Schnellstart: Erstellen einer Data Factory im Azure-Portal
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Diese Schnellstartanleitung beschreibt, wie Sie mit Azure Data Factory Studio oder der Azure-Portal-Benutzeroberfläche eine Data Factory erstellen.
Hinweis
Wenn Sie mit Azure Data Factory nicht vertraut sind, lesen Sie die Informationen unter Einführung in Azure Data Factory, bevor sie diesen Schnellstart ausprobieren.
Voraussetzungen
Azure-Abonnement
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Azure-Rollen
Informationen zu den Azure-Rollenanforderungen zum Erstellen einer Data Factory finden Sie unter Azure-Rollen.
Erstellen einer Data Factory
In Azure Data Factory Studio wird eine Umgebung für die schnelle Erstellung bereitgestellt, damit Benutzer innerhalb von Sekunden eine Data Factory erstellen können. Im Azure-Portal sind erweiterte Erstellungsoptionen verfügbar.
Schnelle Erstellung in Azure Data Factory Studio
Starten Sie den Webbrowser Microsoft Edge oder Google Chrome. Die Data Factory-Benutzeroberfläche wird zurzeit nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
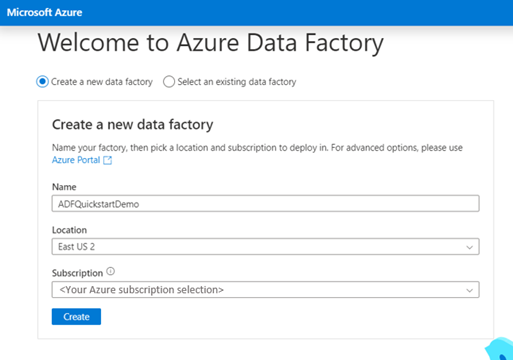
Wechseln Sie zum Azure Data Factory Studio, und wählen Sie das Optionsfeld Neue Data Factory erstellen aus.
Sie können die Standardwerte verwenden, um direkt zu erstellen, oder einen eindeutigen Namen eingeben und einen bevorzugten Speicherort und ein Abonnement auswählen, das beim Erstellen der neuen Data Factory verwendet werden soll.
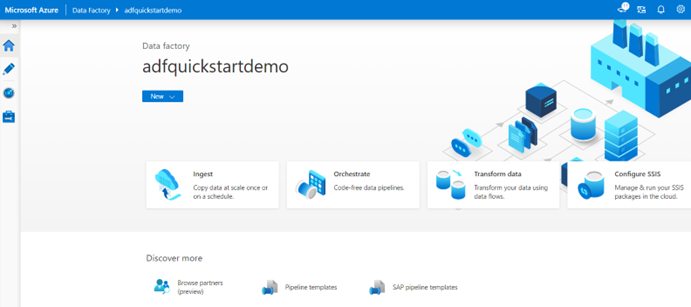
Nach der Erstellung können Sie direkt die Homepage von Azure Data Factory Studio eingeben.
Erweiterte Erstellung im Azure-Portal
Starten Sie den Webbrowser Microsoft Edge oder Google Chrome. Die Data Factory-Benutzeroberfläche wird zurzeit nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Wechseln Sie zur Data Factorys-Seite im Azure-Portal.
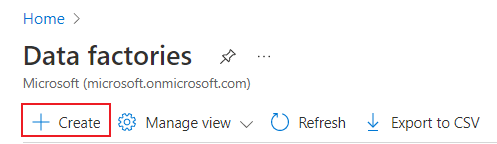
Klicken Sie auf der Data Factorys-Seite im Azure-Portal auf Erstellen.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
Wählen Sie in der Dropdownliste eine vorhandene Ressourcengruppe aus.
Wählen Sie Neu erstellen aus, und geben Sie den Namen einer neuen Ressourcengruppe ein.
Weitere Informationen zu Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie unter Region den Standort für die Data Factory aus.
In der Liste werden nur Standorte angezeigt, die von Data Factory unterstützt werden und an denen Ihre Azure Data Factory-Metadaten gespeichert werden. Die von Data Factory verwendeten zugeordneten Datenspeicher (z. B. Azure Storage und Azure SQL-Datenbank) und Computedienste (z. B. Azure HDInsight) können in anderen Regionen ausgeführt werden.
Geben Sie unter Name den Namen ADFTutorialDataFactory ein.
Der Name der Azure Data Factory muss global eindeutigsein. Sollte der folgende Fehler auftreten, ändern Sie den Namen der Data Factory (beispielsweise in <IhrName>ADFTutorialDataFactory), und wiederholen Sie den Vorgang. Benennungsregeln für Data Factory-Artefakte finden Sie im Artikel Azure Data Factory – Benennungsregeln.
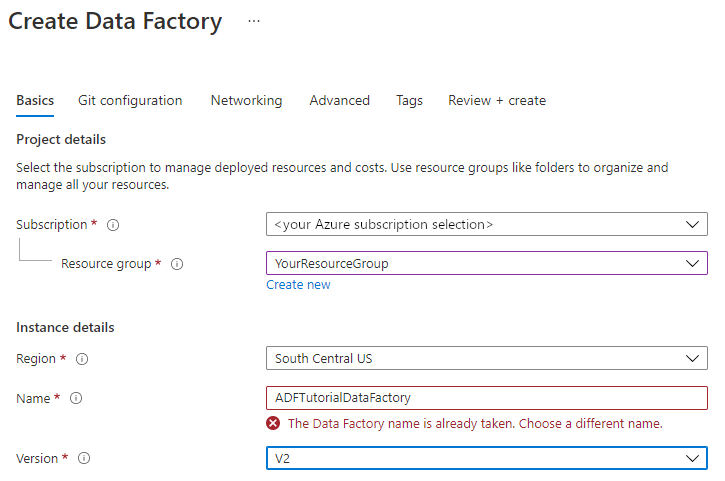
Wählen Sie V2 als Version aus.
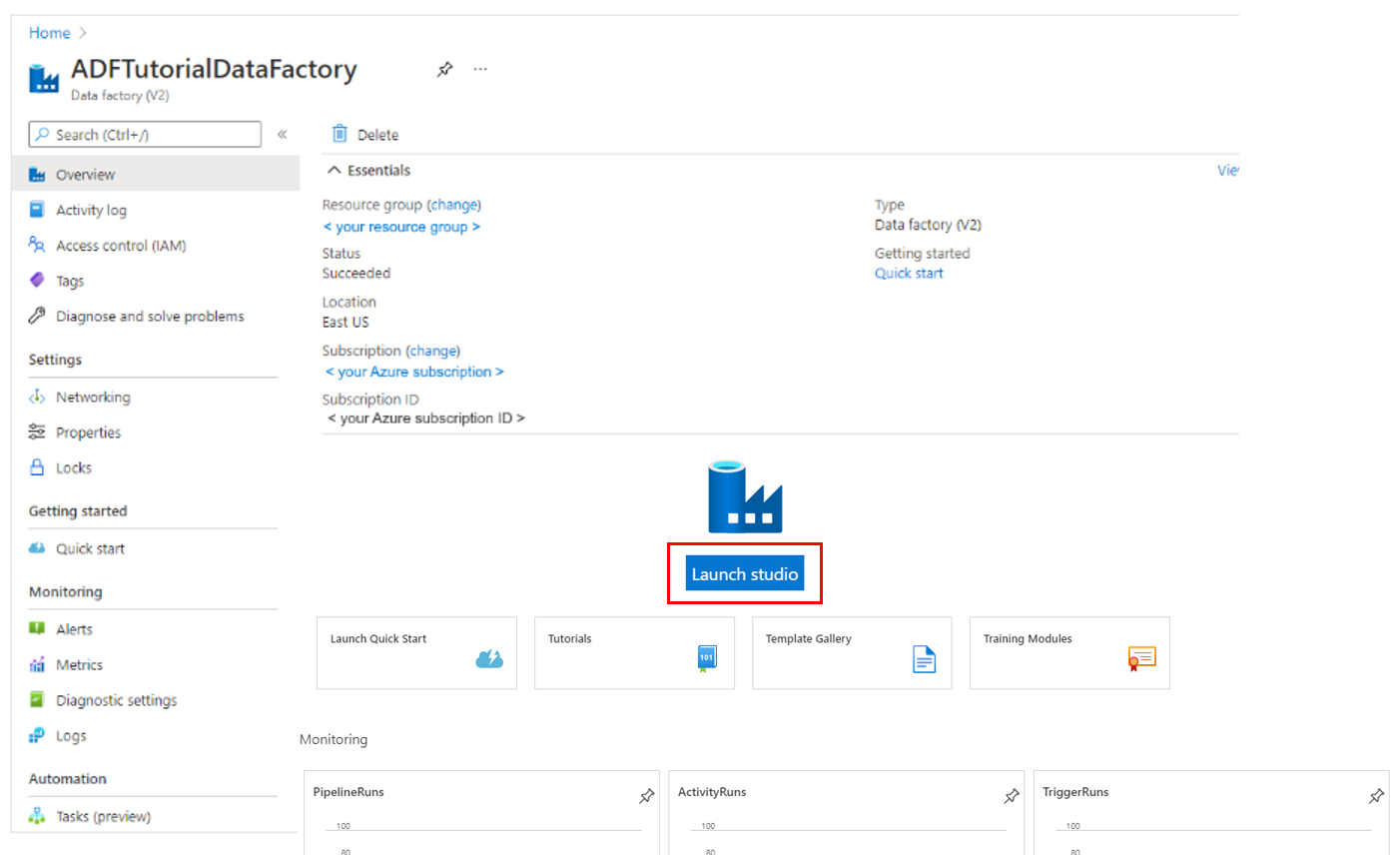
Wählen Sie Überprüfen und erstellen und nach erfolgreicher Prüfung Erstellen aus. Wählen Sie nach der Erstellung Zu Ressource wechseln aus, um zur Seite Data Factory zu navigieren.
Wählen Sie Studio starten aus, um Azure Data Factory Studio zu öffnen und die Anwendung für die Azure Data Factory-Benutzeroberfläche (User Interface, UI) auf einer separaten Registerkarte des Browsers zu starten.
Hinweis
Falls der Webbrowser bei „Autorisierung läuft“ hängt, sollten Sie das Kontrollkästchen Cookies und Websitedaten von Drittanbietern blockieren deaktivieren. Alternativ können Sie die Aktivierung beibehalten, eine Ausnahme für login.microsoftonline.com erstellen und dann erneut versuchen, die App zu öffnen.
Zugehöriger Inhalt
Erfahren Sie im Tutorial Kopieren von Daten aus Azure Blob Storage in eine Datenbank in Azure SQL-Datenbank mithilfe von Azure Data Factory, wie Sie mit Azure Data Factory Daten von einem Speicherort an einen anderen kopieren. Erfahren Sie, wie Sie mit Azure Data Factory einen Datenfluss erstellen[data-flow-create.md].