Indizieren von Daten von SharePoint-Dokumentbibliotheken aus
Wichtig
SharePoint Online-Indexerunterstützung befindet sich in der öffentlichen Vorschauphase. Er wird in der vorliegenden Form gemäß den Zusätzlichen Nutzungsbedingungen angeboten und nur nach besten Bemühungen unterstützt. Vorschaufeatures werden für Produktionsworkloads nicht empfohlen und es wird nicht garantiert, dass sie allgemein verfügbar sein werden.
Lesen Sie unbedingt den Abschnitt Bekannte Einschränkungen, bevor Sie beginnen.
Um diese Vorschau zu verwenden, füllen Sie dieses Formular aus. Sie erhalten keine Benachrichtigung über die Genehmigung, da jede Zugriffsanforderung nach der Übermittlung automatisch angenommen wird. Nachdem der Zugriff aktiviert ist, verwenden Sie eine Vorschau-REST-API (2023-10-01-Preview oder höher), um Ihre Inhalte zu indizieren.
In diesem Artikel wird erläutert, wie Sie einen Suchindexer zum Indizieren von Dokumenten, die in SharePoint-Dokumentbibliotheken gespeichert sind, für die Volltextsuche in Azure KI Search konfigurieren. Zuerst kommen die Konfigurationsschritte, gefolgt von Verhalten und Szenarien.
Funktionalität
Ein Indexer in Azure KI Search ist ein Crawler, der durchsuchbare Daten und Metadaten aus einer Datenquelle extrahiert. Der SharePoint Online-Indexer stellt eine Verbindung mit Ihrer SharePoint-Site her und indiziert Dokumente aus einer oder mehreren Dokumentbibliotheken. Der Indexer bietet die folgenden Funktionen:
- Indizieren von Dateien und Metadaten aus einer oder mehreren Dokumentbibliotheken.
- Inkrementelles Indizieren, wobei nur die neuen und geänderten Dateien und Metadaten aufgenommen werden.
- Die Löscherkennung ist integriert. Das Löschen in einer Dokumentbibliothek wird bei der nächsten Indexerausführung aufgenommen, und das Dokument wird aus dem Index entfernt.
- Text und normalisierte Bilder werden standardmäßig aus den indizierten Dokumenten extrahiert. Optional können Sie ein Skillset für eine tiefere KI-Anreicherung hinzufügen, z. B. OCR oder Textübersetzung.
Voraussetzungen
SharePoint im Microsoft 365-Clouddienst
Dateien in einer Dokumentbibliothek
Unterstützte Dokumentformate
Der SharePoint Online-Indexer kann Text aus den folgenden Dokumentformaten extrahieren:
- CSV (siehe Indizierung von CSV-Blobs)
- EML
- EPUB
- GZ
- HTML
- JSON (Siehe Indizierung von JSON-Blobs)
- KML (XML für geografische Darstellungen)
- Microsoft Office-Formate: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (Outlook-E-Mails), XML (WORD XML 2003 und 2006)
- Öffnen von Dokumentformaten: ODT, ODS, ODP
- Textdateien (Siehe auch Indizierung von Nur-Text)
- RTF
- XML
- ZIP
Einschränkungen und Aspekte
Hier sind die Einschränkungen für dieses Feature:
Das Indizieren von SharePoint-Listen wird nicht unterstützt.
Das Indizieren von SharePoint .ASPX-Siteinhalten wird nicht unterstützt.
OneNote-Notizbuchdateien werden nicht unterstützt.
Privater Endpunkt wird nicht unterstützt.
Das Umbenennen eines SharePoint-Ordners löst keine inkrementelle Indizierung aus. Ein umbenannter Ordner wird als neuer Inhalt behandelt.
SharePoint unterstützt ein detailliertes Autorisierungsmodell, das den benutzerspezifischen Zugriff auf Dokumentebene bestimmt. Der Indexer übernimmt diese Berechtigungen nicht in den Index, und die Azure KI-Suche unterstützt keine Autorisierung auf Dokumentebene. Wenn ein Dokument von SharePoint in einen Suchdienst indiziert wird, steht der Inhalt allen Benutzern zur Verfügung, die über Lesezugriff auf den Index verfügen. Wenn Sie Berechtigungen auf Dokumentebene benötigen, sollten Sie Sicherheitsfilter zum Kürzen der Ergebnisse und die Automatisierung des Kopierens der Berechtigungen auf Dateiebene in ein Feld im Index in Erwägung ziehen.
Das Indizieren von benutzerverschlüsselten Dateien, IRM-geschützten Dateien (Information Rights Management), ZIP-Dateien mit Kennwörtern oder ähnlichen verschlüsselten Inhalten wird nicht unterstützt. Damit verschlüsselte Inhalte verarbeitet werden können, muss der Benutzer mit den entsprechenden Berechtigungen für die spezifische Datei die Verschlüsselung entfernen, damit das Element entsprechend indiziert werden kann, wenn der Indexer die nächste geplante Iteration ausführt.
Hier sind wichtige Überlegungen beim Verwenden dieses Features:
- Wenn Sie eine SharePoint-Inhaltsindizierungslösung in einer Produktionsumgebung benötigen, sollten Sie einen benutzerdefinierten Connector mit SharePoint-Webhooks erstellen, der die Microsoft Graph-API aufruft, um die Daten in einen Azure Blob-Container zu exportieren, und dann den Azure Blob Indexer für die inkrementelle Indizierung verwenden.
- Wenn Ihre SharePoint-Konfiguration es Microsoft 365-Prozessen ermöglicht, SharePoint-Dateisystemmetadaten zu aktualisieren, dann sollten Sie beachten, dass diese Aktualisierungen den SharePoint Online-Indexer auslösen können, wodurch der Indexer Dokumente mehrmals erfasst. Da der SharePoint Online-Indexer ein Drittanbieterconnector für Azure ist, kann der Indexer die Konfiguration nicht lesen und ihr Verhalten nicht anpassen. Er reagiert auf Änderungen in neuen und geänderten Inhalten, unabhängig davon, wie diese Aktualisierungen vorgenommen werden. Stellen Sie deshalb sicher, dass Sie Ihre Einrichtung testen und die Dokumentverarbeitungsanzahl verstehen, bevor Sie den Indexer und eine KI-Anreicherung verwenden.
Konfigurieren des SharePoint Online-Indexers
Um den SharePoint Online-Indexer einzurichten, verwenden Sie das Azure-Portal sowie eine Vorschau-REST-API.
Dieser Abschnitt enthält die Schritte. Sie können sich auch das folgende Video ansehen.
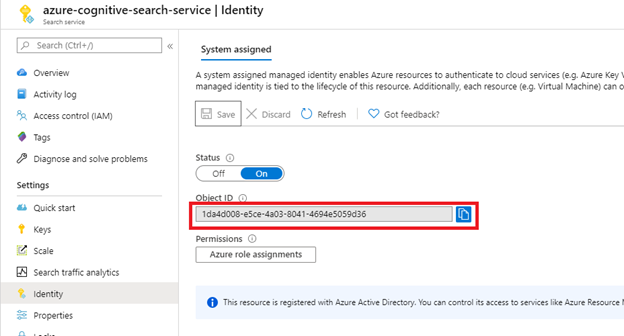
Schritt 1 (optional): Aktivieren einer systemseitig zugewiesenen verwalteten Identität
Aktivieren Sie eine systemseitig zugewiesene verwaltete Identität, um den Mandanten, in dem der Suchdienst bereitgestellt wird, automatisch zu erkennen.
Führen Sie diesen Schritt aus, wenn sich die SharePoint-Site im gleichen Mandanten wie der Suchdienst befindet. Überspringen Sie diesen Schritt, wenn sich die SharePoint-Site in einem anderen Mandanten befindet. Die Identität wird nicht für die Indizierung verwendet, nur für die Mandantenerkennung. Sie können diesen Schritt auch überspringen, wenn Sie die Mandanten-ID in die Verbindungszeichenfolge einfügen möchten.

Nach dem Auswählen von Speichern erhalten Sie eine Objekt-ID, die dem Suchdienst zugewiesen wurde.
Schritt 2: Entscheiden, welche Berechtigungen der Indexer benötigt
Der SharePoint Online-Indexer unterstützt sowohl delegierte Berechtigungen als auch Anwendungsberechtigungen. Wählen Sie basierend auf Ihrem Szenario aus, welche Berechtigungen Sie verwenden möchten.
Wir empfehlen anwendungsbasierte Berechtigungen. Informationen zu bekannten Problemen bezüglich delegierten Berechtigungen finden Sie unter Einschränkungen.
Bei Anwendungsberechtigungen (empfohlen) wird der Indexer unter der Identität des SharePoint-Mandanten ausgeführt und hat Zugriff auf alle Sites und Dateien. Für den Indexer ist ein geheimer Clientschlüssel erforderlich. Der Indexer erfordert auch die Genehmigung des Mandantenadministrators, bevor er Inhalte indizieren kann.
Mit delegierten Berechtigungen wird der Indexer unter der Identität der Benutzer oder Apps ausgeführt, die die Anforderung senden. Der Datenzugriff ist auf die Sites und Dateien beschränkt, auf die die aufrufende Funktion Zugriff hat. Um delegierte Berechtigungen zu unterstützen, benötigt der Indexer eine Gerätecodeaufforderung, um sich im Namen des Benutzers anzumelden. Benutzerdelegierte Berechtigungen erzwingen den Tokenablauf alle 75 Minuten gemäß den neuesten Sicherheitsbibliotheken, die zum Implementieren dieses Authentifizierungstyps verwendet werden. Das ist kein Verhalten, das angepasst werden kann. Für ein abgelaufenes Token ist eine manuelle Indizierung mit Indexer ausführen (Vorschau) erforderlich. Daher könnte es besser sein, stattdessen anwendungsbasierte Berechtigungen zu verwenden.
Wenn in Ihrer Microsoft Entra-Organisation der bedingte Zugriff aktiviert ist und Ihr Administrator keinen Gerätezugriff für delegierte Berechtigungen gewähren kann, sollten Sie stattdessen anwendungsbasierte Berechtigungen in Betracht ziehen. Weitere Informationen finden Sie unter Microsoft Entra Richtlinien für den bedingten Zugriff.
Schritt 3: Erstellen einer Microsoft Entra-Anwendungsregistrierung
Der SharePoint Online-Indexer verwendet diese Microsoft Entra-Anwendung für die Authentifizierung.
Melden Sie sich beim Azure-Portal an.
Suche Sie Microsoft Entra ID, bzw. navigieren Sie dorthin, und wählen Sie dann App-Registrierungen aus.
Wählen Sie + Neue Registrierung aus:
- Geben Sie einen Namen für Ihre App an.
- Wählen Sie Einzelner Mandant aus.
- Überspringen Sie den Schritt für die URI-Bezeichnung. Es ist kein Umleitungs-URI erforderlich.
- Wählen Sie Registrieren aus.
Wählen Sie auf der linken Seite API-Berechtigungen aus, anschließend Berechtigung hinzufügen und dann Microsoft Graph.
Wenn der Indexer Anwendungs-API-Berechtigungen verwendet, wählen Sie Anwendungsprogrammierschnittstelle aus und fügen Sie Folgendes hinzu:
- Anwendung: Files.Read.All
- Anwendung: Sites.Read.All

Bei der Verwendung von Anwendungsberechtigungen greift der Indexer in einem Dienstkontext auf die SharePoint-Site zu. Wenn Sie also den Indexer ausführen, hat er Zugriff auf alle Inhalte im SharePoint-Mandanten, wofür die Genehmigung des Mandantenadministrators erforderlich ist. Für die Authentifizierung ist auch ein geheimer Clientschlüssel erforderlich. Das Einrichten des geheimen Clientschlüssels wird weiter unten in diesem Artikel beschrieben.
Wenn der Indexer delegierte API-Berechtigungen verwendet, wählen Sie Delegierte Berechtigungen aus, und fügen Sie Folgendes hinzu:
- Delegiert – Files.Read.All
- Delegiert – Sites.Read.All
- Delegiert – User.Read
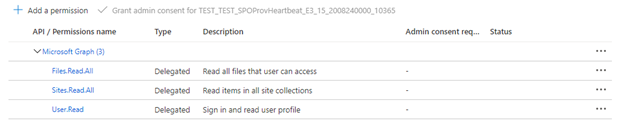
Delegierte Berechtigungen ermöglichen dem Suchclient, unter der Sicherheitsidentität des aktuellen Benutzers eine Verbindung mit SharePoint herzustellen.
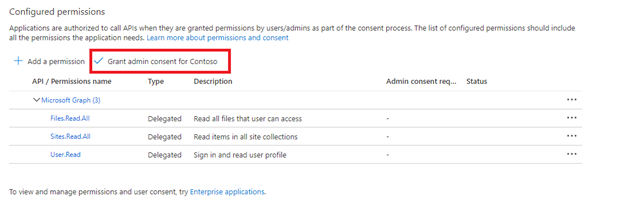
Erteilen Sie die Administratoreinwilligung.
Die Einwilligung des Mandantenadministrators ist erforderlich, wenn Anwendungs-API-Berechtigungen verwendet werden. In einigen Mandanten gibt es bestimmte Sperren, weswegen die Einwilligung des Mandantenadministrators auch bei diesen delegierten API-Berechtigungen erforderlich ist. Wenn eine dieser Bedingungen zutrifft, muss ein Mandantenadministrator die Genehmigung für diese Microsoft Entra-Anwendung erteilen, bevor Sie den Indexer erstellen.
Wählen Sie die Registerkarte Authentifizierung aus.
Legen Sie Öffentliche Clientflows zu lassen auf Ja fest, und wählen Sie dann Speichern aus.
Wählen Sie + Plattform hinzufügen und dann Mobilgerät- und Desktopanwendungen aus, aktivieren Sie
https://login.microsoftonline.com/common/oauth2/nativeclient, und klicken Sie auf Konfigurieren.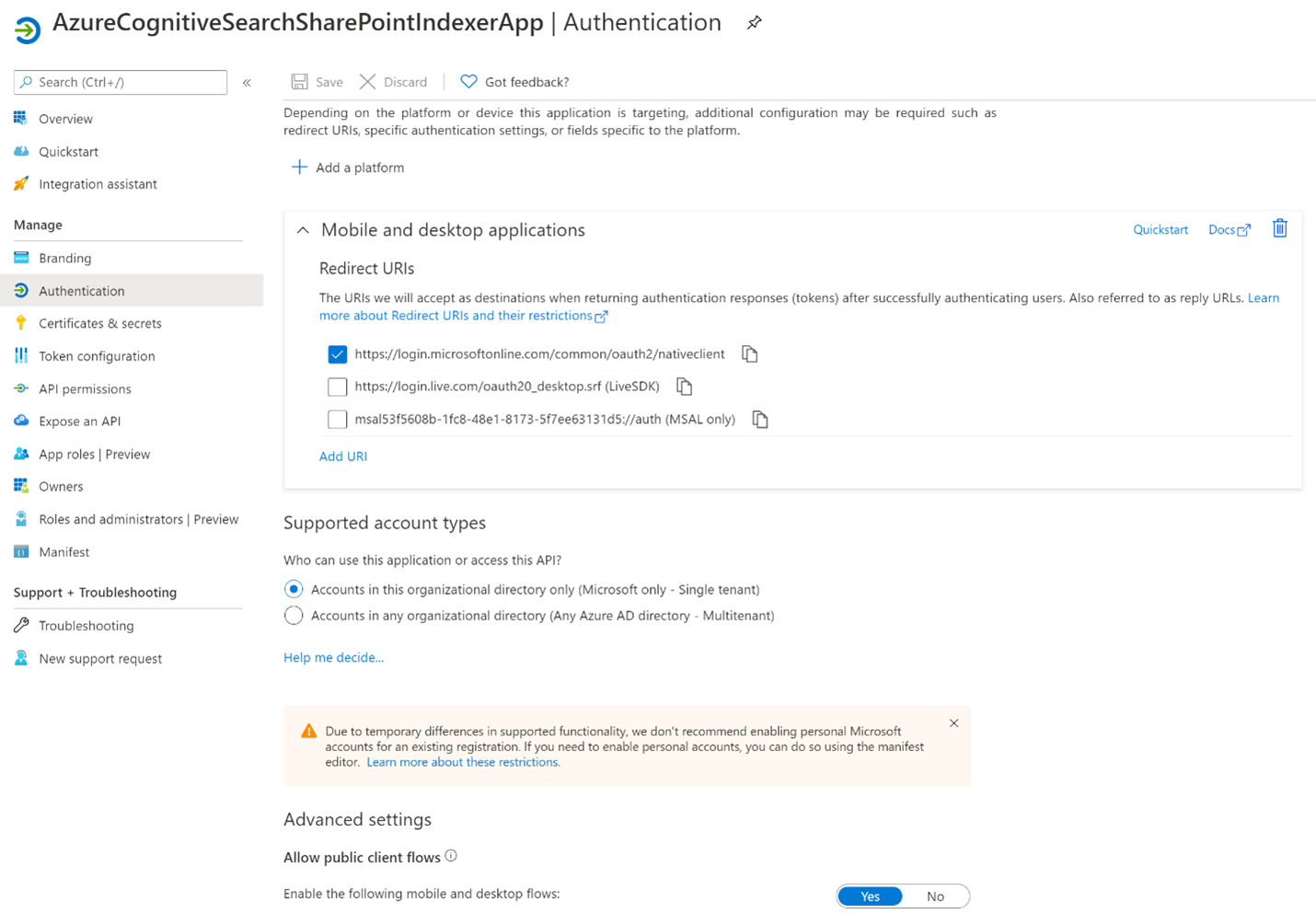
(Nur Anwendungs-API-Berechtigungen) Um sich mit Anwendungsberechtigungen bei der Microsoft Entra-Anwendung zu authentifizieren, benötigt der Indexer einen geheimen Clientschlüssel.
Wählen Sie im Menü auf der linken Seite die Option Zertifikate und Geheimnisse, dann Geheime Clientschlüssel und dann Neuer geheimer Clientschlüssel aus.

Geben Sie im daraufhin angezeigten Menü eine Beschreibung für den neuen geheimen Clientschlüssel ein. Passen Sie bei Bedarf das Ablaufdatum an. Wenn das Geheimnis abläuft, muss es neu erstellt werden, und der Indexer muss mit dem neuen Geheimnis aktualisiert werden.
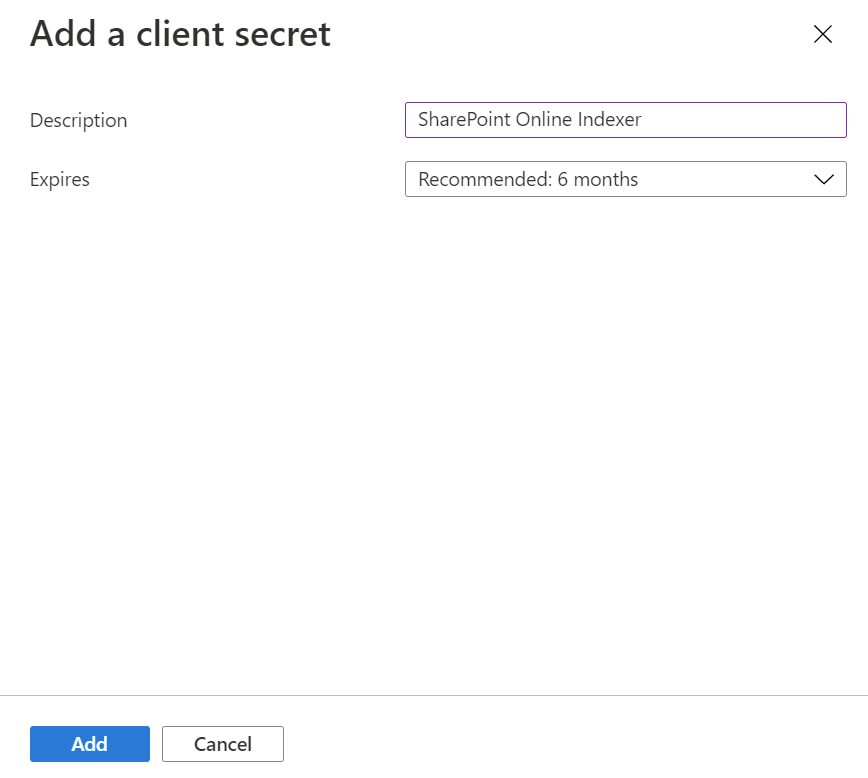
Der neue geheime Clientschlüssel wird in der Geheimnisliste angezeigt. Wenn Sie die Seite verlassen, ist das Geheimnis nicht mehr sichtbar. Kopieren Sie es also mithilfe der Schaltfläche „Kopieren“ und speichern Sie es an einem sicheren Ort.

Schritt 4: Erstellen einer Datenquelle
Wichtig
Ab diesem Abschnitt verwenden Sie die Vorschau-REST-API für die verbleibenden Schritte. Wir empfehlen die neueste Vorschau-API: 2023-10-01-preview. Sehen Sie sich diesen Schnellstart an, falls Sie nicht mit der REST-API für Azure KI Search vertraut sind.
Eine Datenquelle gibt an, welche Daten indiziert werden müssen, und legt zudem Anmeldeinformationen und Richtlinien fest, um Änderungen an den Daten effizient zu identifizieren (neue, geänderte oder gelöschte Zeilen). Eine Datenquelle kann von mehreren Indexern im selben Suchdienst verwendet werden.
Für die SharePoint-Indizierung muss die Datenquelle über die folgenden erforderlichen Eigenschaften verfügen:
- name ist der eindeutige Name der Datenquelle im Suchdienst.
- type muss „sharepoint“ sein. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet.
- credentials geben den SharePoint-Endpunkt und die ID der Microsoft Entra-Anwendung (Client) an. Ein Beispiel für einen SharePoint-Endpunkt ist
https://microsoft.sharepoint.com/teams/MySharePointSite. Den Endpunkt erhalten Sie, indem Sie zur Startseite Ihrer SharePoint-Website navigieren und die URL aus dem Browser kopieren. - container gibt an, welche Dokumentbibliothek indiziert werden soll. Eigenschaften steuern, welche Dokumente indiziert werden.
Um eine Datenquelle zu erstellen, rufen Sie Datenquelle erstellen (Vorschau) auf.
POST https://[service name].search.windows.net/datasources?api-version=2023-10-01-Preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-datasource",
"type" : "sharepoint",
"credentials" : { "connectionString" : "[connection-string]" },
"container" : { "name" : "defaultSiteLibrary", "query" : null }
}
Format der Verbindungszeichenfolge
Das Format der Verbindungszeichenfolge ändert sich je nachdem ob der Indexer delegierte API-Berechtigungen oder Anwendungs-API-Berechtigungen verwendet.
Verbindungszeichenfolgenformat für delegierte API-Berechtigungen
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];TenantId=[SharePoint site tenant id]Verbindungszeichenfolgenformat für Anwendungs-API-Berechtigungen
SharePointOnlineEndpoint=[SharePoint site url];ApplicationId=[Azure AD App ID];ApplicationSecret=[Azure AD App client secret];TenantId=[SharePoint site tenant id]
Hinweis
Wenn sich die SharePoint-Website im selben Mandanten wie der Suchdienst befindet und die systemseitig zugewiesene verwaltete Identität aktiviert ist, muss TenantId nicht in die Verbindungszeichenfolge eingeschlossen werden. Wenn sich die SharePoint-Website in einem anderen Mandanten als der Suchdienst befindet, muss TenantId eingeschlossen werden.
Schritt 5: Erstellen eines Index
Mit dem Index werden die Felder in einem Dokument, Attribute und andere Konstrukte für die Suchoberfläche angegeben.
Um einen Index zu erstellen, rufen Sie Index erstellen (Vorschau) auf:
POST https://[service name].search.windows.net/indexes?api-version=2023-10-01-Preview
Content-Type: application/json
api-key: [admin key]
{
"name" : "sharepoint-index",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "metadata_spo_item_name", "type": "Edm.String", "key": false, "searchable": true, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_path", "type": "Edm.String", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "metadata_spo_item_content_type", "type": "Edm.String", "key": false, "searchable": false, "filterable": true, "sortable": false, "facetable": true },
{ "name": "metadata_spo_item_last_modified", "type": "Edm.DateTimeOffset", "key": false, "searchable": false, "filterable": false, "sortable": true, "facetable": false },
{ "name": "metadata_spo_item_size", "type": "Edm.Int64", "key": false, "searchable": false, "filterable": false, "sortable": false, "facetable": false },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "sortable": false, "facetable": false }
]
}
Wichtig
Nur metadata_spo_site_library_item_id kann als Schlüsselfeld in einem vom SharePoint Online-Indexer erstellten Index verwendet werden. Wenn ein Schlüsselfeld in der Datenquelle nicht vorhanden ist, wird metadata_spo_site_library_item_id automatisch dem Schlüsselfeld zugeordnet.
Schritt 6: Erstellen eines Indexers
Ein Indexer verbindet eine Datenquelle mit einem Zielsuchindex und stellt einen Zeitplan zur Automatisierung der Datenaktualisierung bereit. Nachdem der Index und die Datenquelle erstellt wurden, können Sie den Indexer erstellen.
In diesem Schritt werden Sie aufgefordert, sich mit den Anmeldeinformationen für die Organisation anzumelden, die Zugriff auf die SharePoint-Site gewähren. Erstellen Sie nach Möglichkeit ein neues Organisationsbenutzerkonto, und weisen Sie diesem neuen Benutzer die genauen Berechtigungen zu, die der Indexer besitzen soll.
Zum Erstellen des Indexers führen Sie die folgenden Schritte aus:
Senden Sie die Anforderung Indexer erstellen (Vorschau):
POST https://[service name].search.windows.net/indexers?api-version=2023-10-01-Preview Content-Type: application/json api-key: [admin key] { "name" : "sharepoint-indexer", "dataSourceName" : "sharepoint-datasource", "targetIndexName" : "sharepoint-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpg", "dataToExtract": "contentAndMetadata" } }, "schedule" : { }, "fieldMappings" : [ { "sourceFieldName" : "metadata_spo_site_library_item_id", "targetFieldName" : "id", "mappingFunction" : { "name" : "base64Encode" } } ] }Wenn Sie den Indexer erstmals erstellen, wartet die Anforderung Indexer erstellen (Vorschau), bis Sie den nächsten Schritt abgeschlossen haben. Sie müssen Indexer-Status abrufen aufrufen, um den Link zu erhalten und den neuen Gerätecode einzugeben.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2023-10-01-Preview Content-Type: application/json api-key: [admin key]Wenn Sie nicht innerhalb von 10 Minuten Indexer-Status abrufen ausführen, läuft der Code ab, und Sie müssen die Datenquelle neu erstellen.
Kopieren Sie den Geräteanmeldecode aus der Antwort von Indexer-Status abrufen. Die Geräteanmeldung finden Sie in der „errorMessage“.
{ "lastResult": { "status": "transientFailure", "errorMessage": "To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code <CODE> to authenticate." } }Geben Sie den in der Fehlermeldung angezeigten Code an.
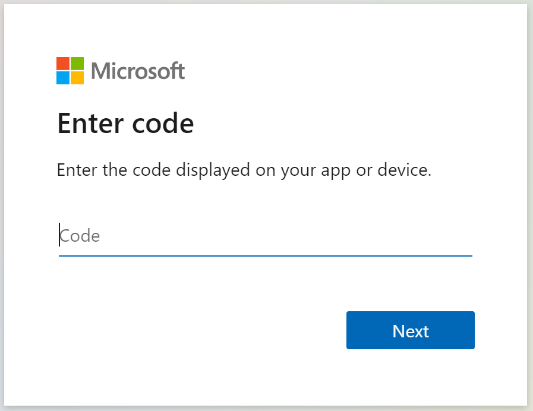
Der SharePoint Online-Indexer greift als der angemeldeter Benutzer auf den SharePoint-Inhalt zu. Der Benutzer, der sich in diesem Schritt anmeldet, ist der angemeldete Benutzer. Wenn Sie sich also mit einem Benutzerkonto anmelden, das keinen Zugriff auf ein Dokument in der Dokumentbibliothek hat, das Sie indizieren möchten, hat der Indexer keinen Zugriff auf dieses Dokument.
Erstellen Sie nach Möglichkeit ein neues Benutzerkonto, und weisen Sie diesem neuen Benutzer die genauen Berechtigungen zu, die der Indexer besitzen soll.
Genehmigen Sie die angeforderten Berechtigungen.
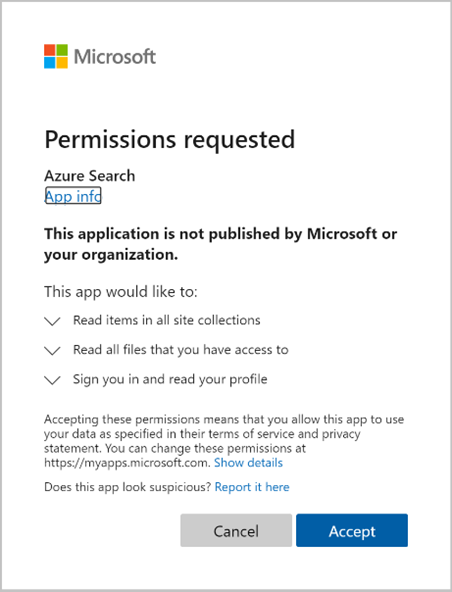
Die anfängliche Anforderung Indexer erstellen (Vorschau) wird abgeschlossen, wenn alle oben angegebenen Berechtigungen korrekt sind und sich im zehnminütigen Zeitfenster befinden.
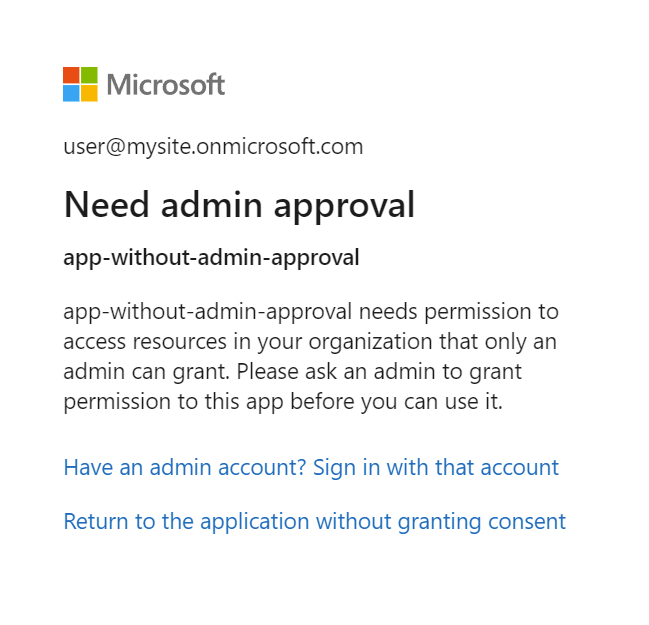
Hinweis
Wenn die Microsoft Entra-Anwendung eine Administratorgenehmigung erfordert und vor dem Anmelden nicht genehmigt wurde, wird möglicherweise der folgende Bildschirm angezeigt. Zum Fortsetzen ist eine Administratorgenehmigung erforderlich.
Schritt 7: Überprüfen des Indexerstatus
Nachdem der Indexer erstellt wurde, können Sie den Indexerstatus aufrufen:
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2023-10-01-Preview
Content-Type: application/json
api-key: [admin key]
Aktualisieren der Datenquelle
Wenn keine Aktualisierungen des Datenquellenobjekts vorliegen, wird der Indexer ohne Benutzerinteraktion nach einem Zeitplan ausgeführt.
Doch wenn Sie das Datenquellenobjekt ändern, während der Gerätecode abgelaufen ist, müssen Sie sich erneut anmelden, damit der Indexer ausgeführt wird. Wenn Sie z. B. die Datenquellenabfrage ändern, melden Sie sich erneut unter https://microsoft.com/devicelogin an und rufen Sie den neuen Gerätecode ab.
Hier sind die Schritte zum Aktualisieren einer Datenquelle, wenn der Gerätecode abgelaufen ist:
Rufen Sie Indexer ausführen (Vorschau) auf, um die Indexerausführung manuell zu starten.
POST https://[service name].search.windows.net/indexers/sharepoint-indexer/run?api-version=2023-10-01-Preview Content-Type: application/json api-key: [admin key]Überprüfen Sie den Indexerstatus.
GET https://[service name].search.windows.net/indexers/sharepoint-indexer/status?api-version=2023-10-01-Preview Content-Type: application/json api-key: [admin key]Wenn eine Fehlermeldung angezeigt wird und Sie aufgefordert werden,
https://microsoft.com/deviceloginzu besuchen, öffnen Sie die Seite, und kopieren Sie den neuen Code.Fügen Sie den Code in das Dialogfeld ein.
Führen Sie den Indexer manuell erneut aus, und überprüfen Sie den Indexerstatus. Dieses Mal sollte die Indexerausführung erfolgreich gestartet werden.
Indizieren von Dokumentmetadaten
Wenn Sie Dokumentmetadaten ("dataToExtract": "contentAndMetadata") indizieren, können Sie die folgenden Metadaten indizieren.
| Bezeichner | type | Beschreibung |
|---|---|---|
| metadata_spo_site_library_item_id | Edm.String | Der kombinierte Schlüssel aus Site-ID, Bibliotheks-ID und Element-ID, der ein Element in einer Dokumentbibliothek für eine Site eindeutig identifiziert. |
| metadata_spo_site_id | Edm.String | Die ID der SharePoint-Website. |
| metadata_spo_library_id | Edm.String | Die ID der Dokumentbibliothek. |
| metadata_spo_item_id | Edm.String | Die ID des Elements bzw. Dokumentelements in der Bibliothek. |
| metadata_spo_item_last_modified | Edm.DateTimeOffset | Das Datum/die Uhrzeit (UTC) der letzten Änderung des Elements. |
| metadata_spo_item_name | Edm.String | Name des Elements. |
| metadata_spo_item_size | Edm.Int64 | Die Größe (in Bytes) des Elements. |
| metadata_spo_item_content_type | Edm.String | Der Inhaltstyp des Elements. |
| metadata_spo_item_extension | Edm.String | Die Erweiterung des Elements. |
| metadata_spo_item_weburi | Edm.String | Der URI des Elements. |
| metadata_spo_item_path | Edm.String | Die Kombination aus dem übergeordneten Pfad und dem Elementnamen. |
Der SharePoint Online-Indexer unterstützt auch spezifische Metadaten für die einzelnen Dokumenttypen. Weitere Informationen finden Sie unter Metadateneigenschaften von Inhalten, die in Azure KI Search verwendet werden.
Hinweis
Zum Indizieren benutzerdefinierter Metadaten muss „additionalColumns“ im Abfrageparameter der Datenquelle angegeben werden.
Ein- oder Ausschließen nach Dateityp
Sie können steuern, welche Dateien indiziert werden, indem Sie Einschluss- und Ausschlusskriterien im Abschnitt „parameters“ der Indexerdefinition festlegen.
Schließen Sie bestimmte Dateierweiterungen ein, indem Sie für "indexedFileNameExtensions" eine durch Komma getrennte Liste von Dateierweiterungen (mit einem führenden Punkt) festlegen. Schließen Sie bestimmte Dateierweiterungen aus, indem Sie für "excludedFileNameExtensions" die Erweiterungen festlegen, die übersprungen werden sollen. Wenn die gleiche Erweiterung in beiden Listen vorhanden ist, wird sie von der Indizierung ausgeschlossen.
PUT /indexers/[indexer name]?api-version=2020-06-30
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
Steuern der indizierten Dokumente
Ein einzelner SharePoint Online-Indexer kann Inhalte aus einer oder mehreren Dokumentbibliotheken indizieren. Verwenden Sie den Parameter „container“ in der Datenquellendefinition, um anzugeben, von welcher Site und welchen Dokumentbibliotheken aus indiziert werden soll.
Der Datenquellenabschnitt „container“ bietet zwei Eigenschaften für diese Aufgabe: „name“ und „query“.
Name
Die name-Eigenschaft ist erforderlich und muss einen der folgenden drei Werte aufweisen:
| Wert | Beschreibung |
|---|---|
| defaultSiteLibrary | Indiziert den gesamten Inhalt der Standarddokumentbibliothek der Website. |
| allSiteLibraries | Indiziert den gesamten Inhalt aller Dokumentbibliotheken einer Website. Dokumentbibliotheken aus einer Unterwebsite liegen außerhalb des Geltungsbereichs. Wenn Sie Inhalte von Unterwebsites benötigen, wählen Sie „useQuery“ aus, und geben Sie „includeLibrariesInSite“ an. |
| useQuery | Indiziert nur den in der „Abfrage“ definierten Inhalt. |
Abfrage
Der query-Parameter der Datenquelle besteht aus Schlüsselwort-Wert-Paaren. Die unten aufgeführten Schlüsselwörter können verwendet werden. Die Werte sind entweder Website-URLs oder Dokumentbibliothek-URLs.
Hinweis
Um den Wert für ein bestimmtes Schlüsselwort zu ermitteln, sollten Sie zu der Dokumentbibliothek navigieren, die Sie ein- bzw. ausschließen möchten, und den URI aus dem Browser kopieren. Dies ist die einfachste Möglichkeit, um den Wert zur Verwendung mit einem Schlüsselwort in der Abfrage zu erhalten.
| Stichwort | Wertbeschreibung und Beispiele |
|---|---|
| NULL | Wenn der Wert NULL oder leer ist, werden je nach Containername entweder die Standarddokumentbibliothek oder alle Dokumentbibliotheken indiziert. Beispiel: "container" : { "name" : "defaultSiteLibrary", "query" : null } |
| includeLibrariesInSite | Indiziert die Inhalte aller Bibliotheken unter der angegebenen Website in der Verbindungszeichenfolge. Der Bereich umfasst alle Unterwebsites Ihrer Website. Der Wert sollte der URI der Website oder der Unterwebsite sein. Beispiel: "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/mysite" } |
| includeLibrary | Indiziert den gesamten Inhalt dieser Bibliothek. Der Wert ist der vollqualifizierte Pfad zur Bibliothek, der aus Ihrem Browser kopiert werden kann: Beispiel 1 (vollqualifizierter Pfad): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary" } Beispiel 2 (aus dem Browser kopierter URI): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| excludeLibrary | Schließt den Inhalt dieser Bibliothek von der Indizierung aus. Der Wert ist der vollqualifizierte Pfad zur Bibliothek, der aus Ihrem Browser kopiert werden kann: Beispiel 1 (vollqualifizierter Pfad): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mysite.sharepoint.com/subsite1; excludeLibrary=https://mysite.sharepoint.com/subsite1/MyDocumentLibrary" } Beispiel 2 (aus dem Browser kopierter URI): "container" : { "name" : "useQuery", "query" : "includeLibrariesInSite=https://mycompany.sharepoint.com/teams/mysite; excludeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx" } |
| additionalColumns | Indiziert Spalten aus der Dokumentbibliothek. Der Wert ist eine durch Trennzeichen getrennte Liste von Spaltennamen, die Sie indizieren möchten. Verwenden Sie einen doppelten umgekehrten Schrägstrich, um Semikolons und Kommas in Spaltennamen mit Escapezeichen zu versehen: Beispiel 1 (additionalColumns=MyCustomColumn,MyCustomColumn2): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/mysite/MyDocumentLibrary;additionalColumns=MyCustomColumn,MyCustomColumn2" } Beispiel 2 (Escapezeichen mit doppeltem umgekehrtem Schrägstrich): "container" : { "name" : "useQuery", "query" : "includeLibrary=https://mycompany.sharepoint.com/teams/mysite/MyDocumentLibrary/Forms/AllItems.aspx;additionalColumns=MyCustomColumnWith\\,,MyCustomColumnWith\\;" } |
Behandeln von Fehlern
Der SharePoint Online-Indexer wird standardmäßig beendet, sobald er auf ein Dokument mit einem nicht unterstützten Inhaltstyp trifft (z. B. ein Bild). Sie können mithilfe des Parameters excludedFileNameExtensions bestimmte Inhaltstypen überspringen. Allerdings müssen Sie möglicherweise Dokumente indizieren, ohne im Voraus alle möglichen Inhaltstypen zu kennen. Um die Indizierung bei einem nicht unterstützten Inhaltstyp fortzusetzen, setzen Sie den Konfigurationsparameter failOnUnsupportedContentType auf FALSE:
PUT https://[service name].search.windows.net/indexers/[indexer name]?api-version=2023-10-01-Preview
Content-Type: application/json
api-key: [admin key]
{
... other parts of indexer definition
"parameters" : { "configuration" : { "failOnUnsupportedContentType" : false } }
}
Es kann vorkommen, dass Azure KI Search den Inhaltstyp einiger Dokumenten nicht bestimmen oder ein Dokument mit einem eigentlich unterstützten Inhaltstyp nicht verarbeiten kann. Um diesen Fehlermodus zu ignorieren, legen Sie den Konfigurationsparameter failOnUnprocessableDocument auf FALSE fest:
"parameters" : { "configuration" : { "failOnUnprocessableDocument" : false } }
Azure KI Search beschränkt die Größe der indizierten Dokumente. Diese Grenzwerte werden in Grenzwerte für den Azure KI Search-Dienst dokumentiert. Zu große Dokumente werden standardmäßig als Fehler behandelt. Wenn Sie den Konfigurationsparameter indexStorageMetadataOnlyForOversizedDocuments auf TRUE setzen, können Sie Speichermetadaten von zu großen Dokumenten jedoch weiterhin indizieren:
"parameters" : { "configuration" : { "indexStorageMetadataOnlyForOversizedDocuments" : true } }
Sie können die Indizierung auch fortsetzen, wenn bei der Verarbeitung während der Analyse von Dokumenten oder beim Hinzufügen von Dokumenten zu einem Index Fehler auftreten. Um eine bestimmte Anzahl von Fehlern zu ignorieren, legen Sie die Konfigurationsparameter maxFailedItems und maxFailedItemsPerBatch auf die gewünschten Werte fest. Zum Beispiel:
{
... other parts of indexer definition
"parameters" : { "maxFailedItems" : 10, "maxFailedItemsPerBatch" : 10 }
}
Wenn für eine Datei auf der SharePoint-Site die Verschlüsselung aktiviert ist, kann eine Fehlermeldung wie die folgende angezeigt werden:
Code: resourceModified Message: The resource has changed since the caller last read it; usually an eTag mismatch Inner error: Code: irmEncryptFailedToFindProtector
Die Fehlermeldung enthält auch die SharePoint-Site-ID, die Laufwerk-ID und die Laufwerkelement-ID im folgenden Muster: <sharepoint site id> :: <drive id> :: <drive item id>. Diese Informationen können verwendet werden, um festzustellen, welches Element am SharePoint-Ende fehlschlägt. Der Benutzer kann dann die Verschlüsselung aus dem Element entfernen, um das Problem zu beheben.