Estimate and manage capacity of a search service
In Azure AI Search, capacity is based on replicas and partitions that can be scaled to your workload. Replicas are copies of the search engine. Partitions are units of storage. Each new search service starts with one each, but you can add or remove replicas and partitions independently to accommodate fluctuating workloads. Adding capacity increases the cost of running a search service.
The physical characteristics of replicas and partitions, such as processing speed and disk IO, vary by service tier. On a standard search service, the replicas and partitions are faster and larger than those of a basic service.
Changing capacity isn't instantaneous. It can take up to an hour to commission or decommission partitions, especially on services with large amounts of data.
When scaling a search service, you can choose from the following tools and approaches:
Note
Higher capacity partitions are available at the same billing rate on newer services created after April and May 2024. For more information, see Service limits for partition size upgrades.
Capacity is expressed in search units that can be allocated in combinations of partitions and replicas.
| Concept | Definition |
|---|---|
| Search unit | A single increment of total available capacity (36 units). A minimum of one unit is required to run the service. The first replica and partition pair is the first search unit. However, each extra instance of a replica or a partition consumes an extra search unit. For example, you start with one replica and partition (one search unit), add a second replica, you are now consuming two search units. A search unit is also the billing unit for an Azure AI Search service. |
| Replica | Instances of the search service, used primarily to load balance query operations. Each replica hosts one copy of an index. If you allocate three replicas, you have three copies of an index available for servicing query requests. |
| Partition | Physical storage and I/O for read/write operations (for example, when rebuilding or refreshing an index). Each partition has a slice of the total index. If you allocate three partitions, your index is divided into thirds. |
Review the partitions and replicas table for possible combinations that stay under the 36 unit limit.
Initially, a service is allocated a minimal level of resources consisting of one partition and one replica. The tier you choose determines partition size and speed, and each tier is optimized around a set of characteristics that fit various scenarios. If you choose a higher-end tier, you might need fewer partitions than if you go with S1. One of the questions you'll need to answer through self-directed testing is whether a larger and more expensive partition yields better performance than two cheaper partitions on a service provisioned at a lower tier.
A single service must have sufficient resources to handle all workloads (indexing and queries). Neither workload runs in the background. You can schedule indexing for times when query requests are naturally less frequent, but the service won't otherwise prioritize one task over another. Additionally, a certain amount of redundancy smooths out query performance when services or nodes are updated internally.
Some guidelines for determining whether to add capacity include:
- Meeting the high availability criteria for service level agreement
- The frequency of HTTP 503 errors is increasing
- Large query volumes are expected
As a general rule, search applications tend to need more replicas than partitions, particularly when the service operations are biased toward query workloads. Each replica is a copy of your index, allowing the service to load balance requests against multiple copies. All load balancing and replication of an index is managed by Azure AI Search and you can alter the number of replicas allocated for your service at any time. You can allocate up to 12 replicas in a Standard search service and 3 replicas in a Basic search service. Replica allocation can be made either from the Azure portal or one of the programmatic options.
Extra partitions are helpful for intensive indexing workloads. Extra partitions spread read/write operations across a larger number of compute resources.
Finally, larger indexes take longer to query. As such, you might find that every incremental increase in partitions requires a smaller but proportional increase in replicas. The complexity of your queries and query volume will factor into how quickly query execution is turned around.
Note
Adding more replicas or partitions increases the cost of running the service, and can introduce slight variations in how results are ordered. Be sure to check the pricing calculator to understand the billing implications of adding more nodes. The chart below can help you cross-reference the number of search units required for a specific configuration. For more information on how additional replicas impact query processing, see Ordering results.
To increase or decrease the capacity of your search service, add or remove partitions and replicas.
Sign in to the Azure portal and select the search service.
Under Settings, open the Scale page to modify replicas and partitions.
The following screenshot shows a Standard service provisioned with one replica and partition. The formula at the bottom indicates how many search units are being used (1). If the unit price was $100 (not a real price), the monthly cost of running this service would be $100 on average.
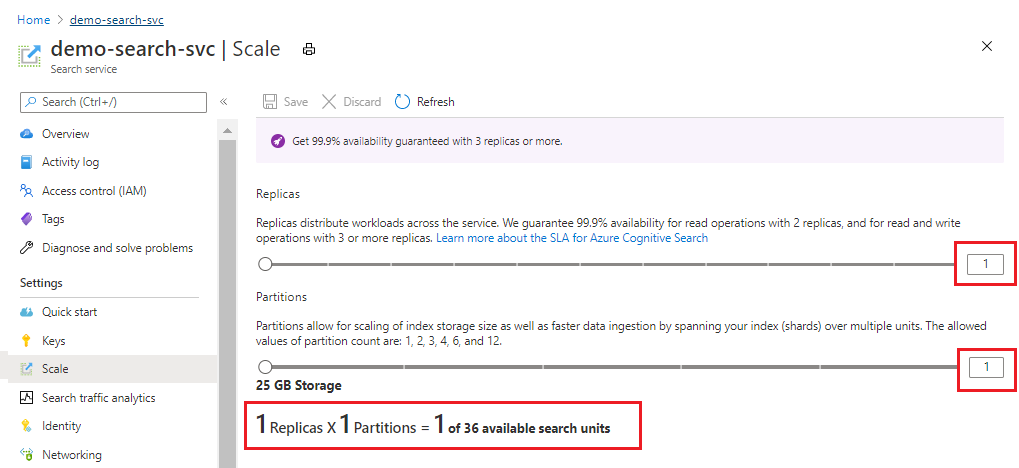
Use the slider to increase or decrease the number of partitions. Select Save.
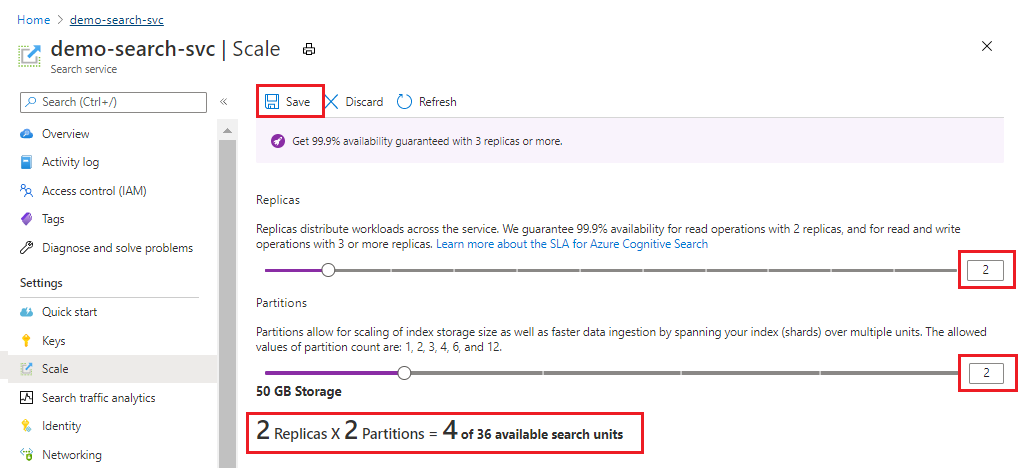
This example adds a second replica and partition. Notice the search unit count; it's now four because the billing formula is replicas multiplied by partitions (2 x 2). Doubling capacity more than doubles the cost of running the service. If the search unit cost was $100, the new monthly bill would now be $400.
For the current per unit costs of each tier, visit the Pricing page.
After saving, you can check notifications to confirm the action succeeded.
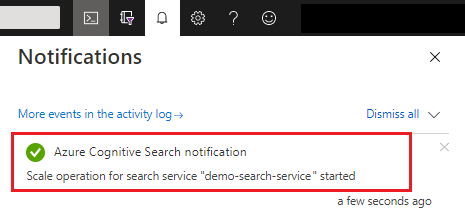
Changes in capacity can take anywhere from 15 minutes up to several hours to complete. You can't cancel once the process has started and there's no real-time monitoring for replica and partition adjustments. However, the following message remains visible while changes are underway.

Note
After a service is provisioned, it cannot be upgraded to a higher tier. You must create a search service at the new tier and reload your indexes. See Create an Azure AI Search service in the Azure portal for help with service provisioning.
Upon receipt of a scale request, the search service:
- Checks whether the request is valid.
- Starts backing up data and system information.
- Checks whether the service is already in a provisioning state (currently adding or eliminating either replicas or partitions).
- Starts provisioning.
Scaling a service can take as little as 15 minutes or well over an hour, depending on the size of the service and the scope of the request. Backup can take several minutes, depending on the amount of data and number of partitions and replicas.
The above steps aren't entirely consecutive. For example, the system starts provisioning when it can safely do so, which could be while backup is winding down.
The error message "Service update operations aren't allowed at this time because we're processing a previous request" is caused by repeating a request to scale down or up when the service is already processing a previous request.
Resolve this error by checking service status to verify provisioning status:
- Use the Management REST API, Azure PowerShell, or Azure CLI to get service status.
- Call Get Service (REST) or equivalent for PowerShell or the CLI.
- Check the response for "provisioningState": "provisioning"
If status is "Provisioning", wait for the request to complete. Status should be either "Succeeded" or "Failed" before another request is attempted. There's no status for backup. Backup is an internal operation and it's unlikely to be a factor in any disruption of a scale exercise.
If your search service appears to be stalled in a provisioning state, check for orphaned indexes that are unusable, with zero query volumes and no index updates. An unusable index can block changes to service capacity. In particular, look for indexes that are CMK-encrypted, whose keys are no longer valid. You should either delete the index or restore the keys to bring the index back online and unblock your scale operation.
The following chart applies to Standard tier and higher. It shows all possible combinations of partitions and replicas, subject to the 36 search unit maximum per service.
| 1 partition | 2 partitions | 3 partitions | 4 partitions | 6 partitions | 12 partitions | |
|---|---|---|---|---|---|---|
| 1 replica | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 replicas | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 replicas | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 replicas | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | N/A |
| 5 replicas | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | N/A |
| 6 replicas | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | N/A |
| 12 replicas | 12 SU | 24 SU | 36 SU | N/A | N/A | N/A |
Basic search services have lower search unit counts.
On search services created before April 3, 2024, a basic search service can have exactly one partition and up to three replicas, for a maximum limit of three SUs. The only adjustable resource is replicas.
On search services created after April 3, 2024 in supported regions, basic services can have up to three partitions and three replicas. The maximum SU limit is nine to support a full complement of partitions and replicas.
For search services on any billable tier, regardless of creation date, you need a minimum of two replicas for high availability on queries.
For billing rates per tier and currency, see the Azure AI Search pricing page.
Storage needs are determined by the size of the indexes you expect to build. There are no solid heuristics or generalities that help with estimates. The only way to determine the size of an index is build one. Its size is based on tokenization and embeddings, and whether you enable suggesters, filtering, and sorting, or can take advantage of vector compression.
We recommend estimating on a billable tier, Basic or above. The Free tier runs on physical resources shared by multiple customers and is subject to factors beyond your control. Only the dedicated resources of a billable search service can accommodate larger sampling and processing times for more realistic estimates of index quantity, size, and query volumes during development.
Review service limits at each tier to determine whether lower tiers can support the number of indexes you need. Consider whether you need multiple copies of an index for active development, testing, and production.
A search service is subject to object limits (maximum number of indexes, indexers, skillsets, etc.) and storage limits. Whichever limit is reached first is the effective limit.
Create a service at a billable tier. Tiers are optimized for certain workloads. For example, Storage Optimized tier has a limit of 10 indexes because it's designed to support a low number of very large indexes.
Start low, at Basic or S1, if you're not sure about the projected load.
Start high, at S2 or even S3, if testing includes large-scale indexing and query loads.
Start with Storage Optimized, at L1 or L2, if you're indexing a large amount of data and query load is relatively low, as with an internal business application.
Build an initial index to determine how source data translates to an index. This is the only way to estimate index size. Attributes on the field definitions affect physical storage requirements:
For keyword search, marking fields as filterable and sortable increases index size.
For vector search, you can set parameters to reduce vector size.
Monitor storage, service limits, query volume, and latency in the Azure portal. the Azure portal shows you queries per second, throttled queries, and search latency. All of these values can help you decide if you selected the right tier.
Add replicas for high availability or to mitigate slow query performance.
There are no guidelines on how many replicas are needed to accommodate query loads. Query performance depends on the complexity of the query and competing workloads. Although adding replicas clearly results in better performance, the result isn't strictly linear: adding three replicas doesn't guarantee triple throughput. For guidance in estimating QPS for your solution, see Analyze performanceand Monitor queries.
For an inverted index, size and complexity are determined by content, not necessarily by the amount of data that you feed into it. A large data source with high redundancy could result in a smaller index than a smaller dataset that contains highly variable content. So it's rarely possible to infer index size based on the size of the original dataset.
Storage requirements can be inflated if you include data that will never be searched. Ideally, documents contain only the data that you need for the search experience.
The Free tier and preview features aren't covered by service-level agreements (SLAs). For all billable tiers, SLAs take effect when you provision sufficient redundancy for your service.
Two or more replicas satisfy query (read) SLAs.
Three or more replicas satisfy query and indexing (read-write) SLAs.
The number of partitions doesn't affect SLAs.