Verwenden von Apache Zeppelin Notebooks mit Apache Spark-Cluster in Azure HDInsight
HDInsight Spark-Cluster enthalten Apache Zeppelin Notebooks. Verwenden Sie die Notebooks, um Apache Spark-Aufträge auszuführen. In diesem Artikel wird beschrieben, wie Sie das Zeppelin Notebook in einem HDInsight-Cluster verwenden.
Voraussetzungen
- Ein Apache Spark-Cluster unter HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight.
- Das URI-Schema für Ihren primären Clusterspeicher. Dieses Schema ist
wasb://für Azure Blob Storage,abfs://für Azure Data Lake Storage Gen2 oderadl://für Azure Data Lake Storage Gen1. Wenn die sichere Übertragung für Blob Storage aktiviert ist, lautet der URIwasbs://. Weitere Informationen finden Sie unter Vorschreiben einer sicheren Übertragung in Azure Storage.
Starten des Apache Zeppelin Notebooks
Wählen Sie im Spark-Cluster Übersicht unter Clusterdashboards die Option Zeppelin-Notebook. Geben Sie die Administratoranmeldeinformationen für den Cluster ein.
Hinweis
Sie können auch das Zeppelin Notebook für Ihren Cluster aufrufen, indem Sie in Ihrem Browser die folgende URL öffnen. Ersetzen Sie CLUSTERNAME durch den Namen Ihres Clusters:
https://CLUSTERNAME.azurehdinsight.net/zeppelinErstellen Sie ein neues Notebook. Navigieren Sie im Headerbereich zu Notebook>Neue Notiz erstellen.
Geben Sie einen Namen für das Notebook ein, und wählen Sie anschließend Notiz erstellen.
Stellen Sie sicher, dass im Header des Notebooks der Status „Verbunden“ angezeigt wird. Dies wird durch einen grünen Punkt in der oberen rechten Ecke angezeigt.
Laden Sie Beispieldaten in eine temporäre Tabelle. Wenn Sie einen Spark-Cluster in HDInsight erstellen, wird die Beispieldatei
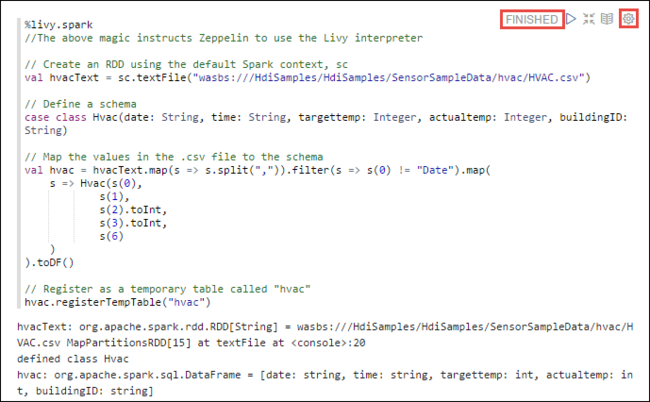
hvac.csvin das zugeordnete Speicherkonto unter\HdiSamples\SensorSampleData\hvackopiert.Fügen Sie in den leeren Absatz, der im neuen Notebook standardmäßig erstellt wird, den folgenden Codeausschnitt ein.
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Drücken Sie UMSCHALT+EINGABETASTE, oder wählen Sie die Schaltfläche Wiedergeben für den Absatz aus, um den Codeausschnitt auszuführen. Der Status in der rechten Ecke des Absatzes sollte sich entsprechend ändern: BEREIT, AUSSTEHEND, WIRD AUSGEFÜHRT bis zu BEENDET. Die Ausgabe wird unten im Absatz angezeigt. Der Screenshot sieht wie folgt aus:
Sie können auch einen Titel für jeden Absatz angeben. Wählen Sie in der rechten Ecke des Absatzes das Symbol Einstellungen (Zahnrad) und dann Titel anzeigen.
Hinweis
Der %spark2-Interpreter wird in Zeppelin-Notebooks bei keiner HDInsight-Version unterstützt, und der %sh-Interpreter wird ab HDInsight 4.0 nicht unterstützt.
Sie können jetzt Spark SQL-Anweisungen für die Tabelle
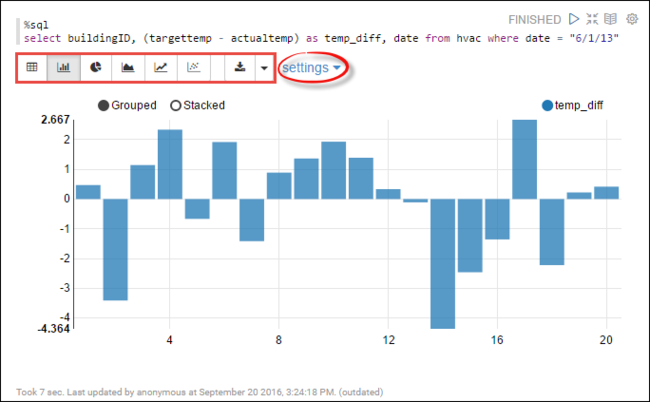
hvacausführen. Fügen Sie die folgende Abfrage in einen neuen Absatz ein. Die Abfrage ruft die Gebäude-ID ab. Außerdem wird der Unterschied zwischen den Ziel- und Ist-Temperaturen für jedes Gebäude an einem bestimmten Datum abgerufen. Drücken Sie UMSCHALT+EINGABETASTE.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"Mit der %sql-Anweisung am Anfang wird das Notebook angewiesen, den Livy Scala-Interpreter zu verwenden.
Wählen Sie das Symbol Balkendiagramm aus, um die Anzeige zu ändern. Unter der Option Einstellungen, die nach dem Auswählen von Balkendiagramm angezeigt wird, können Sie Schlüssel und Werte auswählen. Im folgenden Screenshot ist die Ausgabe dargestellt.
Sie können auch Spark-SQL-Anweisungen ausführen, indem Sie die Variablen in der Abfrage verwenden. Der nächste Codeausschnitt zeigt, wie Sie eine Variable (
Temp) in der Abfrage mit den möglichen Werten definieren, die für die Abfrage verwendet werden sollen. Beim ersten Ausführen der Abfrage wird automatisch eine Dropdownliste mit den Werten aufgefüllt, die Sie für die Variable angegeben haben.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Fügen Sie diesen Codeausschnitt in einen neuen Absatz ein, und drücken Sie UMSCHALT+EINGABETASTE. Wählen Sie anschließend in der Dropdownliste Temp den Wert 65 aus.
Wählen Sie das Symbol Balkendiagramm aus, um die Anzeige zu ändern. Wählen Sie anschließend Einstellungen, und nehmen Sie die folgenden Änderungen vor:
Gruppen: Fügen Sietargettemp hinzu.
Werte: 1. Entfernen Sie date. 2. Fügen Sie temp_diff hinzu. 3. Ändern Sie den Aggregator von SUM in AVG.
Im folgenden Screenshot ist die Ausgabe dargestellt.

Wie verwende ich externe Pakete mit dem Notebook?
Ein Zeppelin Notebook in einem Apache Spark-Cluster in HDInsight kann externe, von der Community bereitgestellte Pakete verwenden, die nicht im Lieferumfang des Clusters enthalten sind. Durchsuchen Sie das Maven Repository nach einer vollständigen Liste der verfügbaren Pakete. Sie können die Liste der verfügbaren Pakete auch aus anderen Quellen abrufen. Beispielsweise steht eine vollständige Liste der von der Community bereitgestellten Pakete auf Spark-Paketezur Verfügung.
In diesem Artikel erfahren Sie, wie Sie das Paket spark-csv mit Jupyter Notebook verwenden.
Öffnen Sie die Einstellungen des Interpreters. Wählen Sie in der Ecke oben rechts den Namen des angemeldeten Benutzers und dann Interpreter aus.
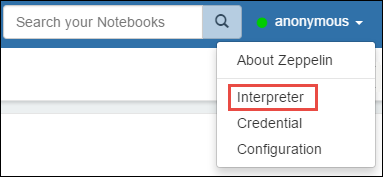
Scrollen Sie zu livy2, und wählen Sie dann edit aus.
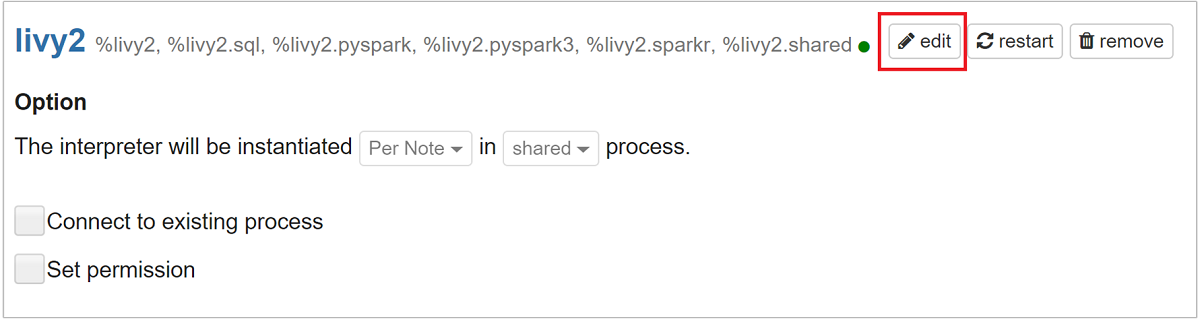
Navigieren Sie zum Schlüssel
livy.spark.jars.packages, und legen Sie seinen Wert im Formatgroup:id:versionfest. Wenn Sie das Paket spark-csv verwenden möchten, müssen Sie den Wert des Schlüssels aufcom.databricks:spark-csv_2.10:1.4.0festlegen.
Wählen Sie Speichern und dann OK aus, um den Livy-Interpreter neu zu starten.
Hier ist angegeben, wie Sie zum Wert des oben eingegebenen Schlüssels gelangen, falls dies für Sie interessant ist.
a. Suchen Sie das Paket im Maven-Repository. In diesem Artikel verwendeten wir spark-csv.
b. Sammeln Sie im Repository die Werte für GroupId, ArtifactId und Version.
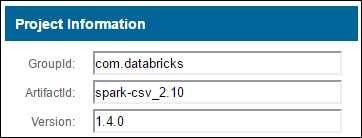
c. Verketten Sie die drei Werte, getrennt durch einen Doppelpunkt ( : ).
com.databricks:spark-csv_2.10:1.4.0
Wo werden Zeppelin Notebooks gespeichert?
Die Zeppelin Notebooks werden in den Clusterhauptknoten gespeichert. Wenn Sie den Cluster löschen, werden also auch die Notebooks gelöscht. Falls Sie Ihre Notebooks zur späteren Verwendung auf anderen Clustern beibehalten möchten, müssen Sie sie exportieren, nachdem Sie die Ausführung der Aufträge abgeschlossen haben. Wählen Sie zum Exportieren eines Notebooks das Symbol Exportieren. Dies ist in der Abbildung unten dargestellt.
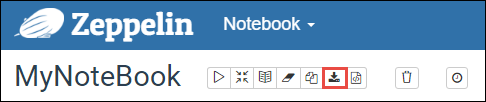
Durch diese Aktion wird das Notebook als JSON-Datei in Ihrem Downloadverzeichnis gespeichert.
Hinweis
In HDI 4.0 ist der Directory-Pfad des Zeppelin-Notebooks
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Beispiel: /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Während sich in HDI 5.0 und höher dieser Pfad unterscheidet
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Beispiel: /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
Der gespeicherte Dateiname unterscheidet sich in HDI 5.0. Er wird als
<notebook_name>_<sessionid>.zplngespeichertBeispiel: testzeppelin_2JJK53XQA.zpln
In HDI 4.0 lautet der Dateiname nur note.json und wird unter dem Verzeichnis session_id gespeichert.
Beispiel: /2JMC9BZ8X/note.json
HDI Zeppelin speichert das Notebook immer im Pfad
/usr/hdp/<version>/zeppelin/notebook/auf der lokalen Festplatte hn0.Wenn das Notebook auch nach dem Löschen des Clusters verfügbar sein soll, können Sie versuchen, Azure File Storage (mit dem SMB-Protokoll) zu verwenden und mit dem lokalen Pfad zu verknüpfen. Weitere Informationen finden Sie unter Einbinden einer Azure-SMB-Dateifreigabe unter Linux
Nach der Einbindung können Sie die Zeppelin-Konfiguration zeppelin.notebook.dir in den eingebundenen Pfad in der Ambari-Benutzeroberfläche ändern.
- Die SMB-Dateifreigabe als GitNotebookRepo-Speicher wird nicht für die Zeppelin-Version 0.10.1 empfohlen
Verwenden von Shiro zum Konfigurieren des Zugriffs auf Zeppelin-Interpreter in ESP-Clustern (Enterprise-Sicherheitspaket)
Wie bereits erwähnt, wird der %sh-Interpreter ab HDInsight 4.0 nicht unterstützt. Da der %sh-Interpreter potenzielle Sicherheitsprobleme bewirkt, z. B. Zugriff auf Keytabs mithilfe von Shellbefehlen, wurde er auch aus HDInsight 3.6 ESP-Clustern entfernt. Das bedeutet, dass der %sh-Interpreter beim Klicken auf Neue Notiz erstellen oder auf der Interpreter-Benutzeroberfläche standardmäßig nicht verfügbar ist.
Privilegierte Domänenbenutzer können mithilfe der Datei Shiro.ini den Zugriff auf die Interpreter-Benutzeroberfläche steuern. Nur diese Benutzer können neue %sh-Interpreter erstellen und für jeden neuen %sh-Interpreter Berechtigungen festlegen. Führen Sie die folgenden Schritte aus, um den Zugriff mithilfe der Datei shiro.ini zu steuern:
Definieren Sie eine neue Rolle mit dem Namen einer vorhandenen Domänengruppe. Im folgenden Beispiel ist
adminGroupNameeine Gruppe privilegierter Benutzer in AAD. Verwenden Sie keine Sonderzeichen oder Leerzeichen im Gruppennamen. Die Zeichen nach=geben die Berechtigungen für diese Rolle an.*bedeutet, dass die Gruppe über vollständige Berechtigungen verfügt.[roles] adminGroupName = *Fügen Sie die neue Rolle für den Zugriff auf Zeppelin-Interpreter hinzu. Im folgenden Beispiel erhalten alle Benutzer in
adminGroupNameZugriff auf Zeppelin-Interpreter und können neue Interpreter erstellen. Sie können mehrere Rollen, getrennt durch Kommas, in die eckigen Klammern vonroles[]einfügen. Benutzer, die über die erforderlichen Berechtigungen verfügen, können dann auf Zeppelin-Interpreter zugreifen.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Beispiel für „shiro.ini“ für mehrere Domänengruppen:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Livy-Sitzungsverwaltung
Bei Ausführung des ersten Codeabsatzes in Ihrem Zeppelin Notebook wird eine neue Livy-Sitzung in Ihrem Cluster erstellt. Diese Sitzung kann für alle später erstellten Zeppelin Notebooks gemeinsam verwendet werden. Wird die Livy-Sitzung aus irgendeinem Grund unterbrochen, werden keine Aufträge über das Zeppelin Notebook ausgeführt.
In diesem Fall müssen Sie die folgenden Schritte ausführen, bevor Sie mit dem Ausführen von Aufträgen über ein Zeppelin Notebook beginnen können.
Starten Sie den Livy-Interpreter über das Zeppelin Notebook neu. Öffnen Sie zu diesem Zweck die Einstellungen des Interpreters, indem Sie oben rechts den Namen des angemeldeten Benutzers und dann Interpreter auswählen.
Scrollen Sie zu livy2, und wählen Sie dann restart aus.
Führen Sie eine Codezelle über ein vorhandenes Zeppelin Notebook aus. Durch diesen Code wird im HDInsight-Cluster eine neue Livy-Sitzung erstellt.
Allgemeine Informationen
Überprüfen des Diensts
Zum Überprüfen des Diensts über Ambari navigieren Sie zu https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, wobei CLUSTERNAME der Name Ihres Clusters ist.
Zum Überprüfen des Diensts über eine Befehlszeile stellen Sie eine SSH-Verbindung zum Hauptknoten her. Ändern Sie mit dem Befehl sudo su zeppelin den Benutzer in Zeppelin. Statusbefehle:
| Get-Help | BESCHREIBUNG |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Dienststatus |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Dienstversion |
ps -aux | grep zeppelin |
Identifizieren der PID |
Protokollspeicherorte
| Dienst | `Path` |
|---|---|
| Zeppelin-Server | /usr/hdp/current/zeppelin-server/ |
| Serverprotokolle | /var/log/zeppelin |
Configuration Interpreter, Shiro, site.xml, log4j |
/usr/hdp/current/zeppelin-server/conf or /etc/zeppelin/conf |
| PID-Verzeichnis | /var/run/zeppelin |
Debugprotokollierung aktivieren
Navigieren Sie zu
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, wobei CLUSTERNAME der Name Ihres Clusters ist.Navigieren Sie zu CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content.
Ändern Sie
log4j.appender.dailyfile.Threshold = INFOinlog4j.appender.dailyfile.Threshold = DEBUG.Fügen Sie
log4j.logger.org.apache.zeppelin.realm=DEBUGhinzu.Speichern Sie die Änderungen, und starten Sie den Dienst neu.