High availability for Azure SQL Database
Applies to: ![]() Azure SQL Database
Azure SQL Database
This article describes the high availability architecture in Azure SQL Database.
Overview
The goal of the high availability architecture in Azure SQL Database is to minimize impact on customer workloads from service maintenance operations and outages. For information regarding specific SLAs for different service tiers, see SLA for Azure SQL Database.
SQL Database runs on the latest stable version of the SQL Server Database Engine on the Windows operating system with all applicable patches. SQL Database automatically handles critical servicing tasks, such as patching, backups, Windows and SQL engine upgrades, and unplanned events such as underlying hardware, software, or network failures. When a database or elastic pool in SQL Database is patched or fails over, the downtime isn't impactful if you employ retry logic in your app. SQL Database can quickly recover even in the most critical circumstances, ensuring that your data is always available. Most users do not notice that upgrades are performed continuously.
The high availability solution is designed to ensure that committed data is never lost due to failures, that maintenance operations don't affect your workload, and that the database won't be a single point of failure in your software architecture.
There are three high availability architectural models:
- Remote storage model that is based on a separation of compute and storage. It relies on the high availability and reliability of the remote storage tier. This architecture targets budget-oriented business applications that can tolerate some performance degradation during maintenance activities.
- Local storage model that is based on a cluster of database engine processes. It relies on the fact that there is always a quorum of available database engine nodes. This architecture targets mission-critical applications with high IO performance, high transaction rate and guarantees minimal performance impact on your workload during maintenance activities.
- Hyperscale model which uses a distributed system of highly available components such as compute nodes, page servers, log service, and persistent storage. Each component supporting a Hyperscale database provides its own redundancy and resiliency to failures. Compute nodes, page servers, and log service run on Azure Service Fabric, which controls health of each component and performs failovers to available healthy nodes as necessary. Persistent storage uses Azure Storage with its native high availability and redundancy capabilities. To learn more, see Hyperscale architecture.
Within each of the three availability models, SQL Database supports local redundancy and zonal redundancy options. Local redundancy provides resiliency within a datacenter, while zonal redundancy improves resiliency further by protecting against outages of an availability zone within a region.
The following table shows the availability options based on service tiers:
| Service tier | High availability model | locally redundant availability | Zone-redundant availability |
|---|---|---|---|
| General Purpose (vCore) | Remote storage | Yes | Yes |
| Business Critical (vCore) | Local storage | Yes | Yes |
| Hyperscale (vCore) | Hyperscale | Yes | Yes |
| Basic (DTU) | Remote storage | Yes | No |
| Standard (DTU) | Remote storage | Yes | No |
| Premium (DTU) | Local storage | Yes | Yes |
Locally redundant availability
Locally redundant availability is based on storing your database to locally redundant storage (LRS) which copies your data three times within a single datacenter in the primary region and protects your data in the event of local failure, such as a small-scale network or power failure. LRS is the lowest-cost redundancy option and offers the least durability compared to other options. If a large-scale disaster such as fire or flooding occurs within a region, all replicas of a storage account using LRS might be lost or unrecoverable. As such, to further protect your data when using the locally redundant availability option, consider using a more resilient storage option for your database backups. This does not apply to Hyperscale databases, where the same storage is used for both data files and backups.
Locally redundant availability is available to all databases in all service tiers and Recovery Point Objective (RPO) which indicates the amount of data loss is zero.
Basic, Standard and General Purpose service tiers
The Basic, Standard, and General Purpose service tiers use the remote storage availability model for both serverless and provisioned compute. The following figure shows four different nodes with the separated compute and storage layers.
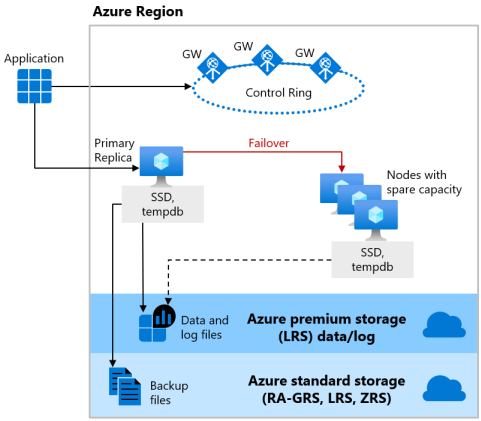
The remote storage availability model includes two layers:
- A stateless compute layer that runs the database engine process and contains only transient and cached data, such as the
tempdbandmodeldatabases on the attached SSD, and plan cache, buffer pool, and columnstore pool in memory. This stateless node is operated by Azure Service Fabric that initializes database engine, controls health of the node, and performs failover to another node if necessary. - A stateful data layer with the database files (
.mdfand.ldf) stored in Azure Blob Storage. Azure Blob Storage has built-in data availability and redundancy features. It guarantees that every record in the log file or page in the data file will be preserved even if database engine process crashes.
Whenever the database engine or the operating system is upgraded, or a failure is detected, Azure Service Fabric will move the stateless database engine process to another stateless compute node with sufficient free capacity. Data in Azure Blob storage isn't affected by the move, and the data/log files are attached to the newly initialized database engine process. This process guarantees high availability, but a heavy workload might experience some performance degradation during the transition since the new database engine process starts with cold cache.
Premium and Business Critical service tier
Premium and Business Critical service tiers use the local storage availability model, which integrates compute resources (database engine process) and storage (locally attached SSD) on a single node. High availability is achieved by replicating both compute and storage to additional nodes.

The underlying database files (.mdf/.ldf) are placed on the attached SSD storage to provide very low latency IO to your workload. High availability is implemented using a technology similar to SQL Server Always On availability groups. The cluster includes a single primary replica that is accessible for read-write customer workloads, and up to three secondary replicas (compute and storage) containing copies of data. The primary replica constantly pushes changes to the secondary replicas in order and ensures that the data is persisted on a sufficient number of secondary replicas before committing each transaction. This process guarantees that if the primary replica or a readable secondary replica crash for any reason, there is always a fully synchronized replica to fail over to. The failover is initiated by the Azure Service Fabric. Once a secondary replica becomes the new primary replica, another secondary replica is created to ensure the cluster has a sufficient number of replicas to maintain quorum. Once a failover is complete, Azure SQL connections are automatically redirected to the new primary replica or readable secondary replica.
As an extra benefit, the local storage availability model includes the ability to redirect read-only Azure SQL connections to one of the secondary replicas. This feature is called Read Scale-Out. It provides 100% additional compute capacity at no extra charge to off-load read-only operations, such as analytical workloads, from the primary replica.
Hyperscale service tier
The Hyperscale service tier architecture is described in Distributed functions architecture.

The availability model in Hyperscale includes four layers:
- A stateless compute layer that runs the database engine processes and contains only transient and cached data, such as non-covering RBPEX cache,
tempdbandmodeldatabases, etc. on the attached SSD, and plan cache, buffer pool, and columnstore pool in memory. This stateless layer includes the primary compute replica, and optionally a number of secondary compute replicas, that can serve as failover targets. - A stateless storage layer formed by page servers. This layer is the distributed storage engine for the database engine processes running on the compute replicas. Each page server contains only transient and cached data, such as covering RBPEX cache on the attached SSD, and data pages cached in memory. Each page server has a paired page server in an active-active configuration to provide load balancing, redundancy, and high availability.
- A stateful transaction log storage layer formed by the compute node running the Log service process, the transaction log landing zone, and transaction log long-term storage. Landing zone and long-term storage use Azure Storage, which provides availability and redundancy for transaction log, ensuring data durability for committed transactions.
- A stateful data storage layer with the database files (.mdf/.ndf) that are stored in Azure Storage and are updated by page servers. This layer uses data availability and redundancy features of Azure Storage. It guarantees that every page in a data file will be preserved even if processes in other layers of Hyperscale architecture crash, or if compute nodes fail.
Compute nodes in all Hyperscale layers run on Azure Service Fabric, which controls health of each node and performs failovers to available healthy nodes as necessary.
For more information on high availability in Hyperscale, see Database High Availability in Hyperscale.
Zone-redundant availability
Zone-redundant availability ensures your data is spread across three Azure availability zones in the primary region. Each availability zone is a separate physical location with independent power, cooling, and networking.
Zone-redundant availability is available to databases in the Premium, Business Critical, General Purpose and Hyperscale service tiers, and not the Basic and Standard service tiers of the DTU-based purchasing model. Each service tier implements zone-redundant availability differently. See the details for each service tier in the following sections. All implementations ensure a Recovery Point Objective (RPO) with zero loss of committed data upon failover.
General Purpose service tier
Zone-redundant configuration for the General Purpose service tier is offered for both serverless and provisioned compute for databases in vCore purchasing model. This configuration utilizes Azure Availability Zones to replicate databases across multiple physical locations within an Azure region. By selecting zone-redundancy, you can make your new and existing serverless and provisioned general purpose single databases and elastic pools resilient to a much larger set of failures, including catastrophic datacenter outages, without any changes of the application logic.
Zone-redundant configuration for the General Purpose tier has two layers:
- A stateful data layer with the database files (.mdf/.ldf) that are stored in ZRS(zone-redundant storage). Using ZRS the data and log files are synchronously copied across three physically isolated Azure availability zones.
- A stateless compute layer that runs the sqlservr.exe process and contains only transient and cached data, such as the
tempdbandmodeldatabases on the attached SSD, and plan cache, buffer pool, and columnstore pool in memory. This stateless node is operated by Azure Service Fabric that initializes sqlservr.exe, controls health of the node, and performs failover to another node if necessary. For zone-redundant serverless and provisioned General Purpose databases, nodes with spare capacity are readily available in other Availability Zones for failover.
The zone-redundant version of the high availability architecture for the General Purpose service tier is illustrated by the following diagram:
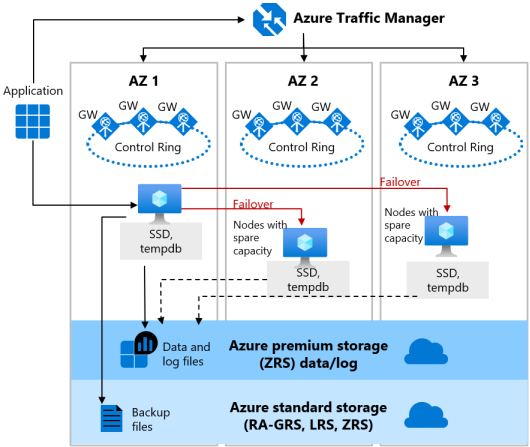
Consider the following when configuring your General Purpose databases with zone-redundancy:
- For General Purpose tier the zone-redundant configuration is Generally Available in the following regions:
- (Africa) South Africa North
- (Asia Pacific) Australia East
- (Asia Pacific) East Asia
- (Asia Pacific) Japan East
- (Asia Pacific) Korea Central
- (Asia Pacific) Southeast Asia
- (Asia Pacific) Central India
- (Asia Pacific) China North 3
- (Asia Pacific) UAE North
- (Europe) France Central
- (Europe) Germany West Central
- (Europe) Italy North
- (Europe) North Europe
- (Europe) Norway East
- (Europe) Poland Central
- (Europe) West Europe
- (Europe) UK South
- (Europe) Switzerland North
- (Europe) Sweden Central
- (Middle East) Israel Central
- (Middle East) Qatar Central
- (North America) Canada Central
- (North America) East US
- (North America) East US 2
- (North America) South Central US
- (North America) West US 2
- (North America) West US 3
- (South America) Brazil South
- For zone redundant availability, choosing a maintenance window other than the default is currently available in select regions.
- Zone-redundant configuration is only available in SQL Database when standard-series (Gen5) hardware is selected.
- Zone-redundancy is not available for Basic and Standard service tiers in the DTU purchasing model.
Premium and Business Critical service tiers
When Zone Redundancy is enabled for Premium or Business Critical service tier, the replicas are placed in different availability zones in the same region. To eliminate a single point of failure, the control ring is also duplicated across multiple zones as three gateway rings (GW). The routing to a specific gateway ring is controlled by Azure Traffic Manager. Because the zone-redundant configuration in the Premium or Business Critical service tiers uses its existing replicas to place in different availablity zones, you can enable it at no extra cost. By selecting a zone-redundant configuration, you can make your Premium or Business Critical databases and elastic pools resilient to a much larger set of failures, including catastrophic datacenter outages, without any changes to the application logic. You can also convert any existing Premium or Business Critical databases or elastic pools to zone-redundant configuration.
The zone-redundant version of the high availability architecture is illustrated by the following diagram:

Consider the following when configuring your Premium or Business Critical databases with zone-redundancy:
- For up to date information about the regions that support zone-redundant databases, see Services support by region.
- For zone redundant availability, choosing a maintenance window other than the default is currently available in select regions.
Hyperscale service tier
It's possible to configure zone-redundancy for databases in the Hyperscale service tier. To learn more, review Create zone-redundant Hyperscale database.
Enabling this configuration ensures zone-level resiliency through replication across Availability Zones for all Hyperscale layers. By selecting zone-redundancy, you can make your Hyperscale databases resilient to a much larger set of failures, including catastrophic datacenter outages, without any changes to the application logic. All Azure regions that have Availability Zones support zone redundant Hyperscale database.
Zone-redundant availability is supported in both Hyperscale standalone databases and Hyperscale elastic pools. For more information, see Hyperscale elastic pools.
The following diagram demonstrates the underlying architecture for zone redundant Hyperscale databases:

Consider the following limitations:
Zone redundant configuration can only be specified during database creation. This setting can't be modified once the resource is provisioned. Use Database copy, point-in-time restore, or create a geo-replica to update the zone redundant configuration for an existing Hyperscale database. When using one of these update options, if the target database is in a different region than the source or if the database backup storage redundancy from the target differs from the source database, the copy operation will be a size of data operation.
For zone redundant availability, choosing a maintenance window other than the default is currently available in select regions.
There's currently no option to specify zone redundancy when migrating a database to Hyperscale using the Azure portal. However, zone redundancy can be specified using Azure PowerShell, Azure CLI, or the REST API when migrating an existing database from another Azure SQL Database service tier to Hyperscale. Here's an example with Azure CLI:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant trueAt least 1 high availability compute replica and the use of zone-redundant or geo-zone-redundant backup storage is required for enabling the zone redundant configuration for Hyperscale.
Database zone redundant availability
In Azure SQL Database, a server is a logical construct that acts as a central administrative point for a collection of databases. At the server level, you can administer logins, authentication method, firewall rules, auditing rules, threat detection policies, and failover groups. Data related to some of these features, such as logins and firewall rules, is stored in the master database. Similarly, data for some DMVs, for example sys.resource_stats, is also stored in the master database.
When a database with a zone-redundant configuration is created on a logical server, the master database associated with the server is automatically made zone-redundant as well. This ensures that in a zonal outage, applications using the database remain unaffected because features dependent on the master database, such as logins and firewall rules, are still available. Making the master database zone-redundant is an asynchronous process and will take some time to finish in the background.
When none of the databases on a server are zone-redundant, or when you create an empty server, then the master database associated with the server is not zone-redundant.
You can use Azure PowerShell or the Azure CLI or the REST API to check the ZoneRedundant property for the master database:
Use the following example command to check the value of "ZoneRedundant" property for master database.
Get-AzSqlDatabase -ResourceGroupName "myResourceGroup" -ServerName "myServerName" -DatabaseName "master"
Test application fault resiliency
High availability is a fundamental part of the SQL Database platform that works transparently for your database application. However, we recognize that you might want to test how the automatic failover operations initiated during planned or unplanned events would impact an application before you deploy it to production. You can manually trigger a failover by calling a special API to restart a database, or an elastic pool. In the case of a zone-redundant serverless or provisioned General Purpose database or elastic pool, the API call would result in redirecting client connections to the new primary in an Availability Zone different from the Availability Zone of the old primary. So in addition to testing how failover impacts existing database sessions, you can also verify if it changes the end-to-end performance due to changes in network latency. Because the restart operation is intrusive and a large number of them could stress the platform, only one failover call is allowed every 15 minutes for each database or elastic pool.
For more on Azure SQL Database high availability and disaster recovery, review the HA/DR Checklist.
A failover can be initiated using PowerShell, REST API, or Azure CLI:
| Deployment type | PowerShell | REST API | Azure CLI |
|---|---|---|---|
| Database | Invoke-AzSqlDatabaseFailover | Database failover | az rest might be used to invoke a REST API call from Azure CLI |
| Elastic pool | Invoke-AzSqlElasticPoolFailover | Elastic pool failover | az rest might be used to invoke a REST API call from Azure CLI |
Important
The Failover command is not available for readable secondary replicas of Hyperscale databases.
Conclusion
Azure SQL Database features a built-in high availability solution that is deeply integrated with the Azure platform. It is dependent on Service Fabric for failure detection and recovery, on Azure Blob storage for data protection, and on Availability Zones for higher fault tolerance. In addition, SQL Database uses the Always On availability group technology from SQL Server for data synchronization and failover. The combination of these technologies enables applications to fully realize the benefits of a mixed storage model and supports the most demanding SLAs.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for