Partitioning and horizontal scaling in Azure Cosmos DB
APPLIES TO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Gremlin
Gremlin
![]() Table
Table
Azure Cosmos DB uses partitioning to scale individual containers in a database to meet the performance needs of your application. The items in a container are divided into distinct subsets called logical partitions. Logical partitions are formed based on the value of a partition key that is associated with each item in a container. All the items in a logical partition have the same partition key value.
For example, a container holds items. Each item has a unique value for the UserID property. If UserID serves as the partition key for the items in the container and there are 1,000 unique UserID values, 1,000 logical partitions are created for the container.
In addition to a partition key that determines the item's logical partition, each item in a container has an item ID (unique within a logical partition). Combining the partition key and the item ID creates the item's index, which uniquely identifies the item. Choosing a partition key is an important decision that affects your application's performance.
This article explains the relationship between logical and physical partitions. It also discusses best practices for partitioning and gives an in-depth view at how horizontal scaling works in Azure Cosmos DB. It's not necessary to understand these internal details to select your partition key but we're covering them so you can have clarity on how Azure Cosmos DB works.
Logical partitions
A logical partition consists of a set of items that have the same partition key. For example, in a container that contains data about food nutrition, all items contain a foodGroup property. You can use foodGroup as the partition key for the container. Groups of items that have specific values for foodGroup, such as Beef Products, Baked Products, and Sausages and Luncheon Meats, form distinct logical partitions.
A logical partition also defines the scope of database transactions. You can update items within a logical partition by using a transaction with snapshot isolation. When new items are added to a container, the system transparently creates new logical partitions. You don't have to worry about deleting a logical partition when the underlying data is deleted.
There's no limit to the number of logical partitions in your container. Each logical partition can store up to 20 GB of data. Good partition key choices have a wide range of possible values. For example, in a container where all items contain a foodGroup property, the data within the Beef Products logical partition can grow up to 20 GB. Selecting a partition key with a wide range of possible values ensures that the container is able to scale.
You can use Azure Monitor Alerts to monitor if a logical partition's size is approaching 20 GB.
Physical partitions
A container is scaled by distributing data and throughput across physical partitions. Internally, one or more logical partitions are mapped to a single physical partition. Typically smaller containers have many logical partitions but they only require a single physical partition. Unlike logical partitions, physical partitions are an internal implementation of the system and Azure Cosmos DB entirely manages physical partitions.
The number of physical partitions in your container depends on the following characteristics:
The amount of throughput provisioned (each individual physical partition can provide a throughput of up to 10,000 request units per second). The 10,000 RU/s limit for physical partitions implies that logical partitions also have a 10,000 RU/s limit, as each logical partition is only mapped to one physical partition.
The total data storage (each individual physical partition can store up to 50 GBs of data).
Note
Physical partitions are an internal implementation of the system and they are entirely managed by Azure Cosmos DB. When developing your solutions, don't focus on physical partitions because you can't control them. Instead, focus on your partition keys. If you choose a partition key that evenly distributes throughput consumption across logical partitions, you will ensure that throughput consumption across physical partitions is balanced.
There's no limit to the total number of physical partitions in your container. As your provisioned throughput or data size grows, Azure Cosmos DB automatically creates new physical partitions by splitting existing ones. Physical partition splits don't affect your application's availability. After the physical partition split, all data within a single logical partition will still be stored on the same physical partition. A physical partition split simply creates a new mapping of logical partitions to physical partitions.
Throughput provisioned for a container is divided evenly among physical partitions. A partition key design that doesn't distribute requests evenly might result in too many requests directed to a small subset of partitions that become "hot." Hot partitions lead to inefficient use of provisioned throughput, which might result in rate-limiting and higher costs.
You can see your container's physical partitions in the Storage section of the Metrics blade of the Azure portal:

For example, consider a container with the path /foodGroup specified as the partition key. The container could have any number of physical partitions, but in this example we assume it has three. A single physical partition could contain multiple partition keys. As an example, the largest physical partition could contain the top three most significant size logical partitions: Beef Products, Vegetable and Vegetable Products, and Soups, Sauces, and Gravies.
If you assign a throughput of 18,000 request units per second (RU/s), then each of the three physical partitions can utilize 1/3 of the total provisioned throughput. Within the selected physical partition, the logical partition keys Beef Products, Vegetable and Vegetable Products, and Soups, Sauces, and Gravies can, collectively, utilize the physical partition's 6,000 provisioned RU/s. Because provisioned throughput is evenly divided across your container's physical partitions, it's important to choose a partition key that evenly distributes throughput consumption. For more information, see choosing the right logical partition key.
Managing logical partitions
Azure Cosmos DB transparently and automatically manages the placement of logical partitions on physical partitions to efficiently satisfy the scalability and performance needs of the container. As the throughput and storage requirements of an application increase, Azure Cosmos DB moves logical partitions to automatically spread the load across a greater number of physical partitions. You can learn more about physical partitions.
Azure Cosmos DB uses hash-based partitioning to spread logical partitions across physical partitions. Azure Cosmos DB hashes the partition key value of an item. The hashed result determines the logical partition. Then, Azure Cosmos DB allocates the key space of partition key hashes evenly across the physical partitions.
Transactions (in stored procedures or triggers) are allowed only against items in a single logical partition.
Replica sets
Each physical partition consists of a set of replicas, also referred to as a replica set. Each replica hosts an instance of the database engine. A replica set makes the data store within the physical partition durable, highly available, and consistent. Each replica that makes up the physical partition inherits the partition's storage quota. All replicas of a physical partition collectively support the throughput that's allocated to the physical partition. Azure Cosmos DB automatically manages replica sets.
Typically, smaller containers only require a single physical partition, but they still have at least four replicas.
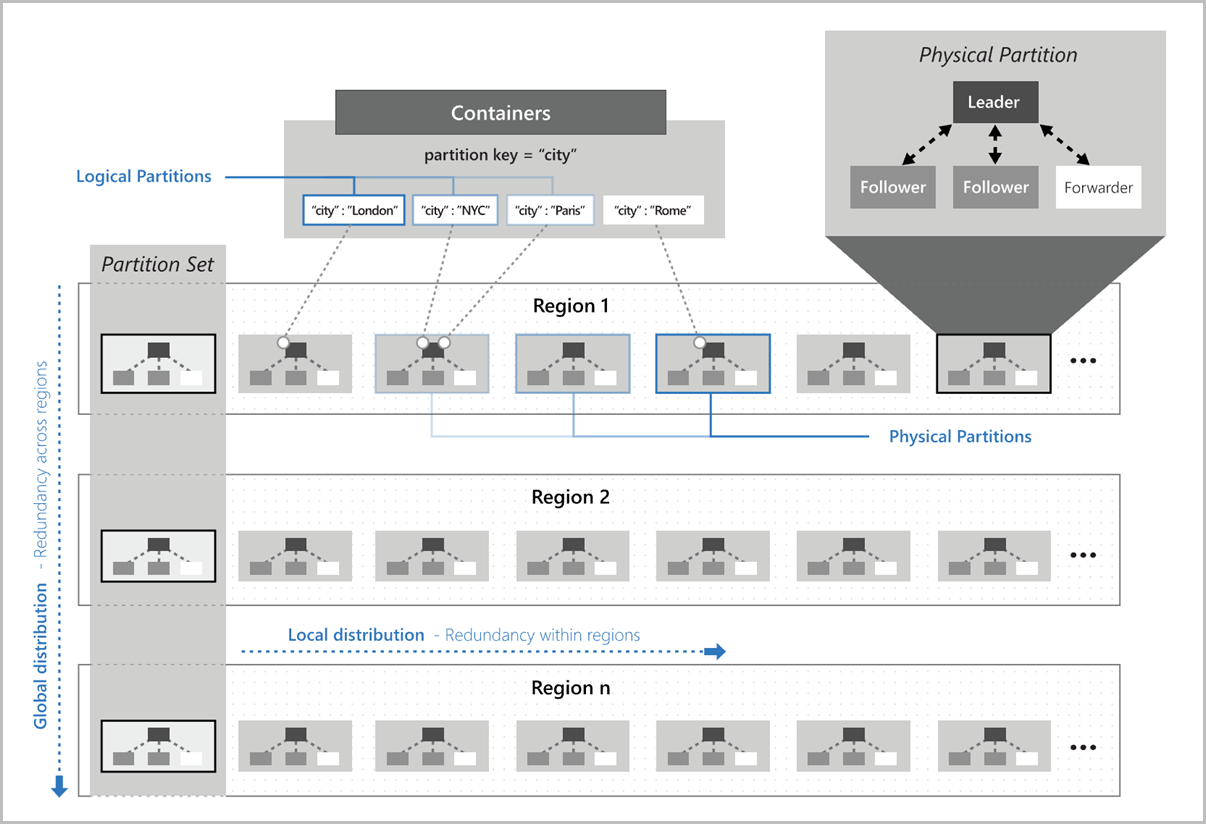
The following image shows how logical partitions are mapped to physical partitions that are distributed globally. Partition set in the image refers to a group of physical partitions that manage the same logical partition keys across multiple regions:
Choose a partition key
A partition key has two components: partition key path and the partition key value. For example, consider an item { "userId" : "Andrew", "worksFor": "Microsoft" } if you choose "userId" as the partition key, the following are the two partition key components:
The partition key path (For example: "/userId"). The partition key path accepts alphanumeric and underscores (_) characters. You can also use nested objects by using the standard path notation(/).
The partition key value (For example: "Andrew"). The partition key value can be of string or numeric types.
To learn about the limits on throughput, storage, and length of the partition key, see the Azure Cosmos DB service quotas article.
Selecting your partition key is a simple but important design choice in Azure Cosmos DB. Once you select your partition key, it isn't possible to change it in-place. If you need to change your partition key, you should move your data to a new container with your new desired partition key. (Container copy jobs help with this process.)
For all containers, your partition key should:
Be a property that has a value, which doesn't change. If a property is your partition key, you can't update that property's value.
Should only contain
Stringvalues - or numbers should ideally be converted into aString, if there's any chance that they are outside the boundaries of double precision numbers according to IEEE 754 binary64. The Json specification calls out the reasons why using numbers outside of this boundary in general is a bad practice due to likely interoperability problems. These concerns are especially relevant for the partition key column, because it's immutable and requires data migration to change it later.Have a high cardinality. In other words, the property should have a wide range of possible values.
Spread request unit (RU) consumption and data storage evenly across all logical partitions. This spread ensures even RU consumption and storage distribution across your physical partitions.
Have values that are no larger than 2048 bytes typically, or 101 bytes if large partition keys aren't enabled. For more information, see large partition keys
If you need multi-item ACID transactions in Azure Cosmos DB, you need to use stored procedures or triggers. All JavaScript-based stored procedures and triggers are scoped to a single logical partition.
Note
If you only have one physical partition, the value of the partition key may not be relevant as all queries will target the same physical partition.
Partition keys for read-heavy containers
For most containers, the above criteria are all you need to consider when picking a partition key. For large read-heavy containers, however, you might want to choose a partition key that appears frequently as a filter in your queries. Queries can be efficiently routed to only the relevant physical partitions by including the partition key in the filter predicate.
This property can be a good partition key choice if most of your workload's requests are queries and most of your queries have an equality filter on the same property. For example, if you frequently run a query that filters on UserID, then selecting UserID as the partition key would reduce the number of cross-partition queries.
However, if your container is small, you probably don't have enough physical partitions to need to worry about the performance of cross-partition queries. Most small containers in Azure Cosmos DB only require one or two physical partitions.
If your container could grow to more than a few physical partitions, then you should make sure you pick a partition key that minimizes cross-partition queries. Your container requires more than a few physical partitions when either of the following are true:
Your container has over 30,000 RUs provisioned
Your container stores over 100 GB of data
Use item ID as the partition key
Note
This section primarily applies to the API for NoSQL. Other APIs, such as the API for Gremlin, do not support the unique identifier as the partition key.
If your container has a property that has a wide range of possible values, it's likely a great partition key choice. One possible example of such a property is the item ID. For small read-heavy containers or write-heavy containers of any size, the item ID (/id) is naturally a great choice for the partition key.
The system property item ID exists in every item in your container. You might have other properties that represent a logical ID of your item. In many cases, these IDs are also great partition key choices for the same reasons as the item ID.
The item ID is a great partition key choice for the following reasons:
- There are a wide range of possible values (one unique item ID per item).
- Because there's a unique item ID per item, the item ID does a great job at evenly balancing RU consumption and data storage.
- You can easily do efficient point reads since you always know an item's partition key if you know its item ID.
Some things to consider when selecting the item ID as the partition key include:
- If the item ID is the partition key, it becomes a unique identifier throughout your entire container. You can't create items that have duplicate item IDs.
- If you have a read-heavy container with many physical partitions, queries are more efficient if they have an equality filter with the item ID.
- You can't run stored procedures or triggers that target multiple logical partitions.
Next steps
- Learn about provisioned throughput in Azure Cosmos DB.
- Learn about global distribution in Azure Cosmos DB.
- See the training module on how to Model and partition your data in Azure Cosmos DB.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for