C#-Lernprogramm: Verwenden von Skillsets zum Generieren durchsuchbarer Inhalte in Azure AI Search
In diesem Lernprogramm erfahren Sie, wie Sie mithilfe des Azure SDK für .NET eine KI-Anreicherungspipeline für inhaltsextraktion und Transformationen während der Indizierung erstellen.
Skillsets fügen KI-Verarbeitung zu Rohinhalten hinzu, wodurch diese Inhalte einheitlicher und durchsuchbarer werden. Sobald Sie wissen, wie Skillsets funktionieren, können Sie eine breite Palette von Transformationen unterstützen: von der Bildanalyse bis hin zur Verarbeitung natürlicher Sprachen bis hin zur angepassten Verarbeitung, die Sie extern bereitstellen.
In diesem Tutorial erfahren Sie Folgendes:
- Definieren von Objekten in einer Anreicherungspipeline
- Erstellen eines Skillsets Aufrufen von OCR, Spracherkennung, Entitätserkennung und Schlüsselbegriffserkennung
- Ausführen der Pipeline Erstellen und Laden eines Suchindex
- Überprüfen der Ergebnisse mithilfe der Volltextsuche
Sollten Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Übersicht
In diesem Tutorial werden C# und die Clientbibliothek Azure.Search.Documents verwendet, um eine Datenquelle, einen Index, einen Indexer und ein Skillset zu erstellen.
Der Indexer steuert jeden Schritt in der Pipeline, beginnend mit der Inhaltsextraktion von Beispieldaten (unstrukturiertem Text und Bildern) in einem BLOB-Container in Azure Storage.
Sobald Inhalte extrahiert wurden, führt das Skillset integrierte Fähigkeiten von Microsoft aus, um Informationen zu finden und zu extrahieren. Die Schritte in der Pipeline umfassen die optische Zeichenerkennung (OCR) für Bilder, die Spracherkennung für Text sowie die Schlüsselwortextraktion und die Entitätserkennung (Organisationen). Neue Informationen, die vom Skillset erstellt wurden, werden an Felder in einem Indexgesendet. Nachdem der Index aufgefüllt wurde, können die Felder in Abfragen, Facetten und Filtern verwendet werden.
Voraussetzungen
Hinweis
Sie können einen kostenlosen Suchdienst für dieses Tutorial verwenden. Der Free-Tarif ist auf drei Indizes, drei Indexer und drei Datenquellen beschränkt. In diesem Tutorial wird davon jeweils eine Instanz erstellt. Vergewissern Sie sich zunächst, dass Ihr Dienst über genügend freie Kapazität für die neuen Ressourcen verfügt.
Herunterladen von Dateien
Laden Sie eine ZIP-Datei des Beispielrepositorys herunter, und extrahieren Sie den Inhalt. Weitere Informationen.
Hochladen von Beispieldaten in Azure Storage
Erstellen Sie in Azure Storage einen neuen Container, und nennen Sie ihn kog-search-demo.
Rufen Sie eine Speicherverbindungszeichenfolge ab, damit Sie eine Verbindung in Azure AI Search formulieren können.
Wählen Sie auf der linken Seite Zugriffsrichtlinien aus.
Kopieren Sie die Verbindungszeichenfolge für schlüssel 1 oder zwei Schlüssel. Die Verbindungszeichenfolge ist eine URL, die in etwa wie folgt aussieht:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure KI Services
Die integrierte KI-Anreicherung nutzt Azure KI Services, darunter den Sprachdienst und Azure KI Vision für die linguistische Datenverarbeitung und die Verarbeitung von Bildern. Für kleine Workloads wie dieses Lernprogramm können Sie die kostenlose Zuordnung von 20 Transaktionen pro Indexer verwenden. Fügen Sie für größere Arbeitslasten eine Azure AI Services-Ressource mit mehreren Regionen an ein Skillset für Die Preise für Pay-as-you-go an.
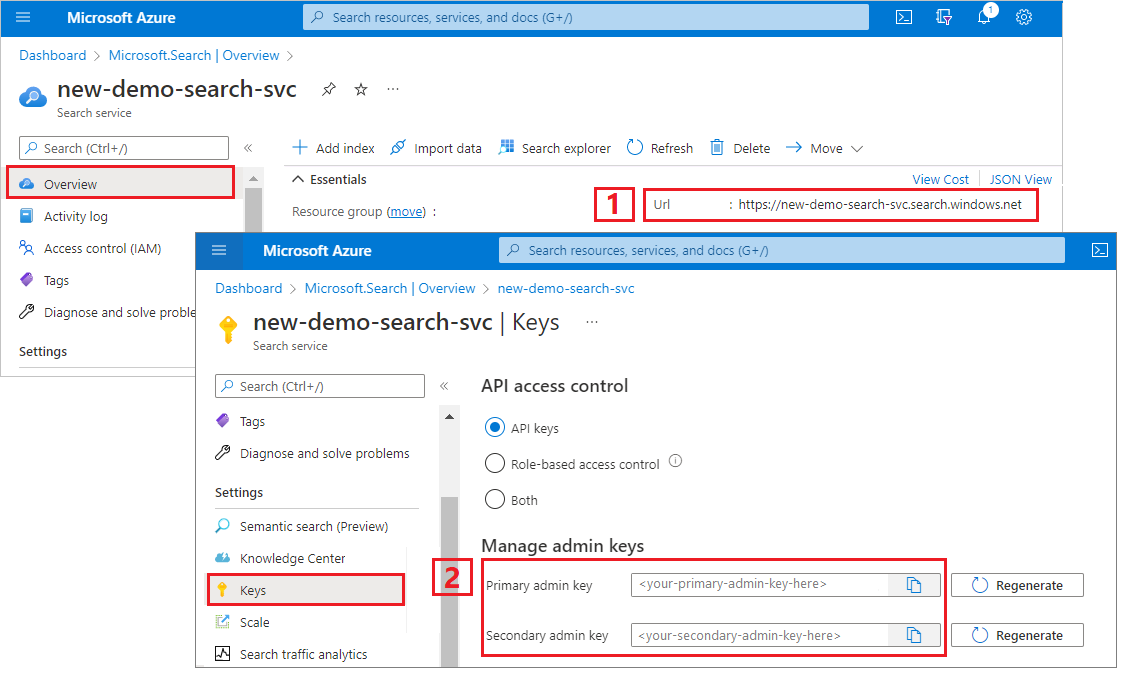
Kopieren von Suchdienst-URL und API-Schlüssel
Für dieses Lernprogramm benötigen Verbindungen mit Azure AI Search einen Endpunkt und einen API-Schlüssel. Diese Werte erhalten Sie im Azure-Portal.
Melden Sie sich beim Azure-Portalan, navigieren Sie zur Seite Übersicht des Suchdiensts, und kopieren Sie die URL. Ein Beispiel für einen Endpunkt ist
https://mydemo.search.windows.net.Kopieren Sie unter Einstellungen>Schlüssel einen Administratorschlüssel. Mit einem Administratorschlüssel können Sie Objekte hinzufügen, ändern und löschen. Es gibt zwei austauschbare Administratorschlüssel. Kopieren Sie einen der beiden Schlüssel.
Erstellen Ihrer Umgebung
Öffnen Sie zunächst Visual Studio, und erstellen Sie ein neues Konsolen-App-Projekt, das mit .NET Core ausgeführt werden kann.
Installieren von Azure.Search.Documents
Das Azure AI Search .NET SDK besteht aus einer Client-Bibliothek, die es Ihnen ermöglicht, Ihre Indizes, Datenquellen, Indexer und Skillsets zu verwalten sowie Dokumente hochzuladen und zu verwalten und Abfragen auszuführen, ohne sich mit den Details von HTTP und JSON beschäftigen zu müssen. Diese Clientbibliothek wird als NuGet-Paket bereitgestellt.
Installieren Sie für dieses Projekt Version 11 oder höher von Azure.Search.Documents sowie die neueste Version von Microsoft.Extensions.Configuration.
Klicken Sie in Visual Studio auf Extras>NuGet-Paket-Manager>NuGet-Pakete für Projektmappe verwalten....
Suchen Sie nach Azure.Search.Document.
Wählen Sie die neueste Version und dann die Option Installieren aus.
Wiederholen Sie die vorherigen Schritte, um Microsoft.Extensions.Configuration und Microsoft.Extensions.Configuration.Json zu installieren.
Hinzufügen von Informationen zur Dienstverbindung
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf Ihr Projekt, und wählen Sie Hinzufügen>Neues Element aus.
Geben Sie der Datei den Namen
appsettings.json, und wählen Sie Hinzufügen aus.Fügen Sie diese Datei in Ihr Ausgabeverzeichnis ein.
- Klicken Sie mit der rechten Maustaste auf
appsettings.json, und wählen Sie Eigenschaften aus. - Ändern Sie den Wert von In Ausgabeverzeichnis kopieren in Kopieren, wenn neuer.
- Klicken Sie mit der rechten Maustaste auf
Kopieren Sie den folgenden JSON-Code in die neue JSON-Datei.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Fügen Sie Ihren Suchdienst und die Informationen Ihres Blob Storage-Kontos hinzu. Denken Sie daran, dass Sie diese Informationen über die Schritte zur Dienstbereitstellung im vorherigen Abschnitt erhalten können.
Geben Sie für SearchServiceUri die vollständige URL ein.
Hinzufügen von Namespaces
Fügen Sie in Program.cs die folgenden Namespaces hinzu.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Erstellen eines Clients
Erstellen Sie unter Main eine Instanz der SearchIndexClient- und der SearchIndexerClient-Klasse.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Hinweis
Die Clients stellen eine Verbindung mit Ihrem Suchdienst her. Sie sollten nach Möglichkeit nur eine Instanz in Ihrer Anwendung freigeben, um zu vermeiden, dass zu viele Verbindungen geöffnet werden. Die Methoden sind threadsicher und ermöglichen diese Freigabe.
Hinzufügen einer Funktion zum Beenden des Programms während eines Fehlers
Dieses Tutorial soll die einzelnen Schritte der Indizierungspipeline veranschaulichen. Bei einem kritischen Problem, das verhindert, dass das Programm die Datenquelle, das Skillset, den Index oder den Indexer erstellt, wird eine Fehlermeldung ausgegeben und das Programm beendet, sodass der Fehler ermittelt und behoben werden kann.
Fügen Sie ExitProgram zu Main hinzu, um Szenarien zu behandeln, in denen das Programm beendet werden muss.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Erstellen der Pipeline
In Azure AI Search erfolgt die KI-Verarbeitung während der Indizierung (oder Datenaufnahme). In diesem Teil der exemplarischen Vorgehensweise werden vier Objekte erstellt: Datenquelle, Indexdefinition, Skillset und Indexer.
Schritt 1: Erstellen einer Datenquelle
SearchIndexerClient verfügt über eine DataSourceName-Eigenschaft, die Sie auf ein SearchIndexerDataSourceConnection-Objekt festlegen können. Dieses Objekt bietet alle Methoden, die Sie zum Erstellen, Auflisten, Aktualisieren oder Löschen von Azure AI Search-Datenquellen benötigen.
Erstellen Sie eine neue SearchIndexerDataSourceConnection-Instanz, indem Sie indexerClient.CreateOrUpdateDataSourceConnection(dataSource) aufrufen. Der folgende Code erstellt eine Datenquelle vom Typ AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
Bei einer erfolgreichen Anforderung gibt die Methode die Datenquelle zurück, die erstellt wurde. Wenn ein Problem mit der Anforderung auftritt, z. B. ein ungültiger Parameter vorhanden ist, löst die Methode eine Ausnahme aus.
Fügen Sie nun unter Main eine Zeile zum Aufrufen der Funktion CreateOrUpdateDataSource hinzu, die Sie gerade hinzugefügt haben.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Erstellen Sie das Projekt, und führen Sie es aus. Da dies Ihre erste Anfrage ist, überprüfen Sie im Azure-Portal, ob die Datenquelle in Azure AI Search erstellt wurde. Überprüfen Sie auf der Übersichtsseite des Suchdiensts, ob die Liste „Datenquellen“ ein neues Element enthält. Möglicherweise müssen Sie einige Minuten warten, bis die Portalseite aktualisiert wurde.

Schritt 2: Erstellen eines Skillsets
In diesem Abschnitt definieren Sie eine Reihe von Anreicherungsschritten, die Sie auf Ihre Daten anwenden möchten. Jeder Anreicherungsschritt wird als Skill und die Anreicherungsschritte zusammen als Skillset bezeichnet. Dieses Tutorial verwendet eingebaute Fertigkeiten für das Skillset:
Mit der Qualifikation für die optische Zeichenerkennung (OCR) wird gedruckter und handschriftlicher Text in Bilddateien erkannt.
Mit der Textzusammenführung wird Text aus einer Sammlung von Feldern in einem einzigen Feld „zusammengeführter Inhalt“ konsolidiert.
Spracherkennung, um die Sprache der Inhalte zu bestimmen.
Entitätserkennung, um die Namen von Organisationen aus Inhalten im Blobcontainer zu extrahieren.
Mit der Textaufteilung werden große Inhalte vor dem Aufrufen der Qualifikationen zur Schlüsselbegriffserkennung und Entitätserkennung in kleinere Teile aufgeteilt. Für die Schlüsselbegriffserkennung und Entitätserkennung werden Eingaben von maximal 50.000 Zeichen akzeptiert. Für einige der Beispieldateien ist eine Aufteilung erforderlich, um diesen Grenzwert zu erfüllen.
Schlüsselbegriffserkennung, um die wichtigsten Schlüsselbegriffe herauszuziehen.
Bei der Erstverarbeitung entschlüsselt Azure AI Search jedes Dokument, um Inhalte aus verschiedenen Dateiformaten zu extrahieren. Aus der Quelldatei stammender Text wird für jedes Dokument jeweils im generierten Feld content gespeichert. Legen Sie daher die Eingabe auf "/document/content" fest, um diesen Text zu verwenden. Bildinhalte werden in einem generierten normalized_images-Feld platziert, das in einem Skillset als /document/normalized_images/* angegeben wird.
Ausgaben können einem Index zugeordnet, als Eingabe einer Downstream-Qualifikation verwendet oder in beider Weise zugleich eingesetzt werden, wie etwa bei Sprachcode. Im Index ist ein Sprachcode zu Filterungszwecken nützlich. Als Eingabe wird ein Sprachcode von Qualifikationen zur Textanalyse verwendet, um die Linguistikregeln über Wörtertrennung zu informieren.
Weitere Informationen zu den Grundlagen von Qualifikationsgruppen finden Sie unter How to define a skillset (Definieren von Qualifikationsgruppen).
OCR-Qualifikation
OcrSkill extrahiert Text aus Bildern. Bei dieser Qualifikation wird davon ausgegangen, dass ein Feld „normalized_images“ vorhanden ist. Um dieses Feld zu generieren, legen Sie später in diesem Tutorial die "imageAction"-Konfiguration in der Indexerdefinition auf "generateNormalizedImages" fest.
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Qualifikation: Zusammenführung
In diesem Abschnitt erstellen Sie ein MergeSkill-Element, mit dem das Feld mit dem Dokumentinhalt mit dem vom OCR-Skill erstellten Text zusammengeführt wird.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Qualifikation „Sprachenerkennung“
LanguageDetectionSkill erkennt die Sprache von Eingabetexten und meldet einen einzigen Sprachcode für jedes Dokument, das mit der Anforderung übermittelt wurde. Wir verwenden die Ausgabe der Qualifikation Sprachenerkennung als Teil der Eingabe für die Qualifikation Textaufteilung.
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Qualifikation „Textaufteilung“
Das folgende SplitSkill-Element teilt Text nach Seiten und beschränkt die Seitenlänge auf 4.000 Zeichen, die mit String.Length gemessen werden. Der Algorithmus versucht, den Text in Blöcke aufzuteilen, die höchstens maximumPageLength groß sind. Dabei versucht der Algorithmus, Sätze an Satzgrenzen zu teilen, sodass die Größe der Blöcke etwas kleiner als maximumPageLength sein kann.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Qualifikation „Entitätserkennung“
Diese EntityRecognitionSkill-Instanz ist auf den Erkennungskategorietyp organization festgelegt. EntityRecognitionSkill kann auch die Kategorietypen person und location erkennen.
Beachten Sie, dass das Feld „context“ mit einem Sternchen auf "/document/pages/*" festgelegt ist, d. h. der Anreicherungsschritt wird für jede Seite unter "/document/pages" aufgerufen.
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Qualifikation „Schlüsselbegriffserkennung“
Wie die EntityRecognitionSkill-Instanz, die gerade erstellt wurde, wird auch KeyPhraseExtractionSkill für jede Seite des Dokuments aufgerufen.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Aufbauen und Erstellen der Qualifikationsgruppe
Erstellen Sie die SearchIndexerSkillset mithilfe der Qualifikationen, die Sie erstellt haben.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Fügen Sie Main die folgenden Zeilen hinzu.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Schritt 3: Erstellen eines Index
In diesem Abschnitt definieren Sie das Indexschema, indem Sie angeben, welche Felder in den durchsuchbaren Index aufgenommen und mit welchen Suchattributen die einzelnen Felder versehen werden sollen. Felder besitzen einen Typ und können Attribute annehmen, die bestimmen, wie das Feld verwendet wird (durchsuchbar, sortierbar usw.). Feldname in einem Index müssen nicht exakt mit den Feldnamen in der Quelle übereinstimmen. In einem späteren Schritt fügen Sie in einem Indexer Feldzuordnungen hinzu, um die Quell- und Zielfelder zu verbinden. Definieren Sie für diesen Schritt den Index mit Feldbenennungskonventionen, die für Ihre Suchanwendung angemessen sind.
In dieser Übung werden die folgenden Felder und Feldtypen verwendet:
| Feldnamen | Feldtypen |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
Liste<Edm.String> |
organizations |
Liste<Edm.String> |
Erstellen der DemoIndex-Klasse
Die Felder für diesen Index werden mithilfe einer Modellklasse definiert. Jede Eigenschaft der Modellklasse verfügt über Attribute, die das suchbezogene Verhalten des entsprechenden Indexfelds bestimmen.
Wir fügen die Modellklasse einer neuen C#-Datei hinzu. Klicken Sie mit der rechten Maustaste auf Ihr Projekt, und wählen Sie Hinzufügen>Neues Element und dann „Klasse“ aus. Geben Sie der Datei den Namen DemoIndex.cs, und wählen Sie dann Hinzufügen aus.
Geben Sie unbedingt auch an, dass Sie die Typen aus den Namespaces Azure.Search.Documents.Indexes und System.Text.Json.Serialization verwenden möchten.
Fügen Sie DemoIndex.cs die folgende Modellklassendefinition hinzu, und fügen Sie sie in denselben Namespace ein, in dem Sie den Index erstellen.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Nach dem Definieren einer Modellklasse können Sie nun in Program.cs ganz problemlos eine Indexdefinition erstellen. Der Name für diesen Index lautet demoindex. Falls bereits ein Index mit diesem Namen vorhanden ist, wird er gelöscht.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Während der Tests stellen Sie möglicherweise fest, dass Sie mehr als einmal versuchen, den Index zu erstellen. Aus diesem Grund sollten Sie vor dem Versuch, den Index zu erstellen, überprüfen, ob er nicht bereits vorhanden ist.
Fügen Sie Main die folgenden Zeilen hinzu.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Fügen Sie die folgende using-Anweisung hinzu, um den mehrdeutigen Verweis zu korrigieren.
using Index = Azure.Search.Documents.Indexes.Models;
Weitere Informationen zu Indexkonzepten finden Sie unter Erstellen eines Index (REST-API).
Schritt 4: Erstellen und Ausführen eines Indexers
Bisher haben Sie eine Datenquelle, eine Qualifikationsgruppe und einen Index erstellt. Diese drei Komponenten werden Teil eines Indexers, der jedes einzelne Stück per Pull in einen einzelnen mehrstufigen Vorgang herunterlädt. Um diese in einem Indexer zusammenzuführen, müssen Sie Feldzuordnungen definieren.
fieldMappings werden vor der Qualifikationsgruppe verarbeitet, und die Quellfelder der Datenquelle werden Zielfeldern in einem Index zugeordnet. Wenn die Feldnamen und -typen auf beiden Seiten gleich sind, ist keine Zuordnung erforderlich.
outputFieldMappings werden nach der Qualifikationsgruppe verarbeitet. Es wird auf nicht vorhandene sourceFieldNames verwiesen, bis diese per Dokumententschlüsselung oder Anreicherung erstellt werden. targetFieldName ist ein Feld in einem Index.
Neben dem Verknüpfen von Ein- und Ausgaben können Sie auch Feldzuordnungen nutzen, um Datenstrukturen zu vereinfachen. Weitere Informationen finden Sie unter Zuordnen angereicherter Felder zu einem durchsuchbaren Index.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Fügen Sie Main die folgenden Zeilen hinzu.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Die Indexerverarbeitung nimmt erwartungsgemäß einige Zeit in Anspruch. Das Dataset ist zwar klein, Analysequalifikationen sind aber rechenintensiv. Einige Qualifikationen, wie etwa die Bildanalyse, weisen lange Ausführungszeiten auf.
Tipp
Die Pipeline wird durch Erstellen eines Indexers aufgerufen. Wenn beim Zugriff auf die Daten, dem Zuordnen von Ein- und Ausgaben oder der Reihenfolge der Vorgänge Probleme bestehen, äußern sie sich in dieser Phase.
Untersuchen der Indexererstellung
Der Code legt "maxFailedItems" auf -1 fest, womit die Index-Engine angewiesen wird, Fehler beim Datenimport zu ignorieren. Dies ist nützlich, weil die Demodatenquelle nur wenige Dokumente enthält. Für eine größere Datenquelle sollten Sie den Wert größer als 0 festlegen.
Beachten Sie auch, dass "dataToExtract" auf "contentAndMetadata" festgelegt ist. Diese Anweisung weist den Indexer an, die Inhalte aus verschiedenen Dateiformaten sowie die den einzelnen Dateien zugeordneten Metadaten automatisch zu extrahieren.
Wenn die Inhalte extrahiert werden, können Sie imageAction darauf festlegen, Text aus in der Datenquelle gefundenen Bildern zu extrahieren. Die Festlegung von "imageAction" auf die Konfiguration "generateNormalizedImages" in Kombination mit den Qualifikationen OCR und Textzusammenführung weist den Indexer an, Text aus den Bildern zu extrahieren (beispielsweise das Wort „Stop“ aus einem Stoppschild) und ihn als Teil des Inhaltsfelds einzubetten. Dieses Verhalten betrifft sowohl die in den Dokumenten eingebetteten Bilder (denken Sie etwa an Bilder in PDF-Dateien) als auch die in der Datenquelle gefundenen Bilder, z.B. eine JPG-Datei.
Überwachen der Indizierung
Nachdem der Indexer definiert wurde, wird er automatisch ausgeführt, wenn Sie die Anforderung senden. Je nachdem, welche Fähigkeiten Sie definiert haben, kann die Indizierung länger dauern, als Sie erwarten. Um herauszufinden, ob der Indexer noch ausgeführt wird, verwenden Sie die GetStatus-Methode.
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo stellt den aktuellen Status und den Ausführungsverlauf eines Indexers dar.
Warnungen sind bei bestimmten Kombinationen aus Quelldatei und Skill häufig und weisen nicht immer auf ein Problem hin. Im Rahmen dieses Tutorials sind die Warnungen gutartig (z.B. keine Texteingaben aus den JPEG-Dateien).
Fügen Sie Main die folgenden Zeilen hinzu.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Suche
In den Konsolen-Apps des Azure AI Search-Tutorials fügen wir normalerweise eine Verzögerung von 2 Sekunden hinzu, bevor wir Abfragen ausführen, die Ergebnisse liefern. Da die Anreicherung jedoch mehrere Minuten dauert, schließen wir die Konsolen-App und verwenden stattdessen einen anderen Ansatz.
Die einfachste Option ist der Such-Explorer im Portal. Sie können zuerst eine leere Abfrage, die alle Dokumente zurückgibt, oder eine gezieltere Suche durchführen, die neuen, von der Pipeline erstellten Feldinhalt zurückgibt.
Klicken Sie im Azure-Portal auf der Übersichtsseite für die Suche auf Indizes.
Suchen Sie in der Liste nach
demoindex. Diese sollte 14 Dokumente enthalten. Wenn die Anzahl der Dokumente 0 (null) ist, wird der Indexer entweder noch ausgeführt, oder die Seite wurde noch nicht aktualisiert.Wählen Sie
demoindexaus. Der Such-Explorer ist die erste Registerkarte.Der Inhalt kann durchsucht werden, sobald das erste Dokument geladen wurde. Führen Sie eine Abfrage ohne Angabe durch, indem Sie auf Suchen klicken, um zu überprüfen, ob Inhalt vorhanden ist. Diese Abfrage gibt alle derzeit indizierten Dokumente zurück und gibt Ihnen so eine Vorstellung davon, was der Index enthält.
Geben Sie als Nächstes die folgende Zeichenfolge ein, um bessere Ergebnisse zu erzielen:
search=*&$select=id, languageCode, organizations.
Zurücksetzen und erneut ausführen
In den frühen experimentellen Phasen der Entwicklung ist es am praktischsten, die Objekt aus Azure KI-Suche zu löschen und sie durch Ihren Code neu zu erstellen. Ressourcennamen sind eindeutig. Wenn Sie ein Objekt löschen, können Sie es unter dem gleichen Namen neu erstellen.
Im Beispielcode dieses Tutorials wird eine Überprüfung auf vorhandene Objekte durchgeführt. Diese werden dann gelöscht, damit Sie Ihren Code erneut ausführen können. Sie können auch das Portal verwenden, um Indizes, Indexer, Datenquellen und Qualifikationsgruppen zu löschen.
Wesentliche Punkte
Dieses Tutorial veranschaulicht die grundlegenden Schritte zum Erstellen einer erweiterten Indizierungspipeline durch Erstellung von Komponenten: eine Datenquelle, eine Qualifikationsgruppe, ein Index und ein Indexer.
Es wurden integrierte Qualifikationen im Zusammenhang mit der Skillsetdefinition und den Mechanismen zur Verkettung von Qualifikationen mithilfe von Ein- und Ausgängen vorgestellt. Sie haben auch gelernt, dass outputFieldMappings in der Indexer-Definition erforderlich ist, um angereicherte Werte aus der Pipeline in einen durchsuchbaren Index auf einem Azure AI Search-Dienst zu leiten.
Ferner haben Sie erfahren, wie die Ergebnisse getestet werden und das System für weitere Entwicklungsschritte zurückgesetzt wird. Sie haben gelernt, dass das Ausgeben von Abfragen auf den Index die von der angereicherten Indizierungspipeline erstellte Ausgabe zurückgibt. Darüber hinaus haben Sie die Überprüfung des Indexerstatus und das Löschen von Objekten vor der erneuten Ausführung einer Pipeline gelernt.
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, ist es ratsam, nach Abschluss eines Projekts die nicht mehr benötigten Ressourcen zu entfernen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können entweder einzelne Ressourcen oder aber die Ressourcengruppe löschen, um den gesamten Ressourcensatz zu entfernen.
Ressourcen können im Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich gesucht und verwaltet werden.
Nächste Schritte
Nachdem Sie sich nun mit allen Objekten einer KI-Anreicherungspipeline vertraut gemacht haben, können Sie sich weiter über Skillsetdefinitionen und einzelne Qualifikationen informieren.