR containers are
# placed behind load balancer.
rabbitmq:
enabled: false # {true/false}
rabbitmq:
username: user
password: password
Wichtig
Ohne Angabe der Werte
billingundapikeylaufen die Dienste nach 15 Minuten ab. Ebenso führt die Überprüfung zu Fehlern, da die Dienste nicht verfügbar sind.Wenn Sie mehrere OCR-Container für das Lesen hinter einem Lastenausgleich bereitstellen (z. B. unter Docker Compose oder Kubernetes), benötigen Sie einen externen Cache. Da der Verarbeitungscontainer und der GET-Anforderungscontainer möglicherweise nicht identisch sind, werden die Ergebnisse in einem externen Cache gespeichert und dort für die Container freigegeben. Ausführliche Informationen zu Cacheeinstellungen finden Sie im Artikel zum Konfigurieren von Docker-Containern für Azure KI Vision.
Erstellen Sie den Ordner templates unter dem Verzeichnis read. Kopieren Sie den folgenden YAML-Code, und fügen Sie ihn in eine Datei mit dem Namen deployment.yaml ein. Die deployment.yaml-Datei dient als Helm-Vorlage.
Vorlagen generieren Manifestdateien, die Beschreibungen von Ressourcen im YAML-Format darstellen, die von Kubernetes verstanden werden können. - Leitfaden zur Vorlage für Helm-Charts
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: {{.Values.read.image.name}}
image: {{.Values.read.image.registry}}{{.Values.read.image.repository}}
ports:
- containerPort: 5000
env:
- name: EULA
value: {{.Values.read.image.args.eula}}
- name: billing
value: {{.Values.read.image.args.billing}}
- name: apikey
value: {{.Values.read.image.args.apikey}}
args:
- ReadEngineConfig:ResultExpirationPeriod={{ .Values.read.image.args.resultExpirationPeriod }}
{{- if .Values.read.image.args.rabbitmq.enabled }}
- Queue:RabbitMQ:HostName={{ include "rabbitmq.hostname" . }}
- Queue:RabbitMQ:Username={{ .Values.read.image.args.rabbitmq.rabbitmq.username }}
- Queue:RabbitMQ:Password={{ .Values.read.image.args.rabbitmq.rabbitmq.password }}
{{- end }}
{{- if .Values.read.image.args.redis.enabled }}
- Cache:Redis:Configuration={{ include "redis.connStr" . }}
{{- end }}
imagePullSecrets:
- name: {{.Values.read.image.pullSecret}}
---
apiVersion: v1
kind: Service
metadata:
name: read-service
spec:
type: LoadBalancer
ports:
- port: 5000
selector:
app: read-app
Kopieren Sie die folgenden Hilfsfunktionen in helpers.tpl, und fügen Sie sie in denselben Ordner templates ein. helpers.tpl definiert nützliche Funktionen zum Generieren der Helm-Vorlage.
{{- define "rabbitmq.hostname" -}}
{{- printf "%s-rabbitmq" .Release.Name -}}
{{- end -}}
{{- define "redis.connStr" -}}
{{- $hostMain := printf "%s-redis-master:6379" .Release.Name }}
{{- $hostReplica := printf "%s-redis-replica:6379" .Release.Name -}}
{{- $passWord := printf "password=%s" .Values.read.image.args.redis.password -}}
{{- $connTail := "ssl=False,abortConnect=False" -}}
{{- printf "%s,%s,%s,%s" $hostMain $hostReplica $passWord $connTail -}}
{{- end -}}
Die Vorlage gibt einen Lastenausgleichsdienst und die Bereitstellung Ihres Containers/Bilds für das Lesen an.
Das Kubernetes-Paket (Helm-Chart)
Das Helm-Chart enthält die Konfiguration, die angibt, welche Docker-Images aus der Containerregistrierung mcr.microsoft.com gepullt werden sollen.
Bei einem Helm-Chart handelt es sich um eine Sammlung von Dateien, die eine zusammengehörige Gruppe von Kubernetes-Ressourcen beschreiben. Ein einzelnes Chart kann sowohl für eine einfache Bereitstellung (beispielsweise eines Memcached-Pods) als auch für komplexere Bereitstellungen (etwa eines vollständigen Web-App-Stapels mit HTTP-Servern, Datenbanken, Caches und Ähnlichem) verwendet werden.
Die bereitgestellten Helm-Charts pullen die Docker-Images des Azure KI Vision-Diensts und den entsprechenden Dienst aus der Containerregistrierung mcr.microsoft.com.
Installieren des Helm-Charts für den Kubernetes-Cluster
Zum Installieren des Helm-Diagramms muss der Befehl helm install ausgeführt werden. Stellen Sie sicher, dass Sie den Installationsbefehl im Verzeichnis über dem Ordner read ausführen.
helm install read ./read
Die Ausgabe nach einer erfolgreichen Installation kann beispielsweise wie folgt aussehen:
NAME: read
LAST DEPLOYED: Thu Sep 04 13:24:06 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
read-57cb76bcf7-45sdh 0/1 ContainerCreating 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 0s
==> v1beta1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
read 0/1 1 0 0s
Der Kubernetes-Bereitstellungsvorgang kann mehrere Minuten dauern. Vergewissern Sie sich durch Ausführen des folgenden Befehls, dass die Pods und Dienste ordnungsgemäß bereitgestellt wurden und verfügbar sind:
kubectl get all
Die Ausgabe sollte in etwa wie folgt aussehen:
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-57cb76bcf7-45sdh 1/1 Running 0 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45h
service/read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 17s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 1/1 1 1 17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-57cb76bcf7 1 1 1 17s
Bereitstellen mehrerer V3-Container auf dem Kubernetes-Cluster
Ab V3 des Containers können Sie die Container parallel auf Aufgaben- und Seitenebene verwenden.
Entwurfsbedingt verfügt jeder V3-Container über einen Verteiler und einen Erkennungsworker. Der Verteiler ist dafür verantwortlich, eine mehrseitige Aufgabe in mehrere einzelne Unteraufgaben mit nur einer Seite aufzuteilen. Der Erkennungsworker ist für die Erkennung eines Dokuments mit nur einer Seite optimiert. Um Parallelität auf Seitenebene zu erreichen, stellen Sie mehrere V3-Container hinter einem Load Balancer bereit, und lassen Sie die Container einen universellen Speicher und eine universelle Warteschlange freigeben.
Hinweis
Zurzeit werden nur Azure Storage und die Azure-Warteschlange unterstützt.
Der Container, der die Anforderung empfängt, kann die Aufgabe in einseitige untergeordnete Aufgaben aufteilen und sie der universellen Warteschlange hinzufügen. Jeder Erkennungsworker aus einem Container mit geringerer Auslastung kann einseitige Unteraufgaben aus der Warteschlange nutzen, eine Erkennung durchführen und das Ergebnis in den Speicher hochladen. Der Durchsatz kann je nach Anzahl der bereitgestellten Container bis zu n Mal verbessert werden.
Der V3-Container stellt die Livetest-API unter dem Pfad /ContainerLiveness bereit. Verwenden Sie das folgende Bereitstellungsbeispiel, um einen Livetest für Kubernetes zu konfigurieren.
Kopieren Sie den folgenden YAML-Code, und fügen Sie ihn in eine Datei mit dem Namen deployment.yaml ein. Ersetzen Sie die Kommentare # {ENDPOINT_URI} und # {API_KEY} durch Ihre eigenen Werte. Ersetzen Sie den # {AZURE_STORAGE_CONNECTION_STRING}-Kommentar durch Ihre Azure Storage-Verbindungszeichenfolge. Konfigurieren Sie replicas auf die gewünschte Anzahl, die im folgenden Beispiel auf 3 festgelegt ist.
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
replicas: # {NUMBER_OF_READ_CONTAINERS}
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: cognitive-services-read
image: mcr.microsoft.com/azure-cognitive-services/vision/read
ports:
- containerPort: 5000
env:
- name: EULA
value: accept
- name: billing
value: # {ENDPOINT_URI}
- name: apikey
value: # {API_KEY}
- name: Storage__ObjectStore__AzureBlob__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
- name: Queue__Azure__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
livenessProbe:
httpGet:
path: /ContainerLiveness
port: 5000
initialDelaySeconds: 60
periodSeconds: 60
timeoutSeconds: 20
---
apiVersion: v1
kind: Service
metadata:
name: azure-cognitive-service-read
spec:
type: LoadBalancer
ports:
- port: 5000
targetPort: 5000
selector:
app: read-app
Führen Sie den folgenden Befehl aus.
kubectl apply -f deployment.yaml
Nachfolgend finden Sie eine Beispielausgabe, die bei erfolgreicher Bereitstellungsausführung angezeigt werden kann:
deployment.apps/read created
service/azure-cognitive-service-read created
Der Kubernetes-Bereitstellungsvorgang kann mehrere Minuten dauern. Vergewissern Sie sich, dass die Pods und Dienste ordnungsgemäß bereitgestellt wurden und verfügbar sind, und führen Sie dann den folgenden Befehl aus:
kubectl get all
Eine Konsolenausgabe ähnlich der folgenden sollte angezeigt werden:
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-6cbbb6678-58s9t 1/1 Running 0 3s
pod/read-6cbbb6678-kz7v4 1/1 Running 0 3s
pod/read-6cbbb6678-s2pct 1/1 Running 0 3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/azure-cognitive-service-read LoadBalancer 10.0.134.0 <none> 5000:30846/TCP 17h
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 78d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 3/3 3 3 3s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-6cbbb6678 3 3 3 3s
Überprüfen auf aktive Container
Es gibt mehrere Möglichkeiten zu überprüfen, ob ein Container aktiv ist. Suchen Sie die externe IP-Adresse und den verfügbar gemachten Port des betreffenden Containers, und öffnen Sie Ihren bevorzugten Webbrowser. Verwenden Sie die folgenden verschiedenen URLs für Anforderungen, um zu überprüfen, ob der Container ausgeführt wird. Die hier aufgeführten Beispiel-URLs für Anforderungen sind http://localhost:5000, aber Ihr spezifischer Container kann variieren. Stellen Sie sicher, dass Sie sich auf die externe IP-Adresse Ihres Containers und den verfügbar gemachten Port beziehen.
| Anforderungs-URL | Zweck |
|---|---|
http://localhost:5000/ |
Der Container stellt eine Homepage bereit. |
http://localhost:5000/ready |
Diese mit GET angeforderte URL ermöglicht es, zu überprüfen, ob der Container eine Abfrage des Modells akzeptiert. Diese Anforderung kann für Live- und Bereitschaftstests von Kubernetes verwendet werden. |
http://localhost:5000/status |
Diese URL wird auch mit GET angefordert und überprüft, ob der zum Starten des Containers verwendete API-Schlüssel gültig ist, ohne dass eine Endpunktabfrage veranlasst wird. Diese Anforderung kann für Live- und Bereitschaftstests von Kubernetes verwendet werden. |
http://localhost:5000/swagger |
Der Container stellt eine umfassende Dokumentation für die Endpunkte sowie die Funktion Jetzt ausprobieren bereit. Diese Funktion ermöglicht Ihnen die Eingabe Ihrer Einstellungen in einem webbasierten HTML-Formular, sodass Sie die Abfrage ausführen können, ohne Code schreiben zu müssen. Nach der Rückgabe der Abfrage wird ein cURL-Beispielbefehl bereitgestellt, der das erforderliche Format für HTTP-Header und -Text veranschaulicht. |

Nächste Schritte
Ausführlichere Informationen zum Installieren von Anwendungen mit Helm in Azure Kubernetes Service (AKS) finden Sie hier.