Exemplarische Vorgehensweise: Matrixmultiplikation
Befolgen Sie die exemplarische Vorgehensweise, um mithilfe von C++ AMP die Ausführung der Matrixmultiplikation zu beschleunigen. Es werden zwei Algorithmen vorgestellt, einer ohne und einer mit Tiling.
Voraussetzungen
Vorbereitungen:
- Read C++ AMP Overview.
- Lesen sie mithilfe von Kacheln.
- Stellen Sie sicher, dass Sie mindestens Windows 7 oder Windows Server 2008 R2 ausführen.
Hinweis
C++AMP-Header sind ab Visual Studio 2022, Version 17.0, veraltet.
Wenn Alle AMP-Header eingeschlossen werden, werden Buildfehler generiert. Definieren Sie _SILENCE_AMP_DEPRECATION_WARNINGS , bevor Sie AMP-Header einschließen, um die Warnungen zu stillen.
So erstellen Sie das Projekt
Anweisungen zum Erstellen eines neuen Projekts variieren je nachdem, welche Version von Visual Studio Sie installiert haben. Um die Dokumentation für Ihre bevorzugte Version von Visual Studio anzuzeigen, verwenden Sie das Auswahlsteuerelement Version. Es befindet sich am Anfang des Inhaltsverzeichnisses auf dieser Seite.
So erstellen Sie das Projekt in Visual Studio
Klicken Sie in der Menüleiste auf Datei>Neu>Projekt, um das Dialogfeld Neues Projekt erstellen zu öffnen.
Legen Sie oben im Dialogfeld die Sprache auf C++, die Plattform auf Windows und den Projekttyp auf Konsole fest.
Wählen Sie in der gefilterten Liste der Projekttypen "Leeres Projekt" und dann "Weiter" aus. Geben Sie auf der nächsten Seite "MatrixMultiply " in das Feld "Name " ein, um einen Namen für das Projekt anzugeben, und geben Sie den Projektspeicherort bei Bedarf an.
Klicken Sie auf die Schaltfläche Erstellen, um das Clientprojekt zu erstellen.
Öffnen Sie in Projektmappen-Explorer das Kontextmenü für Quelldateien, und wählen Sie dann "Neues Element hinzufügen">aus.
Wählen Sie im Dialogfeld "Neues Element hinzufügen" die Option "C++-Datei (.cpp)" aus, geben Sie "MatrixMultiply.cpp " in das Feld "Name " ein, und wählen Sie dann die Schaltfläche "Hinzufügen " aus.
So erstellen Sie ein Projekt in Visual Studio 2017 oder 2015
Klicken Sie in der Menüleiste in Visual Studio auf Datei>Neu>Projekt.
Wählen Sie unter "Installiert" im Vorlagenbereich visual C++ aus.
Wählen Sie "Leeres Projekt" aus, geben Sie "MatrixMultiply" in das Feld "Name" ein, und klicken Sie dann auf die Schaltfläche "OK".
Klicken Sie auf Weiter.
Öffnen Sie in Projektmappen-Explorer das Kontextmenü für Quelldateien, und wählen Sie dann "Neues Element hinzufügen">aus.
Wählen Sie im Dialogfeld "Neues Element hinzufügen" die Option "C++-Datei (.cpp)" aus, geben Sie "MatrixMultiply.cpp " in das Feld "Name " ein, und wählen Sie dann die Schaltfläche "Hinzufügen " aus.
Multiplikation ohne Tiling
In diesem Abschnitt erwägen Sie die Multiplikation von zwei Matrizen, A und B, die folgendermaßen definiert werden:


A ist eine 3 x 2-Matrix und B eine 2 x 3-Matrix. Das Produkt der Multiplikation von A nach B ist die folgende Matrix 3 x 3-Matrix. Das Produkt wird berechnet, indem die Zeilen von A mit den Spalten von B Element für Element multipliziert werden.

Multiplizieren ohne C++ AMP
Öffnen Sie MatrixMultiply.cpp, und verwenden Sie den folgenden Code, um den vorhandenen Code zu ersetzen.
#include <iostream> void MultiplyWithOutAMP() { int aMatrix[3][2] = {{1, 4}, {2, 5}, {3, 6}}; int bMatrix[2][3] = {{7, 8, 9}, {10, 11, 12}}; int product[3][3] = {{0, 0, 0}, {0, 0, 0}, {0, 0, 0}}; for (int row = 0; row < 3; row++) { for (int col = 0; col < 3; col++) { // Multiply the row of A by the column of B to get the row, column of product. for (int inner = 0; inner < 2; inner++) { product[row][col] += aMatrix[row][inner] * bMatrix[inner][col]; } std::cout << product[row][col] << " "; } std::cout << "\n"; } } int main() { MultiplyWithOutAMP(); getchar(); }Der Algorithmus ist eine einfache Implementierung der Definition der Matrixmultiplikation. Um die Berechnungszeit zu reduzieren verwendet er keine Parallel- oder Threaded-Algorithmen.
Klicken Sie in der Menüleiste auf Datei>Alle speichern.
Wählen Sie die F5-Tastenkombination aus, um mit dem Debuggen zu beginnen, und überprüfen Sie, ob die Ausgabe korrekt ist.
Wählen Sie die EINGABETASTE aus, um die Anwendung zu beenden.
Multiplizieren mithilfe von C++ AMP
In MatrixMultiply.cpp fügen Sie den folgenden Code vor der
main-Methode hinzu.void MultiplyWithAMP() { int aMatrix[] = { 1, 4, 2, 5, 3, 6 }; int bMatrix[] = { 7, 8, 9, 10, 11, 12 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 }; array_view<int, 2> a(3, 2, aMatrix); array_view<int, 2> b(2, 3, bMatrix); array_view<int, 2> product(3, 3, productMatrix); parallel_for_each(product.extent, [=] (index<2> idx) restrict(amp) { int row = idx[0]; int col = idx[1]; for (int inner = 0; inner <2; inner++) { product[idx] += a(row, inner)* b(inner, col); } }); product.synchronize(); for (int row = 0; row <3; row++) { for (int col = 0; col <3; col++) { //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Der AMP-Code ähnelt dem Nicht-AMP-Code. Der Aufruf
parallel_for_eachstartet einen Thread für jedes Element inproduct.extentund ersetzt diefor-Schleifen für Zeile und Spalte. Der Wert der Zelle an Zeile und Spalte ist inidxverfügbar. Sie können auf die Elemente einesarray_view-Objekts zugreifen, indem Sie entweder den[]-Operator und eine Indexvariable oder den()-Operator und die Zeilen- und Spaltenvariablen verwenden. Das Beispiel zeigt beide Methoden. Diearray_view::synchronize-Methode kopiert die Werte derproduct-Variablen zurück in dieproductMatrix-Variable.Fügen Sie die folgenden
include- undusing-Anweisungen oben in MatrixMultiply.cpp hinzu.#include <amp.h> using namespace concurrency;Ändern Sie die
main-Methode, um dieMultiplyWithAMP-Methode aufzurufen.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); getchar(); }Drücken Sie die STRG+F5-Tastenkombination, um mit dem Debuggen zu beginnen und zu überprüfen, ob die Ausgabe korrekt ist.
Drücken Sie die LEERTASTE , um die Anwendung zu beenden.
Multiplikation mit Tiling
Bei der Tilung handelt es sich um eine Technik, bei der Sie Daten in Teilmengen gleicher Größe unterteilen, die als Kacheln bezeichnet werden. Drei Dinge ändern sich, wenn Sie Tiling verwenden.
Sie können
tile_static-Variablen erstellen. Der Zugriff auf Daten imtile_static-Space erfolgt möglicherweise um ein Vielfaches schneller als der Zugriff im globalen Namespace. Eine Instanz einertile_static-Variable wird für jeden Tile erstellt, und alle Threads in den Tile haben Zugriff auf die Variable. Der Hauptvorteil beim Tiling ist die Leistungssteigerung durch dentile_static-Zugriff.Sie können die tile_barrier::wait-Methode aufrufen, um alle Threads in einer Kachel in einer bestimmten Codezeile zu beenden. Sie können die Reihenfolge, in der die Threads ausgeführt werden, nicht sicherstellen, nur dass alle Threads in eine Tile beim Aufruf von
tile_barrier::waitbeendet werden, bevor sie weiter ausgeführt werden.Sie haben Zugriff auf den Index des Threads relativ zum vollständigen
array_view-Objekt und den Index relativ zur Tile. Durch Verwenden des lokalen Index wird der Code einfacher zu lesen und zu debuggen.
Um Tiling in der Matrixmultiplikation zu nutzen, muss der Algorithmus die Matrix in Tiles partitionieren und die Tiledaten für einen schnelleren Zugriff in tile_static-Variable kopieren. In diesem Beispiel wird die Matrix in Submatrizes gleicher Größe partitioniert. Das Produkt wird gefunden, indem die Submatrizes multipliziert werden. Die zwei Matrizen und ihr Produkt sind in diesem Beispiel:
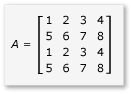

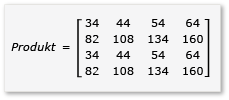
Die Matrizen sind in vier 2 x 2-Matrizen partitioniert, die wie folgt definiert werden:


Das Produkt von A und B kann nun wie folgt geschrieben und berechnet werden:
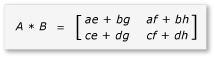
Da es sich bei den Matrizen a bis h um 2 x 2-Matrizen handelt, sind alle Produkte und Summen aus ihnen ebenfalls 2 x 2-Matrizen. Es folgt auch, dass das Produkt von A und B eine 4x4-Matrix ist, wie erwartet. Um den Algorithmus schnell zu überprüfen, berechnen Sie den Wert des Elements in der ersten Zeile/ ersten Spalte im Produkt. In diesem Beispiel ist dies der Wert des Elements in der ersten Zeile/ersten Spalte von ae + bg. Sie müssen für jeden Begriff nur die erste Spalte/erste Zeile von ae und bg berechnen. Dieser Wert für ae ist (1 * 1) + (2 * 5) = 11. Der Wert für bg ist (3 * 1) + (4 * 5) = 23. Der endgültige Wert ist 11 + 23 = 34. Dies ist korrekt.
Um diesen Algorithmus implementieren, verwendet der Code:
ein
tiled_extent-Objekt anstelle einesextent-Objekts imparallel_for_each-Aufruf.ein
tiled_index-Objekt anstelle einesindex-Objekts imparallel_for_each-Aufruf.Erstellt
tile_static-Variablen, um die Submatrizes aufzunehmen.Verwendet die
tile_barrier::wait-Methode, um die Threads für die Berechnung der Produkte der Submatrizes zu beenden.
Multiplizieren mit AMP und Tiling
In MatrixMultiply.cpp fügen Sie den folgenden Code vor der
main-Methode hinzu.void MultiplyWithTiling() { // The tile size is 2. static const int TS = 2; // The raw data. int aMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int bMatrix[] = { 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8 }; int productMatrix[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 }; // Create the array_view objects. array_view<int, 2> a(4, 4, aMatrix); array_view<int, 2> b(4, 4, bMatrix); array_view<int, 2> product(4, 4, productMatrix); // Call parallel_for_each by using 2x2 tiles. parallel_for_each(product.extent.tile<TS, TS>(), [=] (tiled_index<TS, TS> t_idx) restrict(amp) { // Get the location of the thread relative to the tile (row, col) // and the entire array_view (rowGlobal, colGlobal). int row = t_idx.local[0]; int col = t_idx.local[1]; int rowGlobal = t_idx.global[0]; int colGlobal = t_idx.global[1]; int sum = 0; // Given a 4x4 matrix and a 2x2 tile size, this loop executes twice for each thread. // For the first tile and the first loop, it copies a into locA and e into locB. // For the first tile and the second loop, it copies b into locA and g into locB. for (int i = 0; i < 4; i += TS) { tile_static int locA[TS][TS]; tile_static int locB[TS][TS]; locA[row][col] = a(rowGlobal, col + i); locB[row][col] = b(row + i, colGlobal); // The threads in the tile all wait here until locA and locB are filled. t_idx.barrier.wait(); // Return the product for the thread. The sum is retained across // both iterations of the loop, in effect adding the two products // together, for example, a*e. for (int k = 0; k < TS; k++) { sum += locA[row][k] * locB[k][col]; } // All threads must wait until the sums are calculated. If any threads // moved ahead, the values in locA and locB would change. t_idx.barrier.wait(); // Now go on to the next iteration of the loop. } // After both iterations of the loop, copy the sum to the product variable by using the global location. product[t_idx.global] = sum; }); // Copy the contents of product back to the productMatrix variable. product.synchronize(); for (int row = 0; row <4; row++) { for (int col = 0; col <4; col++) { // The results are available from both the product and productMatrix variables. //std::cout << productMatrix[row*3 + col] << " "; std::cout << product(row, col) << " "; } std::cout << "\n"; } }Dieses Beispiel unterscheidet sich deutlich vom Beispiel ohne Tiling. Der Code verwendet diese grundlegenden Schritte:
Kopieren Sie die Elemente der Tile [0,0] von
ainlocA. Kopieren Sie die Elemente der Tile [0,0] vonbinlocB. Beachten Sie, dass Tiling fürproduct, aber nicht füraundbangewendet wird. Sie verwenden daher globale Indizes, um aufa, bundproduct. Der Aufruf vontile_barrier::waitist äußerst wichtig. Er beendet alle Threads in die Tile, bislocAundlocBgefüllt werden.Multiplizieren Sie
locAundlocB, und fügen Sie die Ergebnisse inproductein.Kopieren Sie die Elemente der Kachel [0,1] von
ainlocA. Kopieren Sie die Elemente der Kachel [1,0] vonbinlocB.Multiplizieren Sie
locAundlocB, und fügen Sie sie den Ergebnissen hinzu, die bereits inproductvorhanden sind.Die Multiplikation von Tile [0,0] ist vollständig.
Wiederholen Sie sie für die anderen vier Tiles. Es gibt kein Indizieren speziell für die Tiles, und die Threads können in jeder Reihenfolge ausgeführt werden. Während jeder Thread ausgeführt wird, werden die Variablen
tile_staticfür jedes Tile entsprechend erstellt und der Aufruf vontile_barrier::waitsteuert den Programmfluss.Wenn Sie den Algorithmus sorgfältig untersuchen, beachten Sie, dass jede Submatrix zweimal in einen
tile_static-Arbeitsspeicher geladen wird. Diese Datenübertragung kann länger dauern. Wenn sich die Daten aber einmal imtile_static-Speicher befinden, ist der Zugriff auf die Daten wesentlich schneller. Da das Berechnen der Produkte wiederholten Zugriff auf die Werte in den Submatrizes erfordert, gibt es einen Gesamtleistungsgewinn. Für jeden Algorithmus muss der optimale Algorithmus und die Tilegröße durch Experimentieren herausgefunden werden.
In den Beispielen ohne AMP und ohne Tiling wird vom globalen Arbeitsspeicher aus auf jedes Elements von A und B viermal zugegriffen, um das Produkt zu berechnen. Im Tile-Beispiel wird auf jedes Element zweimal aus dem globalen Arbeitsspeicher und viermal aus dem
tile_static-Speicher zugegriffen. Dies bedeutet keinen signifikanten Leistungsgewinn. Dies ist jedoch der Fall, wenn es sich bei A und B um 1024 x 1024-Matrizen und um Tilegrößen von 16 handelt. In diesem Fall würde jedes Element nur 16 Mal in dentile_static-Speicher kopiert und 1024 Mal aus demtile_static-Arbeitsspeicher zugegriffen.Ändern Sie die Standard-Methode, um die
MultiplyWithTilingMethode aufzurufen, wie dargestellt.int main() { MultiplyWithOutAMP(); MultiplyWithAMP(); MultiplyWithTiling(); getchar(); }Drücken Sie die STRG+F5-Tastenkombination, um mit dem Debuggen zu beginnen und zu überprüfen, ob die Ausgabe korrekt ist.
Drücken Sie die LEERTASTE , um die Anwendung zu verlassen.
Siehe auch
C++ AMP (C++ Accelerated Massive Parallelism)
Exemplarische Vorgehensweise: Debuggen einer C++ AMP-Anwendung
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für