Power Query-Connectors (Vorschau – eingestellt)
Wichtig
Die Unterstützung für Power Query-Connectors wurde als Public Preview unter Zusätzliche Nutzungsbedingungen für Microsoft Azure-Vorschauen eingeführt, wird aber jetzt eingestellt. Wenn Sie über eine Suchlösung verfügen, die einen Power Query-Connector verwendet, migrieren Sie bitte zu einer alternativen Lösung.
Migrieren bis zum 28. November 2022
Die Vorschauversion der Power Query-Connectors wurde im Mai 2021 angekündigt und wird nicht allgemein verfügbar gemacht. Im Folgenden finden Sie einen Migrationsleitfaden für Snowflake und PostgreSQL. Falls Sie einen anderen Connector verwenden und eine Anleitung zur Migration benötigen, fordern Sie über die E-Mail-Kontaktinformationen in Ihrer Registrierung für die Vorschauversion Hilfe an, oder öffnen Sie ein Supportticket beim Azure-Support.
Voraussetzungen
- Azure Storage-Konto Erstellen Sie ein Speicherkonto, falls Sie noch keines besitzen.
- Azure Data Factory-Instanz. Erstellen Sie eine Data Factory-Instanz, falls Sie noch keine haben. Informieren Sie sich vor der Implementierung auf der Seite Data Factory-Pipelines – Preise über die damit verbundenen Kosten. Lesen Sie auch Grundlegendes zu Azure Data Factory-Preisen anhand von Beispielen.
Migrieren einer Snowflake-Datenpipeline
In diesem Abschnitt wird erläutert, wie Sie Daten aus einer Snowflake-Datenbank in einen Azure Cognitive Search-Index kopieren. Es ist kein Prozess für die direkte Indizierung aus Snowflake in Azure Cognitive Search verfügbar. Dieser Abschnitt enthält daher eine Stagingphase, in der Datenbankinhalte in einen Azure Storage-Blobcontainer kopiert werden. Anschließend indizieren Sie die Daten aus diesem Stagingcontainer mithilfe einer Data Factory-Pipeline.
Schritt 1: Abrufen der Snowflake-Datenbankinformationen
Wechseln Sie zu Snowflake, und melden Sie sich bei Ihrem Snowflake-Konto an. Ein Snowflake-Konto sieht wie folgt aus: https://<account_name>.snowflakecomputing.com.
Sammeln Sie nach der Anmeldung die folgenden Informationen aus dem linken Bereich. Sie benötigen diese Informationen im nächsten Schritt:
- Wählen Sie unter Data die Option Databases aus, und kopieren Sie den Namen der Datenbankquelle.
- Wählen Sie in AdminBenutzer & Rollen aus, und kopieren Sie den Namen des Benutzers. Stellen Sie sicher, dass der Benutzer über Leseberechtigungen verfügt.
- Wählen Sie unter Admin die Option Accounts aus, und kopieren Sie den LOCATOR-Wert des Kontos.
- Kopieren Sie aus der Snowflake-URL im Format
https://app.snowflake.com/<region_name>/xy12345/organization)den Regionsnamen. Inhttps://app.snowflake.com/south-central-us.azure/xy12345/organizationist der Regionsname beispielsweisesouth-central-us.azure. - Wählen Sie unter Admin die Option Warehouses aus, und kopieren Sie den Namen des Warehouse, das der Datenbank zugeordnet ist, die Sie als Quelle verwenden.
Schritt 2: Konfigurieren des verknüpften Snowflake-Diensts
Melden Sie sich mit Ihrem Azure-Konto bei Azure Data Factory Studio an.
Wählen Sie Ihre Data Factory und dann Weiter aus.
Wählen Sie im Menü auf der linken Seite das Symbol Verwalten aus.

Wählen Sie unter Verknüpfte Dienste die Option Neu aus.
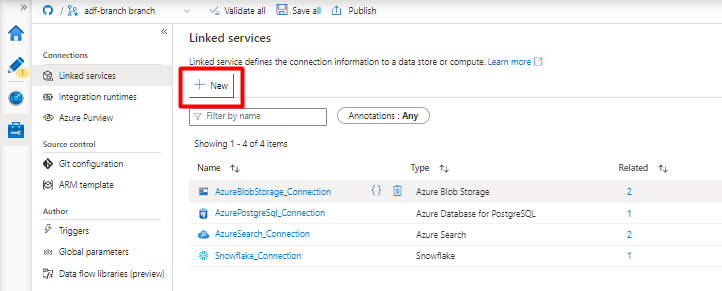
Geben Sie im rechten Bereich „snowflake“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Snowflake und dann Weiter aus.
Füllen Sie das Formular Neuer verknüpfter Dienst mit den Daten aus, die Sie im vorherigen Schritt gesammelt haben. Der Kontoname enthält einen LOCATOR-Wert und die Region (z. B.
xy56789south-central-us.azure).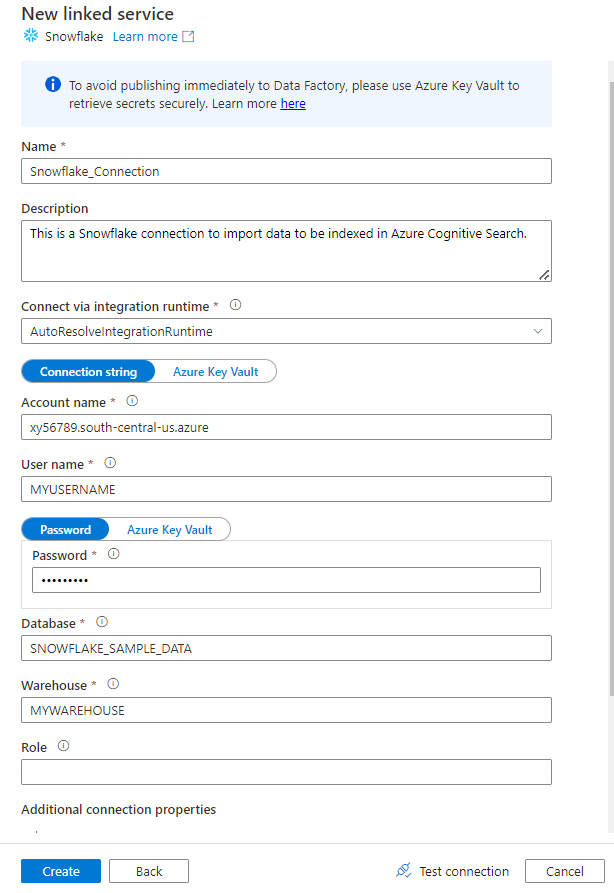
Wählen Sie nach dem Ausfüllen des Formulars Verbindung testen aus.
Wählen Sie Erstellen aus, wenn der Test erfolgreich ist.
Schritt 3: Konfigurieren des Snowflake-Datasets
Wählen Sie im Menü auf der linken Seite das Symbol Autor aus.
Wählen Sie Datasets und dann das Menü mit den Auslassungspunkten (
...) aus, um die Datasetaktionen anzuzeigen.
Wählen Sie Neues Dataset aus.
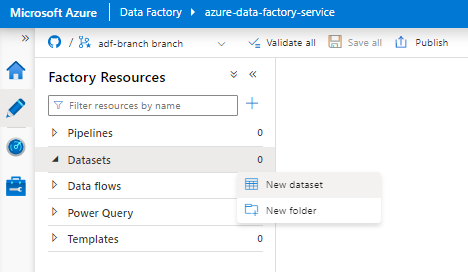
Geben Sie im rechten Bereich „snowflake“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Snowflake und dann Weiter aus.
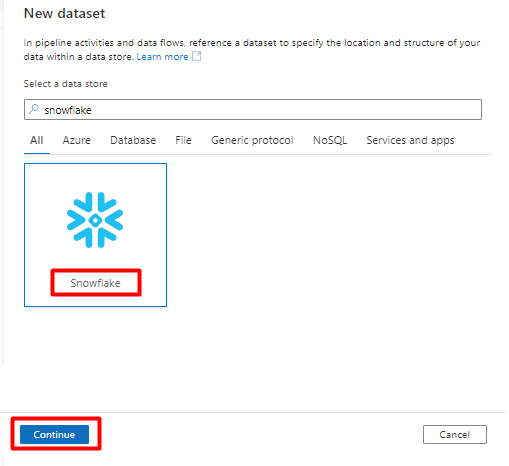
Unter Eigenschaften festlegen:
- Wählen Sie den verknüpften Dienst aus, den Sie in Schritt 2 erstellt haben.
- Wählen Sie die Tabelle, die Sie importieren möchten, und dann OK aus.
Wählen Sie Speichern aus.
Schritt 4: Erstellen eines neuen Index in Azure Cognitive Search
Erstellen Sie einen neuen Index mit dem gleichen Schema, das Sie derzeit für Ihre Snowflake-Daten konfiguriert haben, in Ihrem Azure Cognitive Search-Dienst.
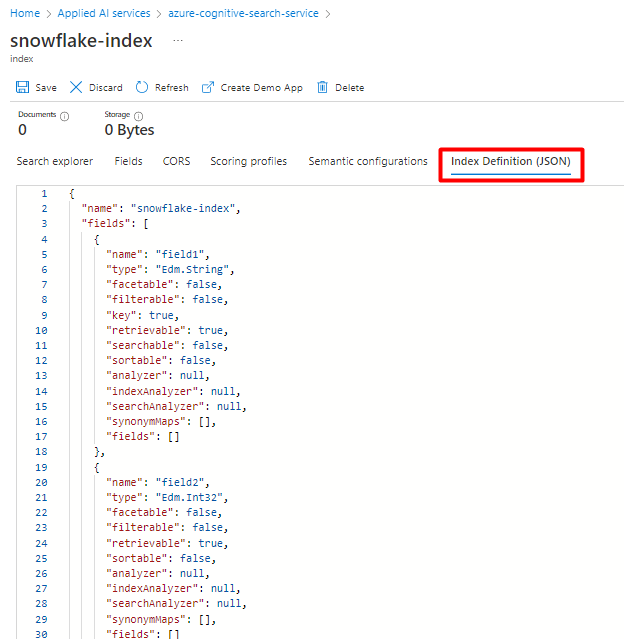
Sie können Ihren aktuellen Index für den Snowflake-Power Query-Connector wiederverwenden. Suchen Sie im Azure-Portal nach dem Index, und wählen Sie dann Indexdefinition (JSON) aus. Wählen Sie die Definition aus, und kopieren Sie sie in den Text Ihrer neuen Indexanforderung.
Schritt 5: Konfigurieren des verknüpften Azure Cognitive Search-Diensts
Wählen Sie im Menü auf der linken Seite das Symbol Verwalten aus.
Wählen Sie unter Verknüpfte Dienste die Option Neu aus.
Geben Sie im rechten Bereich „search“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure Search und dann Weiter aus.
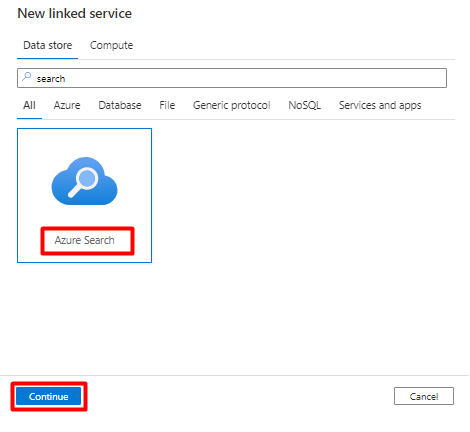
Füllen Sie die Felder unter Neuer verknüpfter Dienst aus:
- Wählen Sie das Azure-Abonnement aus, in dem sich Ihr Azure Cognitive Search-Dienst befindet.
- Wählen Sie den Azure Cognitive Search-Dienst aus, der den Indexer für Ihren Power Query-Connector enthält.
- Klicken Sie auf Erstellen.
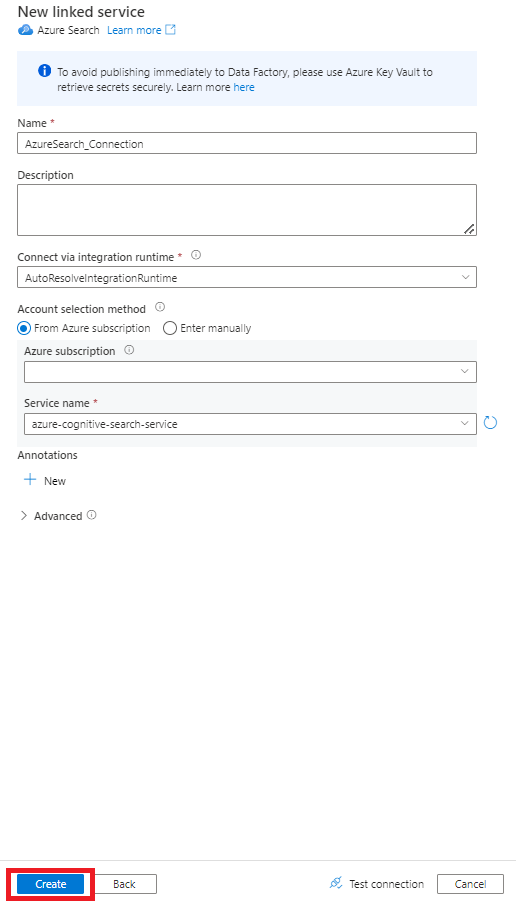
Schritt 6: Konfigurieren des Azure Cognitive Search-Datasets
Wählen Sie im Menü auf der linken Seite das Symbol Autor aus.
Wählen Sie Datasets und dann das Menü mit den Auslassungspunkten (
...) aus, um die Datasetaktionen anzuzeigen.
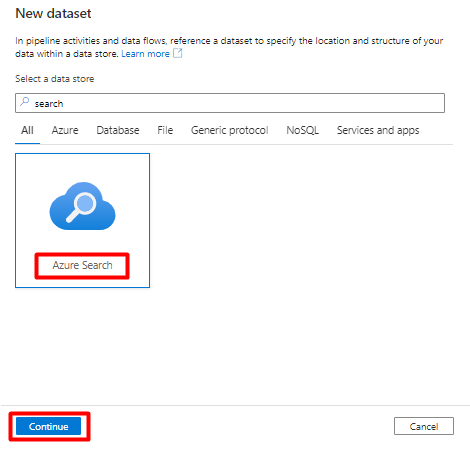
Wählen Sie Neues Dataset aus.
Geben Sie im rechten Bereich „search“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure Search und dann Weiter aus.
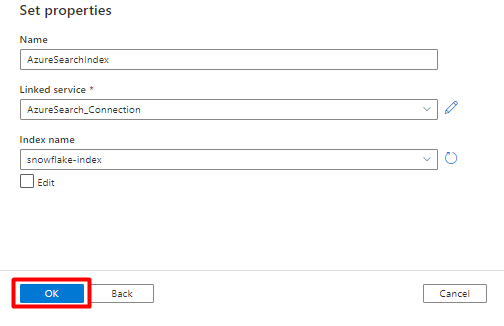
Unter Eigenschaften festlegen:
Wählen Sie Speichern aus.
Schritt 7: Konfigurieren des verknüpften Azure Blob Storage-Diensts
Wählen Sie im Menü auf der linken Seite das Symbol Verwalten aus.
Wählen Sie unter Verknüpfte Dienste die Option Neu aus.
Geben Sie im rechten Bereich „storage“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure Blob Storage und dann Weiter aus.
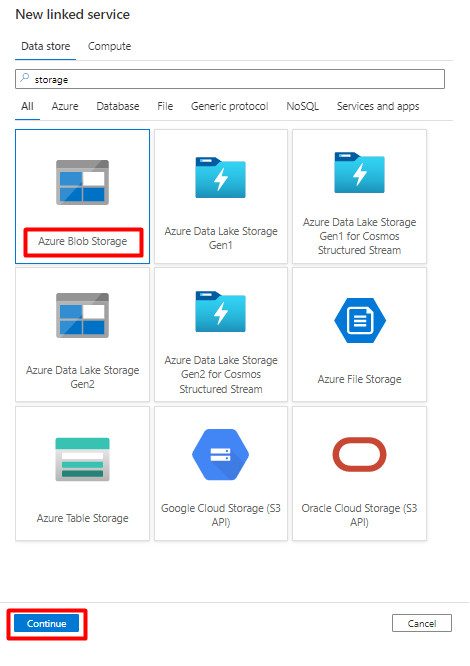
Füllen Sie die Felder unter Neuer verknüpfter Dienst aus:
Wählen Sie den Authentifizierungstyp „SAS-URI“ aus. Zum Importieren von Daten aus Snowflake in Azure Blob Storage kann nur dieser Authentifizierungstyp verwendet werden.
Generieren Sie eine SAS-URL für das Speicherkonto, das Sie für das Staging verwenden. Fügen Sie die Blob-SAS-URL in das Feld „SAS-URL“ ein.
Klicken Sie auf Erstellen.
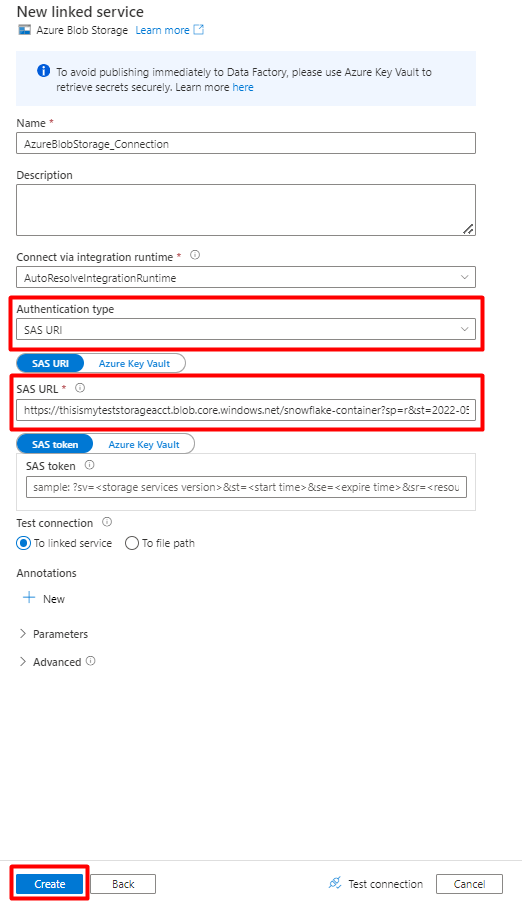
Schritt 8: Konfigurieren des Storage-Datasets
Wählen Sie im Menü auf der linken Seite das Symbol Autor aus.
Wählen Sie Datasets und dann das Menü mit den Auslassungspunkten (
...) aus, um die Datasetaktionen anzuzeigen.
Wählen Sie Neues Dataset aus.
Geben Sie im rechten Bereich „storage“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure Blob Storage und dann Weiter aus.
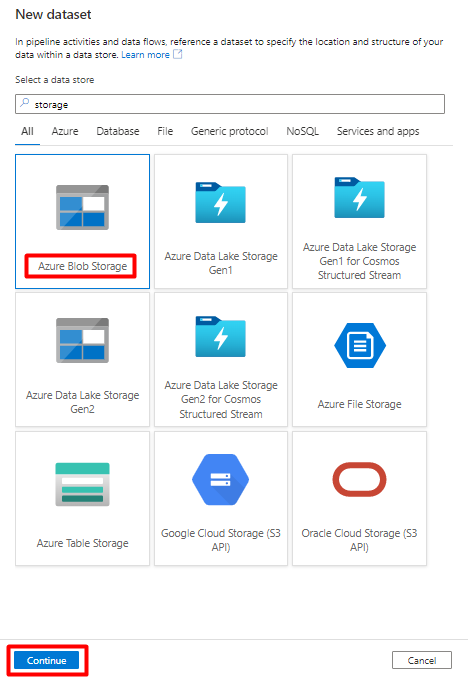
Wählen Sie das Format DelimitedText und dann Weiter aus.
Unter Eigenschaften festlegen:
Wählen Sie unter Verknüpfter Dienst den verknüpften Dienst aus, den Sie in Schritt 7 erstellt haben.
Wählen Sie unter Dateipfad den Container, der als Senke für den Stagingprozess verwendet werden soll, und dann OK aus.
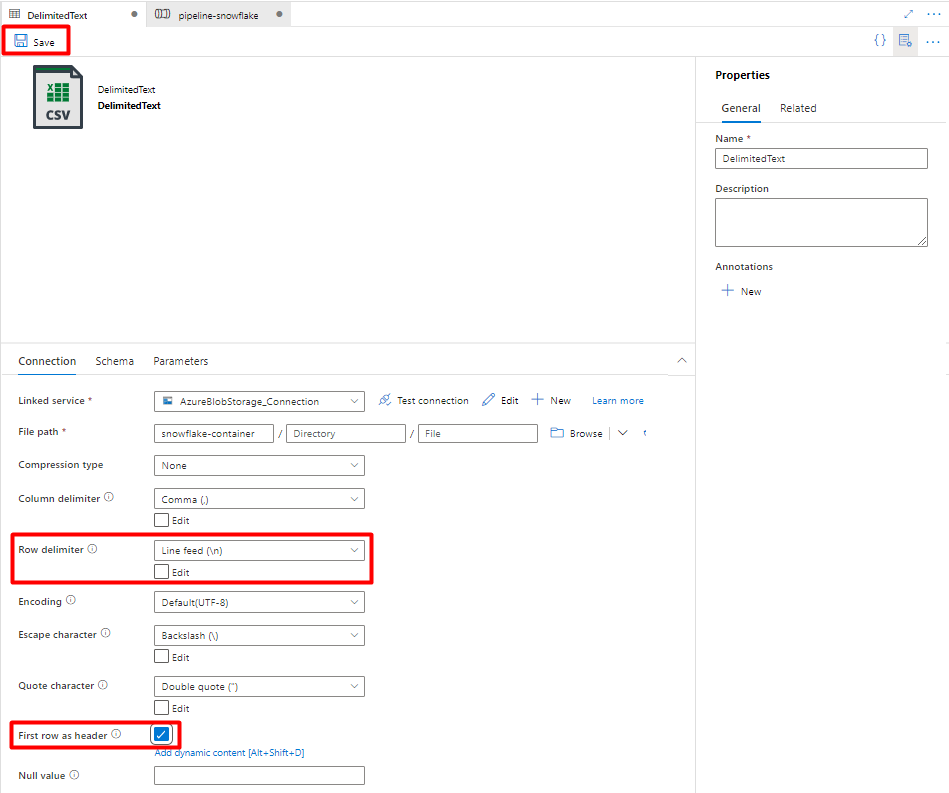
Wählen Sie unter Zeilentrennzeichen die Option Zeilenvorschub (\n) aus.
Aktivieren Sie das Kontrollkästchen Erste Zeile als Kopfzeile.
Wählen Sie Speichern aus.
Schritt 9: Konfigurieren der Pipeline
Wählen Sie im Menü auf der linken Seite das Symbol Autor aus.
Wählen Sie Pipelines und dann das Menü mit den Auslassungspunkten (
...) aus, um die Pipelineaktionen anzuzeigen.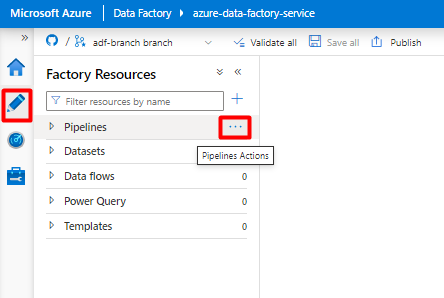
Wählen Sie Neue Pipeline aus.
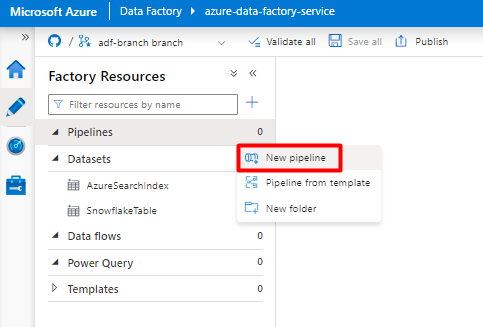
Erstellen und konfigurieren Sie die Data Factory-Aktivitäten zum Kopieren von Daten aus Snowflake in den Azure Storage-Container:
Erweitern Sie den Abschnitt Verschieben & Transformieren , und ziehen Sie die Aktivität Daten kopieren in die leere Pipeline-Editor-Canvas.
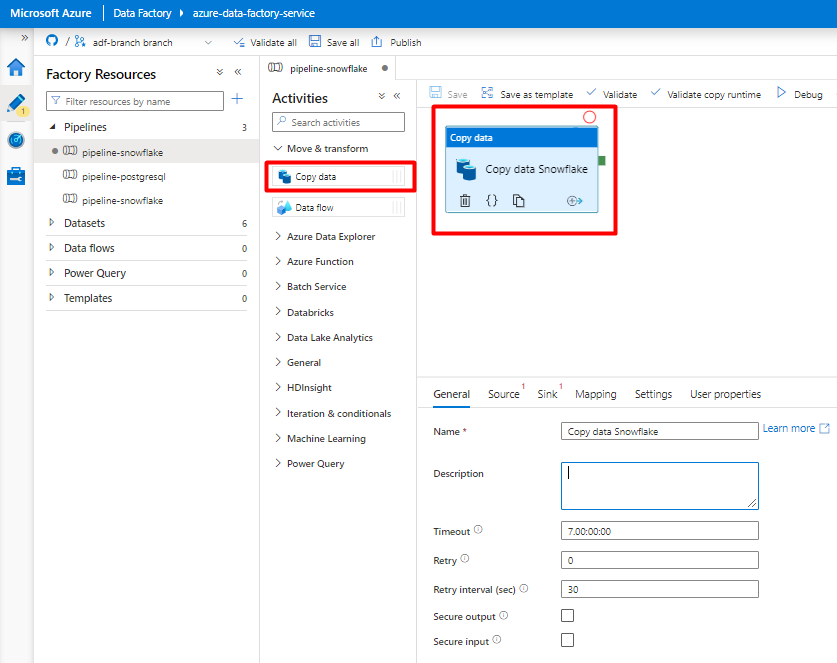
Öffnen Sie die Registerkarte Allgemein. Übernehmen Sie die Standardwerte, es sei denn, Sie müssen die Ausführung anpassen.
Wählen Sie auf der Registerkarte Quelle Ihre Snowflake-Tabelle aus. Übernehmen Sie für die übrigen Optionen die Standardwerte.

Auf der Registerkarte Senke:
Wählen Sie das Storage-Dataset im Format DelimitedText aus, das Sie in Schritt 8 erstellt haben.
Fügen Sie im Feld Dateierweiterung die Erweiterung .csv hinzu.
Übernehmen Sie für die übrigen Optionen die Standardwerte.

Wählen Sie Speichern aus.
Konfigurieren Sie die Aktivitäten zum Kopieren von Daten aus Azure Storage Blob in einen Suchindex:
Erweitern Sie den Abschnitt Verschieben & Transformieren , und ziehen Sie die Aktivität Daten kopieren in die leere Pipeline-Editor-Canvas.
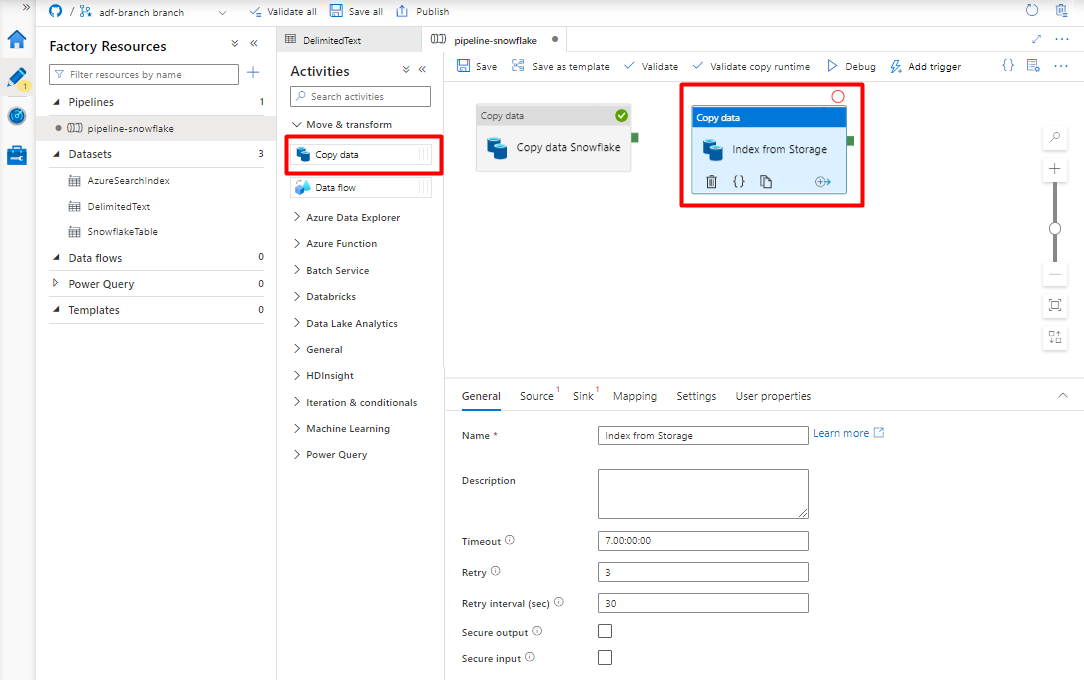
Übernehmen Sie auf der Registerkarte Allgemein die Standardwerte, es sei denn, Sie müssen die Ausführung anpassen.
Auf der Registerkarte Quelle:
- Wählen Sie das Storage-Dataset im Format DelimitedText aus, das Sie in Schritt 8 erstellt haben.
- Wählen Sie im Feld Dateipfadtyp die Option Platzhalterdateipfad aus.
- Übernehmen Sie für alle anderen Felder die Standardwerte.
Wählen Sie auf der Registerkarte Senke Ihren Azure Cognitive Search-Index aus. Übernehmen Sie für die übrigen Optionen die Standardwerte.
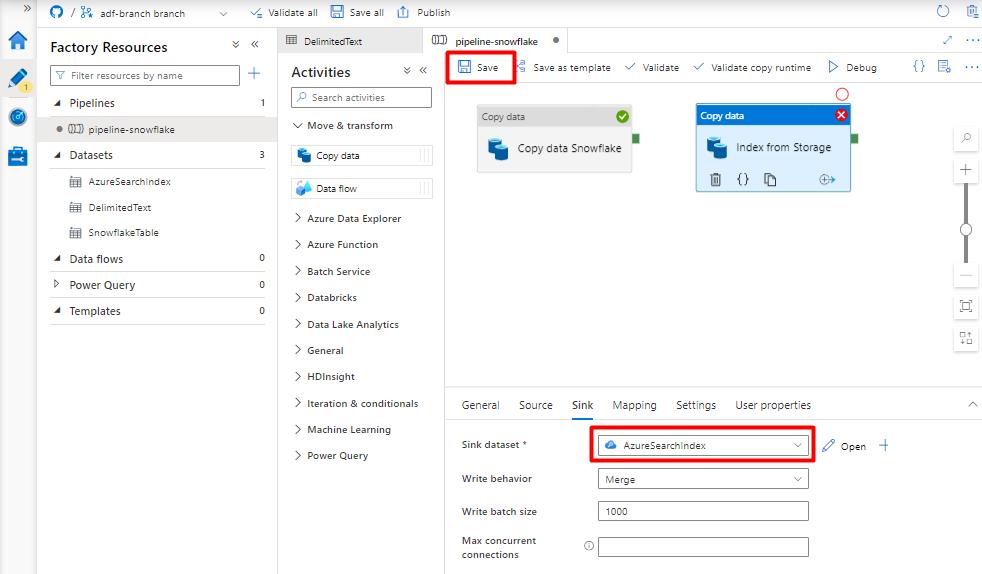
Wählen Sie Speichern aus.
Schritt 10: Konfigurieren der Aktivitätsreihenfolge
Wählen Sie in der Canvas des Pipeline-Editors das kleine grüne Quadrat am Rand der Kachel für die Pipelineaktivität aus. Ziehen Sie es in die Aktivität „Index von Speicherkonto in Azure Cognitive Search“, um die Ausführungsreihenfolge festzulegen.
Wählen Sie Speichern aus.

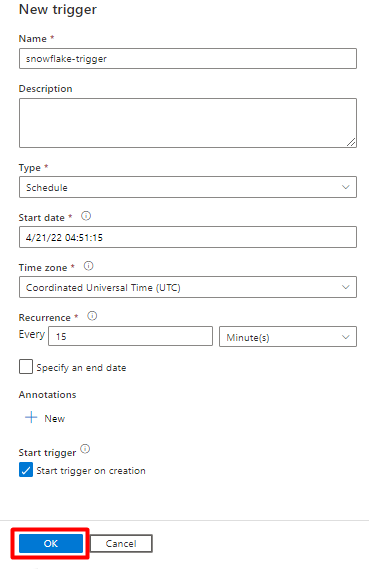
Schritt 11: Hinzufügen eines Pipelinetriggers
Wählen Sie Trigger hinzufügen aus, um die Pipelineausführung zu planen, und wählen Sie dann Neu/Bearbeiten aus.
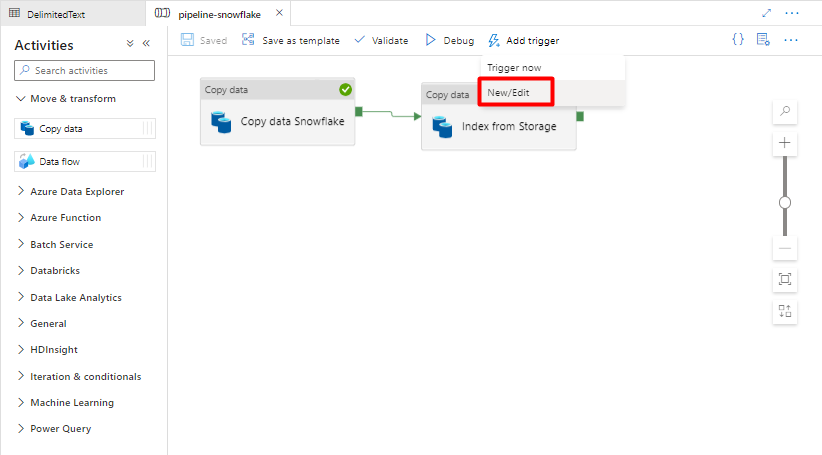
Wählen Sie in der Dropdownliste Trigger auswählen die Option Neu aus.
Überprüfen Sie die Triggeroptionen zum Ausführen der Pipeline, und wählen Sie OK aus.
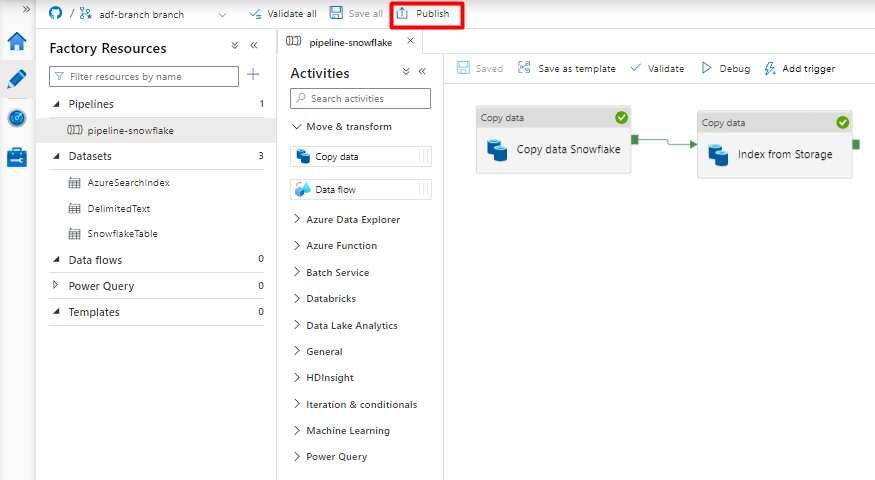
Wählen Sie Speichern aus.
Wählen Sie Veröffentlichen.
Migrieren einer PostgreSQL-Datenpipeline
In diesem Abschnitt wird erläutert, wie Sie Daten aus einer PostgreSQL-Datenbank in einen Azure Cognitive Search-Index kopieren. Es ist kein Prozess für die direkte Indizierung aus PostgreSQL in Azure Cognitive Search verfügbar. Dieser Abschnitt enthält daher eine Stagingphase, in der Datenbankinhalte in einen Azure Storage-Blobcontainer kopiert werden. Anschließend indizieren Sie die Daten aus diesem Stagingcontainer mithilfe einer Data Factory-Pipeline.
Schritt 1: Konfigurieren des verknüpften PostgreSQL-Diensts
Melden Sie sich mit Ihrem Azure-Konto bei Azure Data Factory Studio an.
Wählen Sie Ihre Data Factory und dann Weiter aus.
Wählen Sie im Menü auf der linken Seite das Symbol Verwalten aus.
Wählen Sie unter Verknüpfte Dienste die Option Neu aus.
Geben Sie im rechten Bereich „postgresql“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel PostgreSQL aus, die zeigt, wo sich Ihre PostgreSQL-Datenbank befindet (Azure oder anderer Speicherort), und wählen Sie Weiter aus. In diesem Beispiel befindet sich die PostgreSQL-Datenbank in Azure.

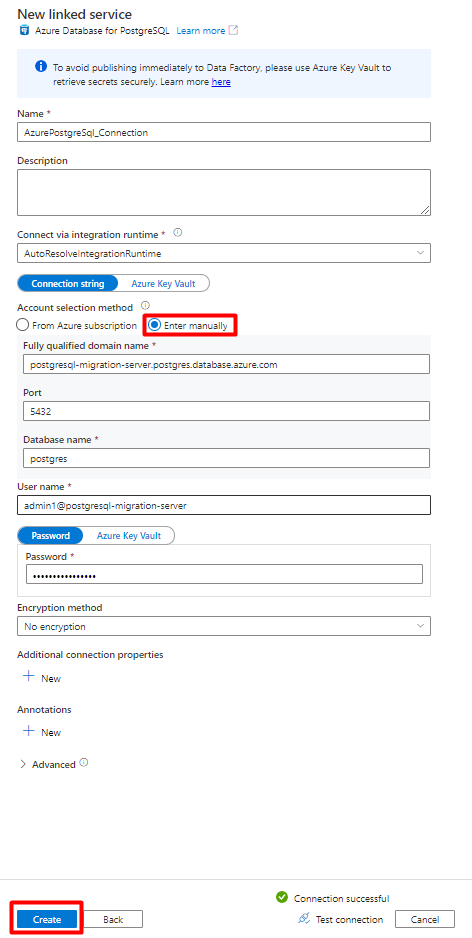
Füllen Sie die Felder unter Neuer verknüpfter Dienst aus:
Wählen Sie unter Methode für Kontoauswahl die Option Manuell eingeben aus.
Fügen Sie im Azure-Portal auf Ihrer Übersichtsseite für Azure Database for PostgreSQL die folgenden Werte in die entsprechenden Felder ein:
- Fügen Sie im Feld Vollqualifizierter Domänenname den Servernamen hinzu.
- Fügen Sie im Feld Benutzername des Administrators den Benutzernamen hinzu.
- Fügen Sie im Feld Datenbankname die Datenbank hinzu.
- Geben Sie das Kennwort für den Administratorbenutzernamen in das Feld Kennwort ein.
- Klicken Sie auf Erstellen.
Schritt 2: Konfigurieren des PostgreSQL-Datasets
Wählen Sie im Menü auf der linken Seite das Symbol Autor aus.
Wählen Sie Datasets und dann das Menü mit den Auslassungspunkten (
...) aus, um die Datasetaktionen anzuzeigen.
Wählen Sie Neues Dataset aus.
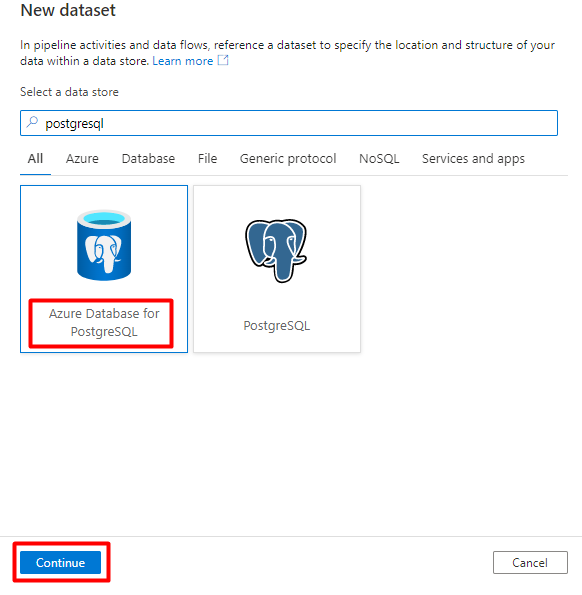
Geben Sie im rechten Bereich „postgresql“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure PostgreSQL aus. Wählen Sie Weiter.
Füllen Sie die Felder unter Eigenschaften festlegen aus:
Wählen Sie den verknüpften PostgreSQL-Dienst aus, den Sie in Schritt 1 erstellt haben.
Wählen Sie die Tabelle aus, die Sie importieren/indizieren möchten.
Klicken Sie auf OK.
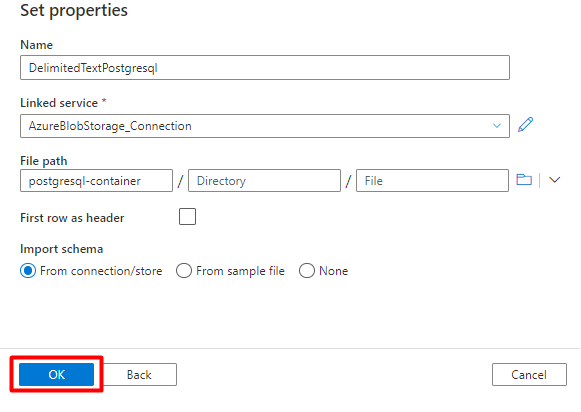
Wählen Sie Speichern aus.
Schritt 3: Erstellen eines neuen Index in Azure Cognitive Search
Erstellen Sie einen neuen Index mit dem gleichen Schema, das Sie für Ihre PostgreSQL-Daten verwendet haben, in Ihrem Azure Cognitive Search-Dienst.
Sie können Ihren aktuellen Index für den PostgreSQL-Power Query-Connector wiederverwenden. Suchen Sie im Azure-Portal nach dem Index, und wählen Sie dann Indexdefinition (JSON) aus. Wählen Sie die Definition aus, und kopieren Sie sie in den Text Ihrer neuen Indexanforderung.
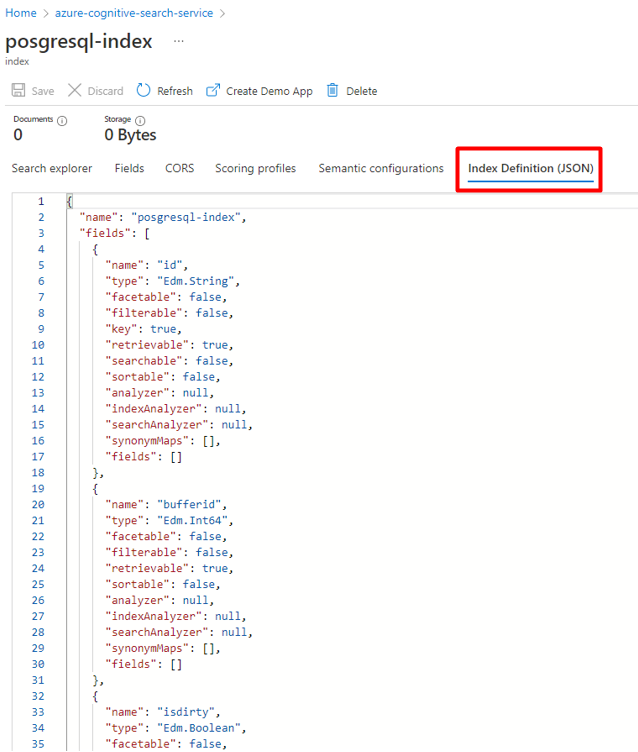
Schritt 4: Konfigurieren des verknüpften Azure Cognitive Search-Diensts
Wählen Sie im Menü auf der linken Seite das Symbol Verwalten aus.
Wählen Sie unter Verknüpfte Dienste die Option Neu aus.
Geben Sie im rechten Bereich „search“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure Search und dann Weiter aus.
Füllen Sie die Felder unter Neuer verknüpfter Dienst aus:
- Wählen Sie das Azure-Abonnement aus, in dem sich Ihr Azure Cognitive Search-Dienst befindet.
- Wählen Sie den Azure Cognitive Search-Dienst aus, der den Indexer für Ihren Power Query-Connector enthält.
- Klicken Sie auf Erstellen.
Schritt 5: Konfigurieren des Azure Cognitive Search-Datasets
Wählen Sie im Menü auf der linken Seite das Symbol Autor aus.
Wählen Sie Datasets und dann das Menü mit den Auslassungspunkten (
...) aus, um die Datasetaktionen anzuzeigen.
Wählen Sie Neues Dataset aus.
Geben Sie im rechten Bereich „search“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure Search und dann Weiter aus.
Unter Eigenschaften festlegen:
Wählen Sie Speichern aus.
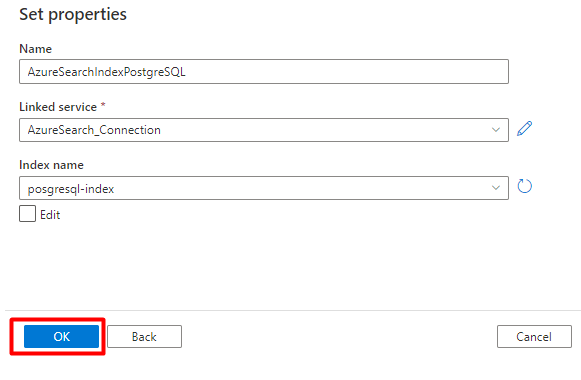
Schritt 6: Konfigurieren des verknüpften Azure Blob Storage-Diensts
Wählen Sie im Menü auf der linken Seite das Symbol Verwalten aus.
Wählen Sie unter Verknüpfte Dienste die Option Neu aus.
Geben Sie im rechten Bereich „storage“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure Blob Storage und dann Weiter aus.
Füllen Sie die Felder unter Neuer verknüpfter Dienst aus:
Wählen Sie für Authentifizierungstyp die Option SAS-URI aus. Zum Importieren von Daten aus PostgreSQL in Azure Blob Storage kann nur diese Methode verwendet werden.
Generieren Sie eine SAS-URL für das Speicherkonto, das Sie für das Staging verwenden, und kopieren Sie die Blob-SAS-URL in das Feld „SAS-URL“.
Klicken Sie auf Erstellen.
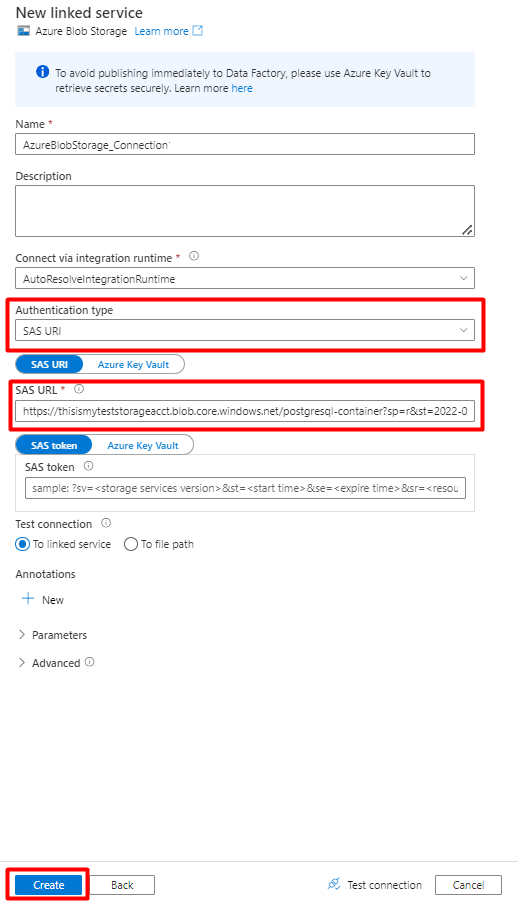
Schritt 7: Konfigurieren des Storage-Datasets
Wählen Sie im Menü auf der linken Seite das Symbol Autor aus.
Wählen Sie Datasets und dann das Menü mit den Auslassungspunkten (
...) aus, um die Datasetaktionen anzuzeigen.
Wählen Sie Neues Dataset aus.
Geben Sie im rechten Bereich „storage“ in das Suchfeld unter „Datenspeicher“ ein. Wählen Sie die Kachel Azure Blob Storage und dann Weiter aus.
Wählen Sie das Format DelimitedText und dann Weiter aus.
Wählen Sie unter Zeilentrennzeichen die Option Zeilenvorschub (\n) aus.
Aktivieren Sie das Kontrollkästchen Erste Zeile als Kopfzeile.
Wählen Sie Speichern aus.
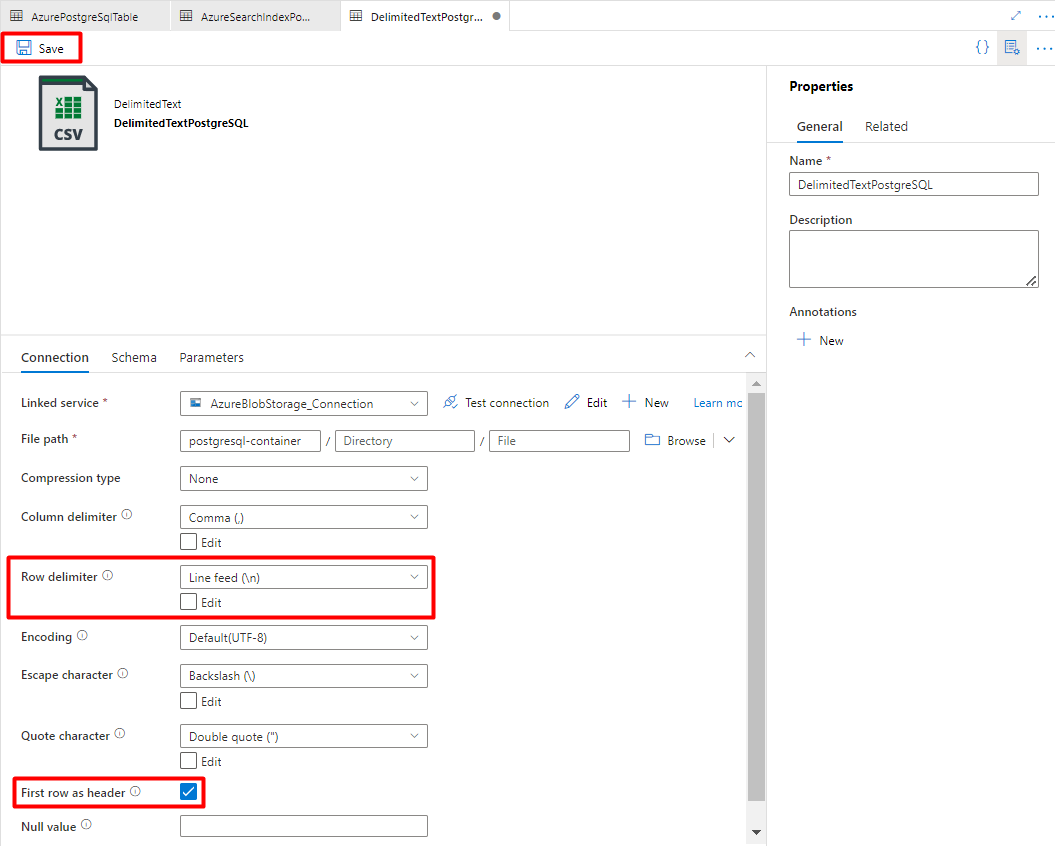
Schritt 8: Konfigurieren der Pipeline
Wählen Sie im Menü auf der linken Seite das Symbol Autor aus.
Wählen Sie Pipelines und dann das Menü mit den Auslassungspunkten (
...) aus, um die Pipelineaktionen anzuzeigen.
Wählen Sie Neue Pipeline aus.
Erstellen und konfigurieren Sie die Data Factory-Aktivitäten zum Kopieren von Daten aus PostgreSQL in den Azure Storage-Container.
Erweitern Sie den Abschnitt Verschieben & Transformieren , und ziehen Sie die Aktivität Daten kopieren in die leere Pipeline-Editor-Canvas.
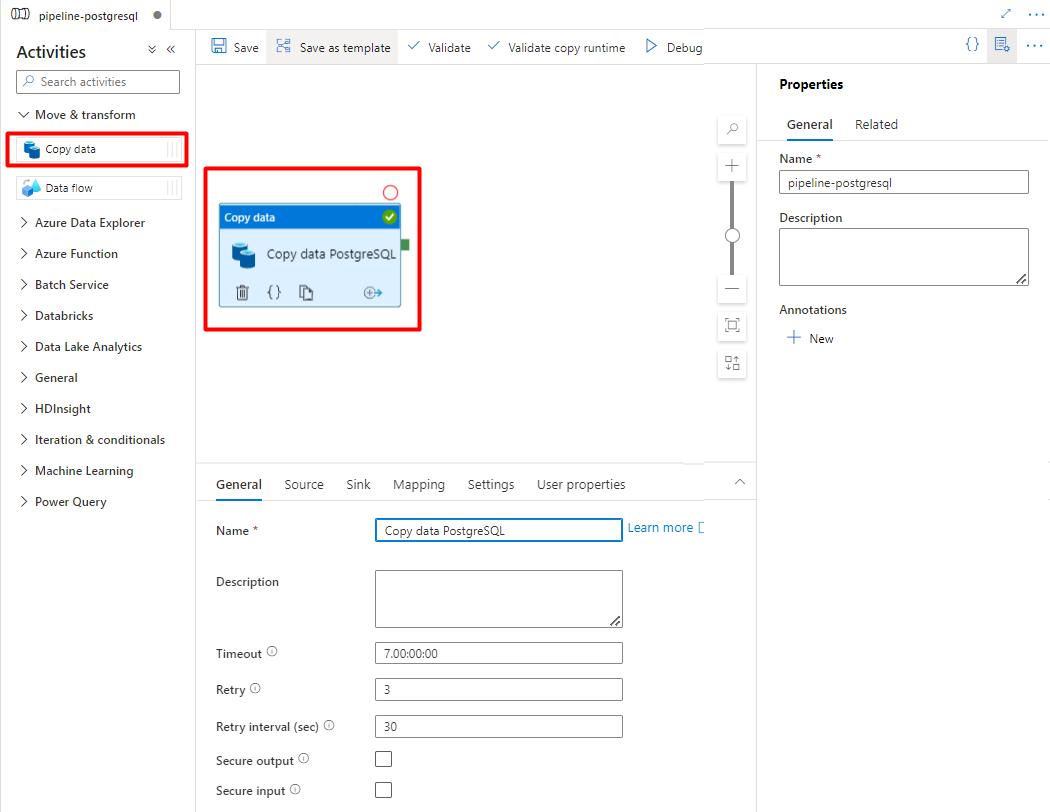
Öffnen Sie die Registerkarte Allgemein, und übernehmen Sie die Standardwerte, es sei denn, Sie müssen die Ausführung anpassen.
Wählen Sie auf der Registerkarte Quelle Ihre PostgreSQL-Tabelle aus. Übernehmen Sie für die übrigen Optionen die Standardwerte.
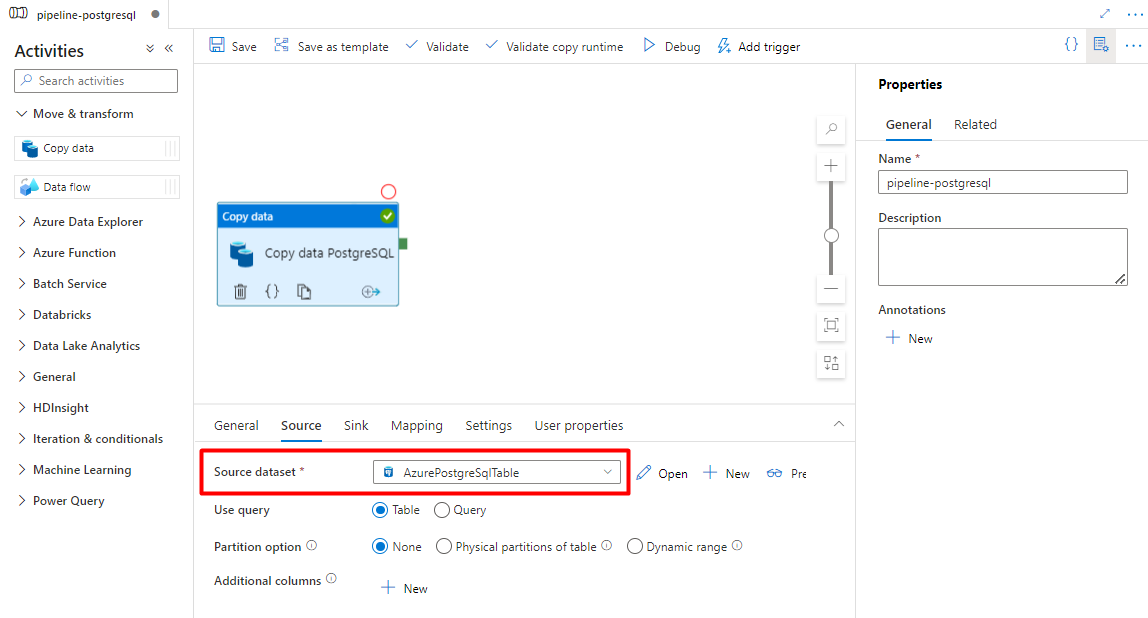
Auf der Registerkarte Senke:
Wählen Sie das Storage-Dataset für PostgreSQL im Format „DelimitedText“ aus, das Sie in Schritt 7 konfiguriert haben.
Fügen Sie im Feld Dateierweiterung die Erweiterung .csv hinzu.
Übernehmen Sie für die übrigen Optionen die Standardwerte.
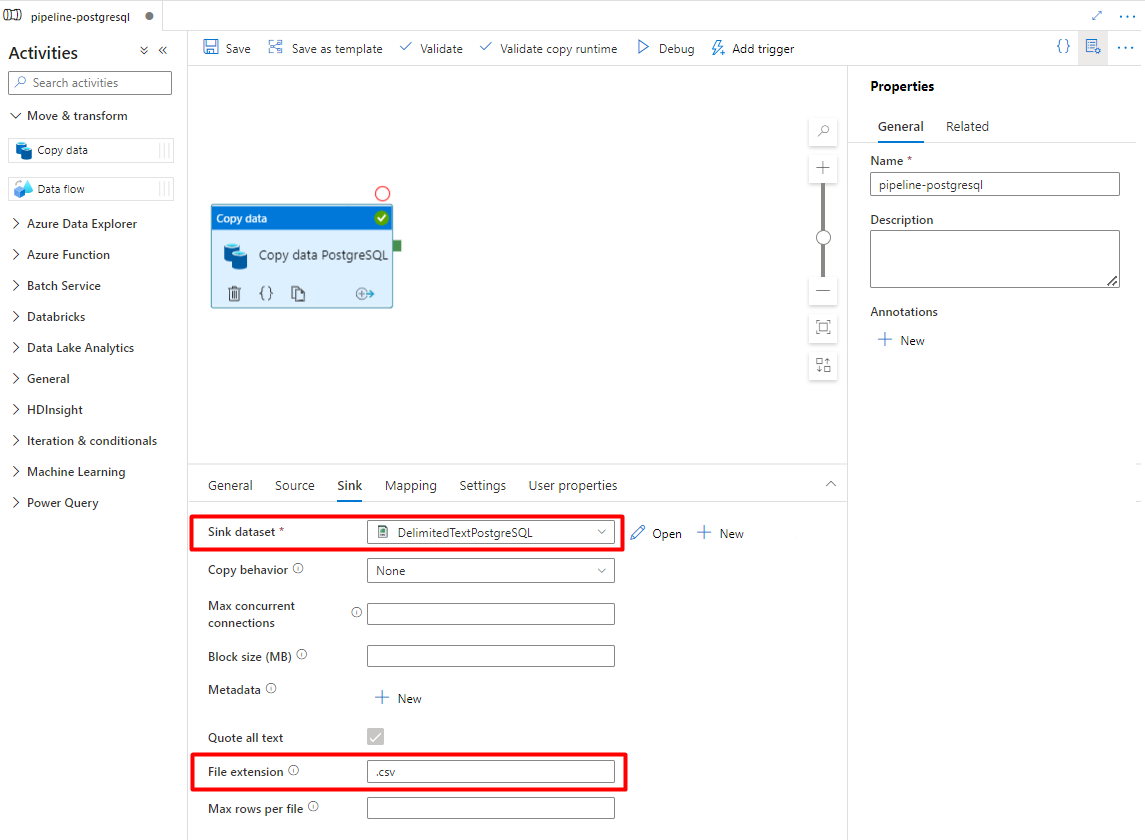
Wählen Sie Speichern aus.
Konfigurieren Sie die Aktivitäten zum Kopieren von Daten aus Azure Storage in einen Suchindex:
Erweitern Sie den Abschnitt Verschieben & Transformieren , und ziehen Sie die Aktivität Daten kopieren in die leere Pipeline-Editor-Canvas.
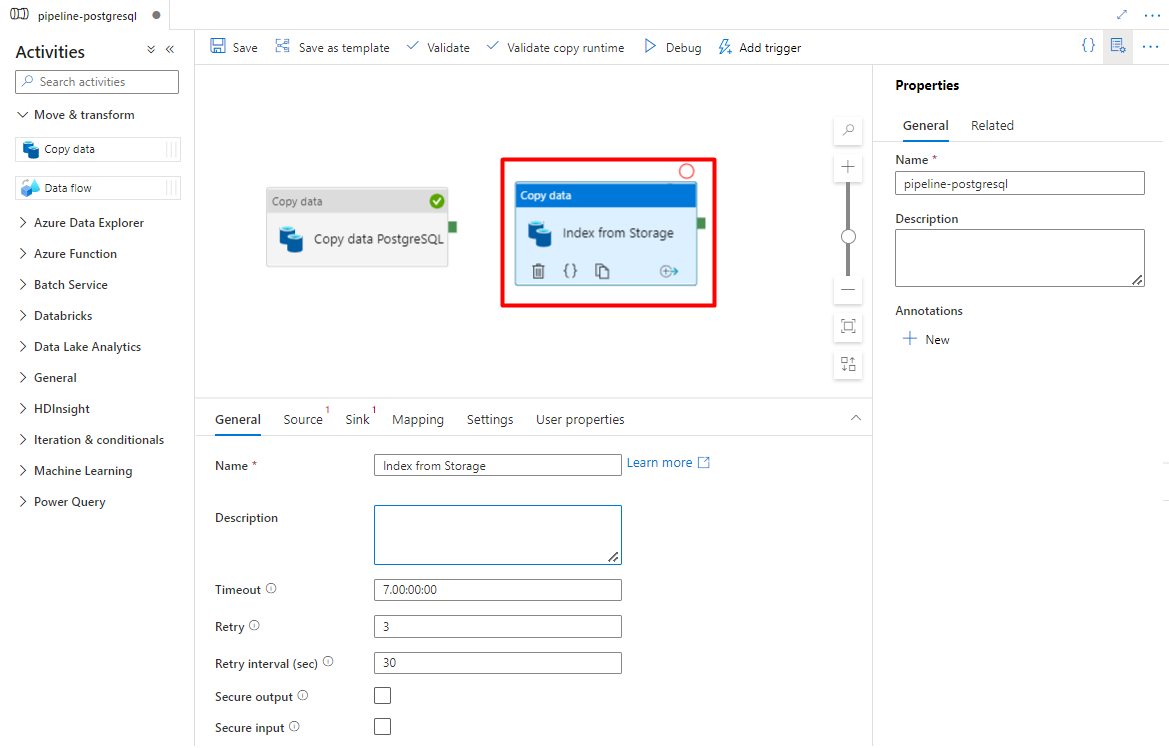
Übernehmen Sie auf der Registerkarte Allgemein die Standardwerte, es sei denn, Sie müssen die Ausführung anpassen.
Auf der Registerkarte Quelle:
- Wählen Sie das Storage-Quelldataset aus, das Sie in Schritt 7 konfiguriert haben.
- Wählen Sie im Feld Dateipfadtyp die Option Platzhalterdateipfad aus.
- Übernehmen Sie für alle anderen Felder die Standardwerte.
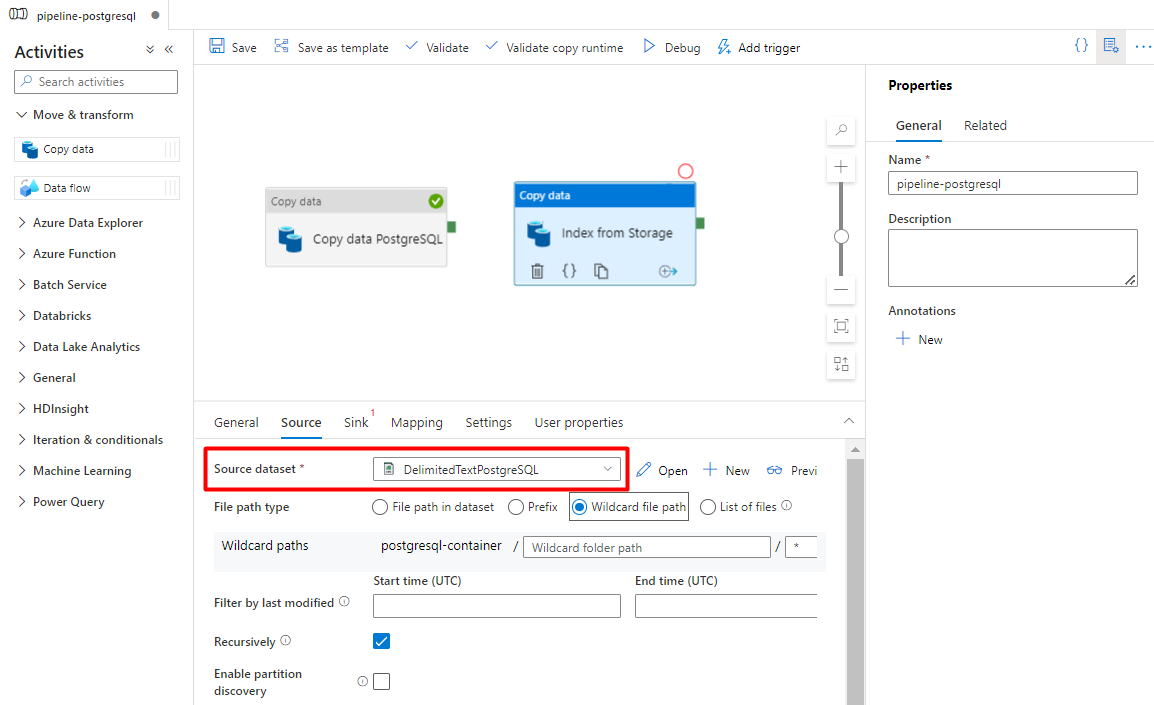
Wählen Sie auf der Registerkarte Senke Ihren Azure Cognitive Search-Index aus. Übernehmen Sie für die übrigen Optionen die Standardwerte.
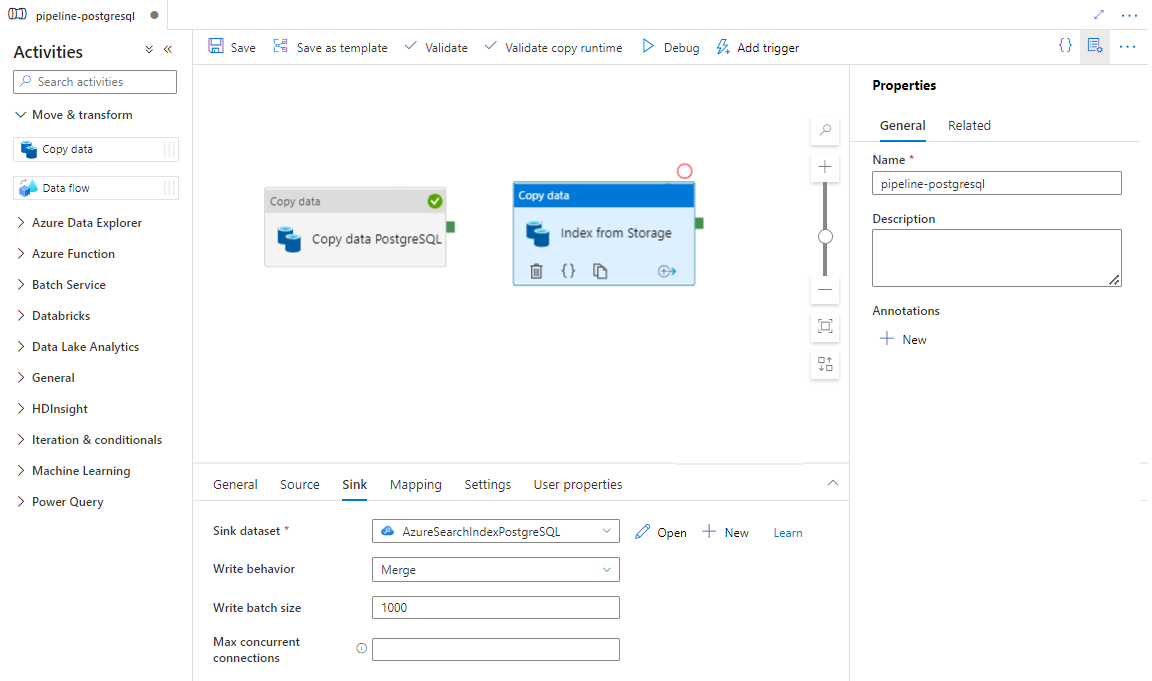
Wählen Sie Speichern aus.
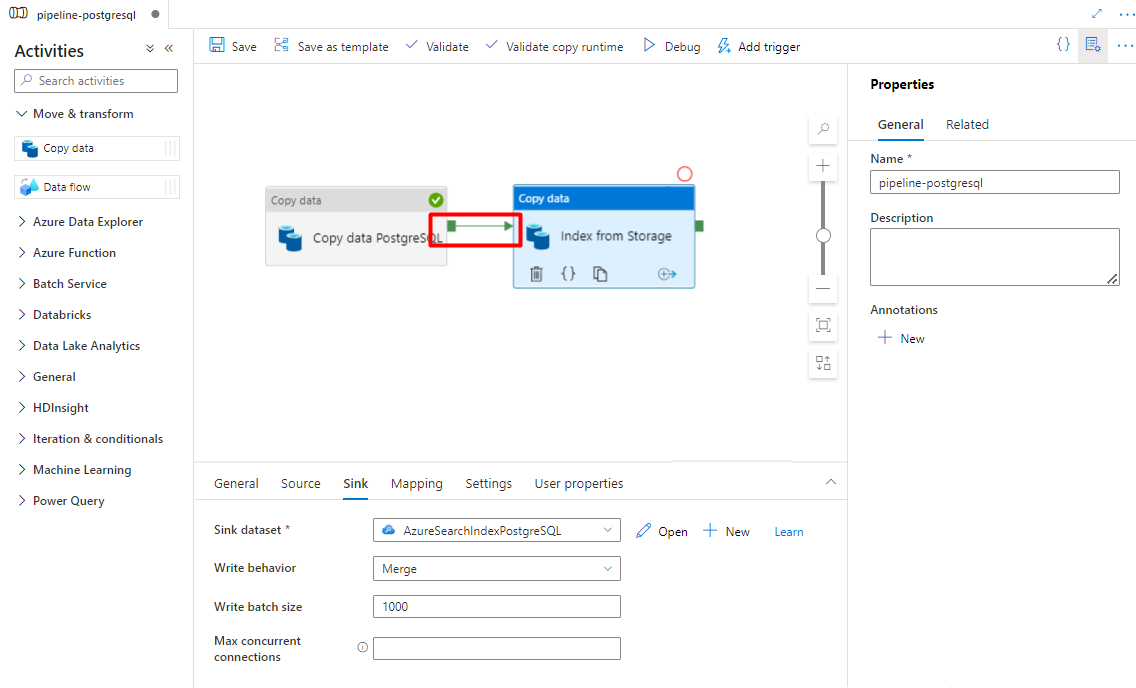
Schritt 9: Konfigurieren der Aktivitätsreihenfolge
Wählen Sie in der Canvas des Pipeline-Editors das kleine grüne Quadrat am Rand der Pipelineaktivität aus. Ziehen Sie es in die Aktivität „Index von Speicherkonto in Azure Cognitive Search“, um die Ausführungsreihenfolge festzulegen.
Wählen Sie Speichern aus.
Schritt 10: Hinzufügen eines Pipelinetriggers
Wählen Sie Trigger hinzufügen aus, um die Pipelineausführung zu planen, und wählen Sie dann Neu/Bearbeiten aus.
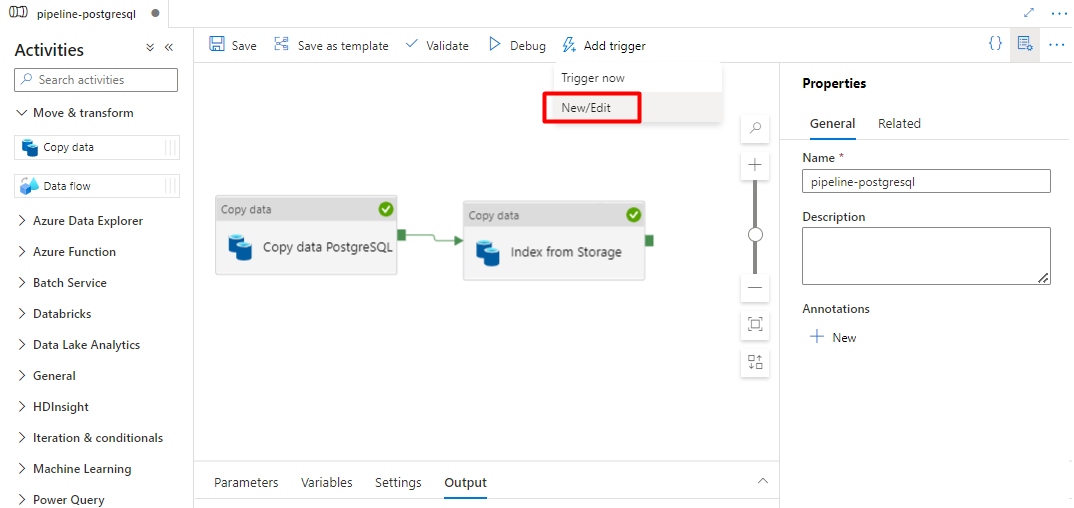
Wählen Sie in der Dropdownliste Trigger auswählen die Option Neu aus.
Überprüfen Sie die Triggeroptionen zum Ausführen der Pipeline, und wählen Sie OK aus.
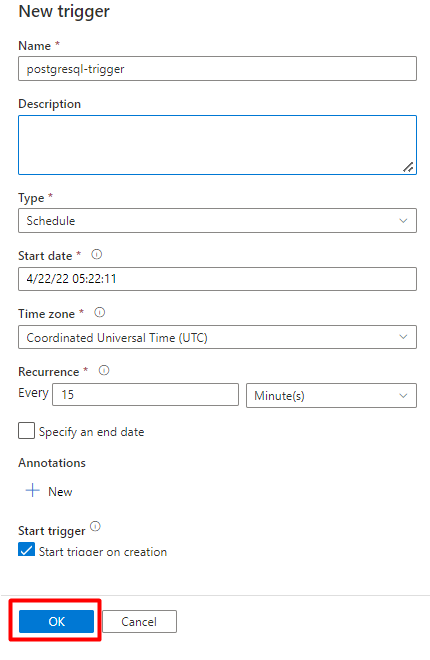
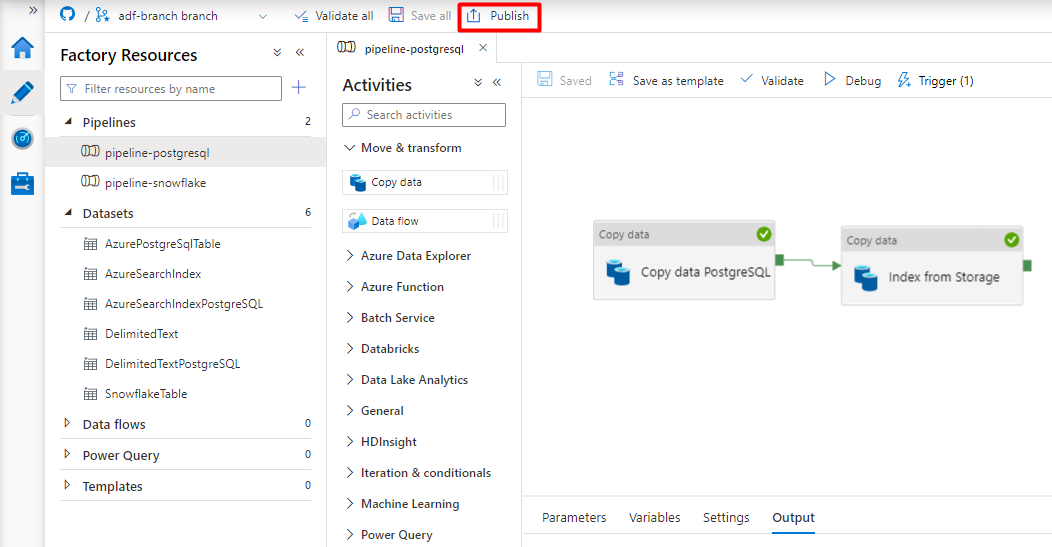
Wählen Sie Speichern aus.
Wählen Sie Veröffentlichen.
Legacyinhalte für die Vorschau der Power Query-Connectors
Ein Power Query-Connector wird mit einem Suchindexer verwendet, um die Datenerfassung aus verschiedenen Datenquellen zu automatisieren (einschließlich der Quellen bei anderen Cloudanbietern). Der Connector verwendet Power Query, um die Daten abzurufen.
In der Vorschauversion werden die folgenden Datenquellen unterstützt:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Salesforce-Objekte
- Salesforce-Berichte
- Smartsheet
- Snowflake
Unterstützte Funktionen
Power Query-Connectors werden in Indexern verwendet. Ein Indexer in Azure Cognitive Search ist ein Crawler, mit dem durchsuchbare Daten und Metadaten aus einer externen Datenquelle extrahiert werden und ein Index basierend auf Feld-zu-Feld-Zuordnungen zwischen dem Index und Ihrer Datenquelle aufgefüllt wird. Dieser Ansatz wird auch als „Pullmodell“ bezeichnet, weil der Dienst Daten abruft, ohne dass Sie Code schreiben müssen, der einem Index Daten hinzufügt. Indexer bieten Benutzern eine bequeme Möglichkeit, Inhalte aus ihrer Datenquelle zu indizieren, ohne ein eigenes Crawler- oder Pushmodell schreiben zu müssen.
Indexer, die auf Power Query-Datenquellen verweisen, verfügen über dasselbe Maß an Unterstützung für Skillsets, Zeitpläne, Erkennungslogik für Änderungen in der Obergrenzenmarkierung und die meisten Parameter, die von anderen Indexern unterstützt werden.
Voraussetzungen
Obwohl Sie dieses Feature nicht mehr verwenden können, wurden in der Vorschau die folgenden Anforderungen erfüllt:
Azure Cognitive Search-Dienst in einer unterstützten Region.
Vorschauregistrierung. Dieses Feature muss auf dem Back-End aktiviert sein.
Azure Blob Storage-Konto, das als Vermittler für Ihre Daten verwendet wird. Die Daten werden von Ihrer Datenquelle an Blob Storage und dann zum Index fließen. Diese Anforderung ist nur bei der anfänglichen geschlossenen Vorschau vorhanden.
Regionale Verfügbarkeit
Die Vorschauversion war nur für Suchdienste in den folgenden Regionen verfügbar:
- USA (Mitte)
- East US
- USA (Ost) 2
- USA Nord Mitte
- Nordeuropa
- USA Süd Mitte
- USA, Westen-Mitte
- Europa, Westen
- USA (Westen)
- USA, Westen 2
Einschränkungen der Vorschau
In diesem Abschnitt werden die Einschränkungen beschrieben, die konkret für die aktuelle Version der Vorschau gelten.
Das Pullen von Binärdaten aus der Datenquelle wird nicht unterstützt.
Die Funktion Debugsitzung wird nicht unterstützt.
Erste Schritte mit dem Azure-Portal
Das Azure-Portal bietet Unterstützung für die Power Query-Connectors. Der Datenimport-Assistent in der kognitiven Azure-Suche kann durch die Entnahme von Stichproben und das Lesen von Metadaten im Container einen Standardindex erstellen, Quellfelder Zielindexfeldern zuordnen und den Index in einem einzigen Vorgang laden. Je nach Größe und Komplexität der Quelldaten können Sie auch innerhalb von Minuten einen funktionsfähigen Volltextsuchindex erstellen.
Im folgenden Video wird gezeigt, wie Sie einen Power Query-Connector in Azure Cognitive Search einrichten.
Schritt 1: Aufbereiten von Quelldaten
Vergewissern Sie sich, dass Ihre Datenquelle Daten enthält. Zur Ableitung eines Indexschemas werden vom Datenimport-Assistenten Metadaten gelesen und Stichproben entnommen, aber es werden auch Daten aus Ihren Datenquellen geladen. Wenn die Daten fehlen, wird der Assistent beendet, und es wird ein Fehler zurückgegeben.
Schritt 2: Starten des Datenimport-Assistenten
Nachdem Sie für die Vorschau genehmigt wurden, stellt Ihnen das Azure Cognitive Search-Team einen Azure-Portal-Link bereit, der ein Featureflag verwendet, damit Sie auf die Power Query-Connectors zugreifen können. Öffnen Sie diese Seite, und starten Sie den Assistenten über die Befehlsleiste auf der Seite des Azure Cognitive Search-Diensts, indem Sie Daten importieren auswählen.
Schritt 3: Auswählen der Datenquelle
Es gibt einige Datenquellen, aus denen Sie Daten mithilfe dieser Vorschau abrufen können. Alle Datenquellen, für die Power Query verwendet wird, enthalten den Hinweis „Powered By Power Query“ auf ihrer Kachel. Wählen Sie Ihre Datenquelle aus.
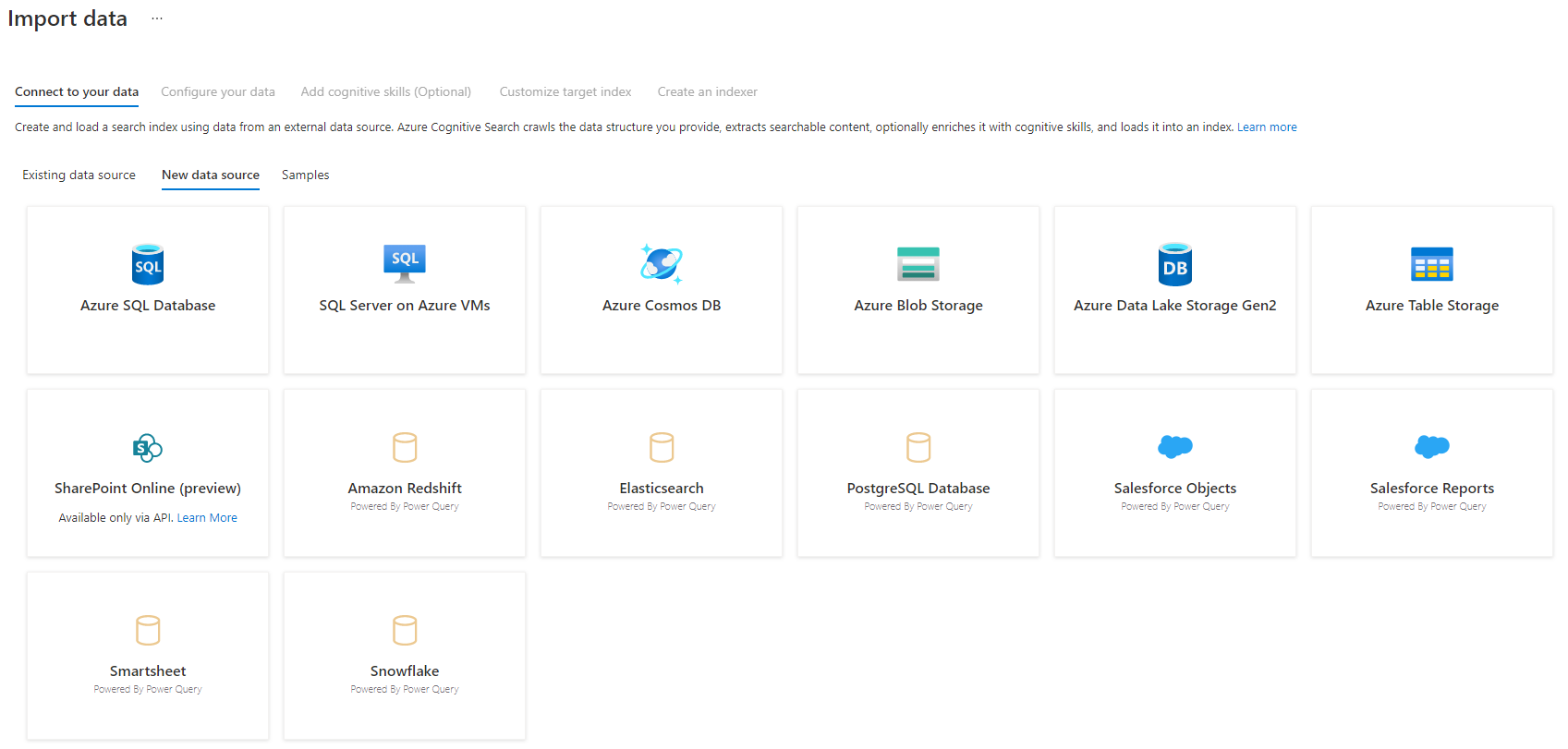
Nachdem Sie Ihre Datenquelle ausgewählt haben, wählen Sie Weiter: Daten konfigurieren aus, um mit dem nächsten Abschnitt fortzufahren.
Schritt 4: Konfigurieren Ihrer Daten
In diesem Schritt konfigurieren Sie Ihre Verbindung. Die einzelnen Datenquellen erfordern jeweils unterschiedliche Informationen. Für einige Datenquellen enthält die Power Query-Dokumentation ausführlichere Informationen zum Herstellen einer Verbindung mit Ihren Daten.
Nachdem Sie Ihre Anmeldeinformationen für die Verbindung angegeben haben, wählen Sie Weiter aus.
Schritt 5: Auswählen Ihrer Daten
Im Import-Assistenten wird eine Vorschau verschiedener Tabellen angezeigt, die in Ihrer Datenquelle verfügbar sind. In diesem Schritt überprüfen Sie eine Tabelle, die die Daten enthält, die Sie in Ihren Index importieren möchten.

Nachdem Sie die Tabelle ausgewählt haben, wählen Sie Weiter aus.
Schritt 6: Transformieren Ihrer Daten (optional)
Power Query-Connectors bieten Ihnen eine umfassende Benutzeroberfläche, mit der Sie die Daten bearbeiten können, damit Sie die richtigen Daten an den Index senden können. Sie können Spalten entfernen, Zeilen filtern und vieles mehr.
Es ist nicht erforderlich, dass Sie die Daten transformieren, bevor Sie sie in Azure Cognitive Search importieren.

Weitere Informationen zum Transformieren von Daten mit Power Query finden Sie unter Verwenden von Power Query in Power BI Desktop.
Wählen Sie nach dem Transformieren der Daten Weiter aus.
Schritt 7: Hinzufügen von Azure Blob Storage
Für die Vorschauversion der Power Query-Connectors müssen Sie derzeit ein Blob-Speicherkonto angeben. Dieser Schritt ist nur bei der anfänglichen geschlossenen Vorschau vorhanden. Dieses Blob-Speicherkonto dient als temporärer Speicher für Daten, die von Ihrer Datenquelle in einen Azure Cognitive Search-Index verschoben werden.
Es wird empfohlen, eine Verbindungszeichenfolge für das Speicherkonto mit Vollzugriff bereitzustellen:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
Sie können die Verbindungszeichenfolge über das Azure-Portal abrufen, indem Sie auf dem Blatt des Speicherkontos zu > „Einstellungen“ > „Schlüssel“ (für klassische Speicherkonten) oder zu „Einstellungen“ > „Zugriffsschlüssel“ (für Azure Resource Manager-Speicherkonten) navigieren.
Nachdem Sie einen Datenquellennamen und eine Verbindungszeichenfolge angegeben haben, wählen Sie „Weiter: Kognitive Qualifikationen hinzufügen (Optional)“ aus.
Schritt 8: Kognitive Qualifikationen hinzufügen (Optional)
Die KI-Anreicherung ist eine Erweiterung von Indexern, die dazu verwendet werden kann, Ihre Inhalte leichter durchsuchbar zu machen.
Sie können beliebige Anreicherungen hinzufügen, die für Ihr Szenario von Nutzen sind. Wählen Sie nach Abschluss des Vorgangs Weiter: Zielindex anpassen aus.
Schritt 9: Anpassen des Zielindex
Auf der Indexseite sollte eine Liste von Feldern mit einem Datentyp sowie mehrere Kontrollkästchen zum Festlegen von Indexattributen aufgeführt sein. Der Assistent kann basierend auf Metadaten und durch Sampling der Quelldaten eine Felderliste erstellen.
Sie können mehrere Attribute gleichzeitig auswählen, indem Sie das Kontrollkästchen oben in einer Attributspalte aktivieren. Wählen Sie Abrufbar und Durchsuchbar für jedes Feld aus, das an eine Client-App zurückgegeben werden sollte und der Volltextsuche unterliegt. Sie werden feststellen, dass ganze Zahlen bei der Volltext- oder Fuzzysuche nicht suchbar sind (Zahlen werden nach ihrem genauen Wortlaut ausgewertet und sind in Filtern häufig hilfreich).
Weitere Informationen finden Sie in den Beschreibungen der Indexattribute und Sprachanalysetools.
Nehmen Sie sich einen Moment Zeit, um Ihre Auswahl zu überprüfen. Wenn Sie den Assistenten ausführen, werden physische Datenstrukturen erstellt, und Sie können den Großteil der Eigenschaften für diese Felder nicht bearbeiten, ohne alle Objekte zu löschen und neu zu erstellen.

Wählen Sie nach Abschluss des Vorgangs Weiter: Indexer erstellen aus.
Schritt 10: Erstellen eines Indexers
Mit dem letzten Schritt wird der Indexer erstellt. Wenn der Indexer benannt wird, kann er als eigenständige Ressource existieren. Diese können Sie unabhängig vom Index und Datenquellenobjekt, die im selben Durchlauf des Assistenten erstellt wurden, planen und verwalten.
Die Ausgabe des Datenimport-Assistenten ist ein Indexer, der Ihre Datenquelle crawlt und die von Ihnen ausgewählten Daten in einen Index in Azure Cognitive Search importiert.
Beim Erstellen des Indexers können Sie optional den Indexer nach einem Zeitplan ausführen und die Änderungserkennung hinzufügen. Legen Sie eine Spalte mit oberem Grenzwert fest, um die Änderungserkennung hinzuzufügen.
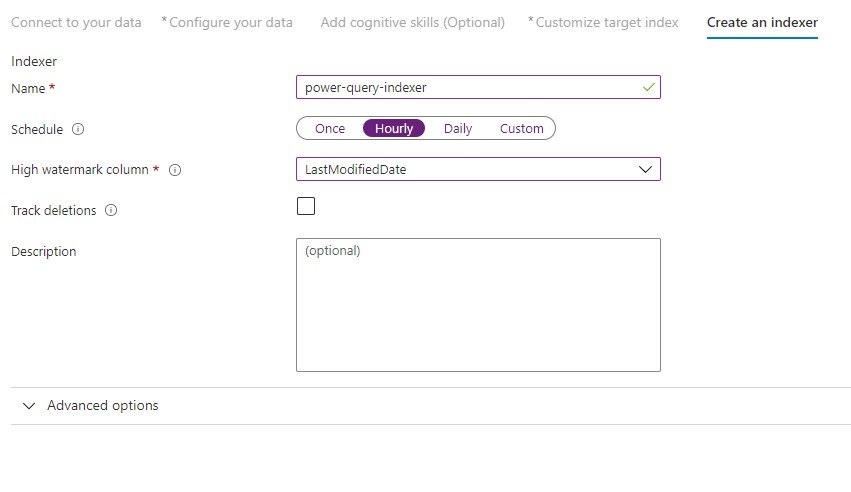
Nachdem Sie diese Seite ausgefüllt haben, wählen Sie die Option zum Übermitteln aus.
Richtlinie zum Erkennen von Änderungen mit oberem Grenzwert
Diese Richtlinie zur Erkennung von Änderungen basiert auf einer Spalte mit oberem Grenzwert, die Version oder Uhrzeit der letzten Aktualisierung einer Zeile erfasst.
Requirements (Anforderungen)
- Alle Einfügungen geben einen Wert für die Spalte an.
- Alle Updates für ein Element ändern auch den Wert der Spalte.
- Der Wert dieser Spalte wird bei jeder Einfügung oder Aktualisierung erhöht.
Nicht unterstützte Spaltennamen
Feldnamen in einem Azure Cognitive Search-Index müssen bestimmte Anforderungen erfüllen. Eine dieser Anforderungen ist, dass einige Zeichen wie „/“ nicht zulässig sind. Wenn ein Spaltenname in Ihrer Datenbank diese Anforderungen nicht erfüllt, wird die Spalte von der Indexschemaerkennung nicht als gültiger Feldname erkannt, und die Spalte wird nicht als vorgeschlagenes Feld für Ihren Index aufgeführt. Normalerweise würde das Problem durch die Verwendung von Feldzuordnungen gelöst, aber Feldzuordnungen werden im Portal nicht unterstützt.
Benennen Sie die Spalte während der Phase „Transform your data“ (Daten transformieren) des Datenimportprozesses um, um Inhalte aus einer Tabellenspalte mit einem nicht unterstützten Feldnamen zu indizieren. Beispielsweise können Sie eine Spalte mit der Bezeichnung „Abrechnungscode/Postleitzahl“ in „Postleitzahl“ umbenennen. Durch Umbenennen der Spalte wird die Spalte von der Indexschemaerkennung als gültiger Feldname erkannt und der Indexdefinition als Vorschlag hinzugefügt.
Nächste Schritte
In diesem Artikel wurde das Pullen von Daten mithilfe der Power Query-Connectors erläutert. Da diese Previewfunktion eingestellt wird, enthält dieser Artikel auch Informationen zur Migration vorhandener Lösungen zu einem unterstützten Szenario.
Weitere Informationen zu Indexern finden Sie unter Indexer in Azure Cognitive Search.