Elastic jobs in Azure SQL Database
Applies to: ![]() Azure SQL Database
Azure SQL Database
In this article, we review the capabilities and details of elastic jobs for Azure SQL Database.
- For a tutorial on configuring elastic jobs, see the elastic jobs tutorial.
- Learn more about automation concepts in Azure database platforms.
Elastic jobs overview
You can create and schedule elastic jobs that could be periodically executed against one or many Azure SQL databases to run Transact-SQL (T-SQL) queries and perform maintenance tasks.
You can define target database or groups of databases where the job will be executed, and also define schedules for running a job. All dates and times in elastic jobs are in the UTC time zone.
A job handles the task of logging in to the target database. You also define, maintain, and persist Transact-SQL scripts to be executed across a group of databases.
Every job logs the status of execution and also automatically retries the operations if any failure occurs.
When to use elastic jobs
There are several scenarios when you could use elastic job automation:
- Automate management tasks and schedule them to run every weekday, after hours, etc.
- Deploy schema changes, credentials management.
- Performance data collection or tenant (customer) telemetry collection.
- Update reference data (information common across all databases).
- Load data from Azure Blob storage.
- Configure jobs to execute across a collection of databases on a recurring basis, such as during off-peak hours.
- Collect query results from a set of databases into a central table on an on-going basis.
- Queries can be continually executed and configured to trigger additional tasks to be executed.
- Collect data for reporting
- Aggregate data from a collection of databases into a single destination table.
- Execute longer running data processing queries across a large set of databases, for example the collection of customer telemetry. Results are collected into a single destination table for further analysis.
- Data movement
- For custom developed solutions, business automation, or other task management.
- ETL processing to extract/process/insert data between tables in a database.
Consider elastic jobs when you:
- Have a task that needs to be run regularly on a schedule, targeting one or more databases.
- Have a task that needs to be run once, but across multiple databases.
- Need to run jobs against any combination of databases: one or more individual databases, all databases on a server, all databases in an elastic pool, with the added flexibility to include or exclude any specific database. Jobs can run across multiple servers, multiple pools, and can even run against databases in different subscriptions. Servers and pools are dynamically enumerated at runtime, so jobs run against all databases that exist in the target group at the time of execution.
- This is a significant differentiation from SQL Agent, which cannot dynamically enumerate the target databases, especially in SaaS customer scenarios where databases are added/deleted dynamically.
Elastic job components
| Component | Description |
|---|---|
| Elastic job agent | The Azure resource you create to run and manage Jobs. |
| Job database | A database in Azure SQL Database that the job agent uses to store job related data, job definitions, etc. |
| Job | A job is a unit of work that is composed of one or more job steps. Job steps specify the T-SQL script to run, as well as other details required to execute the script. |
| Target group | The set of servers, pools, and databases to run a job against. |
Elastic job agent
An elastic job agent is the Azure resource for creating, running, and managing jobs. The elastic job agent is an Azure resource you create in the portal (PowerShell and REST API are also supported).
Creating an elastic job agent requires an existing database in Azure SQL Database. The agent configures this existing Azure SQL Database as the job database.
You can start, disable, or cancel a job through the Azure portal. The Azure portal also allows you to view job definitions and execution history.
Cost of the elastic job agent
The job database is billed at the same rate as any database in Azure SQL Database. For the cost of the Elastic job agent, see Azure Pricing Calculator.
Elastic job database
The job database is used for defining jobs and tracking the status and history of job executions. Jobs are executed in target databases. The job database is also used to store agent metadata, logs, results, job definitions, and also contains many useful stored procedures and other database objects for creating, running, and managing jobs using T-SQL.
An Azure SQL Database (S1 or higher) is recommended to create an elastic job agent.
The job database should be a clean, empty, S1 or higher service objective Azure SQL Database.
The recommended service objective of the job database is S1 or higher, but the optimal choice depends on the performance needs of your job(s): the number of job steps, the number of job targets, and how frequently jobs are run.
If operations against the job database are slower than expected, monitor database performance and the resource utilization in the job database during periods of slowness using Azure portal or the sys.dm_db_resource_stats DMV. If utilization of a resource, such as CPU, Data IO, or Log Write approaches 100% and correlates with periods of slowness, consider incrementally scaling the database to higher service objectives (either in the DTU model or in the vCore model) until job database performance is sufficiently improved.
Important
Do not modify the existing objects or create new objects in the job database, though you can read from the tables for reporting and analytics.
Elastic jobs and job steps
A job is a unit of work that is executed on a schedule or as a one-time job. A job consists of one or more job steps.
Each job step specifies a T-SQL script to execute, one or more target groups to run the T-SQL script against, and the credentials the job agent needs to connect to the target database. Each job step has customizable timeout and retry policies, and can optionally specify output parameters.
Elastic job targets
Elastic jobs provide the ability to run one or more T-SQL scripts in parallel, across a large number of databases, on a schedule or on-demand. The target can be any tier of Azure SQL Database.
You can run scheduled jobs against any combination of databases: one or more individual databases, all databases on a server, all databases in an elastic pool, with the added flexibility to include or exclude any specific database. Jobs can run across multiple servers, multiple pools, and can even run against databases in different subscriptions. Servers and pools are dynamically enumerated at runtime, so jobs run against all databases that exist in the target group at the time of execution.
The following image shows a job agent executing jobs across the different types of target groups:
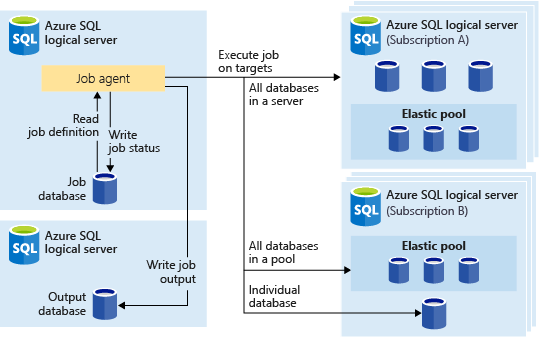
Target group
A target group defines the set of databases a job step will execute on. A target group can contain any number and combination of the following:
- Logical SQL server - if a server is specified, all databases that exist in the server at the time of the job execution are part of the group. The
masterdatabase credential must be provided so that the group can be enumerated and updated prior to job execution. For more information on logical servers, see What is a server in Azure SQL Database and Azure Synapse Analytics?. - Elastic pool - if an elastic pool is specified, all databases that are in the elastic pool at the time of the job execution are part of the group. As for a server, the
masterdatabase credential must be provided so that the group can be updated prior to the job execution. - Single database - specify one or more individual databases to be part of the group.
Tip
At the moment of job execution, dynamic enumeration re-evaluates the set of databases in target groups that include servers or pools. Dynamic enumeration ensures that jobs run across all databases that exist in the server or pool at the time of job execution. Re-evaluating the list of databases at runtime is specifically useful for scenarios where pool or server membership changes frequently.
Pools and single databases can be specified as included or excluded from the group. This enables creating a target group with any combination of databases. For example, you can add a server to a target group, but exclude specific databases in an elastic pool (or exclude an entire pool).
A target group can include databases in multiple subscriptions, and across multiple regions. Cross-region executions have higher latency than executions within the same region.
The following examples show how different target group definitions are dynamically enumerated at the moment of job execution to determine which databases the job will run:

- Example 1 shows a target group that consists of a list of individual databases. When a job step is executed using this target group, the job step's action will be executed in each of those databases.
- Example 2 shows a target group that contains a server as a target. When a job step is executed using this target group, the server is dynamically enumerated to determine the list of databases that are currently in the server. The job step's action will be executed in each of those databases.
- Example 3 shows a similar target group as Example 2, but an individual database is specifically excluded. The job step's action will not be executed in the excluded database.
- Example 4 shows a target group that contains an elastic pool as a target. Similar to Example 2, the pool will be dynamically enumerated at job run time to determine the list of databases in the pool.

- Example 5 and Example 6 show advanced scenarios where servers, elastic pools, and databases can be combined using include and exclude rules.
Note
The job database itself can be the target of a job. In this scenario, the job database is treated just like any other target database. The job user must be created and granted sufficient permissions in the job database, and the database-scoped credential for the job user must also exist in the job database, just like it does for any other target database.
Authentication
Choose one method for all targets for an elastic job agent. For example, for a single elastic job agent, you cannot configure one target server to use database-scoped credentials and another to use Microsoft Entra ID authentication.
The elastic job agent can connect to the server(s)/database(s) specified by the target group via two authentication options:
- Use Microsoft Entra (formerly Azure Active Directory) authentication with a user-assigned managed identity (UMI).
- Use Database-scoped credentials.
Authentication via user-assigned managed identity (UMI)
Microsoft Entra (formerly Azure Active Directory) authentication via user-assigned managed identity (UMI) is the recommended option for connecting elastic jobs to Azure SQL Database. With Microsoft Entra ID support, the job agent will be able to connect to target databases (databases, servers, elastic pools) and output database(s) using the UMI.

Optionally, Microsoft Entra ID authentication can also be enabled on the logical server containing the elastic job database, for accessing/querying that database via Microsoft Entra ID connections. However, the job agent itself uses internal certificate-based authentication to connect to its job database.
You can create one UMI, or use an existing UMI, and assign the same UMI to multiple job agents. Only one UMI is supported per job agent. Once a UMI is assigned to a Job agent, that Job Agent will only use this identity to connect and run t-SQL Jobs at the target databases. SQL Authentication will not be used against the target server/databases of that Job Agent.
The UMI name must begin with a letter or a number and with a length between 3 to 128. It can contain the - and _ characters.
For more information on UMI in Azure SQL Database, see Managed identities for Azure SQL, including the steps required and benefits of using an UMI as the Azure SQL Database logical server identity. For more information, see Use Microsoft Entra (formerly Azure Active Directory) to authenticate to Azure SQL platforms.
Important
When using Microsoft Entra ID authentication, create your jobuser user from that Microsoft Entra ID in every target database. Grant that user the permissions needed to execute your job(s) in each target database.
Using a system-assigned managed identity (SMI) is not supported.
Authentication via database-scoped credentials
While Microsoft Entra (formerly Azure Active Directory) authentication is the recommended option, jobs can be configured to use database-scoped credentials to connect to the databases specified by the target group upon execution. Prior to October 2023, database-scoped credentials were the only authentication option.
If a target group contains servers or pools, these database-scoped credentials are used to connect to the master database to enumerate the available databases.
- The database-scoped credentials must be created in the job database.
- All target databases must have a login with sufficient permissions for the job to complete successfully (
jobuserin the following diagram). - Credentials created in target databases (
LOGINandPASSWORDformasteruserandjobuser, in the following diagram) should match theIDENTITYandSECRETin the credentials created in the job database. - Credentials can be reused across jobs, and the credential passwords are encrypted and secured from users who have read-only access to job objects.
The following image is designed to help understand setting up the proper job credentials, and how the elastic job agent connects using database credentials as authentication to logins/users in target servers/databases.
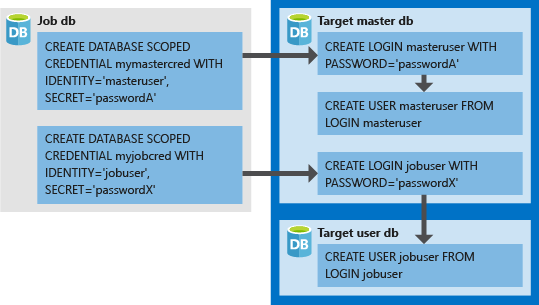
Note
When using database-scoped credentials, remember to create your jobuser user in every target database.
Elastic job private endpoints
The elastic job agent supports elastic job private endpoints. Creating an elastic jobs private endpoint establishes a private link between the elastic job and the target server. The elastic jobs private endpoints feature is different from the Azure Private Link.

The elastic job private endpoints feature supports private connections to target/output servers, such that the job agent can still reach them even when "Deny Public Access" option is enabled. Using private endpoints is also one possible solution if you would like to disable "Allow Azure services and resources to access that server" option.
Elastic job private endpoints support all options of elastic job agent authentication.
The elastic job private endpoint feature allows you to choose a service-managed private endpoint to establish a secure connection between the job agent and its target/output servers. A service-managed private endpoint is a private IP address within a specific virtual network and subnet. When you choose to use private endpoints on one of your job agent's target/output servers, a service-managed private endpoint is created by Microsoft. This private endpoint is then exclusively used by the job agent for connecting and executing jobs, or for writing the job output on that target/output databases.
Elastic job private endpoints can be created and allowed through the Azure portal. Target servers connected via the private link can be anywhere in Azure, even in different geographies and subscriptions. You must create a private endpoint for each desired target server and the job output server to enable this communication.
For a tutorial to configure a new service-managed private endpoint for elastic jobs, see Configure Azure SQL elastic jobs private endpoint.
Requirements for elastic job private endpoints
- To use an elastic jobs private endpoint, both the job agent and target servers/databases must be hosted in Azure (same or different regions) and in the same cloud type (for example, both in public cloud or both in government cloud).
Microsoft.Networkresource provider must be registered for the host subscriptions of both the job agent and the target/output servers.- Elastic job private endpoints are created per target/output server. They must be approved before the elastic job agent can use them. This can be done through the Networking pane of that logical server or your preferred client. The elastic job agent will then be able to reach any databases under that server using private connection.
- The connection from the elastic job agent to the jobs database will not use private endpoint. The job agent itself uses internal certificate-based authentication to connect to its jobs database. One caveat being if you add the jobs database as a target group member. Then it behaves as a regular target that you would need to setup with private endpoint as needed.
Elastic job database permissions
During job agent creation, a schema, tables, and a role called jobs_reader are created in the job database. The role is created with the following permission and is designed to give administrators finer access control for job monitoring. Administrators can provide users the ability to monitor job execution by adding them to the jobs_reader role in the job database.
| Role name | 'jobs' schema permissions | 'jobs_internal' schema permissions |
|---|---|---|
| jobs_reader | SELECT | None |
Caution
You should not update internal catalog views in the job database, such as jobs.target_group_members. Manually changing these catalog views can corrupt the job database and cause failure. These views are for read-only querying only. You can use the stored procedures on your job database to add/delete target groups/members, such as jobs.sp_add_target_group_member.
Important
Consider the security implications before granting any elevated access to the job database. A malicious user with permissions to create or edit jobs could create or edit a job that uses a stored credential to connect to a database under the malicious user's control, which could allow the malicious user to determine the credential's password or execute malicious commands.
Monitor elastic jobs
Starting in October 2023, the elastic job agent has integration with Azure Alerts for job status notifications, simplifying the solution for monitoring the status and history of job execution.
The Azure portal also has new, additional features for supporting elastic jobs and job monitoring. On the Overview page of the Elastic job agent, the most recent job executions are displayed, as in following screenshot.

You can create Azure Monitor Alert rules with the Azure portal, Azure CLI, PowerShell, and REST API. The Failed Elastic jobs metric is a good starting point to monitor and receive alerts on elastic job execution. In addition, you can elect to be alerted through a configurable action like SMS or email by the Azure Alert facility. For more information, see Create alerts for Azure SQL Database in the Azure portal.
For a sample, see Create, configure, and manage elastic jobs.
Job output
The outcome of a job's steps on each target database are recorded in detail, and script output can be captured to a specified table. You can specify a database to save any data returned from a job.
Job history
View elastic job execution history in the job database by querying the table jobs.job_executions. A system cleanup job purges execution history that is older than 45 days. To remove history less than 45 days old manually, execute the sp_purge_jobhistory stored procedure in the job database.
Job status
You can monitor elastic job executions in the job database by querying the table jobs.job_executions.
Best practices
Consider the following best practices when working with elastic database jobs.
Security best practices
- Limit usage of the APIs to trusted individuals.
- Credentials should have the least privileges necessary to perform the job step. For more information, see Authorization and Permissions.
- When using a server and/or pool target group member, it's highly suggested to create a separate credential with rights on the
masterdatabase to view/list databases that is used to expand the database lists of the server(s) and/or pool(s) prior to the job execution.
Elastic job performance
Elastic jobs use minimal compute resources while waiting for long-running jobs to complete.
Depending on the size of the target group of databases and the desired execution time for a job (number of concurrent workers), the agent requires different amounts of compute and performance of the job database (the more targets and the higher number of jobs, the higher the amount of compute required).
Concurrent capacity tiers
Starting in October 2023, the elastic job agent has multiple tiers of performance to allow for increasing capacity.
Capacity increments indicate the total number of concurrent target databases the job agent can connect to and start a job. For more concurrent target connections for job execution, upgrade a job agent's tier from the default JA100 tier, which has a limit of 100 concurrent target connections.
Most environments require less than 100 concurrent jobs at any time, so JA100 is the default.
| Elastic job agent tier | Maximum concurrent jobs |
|---|---|
| JA100 | 100 |
| JA200 | 200 |
| JA400 | 400 |
| JA800 | 800 |
Exceeding the job agent's concurrency capacity tier with job targets will create queuing delays for some target databases/servers. For example, if you start a job with 110 target in the JA100 tier, 10 jobs will wait to start until others finish.
The tier or service objective of an elastic job agent can be modified through the Azure portal, PowerShell, or the Job Agents REST API. For an example, see Scale the job agent.
Limit job impact on elastic pools
To ensure resources aren't overburdened when running jobs against databases in an Azure SQL Database elastic pool, jobs can be configured to limit the number of databases a job can run against at the same time.
Set the number of concurrent databases a job runs on by setting the sp_add_jobstep stored procedure's @max_parallelism parameter in T-SQL.
Idempotent scripts
An elastic job's T-SQL scripts must be idempotent. Idempotent means that if the script succeeds, and it's run again, the same result occurs. A script can fail due to transient network issues. In that case, the job will automatically retry running the script a preset number of times before desisting. An idempotent script has the same result even if it's been successfully run twice (or more).
A simple tactic is to test for the existence of an object before creating it. The following is a hypothetical example:
IF NOT EXISTS (SELECT * FROM sys.objects WHERE [name] = N'some_object')
print 'Object does not exist'
-- Create the object
ELSE
print 'Object exists'
-- If it exists, drop the object before recreating it.
Similarly, a script must be able to execute successfully by logically testing for and countering any conditions it finds.
Limitations
These are the current limitations to the elastic jobs service. We're actively working to remove as many of these limitations as possible.
| Issue | Description |
|---|---|
| The elastic job agent needs to be recreated and started in the new region after a failover/move to a new Azure region. | The elastic jobs service stores all its job agent and job metadata in the jobs database. Any failover or move of Azure resources to a new Azure region will also move the jobs database, job agent and jobs metadata to the new Azure region. However, the elastic job agent is a compute only resource and needs to be explicitly re-created and started in the new region before jobs will start executing again in the new region. Once started, the elastic job agent will resume executing jobs in the new region as per the previously defined job schedule. |
| Excessive Audit logs from jobs database | The elastic job agent operates by constantly polling the job database to check for the arrival of new jobs and other CRUD operations. If auditing is enabled on the server that houses a jobs database, a large number of audit logs can be generated by the jobs database. This can be mitigated by filtering out these audit logs using the Set-AzSqlServerAudit command with a predicate expression.For example: Set-AzSqlServerAudit -ResourceGroupName "ResourceGroup01" -ServerName "Server01" -BlobStorageTargetState Enabled -StorageAccountResourceId "/subscriptions/7fe3301d-31d3-4668-af5e-211a890ba6e3/resourceGroups/resourcegroup01/providers/Microsoft.Storage/storageAccounts/mystorage" -PredicateExpression "database_principal_name <> '##MS_JobAccount##'"This command will only filter out job agent to jobs database audit logs, not job agent to any target databases audit logs. |
| Use of a Hyperscale database as job database | Using a Hyperscale database as a job database isn't supported. However, elastic jobs can target Hyperscale databases in the same way as any other database in Azure SQL Database. |
| Serverless databases and auto-pausing with elastic jobs. | Auto-pause enabled serverless database isn't supported as a job database. Serverless databases targeted by elastic jobs do support auto-pausing, and will be resumed by job connections. |
| Exporting a Job Database to a BACPAC file | Export of a Job Database to a BACPAC file is not supported. If the SQL Server containing a Job Database needs to be exported, Job Database should be dropped first before exporting the server. |
Related content
- Create, configure, and manage elastic jobs
- Automate management tasks in Azure SQL
- Create and manage elastic jobs by using PowerShell
- Create and manage elastic jobs by using T-SQL
Next step
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for