This article demonstrates how to create a search service that enables users to search for documents based on document content in addition to any metadata that's associated with the files.
You can implement this service by using multiple indexers in Azure AI Search.
This article uses an example workload to demonstrate how to create a single search index that's based on files in Azure Blob Storage. The file metadata is stored in Azure Table Storage.
Architecture
Download a PowerPoint file of this architecture.
Dataflow
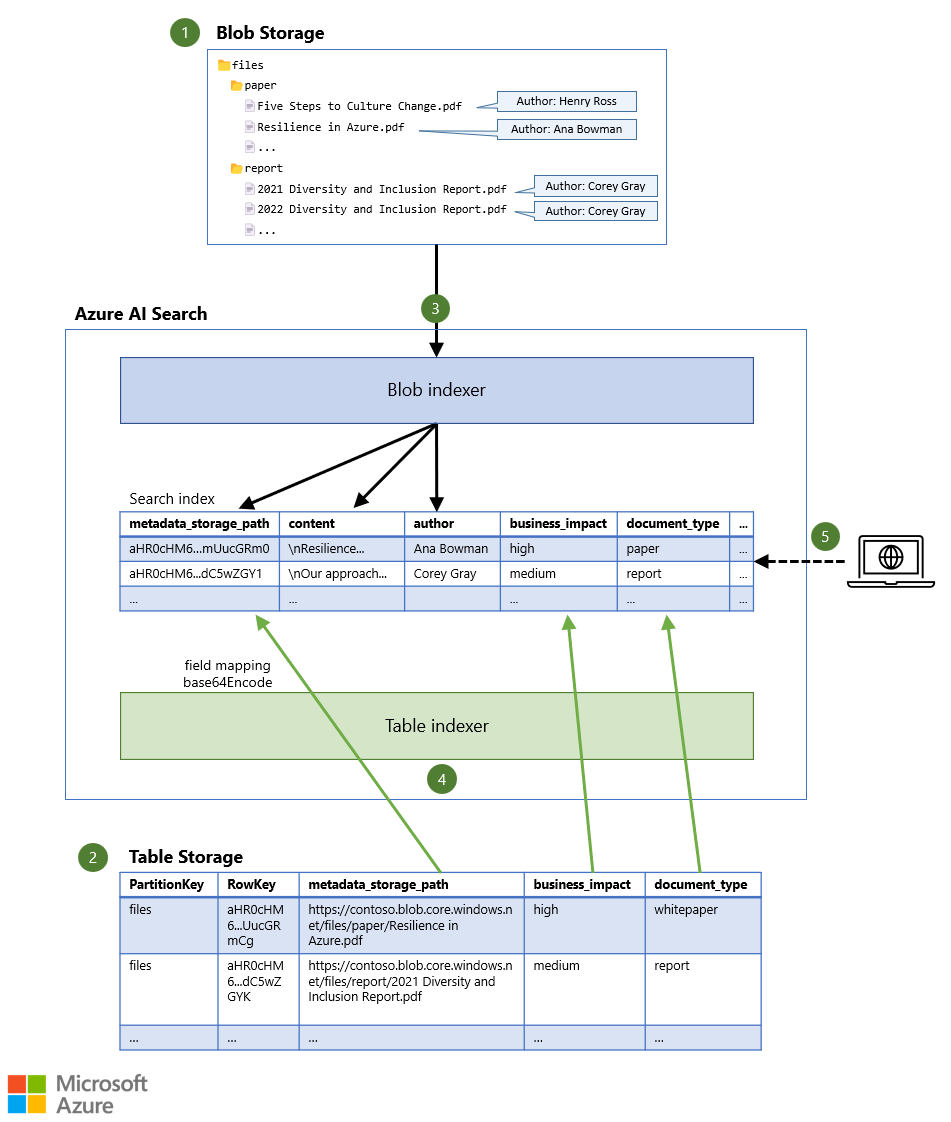
- Files are stored in Blob Storage, possibly together with a limited amount of metadata (for example, the document's author).
- Additional metadata is stored in Table Storage, which can store significantly more information for each document.
- An indexer reads the contents of each file, together with any blob metadata, and stores the data in the search index.
- Another indexer reads the additional metadata from the table and stores it in the same search index.
- A search query is sent to the search service. The query returns matching documents, based on both document content and document metadata.
Components
- Blob Storage provides cost-effective cloud storage for file data, including data in formats like PDF, HTML, and CSV, and in Microsoft 365 files.
- Table Storage provides storage for nonrelational structured data. In this scenario, it's used to store the metadata for each document.
- Azure AI Search is a fully managed search service that provides infrastructure, APIs, and tools for building a rich search experience.
Alternatives
This scenario uses indexers in Azure AI Search to automatically discover new content in supported data sources, like blob and table storage, and then add it to the search index. Alternatively, you can use the APIs provided by Azure AI Search to push data to the search index. If you do, however, you need to write code to push the data into the search index and also to parse and extract text from the binary documents that you want to search. The Blob Storage indexer supports many document formats, which significantly simplifies the text extraction and indexing process.
Also, if you use indexers, you can optionally enrich the data as part of an indexing pipeline. For example, you can use Azure AI services to perform optical character recognition (OCR) or visual analysis of the images in documents, detect the language of documents, or translate documents. You can also define your own custom skills to enrich the data in ways that are relevant to your business scenario.
This architecture uses blob and table storage because they're cost-effective and efficient. This design also enables combined storage of the documents and metadata in a single storage account. Alternative supported data sources for the documents themselves include Azure Data Lake Storage and Azure Files. Document metadata can be stored in any other supported data source that holds structured data, like Azure SQL Database and Azure Cosmos DB.
Scenario details
Searching file content
This solution enables users to search for documents based on both file content and additional metadata that's stored separately for each document. In addition to searching the text content of a document, a user might want to search for the document's author, the document type (like paper or report), or its business impact (high, medium, or low).
Azure AI Search is a fully managed search service that can create search indexes that contain the information you want to allow users to search for.
Because the files that are searched in this scenario are binary documents, you can store them in Blob Storage. If you do, you can use the built-in Blob Storage indexer in Azure AI Search to automatically extract text from the files and add their content to the search index.
Searching file metadata
If you want to include additional information about the files, you can directly associate metadata with the blobs, without using a separate store. The built-in Blob Storage search indexer can even read this metadata and place it in the search index. This enables users to search for metadata along with the file content. However, the amount of metadata is limited to 8 KB per blob, so the amount of information that you can place on each blob is fairly small. You might choose to store only the most critical information directly on the blobs. In this scenario, only the document's author is stored on the blob.
To overcome this storage limitation, you can place additional metadata in another data source that has a supported indexer, like Table Storage. You can add the document type, business impact, and other metadata values as separate columns in the table. If you configure the built-in Table Storage indexer to target the same search index as the blob indexer, the blob and table storage metadata is combined for each document in the search index.
Using multiple data sources for a single search index
To ensure that both indexers point to the same document in the search index, the document key in the search index is set to a unique identifier of the file. This unique identifier is then used to refer to the file in both data sources. The blob indexer uses the metadata_storage_path as the document key, by default. The metadata_storage_path property stores the full URL of the file in Blob Storage, for example, https://contoso.blob.core.windows.net/files/paper/Resilience in Azure.pdf. The indexer performs Base64 encoding on the value to ensure that there are no invalid characters in the document key. The result is a unique document key, like aHR0cHM6...mUucGRm0.
If you add the metadata_storage_path as a column in Table Storage, you know exactly which blob the metadata in the other columns belongs to, so you can use any PartitionKey and RowKey value in the table. For example, you could use the blob container name as the PartitionKey and the Base64-encoded full URL of the blob as the RowKey, ensuring that there are no invalid characters in these keys either.
You can then use a field mapping in the table indexer to map the metadata_storage_path column (or another column) in Table Storage to the metadata_storage_path document key field in the search index. If you apply the base64Encode function on the field mapping, you end up with the same document key (aHR0cHM6...mUucGRm0 in the earlier example), and the metadata from Table Storage is added to the same document that was extracted from Blob Storage.
Note
The table indexer documentation states that you shouldn't define a field mapping to an alternative unique string field in your table. That's because the indexer concatenates the PartitionKey and RowKey as the document key, by default. Because you're already relying on the document key as configured by the blob indexer (which is the Base64-encoded full URL of the blob), creating a field mapping to ensure that both indexers refer to the same document in the search index is appropriate and supported for this scenario.
Alternatively, you can map the RowKey (which is set to the Base64-encoded full URL of the blob) to the metadata_storage_path document key directly, without storing it separately and Base64-encoding it as part of the field mapping. However, keeping the unencoded URL in a separate column clarifies which blob it refers to and allows you to choose any partition and row keys without affecting the search indexer.
Potential use cases
This scenario applies to applications that require the ability to search for documents based on their content and additional metadata.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that you can use to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Reliability
Reliability ensures that your application can meet the commitments you make to your customers. For more information, see Overview of the reliability pillar.
Azure AI Search provides a high service-level agreement (SLA) for reads (querying) if you have at least two replicas. It provides a high SLA for updates (updating the search indexes) if you have at least three replicas. You should therefore provision at least two replicas if you want your users to be able to search reliably, and three if actual changes to the index also need to be high availability operations.
Azure Storage always stores multiple copies of your data to help protect it against planned and unplanned events. Azure Storage provides additional redundancy options for replicating data across regions. These safeguards apply to data in blob and table storage.
Security
Security provides assurances against deliberate attacks and the abuse of your valuable data and systems. For more information, see Overview of the security pillar.
Azure AI Search provides robust security controls that help you implement network security, authentication and authorization, data residency and protection, and administrative controls that help you maintain security, privacy, and compliance.
Whenever possible, use Microsoft Entra authentication to provide access to the search service itself, and connect your search service to other Azure resources (like blob and table storage in this scenario) by using a managed identity.
You can connect from the search service to the storage account by using a private endpoint. When you use a private endpoint, the indexers can use a private connection without requiring the blob and table storage to be accessible publicly.
Cost optimization
Cost optimization is about reducing unnecessary expenses and improving operational efficiencies. For more information, see Overview of the cost optimization pillar.
For information about the costs of running this scenario, see this preconfigured estimate in the Azure pricing calculator. All the services described here are configured in this estimate. The estimate is for a workload that has a total document size of 20 GB in Blob Storage and 1 GB of metadata in Table Storage. Two search units are used to satisfy the SLA for read purposes, as described in the Reliability section of this article. To see how the pricing would change for your particular use case, change the appropriate variables to match your expected usage.
If you review the estimate, you can see that the cost of blob and table storage is relatively low. Most of the cost is incurred by Azure AI Search, because it performs the actual indexing and compute for running search queries.
Deploy this scenario
To deploy this example workload, see Indexing file contents and metadata in Azure AI Search. You can use this sample to:
- Create the required Azure services.
- Upload a few sample documents to Blob Storage.
- Populate the author metadata value on the blob.
- Store the document type and business impact metadata values in Table Storage.
- Create the indexers that maintain the search index.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Jelle Druyts | Principal Customer Experience Engineer
Other contributor:
- Mick Alberts | Technical Writer
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
- Get started with Azure AI Search
- Increase relevancy using semantic search in Azure AI Search
- Security filters for trimming results in Azure AI Search
- Tutorial: Index from multiple data sources using the .NET SDK