Große Semantikmodelle in Power BI Premium
Power BI-Semantikmodelle können Daten für eine optimierte Abfrageleistung in einem stark komprimierten In-Memory-Cache speichern. Dadurch wird eine schnelle Benutzerinteraktion ermöglicht. Mit Premium-Kapazitäten können große Semantikmodelle, die über die Standardgrenze hinausgehen, mit der Speicherformateinstellung „Große Semantikmodelle“ aktiviert werden. Wenn diese Option aktiviert ist, wird die Größe des Semantikmodells vom Administrator durch die Premium-Kapazitätsgröße oder die maximale Größe beschränkt.
Große Semantikmodelle können für alle Premium-P-SKUs sowie eingebettete A-SKUs und mit Premium pro Benutzer (PPU) aktiviert werden. Die Größenbeschränkung für große Semantikmodelle in Premium ist vergleichbar mit Azure Analysis Services in Bezug auf die Größenbeschränkungen von Datenmodellen.
Abgesehen davon, dass die Speicherformateinstellung für große Semantikmodelle erforderlich ist, damit Semantikmodelle auf über 10 GB anwachsen können, bietet sie auch noch weitere Vorteile. Wenn Sie auf XMLA-Endpunkten basierende Tools für Semantikmodellschreibvorgänge verwenden möchten, sollten Sie darauf achten, die Einstellung auch für Semantikmodelle zu aktivieren, die Sie nicht unbedingt als große Semantikmodelle bezeichnen würden. Wenn diese Einstellung aktiviert ist, kann das Speicherformat für große Semantikmodelle die Leistung von XMLA-Schreibvorgängen verbessern.
Große Semantikmodelle im Dienst wirken sich nicht auf die Uploadgröße des Power BI Desktop-Modells aus, die weiterhin auf 10 GB beschränkt ist. Stattdessen können Semantikmodelle im Dienst bei einer Aktualisierung diesen Grenzwert überschreiten.
Wichtig
Power BI Premium unterstützt große Semantikmodelle. Aktivieren Sie die Option Großes Semantikmodellspeicherformat, um Semantikmodelle in Power BI Premium zu verwenden, die den Standardgrenzwert überschreiten.
Hinweis
Große Semantikmodelle in Power BI Premium sind im Power BI-Dienst für DoD-Kunden der US- Regierung nicht verfügbar. Weitere Informationen dazu, welche Features verfügbar sind, finden Sie unter Power BI-Featureverfügbarkeit.
Aktivieren großer Semantikmodelle
In diesem Schritt wird beschrieben, wie Sie große Semantikmodelle für ein neues Modell aktivieren, das im Dienst veröffentlicht wurde. Für vorhandene Semantikmodelle ist nur Schritt 3 erforderlich.
Erstellen Sie ein Modell in Power BI Desktop. Falls das Semantikmodell größer wird und immer mehr Arbeitsspeicher belegt, achten Sie darauf, eine inkrementelle Aktualisierung zu konfigurieren.
Veröffentlichen Sie das Modell als Semantikmodell für den Dienst.
Erweitern Sie unter „Dienst > Semantikmodell >Einstellungen“ die Option Großes Semantikmodellespeicherformat. Legen Sie den Schieberegler auf Ein fest, und klicken Sie auf Anwenden.

Starten Sie eine Aktualisierung, um historische Daten basierend auf der Richtlinie für die inkrementelle Aktualisierung zu laden. Bei der ersten Aktualisierung kann das Laden der historischen Daten einige Zeit in Anspruch nehmen. Nachfolgende Aktualisierungen sollten je nach Ihrer Richtlinie für die inkrementelle Aktualisierung schneller erfolgen.
Festlegen des Standardspeicherformats
In den unterstützten Regionen kann das große Semantikmodellspeicherformat für alle neuen Semantikmodelle, die in einem Arbeitsbereich einer Premium-Kapazität erstellt wurden, standardmäßig aktiviert werden. Wenn der Bereich keine großen Semantikmodelle unterstützt, ist die unten beschriebene Option für Speicherformate für große Semantikmodelle deaktiviert. Im Abschnitt Regionale Verfügbarkeit finden Sie eine Liste aller unterstützten Regionen.
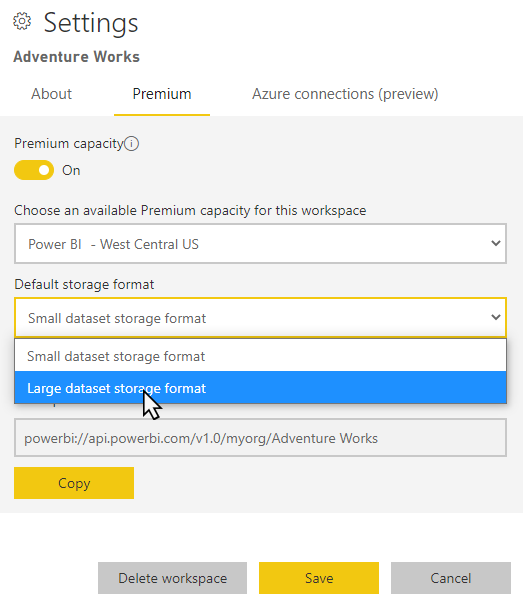
Klicken Sie im Arbeitsbereich auf Einstellungen>Premium.
Klicken Sie unter Standardspeicherformat auf Speicherformat für große Semantikmodelle und dann auf Speichern.
Aktivieren mithilfe von PowerShell
Sie können auch ein großes Semantikmodellspeicherformat mithilfe von PowerShell aktivieren. Zum Ausführen der PowerShell-Cmdlets benötigen Sie Berechtigungen als Kapazitäts- und Arbeitsbereichadministrator.
Suchen Sie die Semantikmodell-ID (GUID). Auf der Registerkarte Semantikmodelle für den Arbeitsbereich können Sie unter den Semantikmodelleinstellungen die ID in der URL sehen.

Installieren Sie in der Eingabeaufforderung für den PowerShell-Administrator das Modul MicrosoftPowerBIMgmt.
Install-Module -Name MicrosoftPowerBIMgmtFühren Sie die folgenden Cmdlets aus, um sich anzumelden und den Speichermodus des Semantikmodelle zu überprüfen.
Login-PowerBIServiceAccount (Get-PowerBIDataset -Scope Organization -Id <Semantic model ID> -Include actualStorage).ActualStorageEs sollte die folgende Antwort ausgegeben werden. Als Speichermodus ist „ABF“ (Analysis Services-Sicherungsdatei) ausgewählt. Das ist die Standardeinstellung.
Id StorageMode -- ----------- <Semantic model ID> AbfFühren Sie die folgenden Cmdlets aus, um den Speichermodus festzulegen. Die Konvertierung in Files Premium kann einige Sekunden in Anspruch nehmen.
Set-PowerBIDataset -Id <Semantic model ID> -TargetStorageMode PremiumFiles (Get-PowerBIDataset -Scope Organization -Id <Semantic model ID> -Include actualStorage).ActualStorageEs sollte die folgende Antwort ausgegeben werden. Der Speichermodus ist jetzt auf Files Premium festgelegt.
Id StorageMode -- ----------- <Semantic model ID> PremiumFiles
Sie können den Status der Konvertierungen der Semantikmodelle in und aus Files Premium mithilfe des Get-PowerBIWorkspaceMigrationStatus-Cmdlets überprüfen.
Semantikmodellabweisung
Das Entfernen von Semantikmodellen ist ein Premium-Feature, durch das die Summe der Semantikmodellgrößen erheblich größer sein darf als der für die erworbene SKU-Größe der Kapazität verfügbare Arbeitsspeicher. Ein einzelnes Semantikmodell ist weiterhin auf die Speichergrenzwerte der SKU beschränkt. Power BI verwendet die dynamische Speicherverwaltung, um inaktive Semantikmodelle aus dem Arbeitsspeicher zu entfernen. Semantikmodelle werden so entfernt, dass Power BI andere Semantikmodelle laden kann, um Benutzerabfragen zu adressieren.
Hinweis
Durch die Wartezeit, die beim erneuten Laden eines entfernten Semantikmodells entsteht, kann es zu erheblichen Verzögerungen kommen.
Bedarfsgesteuertes Laden
Das bedarfsgesteuerte Laden ist für große Semantikmodelle standardmäßig aktiviert und kann die Ladezeit entfernter Semantikmodelle erheblich reduzieren. Das bedarfsgesteuerte Laden bietet bei nachfolgenden Abfragen und Aktualisierungen die folgenden Vorteile:
Relevante Datenseiten werden nach Bedarf geladen (in den Arbeitsspeicher ausgelagert).
Entfernte Semantikmodelle werden schnell für Abfragen verfügbar gemacht.
Beim bedarfsgesteuerten Laden werden zusätzliche DMV-Informationen (dynamische Verwaltungsansicht) bereitgestellt, mit denen Sie Nutzungsmuster identifizieren und den Zustand Ihrer Modelle ermitteln können. Führen Sie z. B. die folgende DMV-Abfrage in SQL Server Management Studio (SSMS) aus, um die Statistiken Temperatur und Letzter Zugriff für die einzelnen Spalten im Semantikmodell zu überprüfen:
Select * from SYSTEMRESTRICTSCHEMA ($System.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS, [DATABASE_NAME] = '<Semantic model Name>')
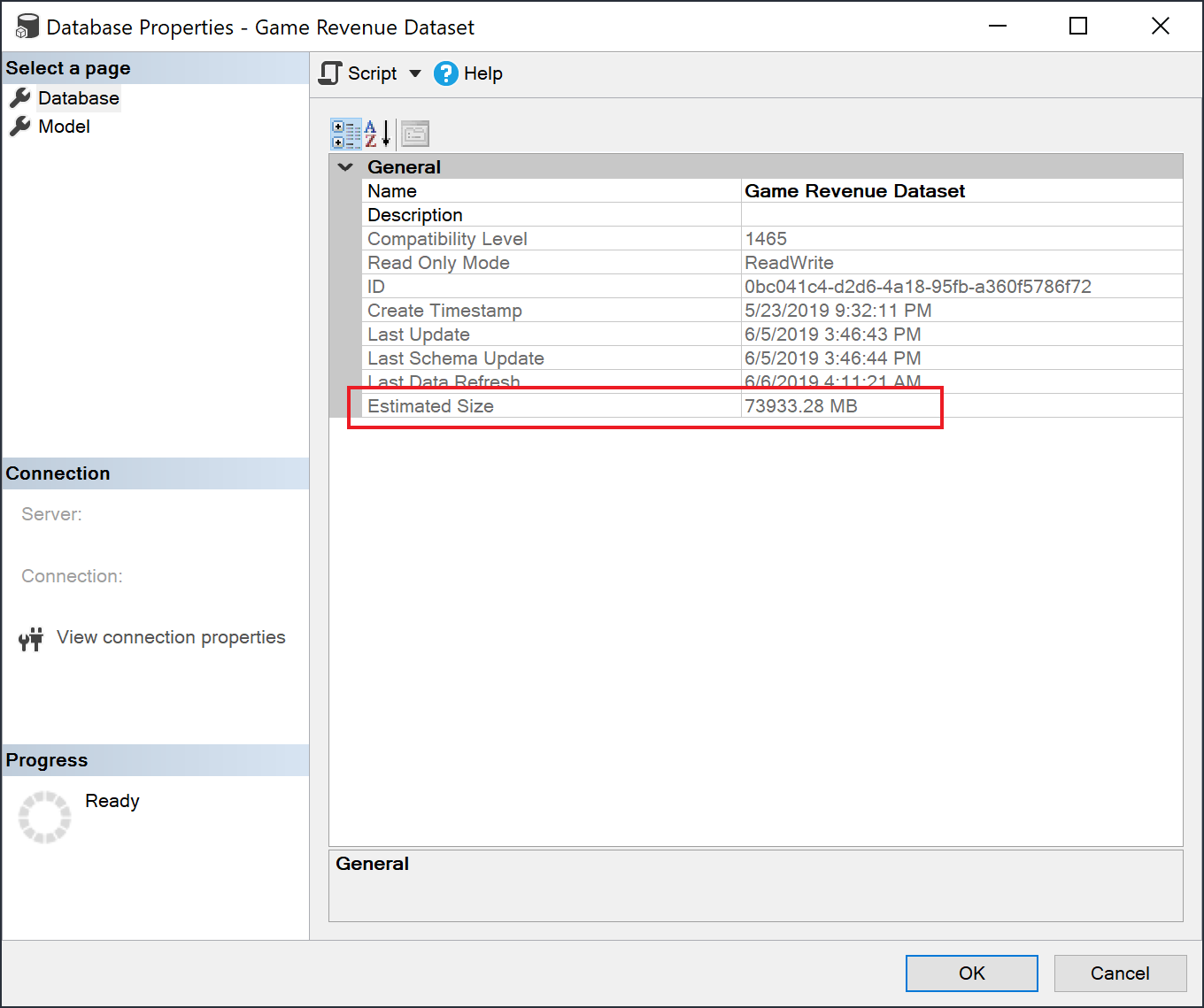
Überprüfen der Größe des Semantikmodells
Nach dem Laden historischer Daten können Sie SSMS über den XMLA-Endpunkt verwenden, um die geschätzte Semantikmodellgröße im Fenster „Modelleigenschaften“ zu überprüfen.
Sie können die Größe des Semantikmodells ebenfalls überprüfen, indem Sie die folgenden DMV-Abfragen aus SSMS ausführen. Wenn Sie die Spalten DICTIONARY_SIZE und USED_SIZE aus der Ausgabe addieren, erhalten Sie die Semantikmodellgröße in Bytes.
SELECT * FROM SYSTEMRESTRICTSCHEMA
($System.DISCOVER_STORAGE_TABLE_COLUMNS,
[DATABASE_NAME] = '<Semantic model Name>') //Sum DICTIONARY_SIZE (bytes)
SELECT * FROM SYSTEMRESTRICTSCHEMA
($System.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS,
[DATABASE_NAME] = '<Semantic model Name>') //Sum USED_SIZE (bytes)
Standardsegmentgröße
Für Semantikmodelle, die das Speicherformat für große Semantikmodelle verwenden, legt Power BI die Standardsegmentgröße automatisch auf 8 Millionen Zeilen fest, um für große Tabellen ein gutes Gleichgewicht zwischen den Arbeitsspeicheranforderungen und der Abfrageleistung zu erreichen. Dies ist die gleiche Segmentgröße wie in Azure Analysis Services. Die Verwendung einer identischen Segmentgröße hilft dabei, vergleichbare Leistungsmerkmale bei der Migration eines großen Datenmodells von Azure Analysis Services zu Power BI sicherzustellen.
Überlegungen und Einschränkungen
Berücksichtigen Sie bei der Verwendung großer Semantikmodelle die folgenden Einschränkungen:
Download auf Power BI Desktop: Wenn ein Semantikmodell in Premium-Dateien gespeichert ist, schlägt das Herunterladen als PBIX-Datei fehl.
Unterstützte Regionen: Große Semantikmodelle sind in Azure-Regionen verfügbar, die Azure Files Storage Premium unterstützen. Eine Liste aller unterstützten Regionen finden Sie in der Tabelle unter Regionale Verfügbarkeit.
Festlegen der maximalen Semantikmodellgröße: Die maximale Semantikmodellgröße kann von Administratoren festgelegt werden. Weitere Informationen finden Sie im Abschnitt Datasets unter Max. Arbeitsspeicher.
Aktualisieren großer Semantikmodelle: Semantikmodelle, deren Größe an die halbe Kapazitätsgröße heranreicht (z. B. ein Semantikmodell mit einer Größe von 12 GB bei einer Kapazitätsgröße von 25 GB), überschreiten möglicherweise bei der Aktualisierung den verfügbaren Arbeitsspeicher. Verwenden Sie die REST-API für erweiterte Aktualisierungen oder den XMLA-Endpunkt, um präzise Datenaktualisierungen durchzuführen. Auf diese Weise kann der für die Aktualisierung erforderliche Arbeitsspeicher entsprechend der Kapazitätsgröße minimiert werden.
Pushsemantikmodelle: Pushsemantikmodelle unterstützen das große Speicherformat des Semantikmodells nicht.
Pro wird nicht unterstützt: Große Semantikmodelle werden in Pro-Arbeitsbereichen nicht unterstützt. Wenn ein Arbeitsbereich von Premium zu Pro migriert wird, werden alle Semantikmodelle mit der Einstellung für das Speicherformat des großen Semantikmodells nicht geladen.
Sie können REST-APIs nicht verwenden, um die Einstellungen eines Arbeitsbereichs zu ändern, damit neue Semantikmodelle standardmäßig das Speicherformat des großen Semantikmodells verwenden können.
Regionale Verfügbarkeit
Große Semantikmodelle in Power BI sind nur in Azure-Regionen verfügbar, die Azure Files Storage Premium unterstützen.
In der folgenden Liste sind Regionen aufgeführt, in denen große Semantikmodelle in Power BI verfügbar sind. In Regionen, die nicht in der folgenden Liste enthalten sind, werden große Modelle nicht unterstützt.
Hinweis
Sobald ein großes Semantikmodell in einem Arbeitsbereich erstellt wurde, muss es in dieser Region verbleiben. Sie können einen Arbeitsbereich mit einem großen Semantikmodell nicht einer Premium Kapazität in einer anderen Region neu zuweisen.
| Azure-Region | Abkürzung der Azure-Region |
|---|---|
| Australien (Osten) | australiaeast |
| Australien, Südosten | australiasoutheast |
| Brasilien Süd | brazilsouth |
| Kanada, Osten | canadaeast |
| Kanada, Mitte | canadacentral |
| Indien, Mitte | centralindia |
| USA (Mitte) | centralus |
| Asien, Osten | eastasia |
| East US | eastus |
| USA (Ost) 2 | eastus2 |
| Frankreich, Mitte | francecentral |
| Frankreich, Süden | francesouth |
| Deutschland, Norden | germanynorth |
| Deutschland, Westen-Mitte | germanywestcentral |
| Japan, Osten | japaneast |
| Japan, Westen | japanwest |
| Korea, Mitte | koreacentral |
| Korea, Süden | koreasouth |
| USA Nord Mitte | northcentralus |
| Nordeuropa | northeurope |
| Südafrika, Norden | southafricanorth |
| Südafrika, Westen | southafricawest |
| USA Süd Mitte | southcentralus |
| Asien, Südosten | southeastasia |
| Schweiz, Norden | switzerlandnorth |
| Schweiz, Westen | switzerlandwest |
| VAE, Mitte | uaecentral |
| Vereinigte Arabische Emirate, Norden | uaenorth |
| UK, Süden | uksouth |
| UK, Westen | ukwest |
| Europa, Westen | westeurope |
| Indien, Westen | westindia |
| USA (Westen) | westus |
| USA, Westen 2 | westus2 |
Zugehöriger Inhalt
Über die folgenden Links können Sie auf nützliche Informationen für die Arbeit mit großen Modellen zugreifen:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für