Überwachen der Clusterleistung in Azure HDInsight
Die Überwachung der Integrität und Leistung eines HDInsight-Clusters ist sehr wichtig, um eine optimale Leistung und Ressourcenverwendung zu gewährleisten. Darüber hinaus kann die Überwachung dazu beitragen, Clusterkonfigurationsfehler und Benutzercodeprobleme zu erkennen und zu behandeln.
In den folgenden Abschnitten erfahren Sie, wie Sie die Last in Ihren Clustern und Apache Hadoop YARN-Warteschlangen überwachen und optimieren und wie Sie Speicherdrosselungsprobleme erkennen.
Überwachen der Clusterlast
Die Leistung von Hadoop-Clustern ist am besten, wenn die Last des Clusters gleichmäßig auf alle Knoten verteilt ist. Dadurch können Verarbeitungsaufgaben ausgeführt werden, ohne durch Arbeitsspeicher-, CPU- oder Datenträgerressourcen auf einzelnen Knoten eingeschränkt zu werden.
Melden Sie sich bei der Ambari-Webbenutzeroberfläche an, und wählen Sie dann die Registerkarte Hosts aus, um sich einen allgemeinen Überblick über die Knoten Ihres Clusters und deren Last zu verschaffen. Ihre Hosts werden anhand ihrer vollqualifizierten Domänennamen aufgelistet. Der Betriebsstatus jedes Hosts wird mit einer farbigen Integritätsanzeige angegeben:
| Color | BESCHREIBUNG |
|---|---|
| Red | Mindestens eine Master-Komponente auf dem Host ist ausgefallen. Zeigen Sie mit der Maus darauf, um eine QuickInfo mit den betroffenen Komponenten anzuzeigen. |
| Orange | Mindestens eine sekundäre Komponente auf dem Host ist ausgefallen. Zeigen Sie mit der Maus darauf, um eine QuickInfo mit den betroffenen Komponenten anzuzeigen. |
| Gelb | Ambari Server hat seit mehr als drei Minuten keinen Heartbeat mehr vom Host empfangen. |
| Grün | Normaler Ausführungszustand |
Außerdem werden Spalten angezeigt, in denen die Anzahl von Kernen und die RAM-Menge für jeden Host sowie die Datenträgerauslastung und die durchschnittliche Auslastung angezeigt werden.
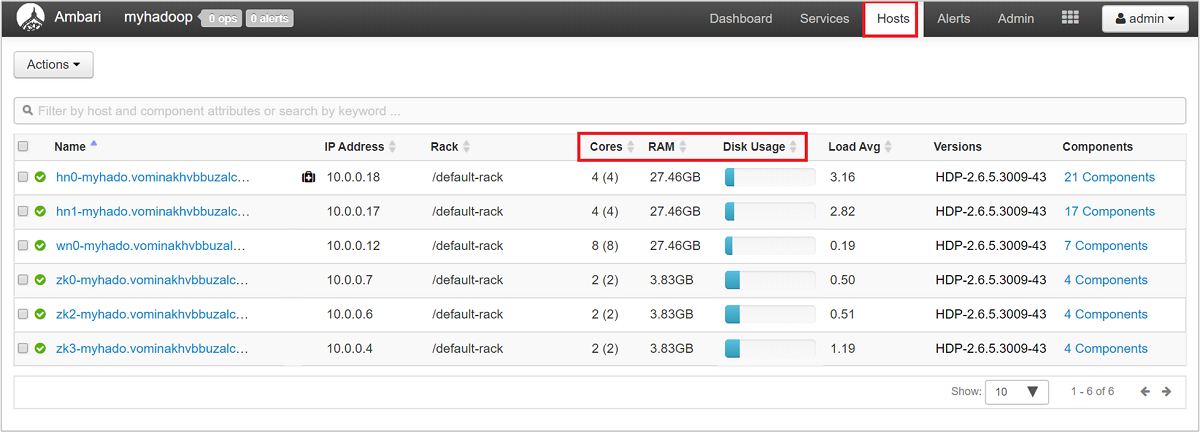
Wählen Sie einen beliebigen Hostnamen aus, um eine ausführliche Übersicht über die Komponenten, die auf diesem Host ausgeführt werden, und die dazugehörigen Metriken zu erhalten. Die Metriken werden als auswählbare Zeitachse für CPU-Auslastung, Ladezustand, Datenträgerauslastung, Speicherauslastung, Netzwerkauslastung und Anzahl von Prozessen angezeigt.
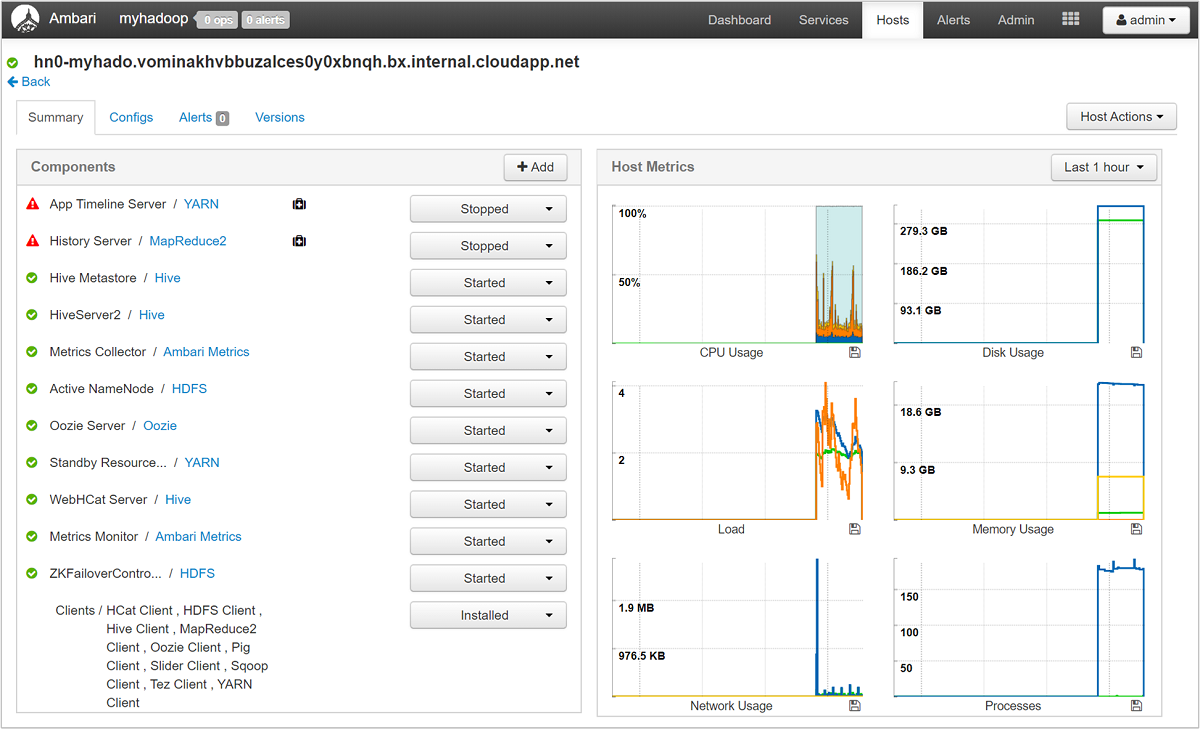
Unter Verwalten von HDInsight-Clustern mithilfe der Apache Ambari-Webbenutzeroberfläche finden Sie Details zum Festlegen von Warnungen und Anzeigen von Metriken.
Konfiguration von YARN-Warteschlangen
Hadoop verfügt über verschiedene Dienste, die auf der dazugehörigen verteilten Plattform ausgeführt werden. YARN (Yet Another Resource Negotiator) koordiniert diese Dienste und ordnet Clusterressourcen zu, um sicherzustellen, dass die Last gleichmäßig auf den gesamten Cluster verteilt wird.
YARN teilt die beiden Aufgaben von JobTracker (Ressourcenverwaltung und Auftragsplanung/-überwachung) auf zwei Daemons auf: einen globalen Ressourcen-Manager und einen anwendungsspezifischen ApplicationMaster (AM).
Der Ressourcen-Manager ist ein reiner Scheduler, dessen einzige Aufgabe darin besteht, die verfügbaren Ressourcen zwischen allen konkurrierenden Anwendungen zu vermitteln. Der Ressourcen-Manager stellt sicher, dass immer alle Ressourcen genutzt werden, und optimiert die Nutzung anhand verschiedener Konstanten (beispielsweise SLAs und Kapazitätsgarantien). Der ApplicationMaster handelt Ressourcen mit dem Ressourcen-Manager aus und arbeitet mit den NodeManager-Komponenten zusammen, um die Container und ihre entsprechende Ressourcennutzung auszuführen und zu überwachen.
Wenn mehrere Mandanten einen großen Cluster gemeinsam nutzen, wird auch ein Konkurrenzkampf um die Ressourcen des Clusters ausgetragen. Der CapacityScheduler ist ein austauschbarer Scheduler, der den Ressourcenaustausch unterstützt, indem Anforderungen in Warteschlangen eingereiht werden. Der CapacityScheduler unterstützt auch hierarchische Warteschlangen, um sicherzustellen, dass Ressourcen zwischen den Unterwarteschlangen einer Organisation gemeinsam genutzt werden, bevor Warteschlangen anderer Anwendungen kostenlose Ressourcen verwenden dürfen.
Mithilfe von YARN können diesen Warteschlangen Ressourcen zugeordnet werden, und es wird angezeigt, ob Ihre gesamten verfügbaren Ressourcen zugewiesen wurden. Melden Sie sich zum Anzeigen von Informationen zu Ihren Warteschlangen bei der Ambari-Webbenutzeroberfläche an, und wählen Sie im oberen Menü die Option YARN Queue Manager aus.
Auf der Seite „YARN Queue Manager“ wird links eine Liste mit Ihren Warteschlangen und der jeweils zugewiesene Kapazitätsprozentsatz angezeigt.
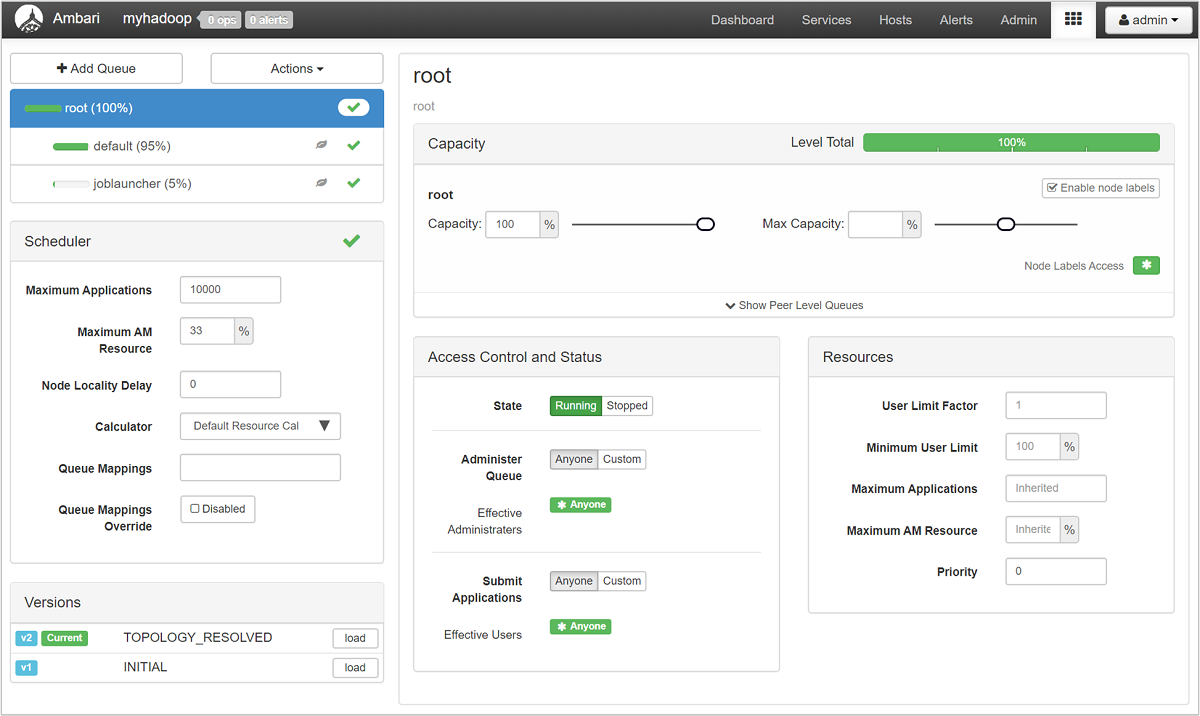
Einen ausführlicheren Überblick über Ihre Warteschlangen erhalten Sie, indem Sie im Ambari-Dashboard in der Liste auf der linken Seite den Dienst YARN auswählen. Wählen Sie anschließend im Dropdownmenü Quick Links (Quicklinks) unter Ihrem aktiven Knoten die Option Resource Manager UI (Benutzeroberfläche des Ressourcen-Managers) aus.
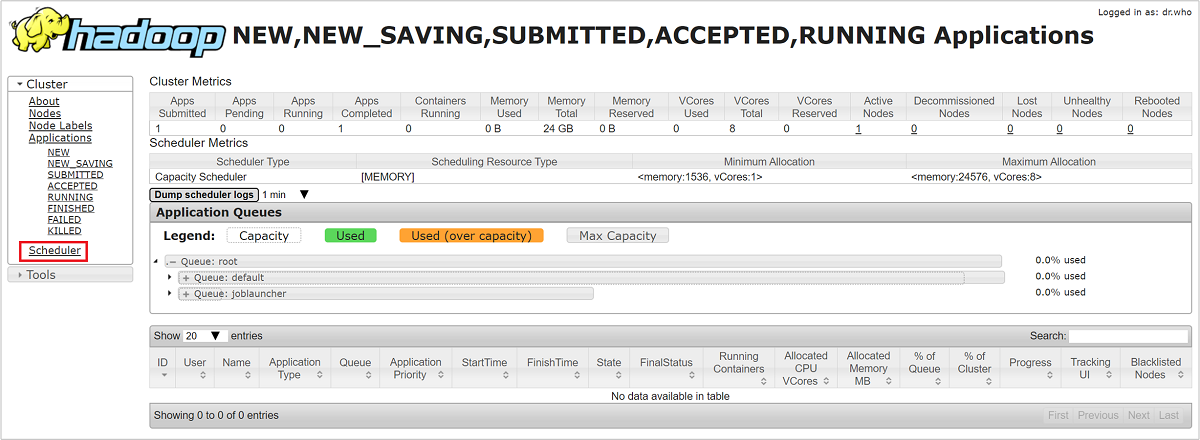
Wählen Sie auf der Benutzeroberfläche des Ressourcen-Managers im Menü auf der linken Seite die Option Scheduler aus. Unter Application Queues (Anwendungswarteschlangen) wird eine Liste mit Ihren Warteschlangen angezeigt. Hier sind die verwendete Kapazität für die einzelnen Warteschlangen, der Grad der Verteilung auf die Warteschlangen und etwaige Ressourceneinschränkungen für Aufträge angegeben.
Speicherdrosselung
Zu einem Leistungsengpass kann es für einen Cluster auf der Speicherebene kommen. Der Grund für diese Art von Engpass ist meistens eine Blockierung der E/A-Vorgänge. Dies geschieht, wenn Ihre ausgeführten Aufgaben mehr E/A-Daten senden, als vom Speicherdienst bewältigt werden können. Diese Blockierung führt zu einer Warteschlange mit E/A-Anforderungen, die auf ihre Verarbeitung nach der Verarbeitung der aktuellen E/A-Daten warten. Zu den Blockierungen kommt es aufgrund von Speicherdrosselung. Es handelt sich hierbei nicht um ein physisches Limit, sondern um eine Beschränkung durch den Speicherdienst per Vereinbarung zum Servicelevel (SLA). Mit dieser Beschränkung wird sichergestellt, dass kein einzelner Client oder Mandant über ein Monopol in Bezug auf den Dienst verfügt. Durch die Vereinbarung zum Servicelevel ist die Anzahl von E/A-Vorgängen pro Sekunde (IOs per second, IOPS) für Azure Storage beschränkt. Ausführliche Informationen finden Sie unter Skalierbarkeits- und Leistungsziele für Standardspeicherkonten.
Wenn Sie Azure Storage nutzen, finden Sie Informationen zur Überwachung von speicherbezogenen Problemen unter Microsoft Azure Storage: Überwachung, Diagnose und Problembehandlung.
Wenn Sie Azure Data Lake Storage (ADLS) als Sicherungsspeicher für Ihren Cluster verwenden, erfolgt die Drosselung bei Ihnen wahrscheinlich aufgrund von Einschränkungen der Bandbreite. Die Drosselung lässt sich in diesem Fall durch Beobachten der Drosselungsfehler in den Taskprotokollen ermitteln. Informationen zu ADLS finden Sie in den folgenden Artikeln jeweils im Abschnitt zur Drosselung für den entsprechenden Dienst:
- Anleitung für die Leistungsoptimierung für Apache Hive in HDInsight und Azure Data Lake Storage
- Anleitung für die Leistungsoptimierung für MapReduce in HDInsight und Azure Data Lake Storage
Beheben von Problemen bei der Leistung langsamer Knoten
Trägheit kann unter anderem auf wenig Speicherplatz im Cluster zurückzuführen sein. Führen Sie eine Untersuchung anhand der folgenden Schritte durch:
Verwenden Sie den SSH-Befehl, um Verbindungen mit den einzelnen Knoten herzustellen.
Überprüfen Sie die Datenträgerauslastung, indem Sie einen der folgenden Befehle ausführen:
df -h du -h --max-depth=1 / | sort -hÜberprüfen Sie anhand der Ausgabe, ob im Ordner
mntoder in anderen Ordnern große Dateien vorhanden sind. Die Ordnerusercacheundappcache(„mnt/resource/hadoop/yarn/local/usercache/hive/appcache/“) enthalten in der Regel große Dateien.Sollten große Dateien vorhanden sein, wurde die Dateivergrößerung entweder durch einen aktuellen Auftrag verursacht, oder ein fehlerhafter vorheriger Auftrag hat zu diesem Problem beigetragen. Überprüfen Sie mithilfe des folgenden Befehls, ob dieses Verhalten durch einen aktuellen Auftrag verursacht wird:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Sollte von diesem Befehl ein bestimmter Auftrag angegeben werden, können Sie diesen mithilfe eines Befehls wie dem folgenden beenden:
yarn application -kill -applicationId <application_id>Ersetzen Sie
application_iddurch die Anwendungs-ID. Sollten keine bestimmten Aufträge angegeben werden, fahren Sie mit dem nächsten Schritt fort.Falls durch den oben genannten Befehl keine spezifischen Aufträge angegeben wurden, löschen Sie die gefundenen großen Dateien mithilfe eines Befehls wie dem folgenden:
rm -rf filecache usercache
Weitere Informationen zu Speicherplatzproblemen finden Sie unter Nicht genügend Speicherplatz.
Hinweis
Wenn Sie über große Dateien verfügen, die zu dem Speicherplatzproblem beitragen, aber erhalten bleiben sollen, müssen Sie Ihren HDInsight-Cluster zentral hochskalieren und die Dienste neu starten. Warten Sie nach Abschluss dieser Prozedur einige Minuten. Danach steht wieder freier Speicherplatz zur Verfügung, und der Knoten funktioniert wie gewohnt.
Nächste Schritte
Weitere Informationen zur Problembehandlung und Überwachung für Ihre Cluster finden Sie unter den folgenden Links: