Erstellen eines Vektorspeichers
In der Azure KI-Suche verfügt ein Vektorspeicher über ein Indexschema, das Vektor- und Nichtvektorfelder definiert, eine Vektorkonfiguration für Algorithmen, die den Einbettungsraum erstellen, und Einstellungen für Vektorfelddefinitionen, die in Abfrageanforderungen verwendet werden. Die API zum Erstellen eines Index erstellt den Vektorspeicher.
Führen Sie die folgenden Schritte aus, um Vektordaten zu indizieren:
- Definieren eines Schemas mit einer oder mehreren Vektorkonfigurationen, das Algorithmen für die Indizierung und Suche festlegt
- Hinzufügen von einem oder mehreren Vektorfeldern
- Laden Sie vorvektorisierte Daten in einem separaten Schritt oder verwenden Sie integrierte Vektorisierung (Vorschau) für Datenblockerstellung und -codierung während der Indizierung.
Dieser Artikel bezieht sich auf die allgemein verfügbare Version (keine Vorschauversion) der Vektorsuche, und es wird davon ausgegangen, dass Ihr Anwendungscode externe Ressourcen für die Datenblockerstellung und Codierung aufruft.
Hinweis
Suchen Sie nach einer Anleitung zur Migration ab 2023-07-01-preview? Weitere Informationen finden Sie unter Upgrade von REST-APIs.
Voraussetzungen
Azure AI Search, in jeder Region und auf jeder Ebene. Die meisten vorhandenen Dienste unterstützen die Vektorsuche. Für Dienste, die vor Januar 2019 erstellt wurden, gibt es eine kleine Teilmenge, die die Vektorsuche nicht unterstützen kann. Wenn ein Index, der Vektorfelder enthält, nicht erstellt oder aktualisiert werden kann, handelt es sich um einen Indikator. In dieser Situation muss ein neuer Dienst erstellt werden.
Bereits vorhandene Vektoreinbettungen in Ihren Quelldokumenten. Die Azure KI-SDK generiert keine Vektoren in der allgemein verfügbaren Version der Azure SDKs und REST-APIs. Wir empfehlen Azure OpenAI-Einbettungsmodelle, aber Sie können ein beliebiges Modell für die Vektorisierung verwenden. Weitere Informationen finden Sie im Artikel zum Generieren von Einbettungen.
Sie sollten die Größeneinschränkung des Modells kennen, das zum Erstellen der Einbettungen und zur Berechnung der Ähnlichkeit verwendet wird. In Azure OpenAI beträgt die Länge des numerischen Vektors 1536 für text-embedding-ada-002. Ähnlichkeit wird mithilfe von
cosineberechnet. Gültige Werte sind 2 bis 3072 Dimensionen.Sie sollten mit der Erstellung eines Index vertraut sein. Das Schema muss ein Feld für den Dokumentschlüssel, andere Felder, die Sie durchsuchen oder filtern möchten, und weitere Konfigurationen für Verhaltensweisen enthalten, die während der Indizierung und Abfragen erforderlich sind.
Vorbereiten von Dokumenten für die Indizierung
Erstellen Sie vor der Indizierung eine Dokumentnutzlast, die Felder mit Vektor- und Nicht-Vektordaten enthält. Die Dokumentstruktur muss dem Indexschema entsprechen.
Stellen Sie für Ihre Dokumente Folgendes sicher:
Sie enthalten ein Feld oder eine Metadateneigenschaft, die jedes Dokument eindeutig identifiziert. Für alle Suchindizes ist ein Dokumentschlüssel erforderlich. Um die Anforderungen des Dokumentschlüssels zu erfüllen, muss ein Quelldokument über ein Feld oder eine Eigenschaft verfügen, mit dem bzw. der es im Index eindeutig identifiziert werden kann. Dieses Quellfeld muss einem Indexfeld vom Typ
Edm.Stringundkey=trueim Suchindex zugeordnet werden.Sie enthalten Vektordaten (ein Array von Gleitkommazahlen mit einfacher Genauigkeit) in Quellfeldern.
Vektorfelder enthalten numerische Daten, die durch Einbettungsmodelle generiert werden (eine Einbettung pro Feld). Wir empfehlen die Einbettungsmodelle in Azure OpenAI (z. B. text-embedding-ada-002) für Textdokumente bzw. die Bildabruf-REST-API für Bilder. Es werden nur Index-Vektorfelder der obersten Ebene unterstützt: Untergeordnete Vektorfelder werden derzeit nicht unterstützt.
Sie enthalten weitere Felder mit von Menschen lesbaren alphanumerischen Inhalten für die Abfrageantwort und für Hybridabfrageszenarien, die Volltextsuche oder semantische Rangfolge in derselben Anforderung enthalten.
Ihr Suchindex sollte Felder und Inhalte für alle Abfrageszenarien enthalten, die Sie unterstützen möchten. Angenommen, Sie möchten nach Produktnamen, Versionen, Metadaten oder Adressen suchen oder filtern. In diesem Fall ist die Ähnlichkeitssuche nicht besonders hilfreich. Schlüsselwortsuche, Geosuche oder Filter wären eine bessere Wahl. Ein Suchindex, der eine umfassende Feldauflistung von Vektor- und Nicht-Vektordaten enthält, bietet maximale Flexibilität für die Abfrageerstellung und Antwortkomposition.
Ein kurzes Beispiel für eine Dokumentnutzlast, die Vektor- und Nicht-Vektorfelder enthält, finden Sie im Abschnitt Laden von Vektordaten dieses Artikels.
Hinzufügen einer Vektorsuchkonfiguration
Eine Vektorkonfiguration gibt den Vektorsuchalgorithmus und Parameter an, die während der Indizierung zum Erstellen von Informationen zum „nächsten Nachbarn“ (Nearest Neighbor) zwischen den Vektorknoten verwendet werden:
- Hierarchical Navigable Small World (HNSW)
- Umfassende KNN
Wenn Sie HNSW für ein Feld auswählen, können Sie sich zur Abfragezeit für umfassende KNN entscheiden. Anders herum funktioniert es jedoch nicht: Wenn Sie umfassende KNN wählen, können Sie später keine HNSW-Suche anfordern, da die zusätzlichen Datenstrukturen, die die ungefähre Suche ermöglichen, nicht vorhanden sind.
Suchen Sie nach einer Anleitung für die Migration von der Vorschau zur stabilen Version? Weitere Informationen für Schritte finden Sie unter Upgrade von REST-APIs.
REST-API-Version 2023-11-01- unterstützt eine Vektorkonfiguration mit Folgendem:
vectorSearch-Algorithmen,hnswundexhaustiveKnnnächsten Nachbarn mit Parametern für die Indizierung und Bewertung.vectorProfilesfür mehrere Kombinationen von Algorithmuskonfigurationen.
Stellen Sie sicher, dass Sie eine Strategie für die Vektorisierung Ihrer Inhalte haben. Die stabile Version bietet keine Vektorisierung für die integrierte Einbettung.
Verwenden Sie die API zum Erstellen oder Aktualisieren von Indizes, um den Index zu erstellen.
Fügen Sie den Abschnitt
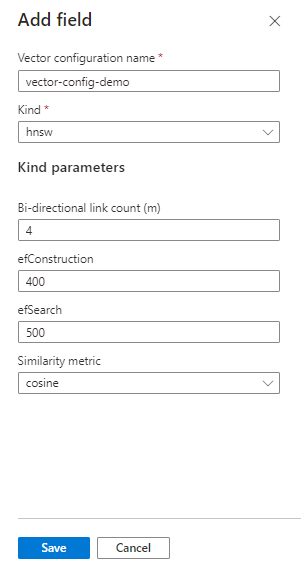
vectorSearchim Index hinzu, der die Suchalgorithmen angibt, mit denen der Einbettungsraum erstellt wird."vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } }, { "name": "my-hnsw-config-2", "kind": "hnsw", "hnswParameters": { "m": 8, "efConstruction": 800, "efSearch": 800, "metric": "cosine" } }, { "name": "my-eknn-config", "kind": "exhaustiveKnn", "exhaustiveKnnParameters": { "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-2" } ] }Die wichtigsten Punkte:
- Name der Konfiguration. Der Name muss innerhalb des Index eindeutig sein.
profilesfügt eine Abstraktionsebene für umfangreichere Definitionen hinzu. Ein Profil wird invectorSearchdefiniert, und anschließend wird für jedes Vektorfeld anhand des Namens darauf verwiesen."hnsw"und"exhaustiveKnn"sind die ANN-Algorithmen (Approximate Nearest Neighbors, ungefähre nächste Nachbarn), die zum Organisieren von Vektorinhalten während der Indizierung verwendet werden.- Der Standardwert für
"m"(Anzahl bidirektionaler Verknüpfungen) beträgt 4. Der Bereich liegt zwischen 4 und 10. Niedrigere Werte sollten zu einer geringeren Anzahl falscher Ergebnisse führen. - Der Standardwert für
"efConstruction"ist 400. Der Bereich liegt zwischen 100 und 1.000. Dies ist die Anzahl der nächsten Nachbarn, die während der Indizierung verwendet werden. - Der Standardwert für
"efSearch"ist 500. Der Bereich liegt zwischen 100 und 1.000. Dies ist die Anzahl der nächsten Nachbarn, die während der Suche verwendet werden. "metric"muss „Kosinus“ sein, wenn Sie Azure OpenAI verwenden. Verwenden Sie andernfalls die Ähnlichkeitsmetrik, die dem verwendeten Einbettungsmodell zugeordnet ist. Folgende Werte werden unterstützt:cosine,dotProduct,euclidean.
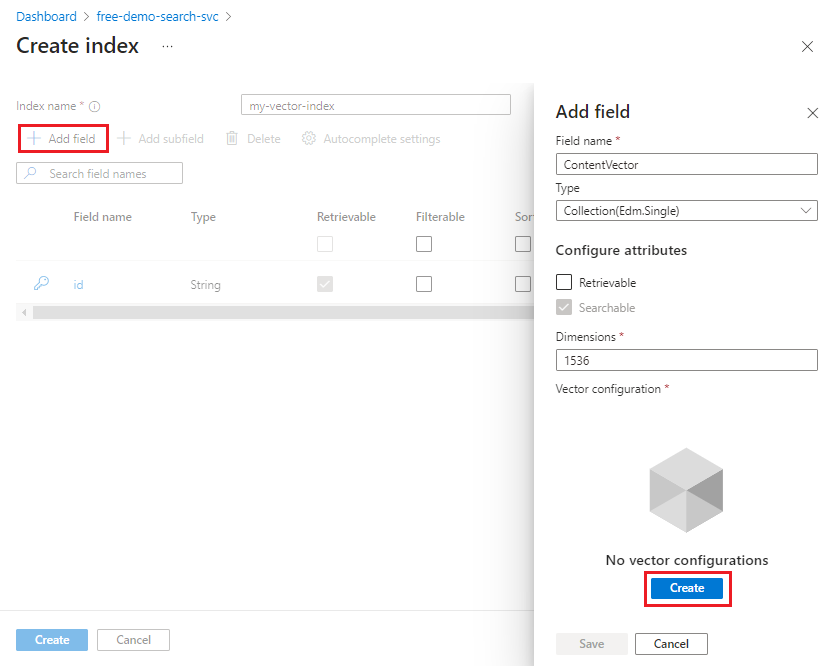
Hinzufügen eines Vektorfelds zur Felderauflistung
Die Felderauflistung muss ein Feld für den Dokumentschlüssel, Vektorfelder und alle anderen Felder enthalten, die Sie für Hybridsuchszenarien benötigen.
Vektorfelder sind vom Typ Collection(Edm.Single) und enthalten Gleitkommawerte mit einfacher Genauigkeit. Ein Feld dieses Typs verfügt zudem über eine dimensions-Eigenschaft und gibt eine Vektorkonfiguration an.
Verwenden Sie diese Version, wenn Sie nur allgemein verfügbare Features nutzen möchten.
Verwenden Sie die API zum Erstellen oder Aktualisieren von Indizes, um den Index zu erstellen.
Definieren Sie ein Vektorfeld mit den folgenden Attributen. Sie können eine generierte Einbettung pro Feld speichern. Für jedes Vektorfeld:
typemuss den WertCollection(Edm.Single)haben.dimensionsist die Anzahl der Dimensionen, die vom Einbettungsmodell generiert werden. Für „text-embedding-ada-002“ ist dieser Wert 1536.vectorSearchProfileist der Name eines Profils, das an anderer Stelle im Index definiert ist.searchablemuss den Wert „true“ haben.retrievablekann true oder false sein. „true“ gibt die unformatierten Vektoren (1536) als Nur-Text zurück und verbraucht Speicherplatz. Legen Sie diese Einstellung auf „true“ fest, wenn Sie ein Vektorergebnis an eine nachgeschaltete App übergeben.filterable,facetableundsortablemüssen den Wert „false“ haben.
Fügen Sie der Auflistung filterbare Nicht-Vektorfelder hinzu, z. B. „title“, und legen Sie dabei
filterableauf „true“ fest, wenn Sie Vorfilterung oder Nachfilterung für die Vektorabfrage aufrufen möchten.Fügen Sie weitere Felder hinzu, die den Inhalt und die Struktur des Textinhalts definieren, den Sie indizieren. Sie benötigen mindestens einen Dokumentschlüssel.
Sie sollten auch Felder hinzufügen, die in der Abfrage oder in ihrer Antwort nützlich sind. Das folgende Beispiel zeigt Vektorfelder für Titel und Inhalt („titleVector“, „contentVector“), die Vektoren entsprechen. Außerdem werden Felder für äquivalente Textinhalte („title“, „content“) bereitgestellt, die beim Sortieren, Filtern und Lesen in einem Suchergebnis hilfreich sind.
Das folgende Beispiel zeigt die Felderauflistung:
PUT https://my-search-service.search.windows.net/indexes/my-index?api-version=2023-11-01&allowIndexDowntime=true Content-Type: application/json api-key: {{admin-api-key}} { "name": "{{index-name}}", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "filterable": true }, { "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "sortable": true, "retrievable": true }, { "name": "titleVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" }, { "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true }, { "name": "contentVector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-default-vector-profile" } ], "vectorSearch": { "algorithms": [ { "name": "my-hnsw-config-1", "kind": "hnsw", "hnswParameters": { "m": 4, "efConstruction": 400, "efSearch": 500, "metric": "cosine" } } ], "profiles": [ { "name": "my-default-vector-profile", "algorithm": "my-hnsw-config-1" } ] } }
Laden von Vektordaten für die Indizierung
Inhalte, die Sie für die Indizierung bereitstellen, müssen dem Indexschema entsprechen und einen eindeutigen Zeichenfolgenwert für den Dokumentschlüssel enthalten. Vorab vektorisierte Daten werden in Vektorfelder geladen, die neben anderen Feldern vorhanden sein können, die alphanumerische Inhalte enthalten.
Sie können entweder Push- oder Pullmethoden für die Datenerfassung verwenden.
Verwenden Sie die API zum Indizieren von Dokumenten (2023-11-01), die API zum Indizieren von Dokumenten (2023-10-01-Preview) oder die API zum Hinzufügen, Aktualisieren oder Löschen von Dokumenten (2023-07-01-Preview), um Dokumente mit Vektordaten zu pushen.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/index?api-version=2023-11-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"value": [
{
"id": "1",
"title": "Azure App Service",
"content": "Azure App Service is a fully managed platform for building, deploying, and scaling web apps. You can host web apps, mobile app backends, and RESTful APIs. It supports a variety of programming languages and frameworks, such as .NET, Java, Node.js, Python, and PHP. The service offers built-in auto-scaling and load balancing capabilities. It also provides integration with other Azure services, such as Azure DevOps, GitHub, and Bitbucket.",
"category": "Web",
"titleVector": [
-0.02250031754374504,
. . .
],
"contentVector": [
-0.024740582332015038,
. . .
],
"@search.action": "upload"
},
{
"id": "2",
"title": "Azure Functions",
"content": "Azure Functions is a serverless compute service that enables you to run code on-demand without having to manage infrastructure. It allows you to build and deploy event-driven applications that automatically scale with your workload. Functions support various languages, including C#, F#, Node.js, Python, and Java. It offers a variety of triggers and bindings to integrate with other Azure services and external services. You only pay for the compute time you consume.",
"category": "Compute",
"titleVector": [
-0.020159931853413582,
. . .
],
"contentVector": [
-0.02780858241021633,
. . .
],
"@search.action": "upload"
}
. . .
]
}
Überprüfen des Indexes auf Vektorinhalte
Zu Überprüfungszwecken können Sie den Index mithilfe des Suchexplorers im Azure-Portal oder eines REST-API-Aufrufs abfragen. Da Azure KI Search einen Vektor nicht in lesbaren Text konvertieren kann, versuchen Sie, Felder aus demselben Dokument zurückzugeben, die Nachweise für die Übereinstimmung liefern. Wenn die Vektorabfrage z. B. auf das Feld „titleVector“ ausgerichtet ist, können Sie „title“ für die Suchergebnisse auswählen.
Felder müssen durch das Attribut „retrievable“ gekennzeichnet sein, damit sie in die Ergebnisse einbezogen werden.
Sie können den Suchexplorer verwenden, um einen Index abzufragen. Der Suchexplorer verfügt über zwei Ansichten: Abfrageansicht (Standard) und JSON-Ansicht.
Verwenden Sie die JSON-Ansicht für Vektorabfragen. Fügen Sie dazu eine JSON-Definition der auszuführenden Vektorabfrage ein.
Verwenden Sie die Standardabfrageansicht, um schnell zu bestätigen, dass der Index Vektoren enthält. Die Abfrageansicht ist für die Volltextsuche vorgesehen. Obwohl Sie sie nicht für Vektorabfragen verwenden können, können Sie eine leere Suche (
search=*) senden, um nach Inhalten zu suchen. Die Inhalte aller Felder, einschließlich Vektorfeldern, werden als Nur-Text zurückgegeben.
Aktualisieren eines Vektorspeichers
Um einen Vektorspeicher zu aktualisieren, ändern Sie das Schema und laden Sie gegebenenfalls die Dokumente neu, um die neuen Felder zu füllen. APIs für das Aktualisieren eines Schemas umfassen Create or Update Index (REST), CreateOrUpdateIndex im Azure SDK für .NET, create_or_update_index im Azure SDK für Python und ähnliche Methoden in anderen Azure SDKs.
Die Standardanleitung für die Aktualisierung eines Indexes finden Sie unter Verwerfen und Neuerstellen eines Indexes.
Wichtige Punkte sind:
Das Verwerfen und Neuerstellen ist häufig für Aktualisierungen und das Löschen bestehender Felder erforderlich.
Sie können jedoch ein bestehendes Schema mit den folgenden Änderungen aktualisieren, ohne dass eine Neuerstellung erforderlich ist:
- Fügen Sie neue Felder zu einer Feldsammlung hinzu.
- Fügen Sie neue Vektorkonfigurationen hinzu, die neuen Feldern zugewiesen werden, aber nicht bestehenden Feldern, die bereits vektorisiert wurden.
- Ändern Sie die Option „abrufbar“ (Werte sind true oder false) für ein bestehendes Feld. Vektorfelder müssen durchsuchbar und abrufbar sein. Wenn Sie jedoch den Zugriff auf ein Vektorfeld in Situationen deaktivieren möchten, in denen das Ablegen und Wiederherstellen nicht möglich ist, können Sie „abrufbar“ auf „false“ setzen.
Nächste Schritte
Als nächsten Schritt wird das Abfragen von Vektordaten in einem Suchindex empfohlen.
Codebeispiele im Repository azure-search-vector veranschaulichen End-to-End-Workflows, die Schemadefinition, Vektorisierung, Indizierung und Abfragen enthalten.
Es gibt Beispielcode für Python, C#und JavaScript.