Microsoft Entra Connect Sync: Understanding Declarative Provisioning
This topic explains the configuration model in Microsoft Entra Connect. The model is called Declarative Provisioning and it allows you to make a configuration change with ease. Many things described in this topic are advanced and not required for most customer scenarios.
Overview
Declarative provisioning is processing objects coming in from a source connected directory and determines how the object and attributes should be transformed from a source to a target. An object is processed in a sync pipeline and the pipeline is the same for inbound and outbound rules. An inbound rule is from a connector space to the metaverse and an outbound rule is from the metaverse to a connector space.

The pipeline has several different modules. Each one is responsible for one concept in object synchronization.
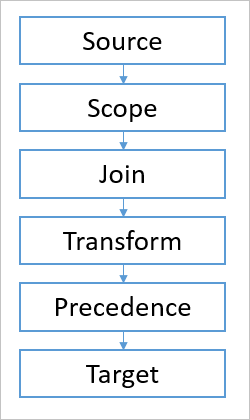
- Source, The source object
- Scope, Finds all sync rules that are in scope
- Join, Determines relationship between connector space and metaverse
- Transform, Calculates how attributes should be transformed and flow
- Precedence, Resolves conflicting attribute contributions
- Target, The target object
Scope
The scope module is evaluating an object and determines the rules that are in scope and should be included in the processing. Depending on the attributes values on the object, different sync rules are evaluated to be in scope. For example, a disabled user with no Exchange mailbox does have different rules than an enabled user with a mailbox.

The scope is defined as groups and clauses. The clauses are inside a group. A logical AND is used between all clauses in a group. For example, (department =IT AND country = Denmark). A logical OR is used between groups.
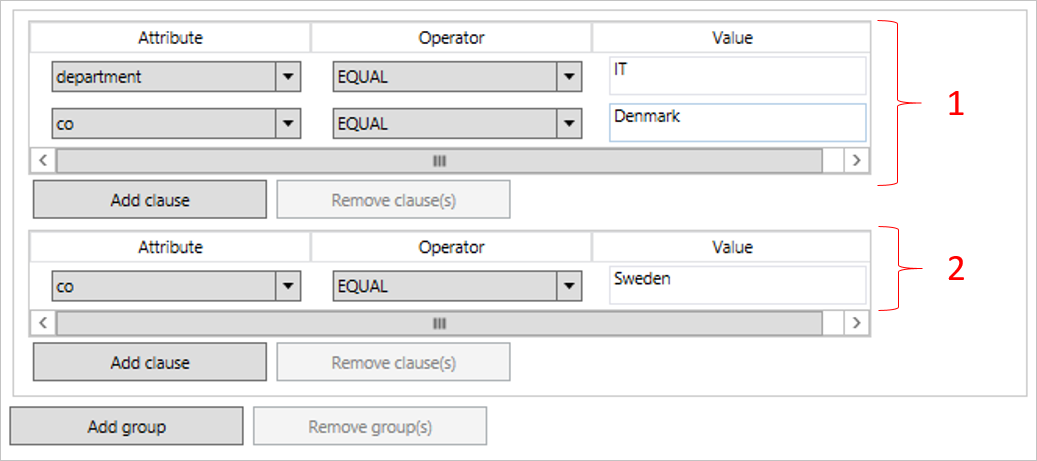
The scope in this picture should be read as (department = IT AND country = Denmark) OR (country=Sweden). If either group 1 or group 2 is evaluated to true, then the rule is in scope.
The scope module supports the following operations.
| Operation | Description |
|---|---|
| EQUAL, NOTEQUAL | A string compare that evaluates if value is equal to the value in the attribute. For multi-valued attributes, see ISIN and ISNOTIN. |
| LESSTHAN, LESSTHAN_OR_EQUAL | A string compare that evaluates if value is less than of the value in the attribute. |
| CONTAINS, NOTCONTAINS | A string compare that evaluates if value can be found somewhere inside value in the attribute. |
| STARTSWITH, NOTSTARTSWITH | A string compare that evaluates if value is in the beginning of the value in the attribute. |
| ENDSWITH, NOTENDSWITH | A string compare that evaluates if value is in the end of the value in the attribute. |
| GREATERTHAN, GREATERTHAN_OR_EQUAL | A string compare that evaluates if value is greater than of the value in the attribute. |
| ISNULL, ISNOTNULL | Evaluates if the attribute is absent from the object. If the attribute is not present and therefore null, then the rule is in scope. |
| ISIN, ISNOTIN | Evaluates if the value is present in the defined attribute. This operation is the multi-valued variation of EQUAL and NOTEQUAL. The attribute is supposed to be a multi-valued attribute and if the value can be found in any of the attribute values, then the rule is in scope. |
| ISBITSET, ISNOTBITSET | Evaluates if a particular bit is set. For example, can be used to evaluate the bits in userAccountControl to see if a user is enabled or disabled. |
| ISMEMBEROF, ISNOTMEMBEROF | The value should contain a DN to a group in the connector space. If the object is a member of the group specified, the rule is in scope. |
Join
The join module in the sync pipeline is responsible for finding the relationship between the object in the source and an object in the target. On an inbound rule, this relationship would be an object in a connector space finding a relationship to an object in the metaverse.

The goal is to see if there is an object already in the metaverse, created by another Connector, it should be associated with. For example, in an account-resource forest the user from the account forest should be joined with the user from the resource forest.
Joins are used mostly on inbound rules to join connector space objects together to the same metaverse object.
The joins are defined as one or more groups. Inside a group, you have clauses. A logical AND is used between all clauses in a group. A logical OR is used between groups. The groups are processed in order from top to bottom. When one group has found exactly one match with an object in the target, then no other join rules are evaluated. If zero or more than one object is found, processing continues to the next group of rules. For this reason, the rules should be created in the order of most explicit first and more fuzzy at the end.
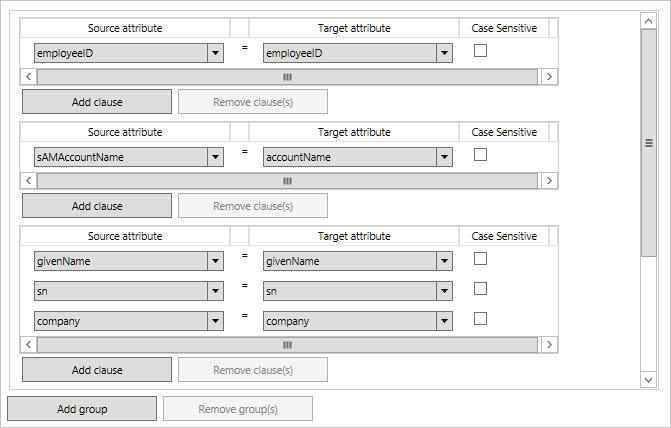
The joins in this picture are processed from top to bottom. First the sync pipeline sees if there is a match on employeeID. If not, the second rule sees if the account name can be used to join the objects together. If that is not a match either, the third and final rule is a more fuzzy match by using the name of user.
If all join rules have been evaluated and there is not exactly one match, the Link Type on the Description page is used. If this option is set to Provision, then a new object in the target is created.
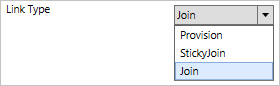
An object should only have one single sync rule with join rules in scope. If there are multiple sync rules where join is defined, an error occurs. Precedence is not used to resolve join conflicts. An object must have a join rule in scope for attributes to flow with the same inbound/outbound direction. If you need to flow attributes both inbound and outbound to the same object, you must have both an inbound and an outbound sync rule with join.
Outbound join has a special behavior when it tries to provision an object to a target connector space. The DN attribute is used to first try a reverse-join. If there is already an object in the target connector space with the same DN, the objects are joined.
The join module is only evaluated once when a new sync rule comes into scope. When an object has joined, it is not disjoining even if the join criteria is no longer satisfied. If you want to disjoin an object, the sync rule that joined the objects must go out of scope.
Metaverse delete
A metaverse object remains as long as there is one sync rule in scope with Link Type set to Provision or StickyJoin. A StickyJoin is used when a Connector is not allowed to provision a new object to the metaverse, but when it has joined, it must be deleted in the source before the metaverse object is deleted.
When a metaverse object is deleted, all objects associated with an outbound sync rule marked for provision are marked for a delete.
Transformations
The transformations are used to define how attributes should flow from the source to the target. The flows can have one of the following flow types: Direct, Constant, or Expression. A direct flow, flows an attribute value as-is with no additional transformations. A constant value sets the specified value. An expression uses the declarative provisioning expression language to express how the transformation should be. The details for the expression language can be found in the understanding declarative provisioning expression language topic.
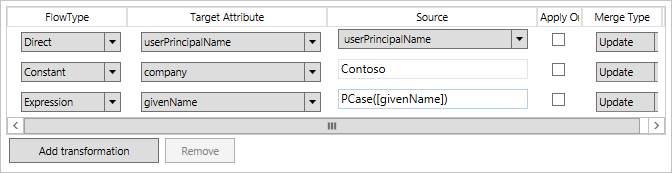
The Apply once checkbox defines that the attribute should only be set when the object is initially created. For example, this configuration can be used to set an initial password for a new user object.
Merging attribute values
In the attribute flows there is a setting to determine if multi-valued attributes should be merged from several different Connectors. The default value is Update, which indicates that the sync rule with highest precedence should win.
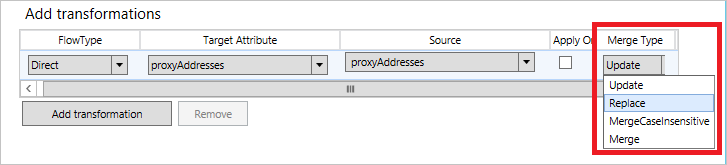
There is also Merge and MergeCaseInsensitive. These options allow you to merge values from different sources. For example, it can be used to merge the proxyAddresses attribute from several different forests. When you use this option, all sync rules in scope for an object must use the same merge type. You cannot define Update from one Connector and Merge from another. If you try, you receive an error.
The difference between Merge and MergeCaseInsensitive is how to process duplicate attribute values. The sync engine makes sure duplicate values are not inserted into the target attribute. With MergeCaseInsensitive, duplicate values with only a difference in case are not going to be present. For example, you should not see both "SMTP:bob@contoso.com" and "smtp:bob@contoso.com" in the target attribute. Merge is only looking at the exact values and multiple values where there only is a difference in case might be present.
The option Replace is the same as Update, but it is not used.
Control the attribute flow process
When multiple inbound sync rules are configured to contribute to the same metaverse attribute, then precedence is used to determine the winner. The sync rule with highest precedence (lowest numeric value) is going to contribute the value. The same happens for outbound rules. The sync rule with highest precedence wins and contribute the value to the connected directory.
In some cases, rather than contribute a value, the sync rule should determine how other rules should behave. There are some special literals used for this case.
For inbound Synchronization Rules, the literal NULL can be used to indicate that the flow has no value to contribute. Another rule with lower precedence can contribute a value. If no rule contributed a value, then the metaverse attribute is removed. For an outbound rule, if NULL is the final value after all sync rules have been processed, then the value is removed in the connected directory.
The literal AuthoritativeNull is similar to NULL but with the difference that no lower precedence rules can contribute a value.
An attribute flow can also use IgnoreThisFlow. It is similar to NULL in the sense that it indicates there is nothing to contribute. The difference is that it does not remove an already existing value in the target. It is like the attribute flow has never been there.
Here is an example:
In Out to AD - User Exchange hybrid the following flow can be found:
IIF([cloudSOAExchMailbox] = True,[cloudMSExchSafeSendersHash],IgnoreThisFlow)
This expression should be read as: if the user mailbox is located in Microsoft Entra ID, then flow the attribute from Microsoft Entra ID to Active Directory. If not, do not flow anything back to Active Directory. In this case, it would keep the existing value in AD.
ImportedValue
The function ImportedValue is different than all other functions since the attribute name must be enclosed in quotes rather than square brackets:
ImportedValue("proxyAddresses").
Inbound synchronization has a concept of assuming that an attribute that hasn’t yet reached a connected directory will eventually reach it at some point so, normally, synchronization gets an attribute value from the respective connector space, even if it hasn’t been yet exported or an error occurred during export. In some cases, however, it is important to only synchronize a value that has been exported and confirmed during import from the connected directory. This function can be found in multiple “In From AD/AAD” out-of-box transformation rules where the attribute should only be synchronized when it has been confirmed that the value was exported successfully.
An example of this function can be found in the out-of-box Synchronization Rule In from AD – User Common from Exchange, for ProxyAddresses attribute flow with Hybrid Exchange. E.g., when a user’s ProxyAddresses is added, the ImportedValue function will only return the new value after it has been confirmed from the following import step:
proxyAddresses <- RemoveDuplicates(Trim(ImportedValue("proxyAddresses")))
This function is required when the target directory might change or discard an exported attribute value silently, and we want the synchronization to only process confirmed attribute values.
Precedence
When several sync rules try to contribute the same attribute value to the target, the precedence value is used to determine the winner. The rule with highest precedence, lowest numeric value, is going to contribute the attribute in a conflict.

This ordering can be used to define more precise attribute flows for a small subset of objects. For example, the out-of-box-rules make sure that attributes from an enabled account (User AccountEnabled) have precedence from other accounts.
Precedence can be defined between Connectors. That allows Connectors with better data to contribute values first.
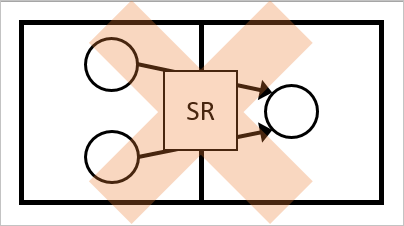
Multiple objects from the same connector space
It is not possible to have several objects in the same connector space joined to the same metaverse object. This configuration is reported as ambiguous even if the attributes in the source have the same value.
Next steps
- Read more about the expression language in Understanding Declarative Provisioning Expressions.
- See how declarative provisioning is used out-of-box in Understanding the default configuration.
- See how to make a practical change using declarative provisioning in How to make a change to the default configuration.
- Continue to read how users and contacts work together in Understanding Users and Contacts.
Overview topics
- Microsoft Entra Connect Sync: Understand and customize synchronization
- Integrating your on-premises identities with Microsoft Entra ID
Reference topics
Σχόλια
Σύντομα διαθέσιμα: Καθ' όλη τη διάρκεια του 2024 θα καταργήσουμε σταδιακά τα ζητήματα GitHub ως μηχανισμό ανάδρασης για το περιεχόμενο και θα το αντικαταστήσουμε με ένα νέο σύστημα ανάδρασης. Για περισσότερες πληροφορίες, ανατρέξτε στο θέμα: https://aka.ms/ContentUserFeedback.
Υποβολή και προβολή σχολίων για