Quickstart: Create a data factory by using the Azure portal
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This quickstart describes how to use either the Azure Data Factory Studio or the Azure portal UI to create a data factory.
Note
If you are new to Azure Data Factory, see Introduction to Azure Data Factory before trying this quickstart.
Prerequisites
Azure subscription
If you don't have an Azure subscription, create a free account before you begin.
Azure roles
To learn about the Azure role requirements to create a data factory, refer to Azure Roles requirements.
Create a data factory
A quick creation experience provided in the Azure Data Factory Studio to enable users to create a data factory within seconds. More advanced creation options are available in Azure portal.
Quick creation in the Azure Data Factory Studio
Launch Microsoft Edge or Google Chrome web browser. Currently, Data Factory UI is supported only in Microsoft Edge and Google Chrome web browsers.
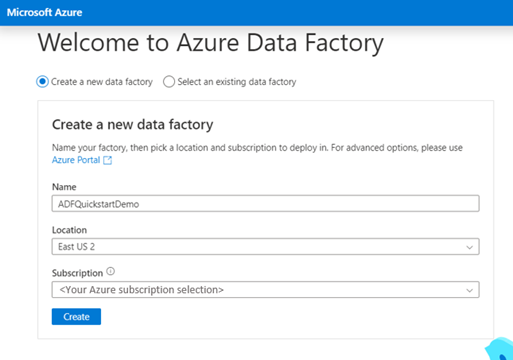
Go to the Azure Data Factory Studio and choose the Create a new data factory radio button.
You can use the default values to create directly, or enter a unique name and choose a preferred location and subscription to use when creating the new data factory.
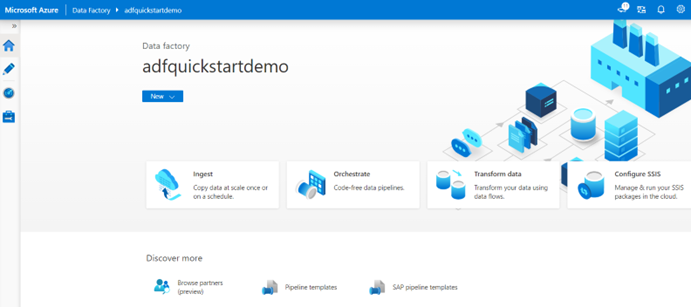
After creation, you can directly enter the homepage of the Azure Data Factory Studio.
Advanced creation in the Azure portal
Launch Microsoft Edge or Google Chrome web browser. Currently, Data Factory UI is supported only in Microsoft Edge and Google Chrome web browsers.
Go to the Azure portal data factories page.
After landing on the data factories page of the Azure portal, click Create.

For Resource Group, take one of the following steps:
Select an existing resource group from the drop-down list.
Select Create new, and enter the name of a new resource group.
To learn about resource groups, see Use resource groups to manage your Azure resources.
For Region, select the location for the data factory.
The list shows only locations that Data Factory supports, and where your Azure Data Factory meta data will be stored. The associated data stores (like Azure Storage and Azure SQL Database) and computes (like Azure HDInsight) that Data Factory uses can run in other regions.
For Name, enter ADFTutorialDataFactory.
The name of the Azure data factory must be globally unique. If you see the following error, change the name of the data factory (for example, <yourname>ADFTutorialDataFactory) and try creating again. For naming rules for Data Factory artifacts, see the Data Factory - naming rules article.
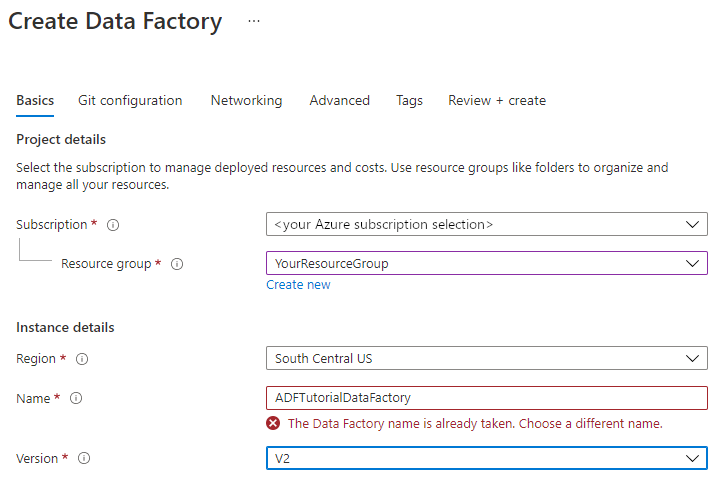
For Version, select V2.
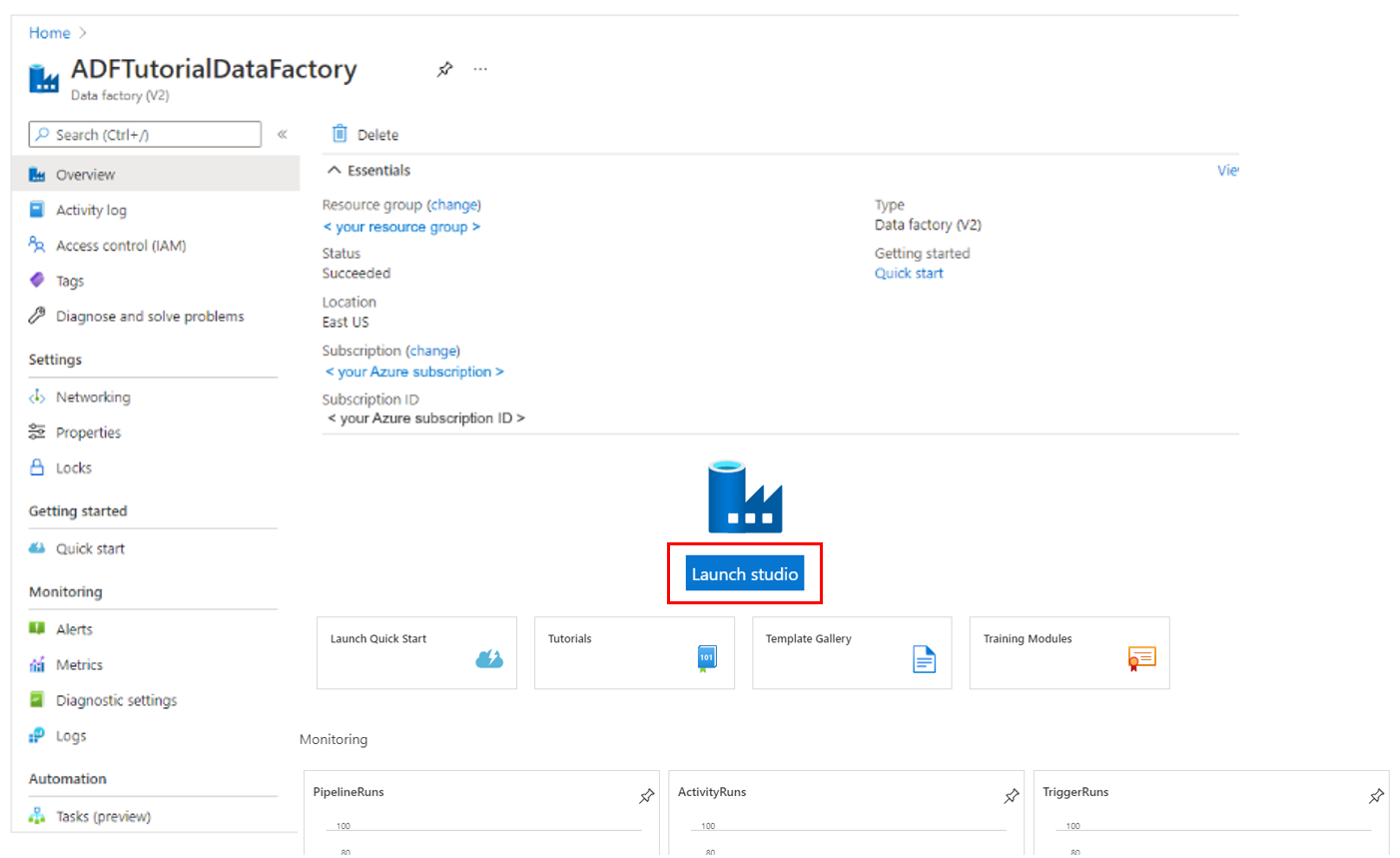
Select Review + create, and select Create after the validation is passed. After the creation is complete, select Go to resource to navigate to the Data Factory page.
Select Launch Studio to open Azure Data Factory Studio to start the Azure Data Factory user interface (UI) application on a separate browser tab.
Note
If you see that the web browser is stuck at "Authorizing", clear the Block third-party cookies and site data check box. Or keep it selected, create an exception for login.microsoftonline.com, and then try to open the app again.
Related content
Learn how to use Azure Data Factory to copy data from one location to another with the Hello World - How to copy data tutorial. Lean how to create a data flow with Azure Data Factory[data-flow-create.md].
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for