REST Tutorial: Use skillsets to generate searchable content in Azure AI Search
In this tutorial, learn how to call REST APIs that create an AI enrichment pipeline for content extraction and transformations during indexing.
Skillsets add AI processing to raw content, making that content more uniform and searchable. Once you know how skillsets work, you can support a broad range of transformations: from image analysis, to natural language processing, to customized processing that you provide externally.
This tutorial helps you learn how to:
- Define objects in an enrichment pipeline.
- Build a skillset. Invoke OCR, language detection, entity recognition, and key phrase extraction.
- Execute the pipeline. Create and load a search index.
- Check the results using full text search.
If you don't have an Azure subscription, open a free account before you begin.
Overview
This tutorial uses a REST client and the Azure AI Search REST APIs to create a data source, index, indexer, and skillset.
The indexer drives each step in the pipeline, starting with content extraction of sample data (unstructured text and images) in a blob container on Azure Storage.
Once content is extracted, the skillset executes built-in skills from Microsoft to find and extract information. These skills include Optical Character Recognition (OCR) on images, language detection on text, key phrase extraction, and entity recognition (organizations). New information created by the skillset is sent to fields in an index. Once the index is populated, you can use the fields in queries, facets, and filters.
Prerequisites
Note
You can use a free search service for this tutorial. The free tier limits you to three indexes, three indexers, and three data sources. This tutorial creates one of each. Before starting, make sure you have room on your service to accept the new resources.
Download files
Download a zip file of the sample data repository and extract the contents. Learn how.
Upload sample data to Azure Storage
In Azure Storage, create a new container and name it cog-search-demo.
Get a storage connection string so that you can formulate a connection in Azure AI Search.
On the left, select Access keys.
Copy the connection string for either key one or key two. The connection string is similar to the following example:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI services
Built-in AI enrichment is backed by Azure AI services, including Language service and Azure AI Vision for natural language and image processing. For small workloads like this tutorial, you can use the free allocation of twenty transactions per indexer. For larger workloads, attach an Azure AI Services multi-region resource to a skillset for pay-as-you-go pricing.
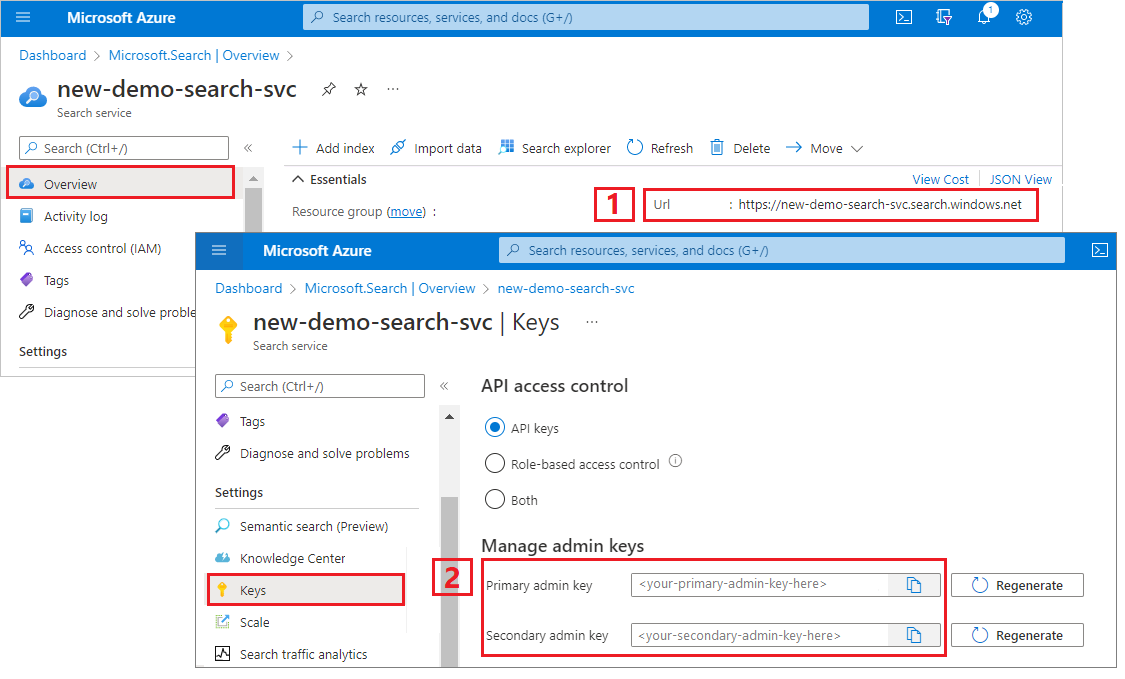
Copy a search service URL and API key
For this tutorial, connections to Azure AI Search require an endpoint and an API key. You can get these values from the Azure portal.
Sign in to the Azure portal, navigate to the search service Overview page, and copy the URL. An example endpoint might look like
https://mydemo.search.windows.net.Under Settings > Keys, copy an admin key. Admin keys are used to add, modify, and delete objects. There are two interchangeable admin keys. Copy either one.
Set up your REST file
Start Visual Studio Code and open the skillset-tutorial.rest file. See Quickstart: Text search using REST if you need help with the REST client.
Provide values for the variables: search service endpoint, search service admin API key, an index name, a connection string to your Azure Storage account, and the blob container name.
Create the pipeline
AI enrichment is indexer-driven. This part of the walkthrough creates four objects: data source, index definition, skillset, indexer.
Step 1: Create a data source
Call Create Data Source to set the connection string to the Blob container containing the sample data files.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Step 2: Create a skillset
Call Create Skillset to specify which enrichment steps are applied to your content. Skills execute in parallel unless there's a dependency.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Key points:
The body of the request specifies the following built-in skills:
Skill Description Optical Character Recognition Recognizes text and numbers in image files. Text Merge Creates "merged content" that recombines previously separated content, useful for documents with embedded images (PDF, DOCX, and so forth). Images and text are separated during the document cracking phase. The merge skill recombines them by inserting any recognized text, image captions, or tags created during enrichment into the same location where the image was extracted from in the document. When you're working with merged content in a skillset, this node is inclusive of all text in the document, including text-only documents that never undergo OCR or image analysis. Language Detection Detects the language and outputs either a language name or code. In multilingual data sets, a language field can be useful for filters. Entity Recognition Extracts the names of people, organizations, and locations from merged content. Text Split Breaks large merged content into smaller chunks before calling the key phrase extraction skill. Key phrase extraction accepts inputs of 50,000 characters or less. A few of the sample files need splitting up to fit within this limit. Key Phrase Extraction Pulls out the top key phrases. Each skill executes on the content of the document. During processing, Azure AI Search cracks each document to read content from different file formats. Found text originating in the source file is placed into a generated
contentfield, one for each document. As such, the input becomes"/document/content".For key phrase extraction, because we use the text splitter skill to break larger files into pages, the context for the key phrase extraction skill is
"document/pages/*"(for each page in the document) instead of"/document/content".
Note
Outputs can be mapped to an index, used as input to a downstream skill, or both as is the case with language code. In the index, a language code is useful for filtering. For more information about skillset fundamentals, see How to define a skillset.
Step 3: Create an index
Call Create Index to provide the schema used to create inverted indexes and other constructs in Azure AI Search.
The largest component of an index is the fields collection, where data type and attributes determine content and behavior in Azure AI Search. Make sure you have fields for your newly generated output.
### Create an index
POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Step 4: Create and run an indexer
Call Create Indexer to drive the pipeline. The three components you have created thus far (data source, skillset, index) are inputs to an indexer. Creating the indexer on Azure AI Search is the event that puts the entire pipeline into motion.
Expect this step to take several minutes to complete. Even though the data set is small, analytical skills are computation-intensive.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Key points:
The body of the request includes references to the previous objects, configuration properties required for image processing, and two types of field mappings.
"fieldMappings"are processed before the skillset, sending content from the data source to target fields in an index. You use field mappings to send existing, unmodified content to the index. If field names and types are the same at both ends, no mapping is required."outputFieldMappings"are for fields created by skills, after skillset execution. The references tosourceFieldNameinoutputFieldMappingsdon't exist until document cracking or enrichment creates them. ThetargetFieldNameis a field in an index, defined in the index schema.The
"maxFailedItems"parameter is set to -1, which instructs the indexing engine to ignore errors during data import. This is acceptable because there are so few documents in the demo data source. For a larger data source, you would set the value to greater than 0.The
"dataToExtract":"contentAndMetadata"statement tells the indexer to automatically extract the values from the blob's content property and the metadata of each object.The
imageActionparameter tells the indexer to extract text from images found in the data source. The"imageAction":"generateNormalizedImages"configuration, combined with the OCR Skill and Text Merge Skill, tells the indexer to extract text from the images (for example, the word "stop" from a traffic Stop sign), and embed it as part of the content field. This behavior applies to both embedded images (think of an image inside a PDF) and standalone image files, for instance a JPG file.
Note
Creating an indexer invokes the pipeline. If there are problems reaching the data, mapping inputs and outputs, or order of operations, they appear at this stage. To re-run the pipeline with code or script changes, you might need to drop objects first. For more information, see Reset and re-run.
Monitor indexing
Indexing and enrichment commence as soon as you submit the Create Indexer request. Depending on skillset complexity and operations, indexing can take a while.
To find out whether the indexer is still running, call Get Indexer Status to check the indexer status.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Key points:
Warnings are common in some scenarios and don't always indicate a problem. For example, if a blob container includes image files, and the pipeline doesn't handle images, you get a warning stating that images weren't processed.
In this sample, there's a PNG file that contains no text. All five of the text-based skills (language detection, entity recognition of locations, organizations, people, and key phrase extraction) fail to execute on this file. The resulting notification shows up in execution history.
Check results
Now that you've created an index that contains AI-generated content, call Search Documents to run some queries to see the results.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Filters can help you narrow results to items of interest:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
These queries illustrate a few of the ways you can work with query syntax and filters on new fields created by Azure AI Search. For more query examples, see Examples in Search Documents REST API, Simple syntax query examples, and Full Lucene query examples.
Reset and rerun
During early stages of development, iteration over the design is common. Reset and rerun helps with iteration.
Takeaways
This tutorial demonstrates the basic steps for using the REST APIs to create an AI enrichment pipeline: a data source, skillset, index, and indexer.
Built-in skills were introduced, along with skillset definition that shows the mechanics of chaining skills together through inputs and outputs. You also learned that outputFieldMappings in the indexer definition is required for routing enriched values from the pipeline into a searchable index on an Azure AI Search service.
Finally, you learned how to test results and reset the system for further iterations. You learned that issuing queries against the index returns the output created by the enriched indexing pipeline.
Clean up resources
When you're working in your own subscription, at the end of a project, it's a good idea to remove the resources that you no longer need. Resources left running can cost you money. You can delete resources individually or delete the resource group to delete the entire set of resources.
You can find and manage resources in the portal, using the All resources or Resource groups link in the left-navigation pane.
Next steps
Now that you're familiar with all of the objects in an AI enrichment pipeline, take a closer look at skillset definitions and individual skills.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for